

使用 Scrapy 抓取網站時,您很快就會遇到各種需要發揮創意或與要抓取的頁面進行互動的場景。其中一個場景是當您需要抓取無限滾動頁面時。當您向下捲動頁面時,這種類型的網站頁面會加載更多內容,就像社交媒體來源一樣。
抓取這些類型的頁面的方法肯定不只一種。我最近解決這個問題的一種方法是繼續滾動,直到頁面長度停止增加(即滾動到底部)。這篇文章將逐步介紹這個過程。
這篇文章假設您已經設定並運行了一個 Scrapy 項目,並且有一個可以修改和運行的 Spider。
此整合使用 scrapy-playwright 外掛程式將 Playwright for Python 與 Scrapy 整合。 Playwright 是一個無頭瀏覽器自動化庫,用於與網頁互動並提取資料。
我一直在使用uv進行Python套件的安裝和管理。
然後,我直接使用 uv 的虛擬環境:
使用以下命令將 scrapy-playwright 外掛程式和 Playwright 安裝到您的虛擬環境:
安裝您想要與 Playwright 一起使用的瀏覽器。例如,要安裝 Chromium,您可以執行以下命令:
如果需要,您也可以安裝其他瀏覽器,例如 Firefox。
注意:以下 Scrapy 程式碼和 Playwright 整合僅使用 Chromium 進行了測試。
更新settings.py檔案或spider中的custom_settings屬性以包含DOWNLOAD_HANDLERS和PLAYWRIGHT_LAUNCH_OPTIONS設定。
對於 PLAYWRIGHT_LAUNCH_OPTIONS,您可以將 headless 選項設為 False,以開啟瀏覽器實例並觀察進程運行。這有利於調試和建構初始抓取器。
我傳遞了額外的參數來禁用網路安全並隔離來源。當您抓取存在 CORS 問題的網站時,這非常有用。
例如,可能會出現由於 CORS 導致所需的 JavaScript 資源未載入或未發出網路請求的情況。如果某些頁面操作(例如單擊按鈕)未按預期工作但其他一切都正常,您可以透過檢查瀏覽器控制台是否有錯誤來更快地隔離此問題。
這是一個爬行無限滾動頁面的蜘蛛的範例。蜘蛛將頁面滾動 700 像素,並等待 750 毫秒以完成請求。蜘蛛將繼續滾動,直到到達頁面底部,滾動位置在循環過程中不會改變。
我正在使用 custom_settings 修改蜘蛛本身的設置,以將設置保留在一個地方。您也可以將這些設定新增到settings.py檔案中。
我了解到的一件事是,沒有兩個頁面或網站是相同的,因此您可能需要調整滾動量和等待時間以考慮頁面以及網路往返中的任何延遲以完成請求。您可以透過檢查滾動位置和完成請求所需的時間以程式設計方式動態調整此值。
在頁面載入時,我等待資源載入和頁面渲染的時間稍長。 Playwright 頁面被傳遞到response.meta 物件中的解析回呼方法。這用於與頁面互動並滾動頁面。這是在 scrapy.Request 參數中使用 playwright=True 和 playwright_include_page=True 選項指定的。
此蜘蛛將使用 page.evaluate 和scrollBy() JavaScript 方法將頁面捲動 700 像素,然後等待 750 毫秒以完成請求。然後,將 Playwright 頁面內容複製到 Scrapy 選擇器,並從頁面中提取連結。然後,這些連結將被傳送到 Scrapy 管道以繼續處理。
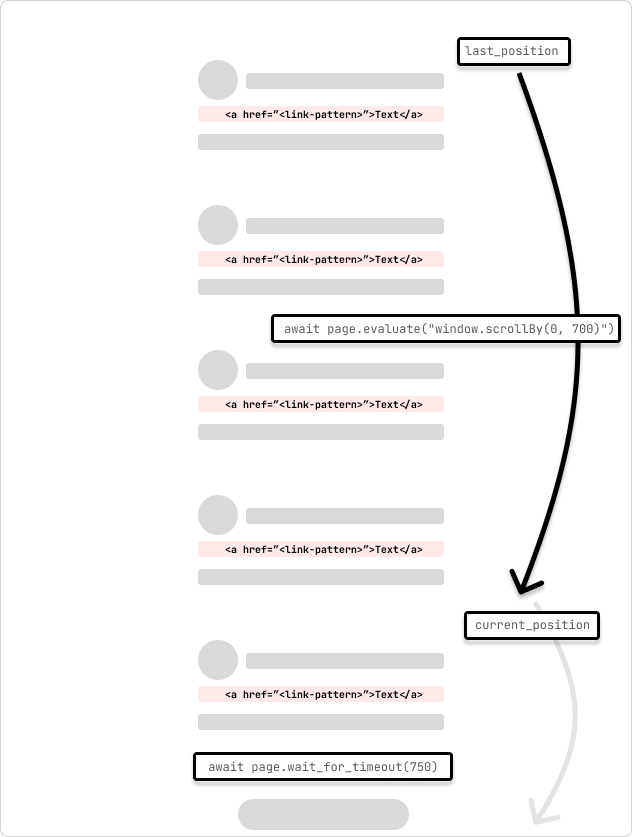
對於頁面要求開始載入重複內容的情況,可以新增一個檢查,看看內容是否已經載入完畢,然後跳出循環。或者,如果您知道滾動加載的數量,則可以添加計數器,以便在一定數量的滾動加上/減去緩衝區後跳出循環。
It's also possible that the page may have an element that you can scroll to (i.e. "Load more") that will trigger the next set of content to load. You can use the page.evaluate method to scroll to the element and then click it to load the next set of content.
... try: while True: button = page.locator('//button[contains(., "Load more")]') await button.wait_for() if not button: print("No 'Load more' button found.") break is_disabled = await button.is_disabled() if is_disabled: print("Button is disabled.") break await button.scroll_into_view_if_needed() await button.click() await page.wait_for_timeout(750) except Exception as error: print(f"Error: {error}") pass ...
This method is useful when you know the page has a button that will load the next set of content. You can also use this method to click on other elements that will trigger the next set of content to load. The scroll_into_view_if_needed method will scroll the button or element into view if it is not already visible on the page. This is one of those scenarios when you will want to double-check the page actions with headless=False to see if the button is being clicked and the content is being loaded as expected before running a full crawl.
Note: As mentioned above, confirm that the page assets(.js) are loading correctly and that the network requests are being made so that the button (or element) is mounted and clickable.
Web crawling is a case-by-case scenario and you will need to adjust the code to fit the page that you are trying to scrape. The above code is a starting point to get you going with crawling infinite scroll pages with Scrapy and Playwright.
Hopefully, this helps to get you unblocked! ?
Subscribe to get my latest content by email -> Newsletter
以上是使用 Scrapy 和 Playwright 無限滾動抓取頁面的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































