AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
該論文作者來自於鵬城實驗室多於智能體與身智慧研究所團隊,包括林倞教授(研究所所長,國家傑青,IEEE Fellow),鄭鋒教授,梁小丹教授,王志強(南科大),鄭浩(南科大),聶雲雙(中大),徐文君(鵬城),葉華(鵬城)等。鵬城實驗室林倞教授團隊致力於打造多智能體協同與模擬訓練平台、雲端協同具身多模態大模型等一般基礎平台,賦能工業互聯網、社會治理與服務等重大應用需求。 今年以來,具身智能正成為學術界和產業界的熱門領域,相關的產品和成果層出不窮。今天,鵬城實驗室多智能體與具身智能研究所(以下簡稱鵬城具身所)聯合南方科技大學、中山大學正式發布並開源其最新的具身智能領域學術成果——ARIO(All Robots In One)具身大規模資料集,旨在解決目前具身智慧領域所面臨的資料獲取難題。 

-
- 專案首頁:https://imaei.github.io/project_pages/ario/🎜🎜鵬城實驗室具身所網站連結:https://imaei.github.io/🎜鵬城實驗室具身所網站連結:https://imaei.github.io/🎜
Als Gehirn des verkörperten Roboters liegt der Schlüssel zur Verbesserung der Leistung des verkörperten großen Modells darin, hochwertige verkörperte Big Data zu erhalten. Anders als die Text- oder Bilddaten, die in großen Sprachmodellen oder großen visuellen Modellen verwendet werden, können verkörperte Daten nicht direkt aus den umfangreichen Inhalten des Internets gewonnen werden, sondern müssen durch echte Roboteroperationen gesammelt oder von fortschrittlichen Simulationsplattformen generiert werden Sammlung verkörperter Daten Es erfordert viel Zeit und Kosten, und es ist schwierig, einen großen Maßstab zu erreichen. Gleichzeitig weisen die aktuellen Open-Source-Datensätze auch viele Mängel auf. Wie in der obigen Tabelle gezeigt, ist das Datenvolumen von JD ManiData, ManiWAV und RH20T nicht groß und die für DROID verwendete Roboter-Hardwareplattform Daten sind relativ einfach. Obwohl die Open-X-Ausführung eine große Datenmenge erreicht hat, sind ihre sensorischen Datenmodalitäten nicht umfangreich und die Datenformate zwischen den Unterdatensätzen sind auch uneinheitlich Es kostet viel Zeit, die Daten vor ihrer Verwendung zu filtern und zu verarbeiten, und es ist schwierig, die Anforderungen an ein effizientes und gezieltes Training verkörperter intelligenter Modelle in komplexen Szenarien zu erfüllen. Im Vergleich dazu enthält der dieses Mal veröffentlichte ARIO-Datensatz sensorische Daten in 5 Modalitäten: 2D, 3D, Text, Berührung und Ton, die zwei Hauptkategorien abdecken: Bedienung und Navigation Zu den Aufgaben gehören: Sowohl Simulationsdaten als auch Realszenendaten und enthalten eine Vielzahl von Roboterhardware, die sehr umfangreich ist. Während der Datenumfang drei Millionen erreicht, gewährleistet er auch ein einheitliches Format der Daten. Es handelt sich derzeit um einen Open-Source-Datensatz, der gleichzeitig eine hohe Qualität, Vielfalt und einen großen Umfang im Bereich der verkörperten Intelligenz erreicht. Für den Datensatz der verkörperten Intelligenz gibt es einige, da Roboter viele Formen haben, wie z. B. einarmige, doppelarmige, humanoide, vierbeinige usw., und auch die Wahrnehmungs- und Kontrollmethoden unterschiedlich sind Sie werden durch Gelenkwinkel gesteuert, und einige werden durch die Körper- oder Endpositionskoordinaten gesteuert, sodass die verkörperten Daten selbst viel komplexer sind als einfache Bild- und Textdaten und viele Steuerparameter aufgezeichnet werden müssen. Und wenn es kein einheitliches Format gibt, wird bei der Aggregation mehrerer Arten von Roboterdaten viel Energie für die zusätzliche Vorverarbeitung aufgewendet. Daher hat das Embodiment Institute des Pengcheng Laboratory zunächst eine Reihe von Formatstandards für verkörperte Big Data entwickelt. Dieser Standard kann verschiedene Formen von Robotersteuerungsparametern aufzeichnen und verfügt über eine klare Struktur der Datenorganisationsform Kompatibel mit Sensoren mit unterschiedlichen Bildraten und zeichnet entsprechende Zeitstempel auf, um die genauen Anforderungen des verkörperten intelligenten Großmodells an die Erfassung und Steuerung des Timings zu erfüllen. Die folgende Abbildung zeigt das Gesamtdesign des ARIO-Datensatzes. O Abbildung 1. ARIO-Datensatzdesign 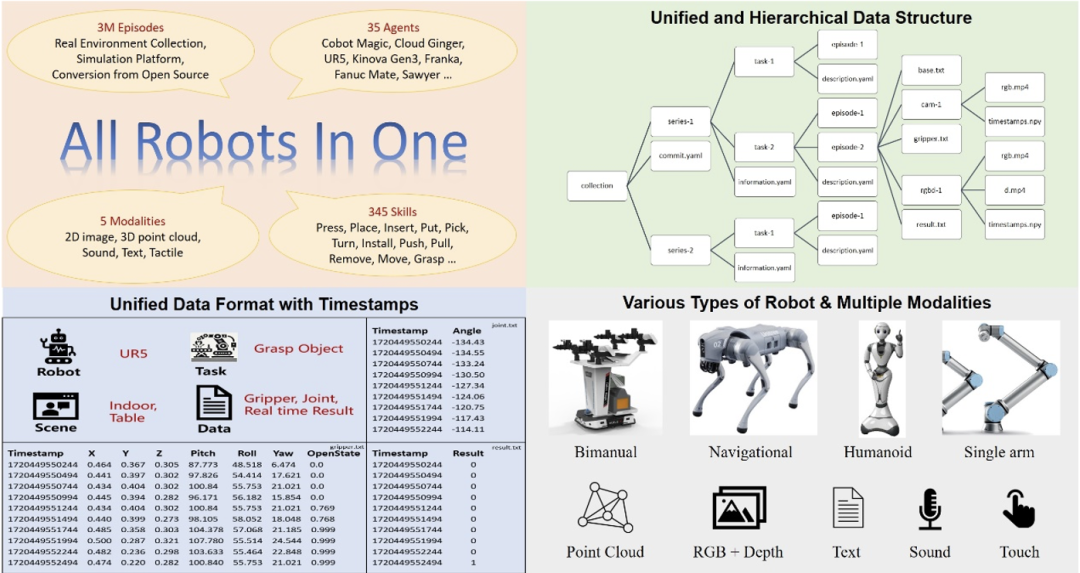
Ario-Datensatz mit insgesamt 258 Szenensequenzen, 32.1064 Aufgaben und 3,03 Millionen Beispielen. Die Daten von ARIO stammen aus drei Hauptquellen. Die eine besteht aus der Sammlung realer Personen durch die Anordnung von Szenen und Aufgaben in realen Umgebungen Robotermodell durch die Simulations-Engine. Der dritte Schritt besteht darin, die derzeit Open-Source-verkörperten Datensätze einzeln zu analysieren, zu verarbeiten und sie in Daten umzuwandeln, die dem ARIO-Formatstandard entsprechen. Im Folgenden werden die spezifische Zusammensetzung des ARIO-Datensatzes sowie die Prozesse und Beispiele aus den 3 Quellen dargestellt. Hochwertige Robotikdaten sind schwer zu bekommen, aber sie sind unglaublich wertvoll. Basierend auf dem Master-Slave-Zweiarmroboter Cobot Magic hat das Pengcheng Laboratory mehr als 30 Aufgaben entwickelt, darunter drei Schwierigkeitsstufen für die Bedienung: einfach – mittel – schwierig, und durch das Hinzufügen störender Objekte, das zufällige Ändern der Positionen von Objekten und Robotern usw Ändern des Layouts Die Umgebung und andere Methoden wurden verwendet, um die Vielfalt der Proben zu erhöhen, und schließlich wurden mehr als 3.000 Flugbahndaten mit 3 RGBD-Kameras erhalten. Nachfolgend werden Sammlungsbeispiele für verschiedene Aufgaben und Sammlungsvideos gezeigt. O Abbildung 3. Beispiel für die Datenerfassung eines echten Ario-Roboters
 ? der Daten erleichtert die Durchführung statistischer Analysen seine Datenzusammensetzung. Die folgende Abbildung zeigt die Statistik der Verteilung von ARIO-Szenen (Abbildung a) und Fähigkeiten (Abbildung b) aus den drei Ebenen Serie, Aufgabe und Episode. Es ist ersichtlich, dass sich die meisten verkörperten Daten derzeit auf Szenen und Fähigkeiten im Innenleben und in häuslichen Umgebungen konzentrieren. Zusätzlich zu Szenarien und Fähigkeiten können ARIO-Daten auch statistische Analysen aus der Perspektive des Roboters selbst durchführen und einige der aktuellen Entwicklungstrends der Roboterindustrie kennenlernen. Der ARIO-Datensatz liefert statistische Daten zur Roboterform, sich bewegenden Objekten, physikalischen Steuervariablen, Sensortypen und Installationsorten, der Anzahl visueller Sensoren, dem Anteil der Steuerungsmethoden, dem Anteil der Datenerfassungsmethoden und dem Anteil der Anzahl der Freiheitsgrade des Roboterarms, entsprechend den Abbildungen a-i unten.
? der Daten erleichtert die Durchführung statistischer Analysen seine Datenzusammensetzung. Die folgende Abbildung zeigt die Statistik der Verteilung von ARIO-Szenen (Abbildung a) und Fähigkeiten (Abbildung b) aus den drei Ebenen Serie, Aufgabe und Episode. Es ist ersichtlich, dass sich die meisten verkörperten Daten derzeit auf Szenen und Fähigkeiten im Innenleben und in häuslichen Umgebungen konzentrieren. Zusätzlich zu Szenarien und Fähigkeiten können ARIO-Daten auch statistische Analysen aus der Perspektive des Roboters selbst durchführen und einige der aktuellen Entwicklungstrends der Roboterindustrie kennenlernen. Der ARIO-Datensatz liefert statistische Daten zur Roboterform, sich bewegenden Objekten, physikalischen Steuervariablen, Sensortypen und Installationsorten, der Anzahl visueller Sensoren, dem Anteil der Steuerungsmethoden, dem Anteil der Datenerfassungsmethoden und dem Anteil der Anzahl der Freiheitsgrade des Roboterarms, entsprechend den Abbildungen a-i unten.  Nehmen Sie Abbildung a unten als Beispiel. Daraus können wir erkennen, dass die meisten aktuellen Daten von einarmigen Robotern stammen. Es gibt nur sehr wenige Open-Source-Daten für humanoide Roboter und diese stammen hauptsächlich aus echten Sammlungen und Simulationsgenerierung des Pengcheng-Labors.
Nehmen Sie Abbildung a unten als Beispiel. Daraus können wir erkennen, dass die meisten aktuellen Daten von einarmigen Robotern stammen. Es gibt nur sehr wenige Open-Source-Daten für humanoide Roboter und diese stammen hauptsächlich aus echten Sammlungen und Simulationsgenerierung des Pengcheng-Labors.  Originalpapier und Projekthomepage.
Originalpapier und Projekthomepage. 以上是總說具身智慧的資料太貴,鵬城實驗室開源百萬規模標準化資料集的詳細內容。更多資訊請關注PHP中文網其他相關文章!
























