

我喜歡表情符號。誰不呢?
幾天前我正在整理一篇高智商的X貼文時,我意識到了一些事情。
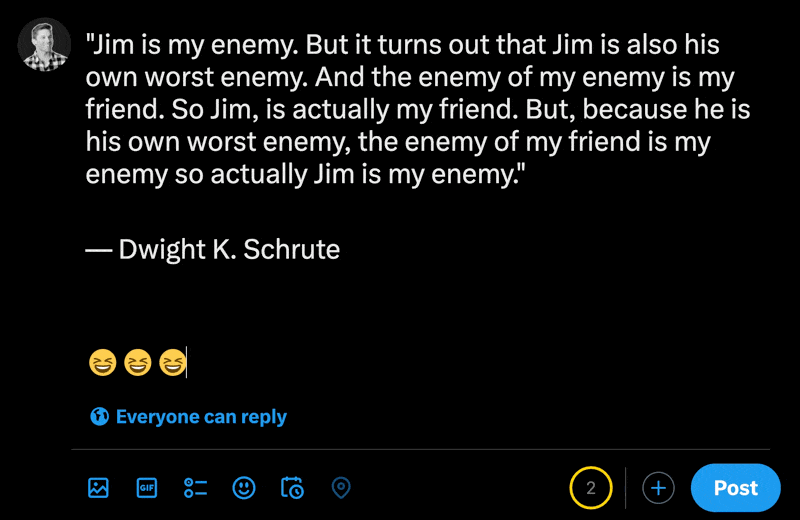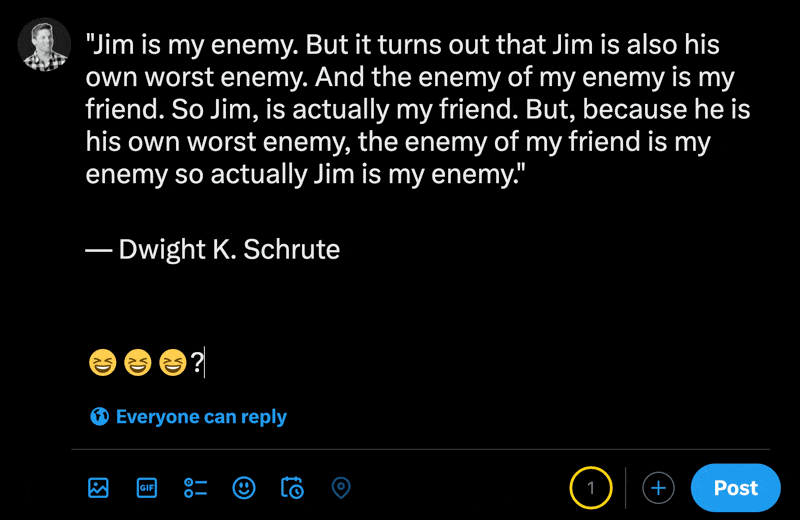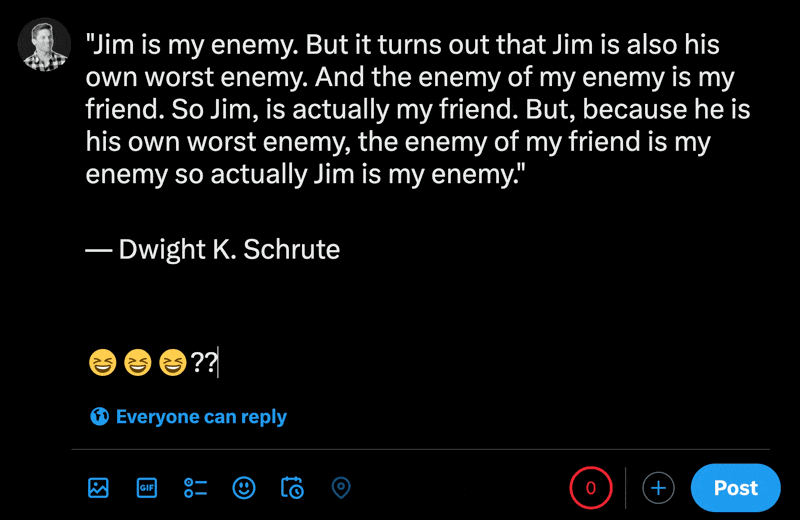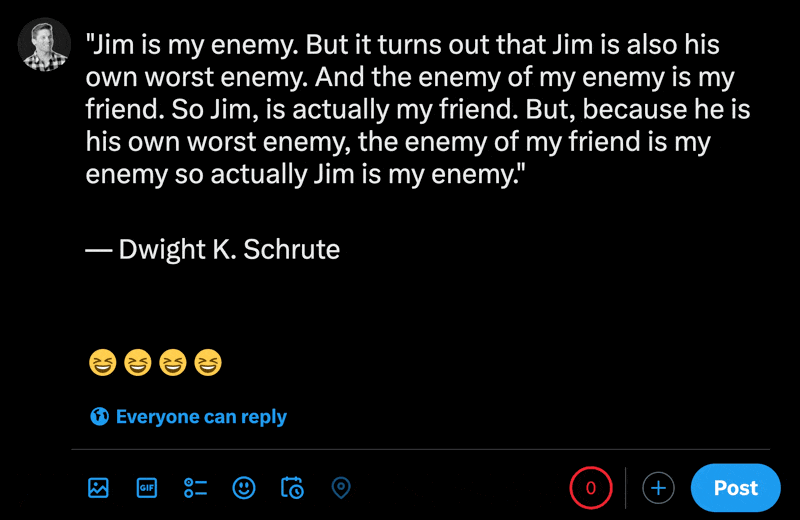
在X的新貼文部分中輸入表情符號時,您可以看到常規字元的數量比表情符號少。
經過快速搜索,我發現這與它們在 Unicode 系統中的編碼方式有關。
本質上,表情符號是由多個代碼點組成的,長度只計算代碼點,而不計算字元。
無論它為何發生,我都會思考我創建的所有文字計數器以及 SaaS 領域中存在多少個文字計數器。
表情符號沒有被公平對待? .
僅僅計算字串的長度並不是準確的計數。舉個例子,像這樣:
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return text.length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
這是一個簡單的 React 元件,用於追蹤輸入到文字欄位中的字元。這是此功能最常見的實作。
但是輸出給我們帶來了與我的 X 帖子相同的問題:

您可以使用名為 Intl.Segmenter 的內建物件。
該物件有更廣泛的用例,但它本質上根據您提供的區域設定將字串分解為更有意義的項目,例如單字和句子。它比簡單地使用程式碼點提供了更多的粒度。
要修復上面的範例,我們要做的就是更新我們的 countString 函數,如下所示:
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return Array.from(new Intl.Segmenter().segment(text)).length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
我們建立 Intl.Segmenter 物件的新實例並將文字傳遞給它。我們將該輸出放入數組中,然後最後獲取長度,這比簡單地獲取原始字串的長度要準確得多。
結果如下:

簡短回答:我不知道。
我已經編程太久了,以至於無法自欺欺人地認為有一個簡單的答案。
但是 Intl.Segmenter 具有良好的瀏覽器支持,任何性能或內存限制都可以忽略不計。
我最好的猜測是程式碼庫太大而且太舊,不值得重構的副作用。
如果有人對此有更深入的了解,我很樂意了解更多。
我希望這有幫助? .
編碼愉快? .
以上是如何在 JavaScript 中使用表情符號計算字串數量的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































