


編輯| ScienceAI
現代醫療保健系統會產生大量高維度臨床數據(HDCD),例如肺功能圖、光體積變化描記圖法(PPG)、心電圖(ECG) 記錄、CT 掃描和MRI 成像,這些數據無法用單一二進位或連續數字來概括。
了解我們的基因組與 HDCD 之間的關聯不僅可以提高我們對疾病的了解,而且對於疾病治療的發展也至關重要。
近日,Google Research 的基因組學團隊在利用 HDCD 來表徵疾病和生物學特徵方面取得了進展。
研究團隊提出了一種無監督深度學習模型,即低維嵌入基因發現的表示學習 (REGLE),用於發現基因變異與 HDCD 之間的關聯。
REGLE 作為一種新穎的基因發現方法,可以利用高維臨床數據中的隱藏信息,其計算效率高,不需要疾病標籤,並且可以整合來自專家定義知識的信息。
總體而言,REGLE 包含的臨床相關資訊超出了現有專家定義的特徵所捕獲的信息,從而可以改善基因發現和疾病預測。
相關研究以「Unsupervised representation learning on high-dimensional clinical data improves genomic discovery and prediction」為題,於 7 月 8 日發佈在《Nature Genetics Genetics》上。

https://www.nature.com/articles/s41588-024-01831-6
CD 中的隱藏訊息🜎種簡單方法是對每個資料座標執行 GWAS,例如,可以研究醫學影像中每個像素值的變化。這種方法計算成本高,並且由於鄰近座標之間的高相關性和大量的多重測試負擔,發現顯著關聯的能力較低。
一種更常用的方法是專注於從 HDCD 中提取的少量專家定義特徵 (Expert-defined Features,EDF) 作為 GWAS 的目標特徵或表型。 EDF 可以包括臨床上已知的特徵,例如肺量圖的用力肺活量 (FVC) 或 1 秒用力呼氣量 (FEV1)。
雖然這些 EDF 是專家發現的重要特徵,但假設它們可能無法全面捕捉 HDCD 中編碼的訊號,因此對這些訊號運行 GWAS 可能無法充分利用 HDCD 的潛力。
REGLE 旨在使用變分自動編碼器 (VAE) 模型克服這些限制。此方法包括三個主要步驟:
(1) 透過VAE 學習HDCD 的非線性、低維、解糾纏表示(即編碼或嵌入);
(2) 對每個編碼座標獨立進行GWAS;
(3) 使用來自編碼座標的多基因風險評分(PRS) 作為一般生物功能的遺傳評分,然後可能將這些評分組合起來為特定疾病或特徵創建PRS(給定少量疾病標籤)。
值得注意的是,REGLE 還允許在修改後的 VAE 架構中將相關 EDF 選擇性地包含在解碼器的輸入中,從而鼓勵編碼器僅學習 EDF 未表示的殘差訊號。

研究人員使用兩種高維臨床數據模式展示了REGLE 的功能:測量肺功能的肺量圖和測量心血管功能的PPG。兩者都可以在診所或消費者穿戴裝置中以非侵入性、相對便宜的方式收集,並且這兩種模式都有眾所周知的特徵)。
與具有相同維度的肺量圖和PPG 特徵的全基因組關聯研究相比,REGLE 對學習編碼的研究恢復了與肺和循環功能相關的大多數已知基因位點(loci),同時也檢測到了其他位點(例如,PPG 的重要位點增加了45%)。如果這些位點在進一步的分析和濕實驗室實驗中得到驗證,它們有可能成為新的藥物標靶。
多基因風險評分 (PRS) 是許多遺傳變異對特定特徵的估計影響的總結,以單一數字表示。透過對 REGLE 嵌入進行全基因組關聯研究創建的 PRS 可以僅使用少量疾病標籤進行組合,以產生針對該特定疾病的 PRS。
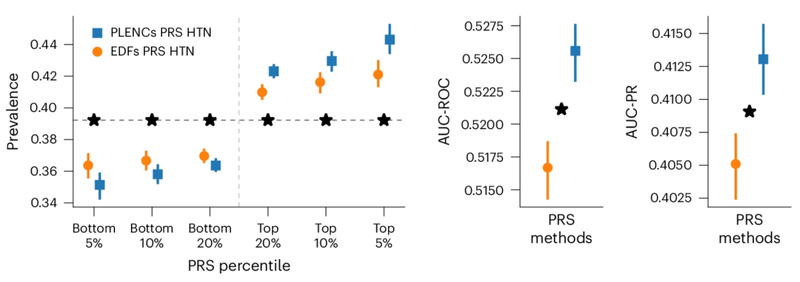
연구자들은 폐활량 측정 코딩으로 생성된 폐 기능 PRS가 전문가 정의 기능, PCA, PRS 등 기존 방법에 비해 COPD 및 천식 예측을 개선하고 위험 스펙트럼의 양쪽 끝에서 기능 PRS보다 성능이 뛰어난 것을 관찰했습니다. 위험 그룹을 보다 효율적으로 계층화합니다. 천식 및 COPD에 대한 여러 독립 데이터 세트(COPDGene, eMERGE III, Indiana Biobank 및 EPIC-Norfolk) 전반에 걸쳐 여러 지표(AUC-ROC, AUC-PR 및 Pearson 상관 관계)에서 통계적으로 유의미한 개선이 다음과 같이 표시됩니다.

마찬가지로 PPG의 REGLE 임베딩에서 파생된 PRS는 고혈압 및 수축기 혈압(SBP) 예측을 향상시킵니다. PPG 인코딩 및 PPG 서명에 의해 생성된 고혈압 및 SBP PRS는 3개의 독립적인 데이터세트(COPDGene, eMERGE III 및 EPIC-Norfolk)와 영국 Biobank 보유 테스트 세트에서 평가되었습니다.
여러 데이터세트에서 고혈압과 SBP 모두에 대해 전문가가 정의한 기능의 PRS를 사용하는 것보다 PPG 코딩의 PRS를 사용하는 일관된 개선 추세가 있는 것으로 관찰되었습니다.

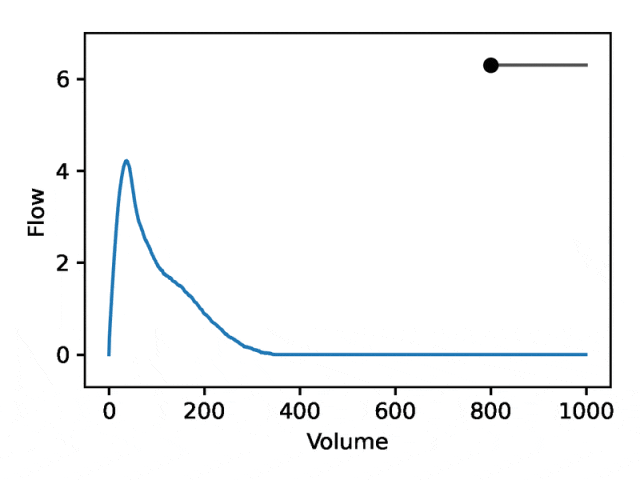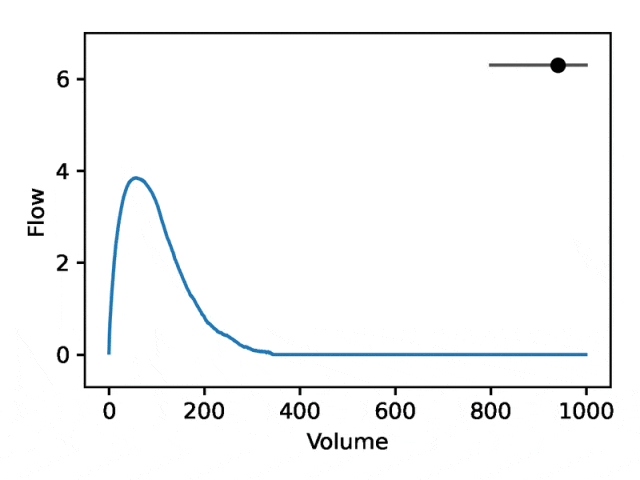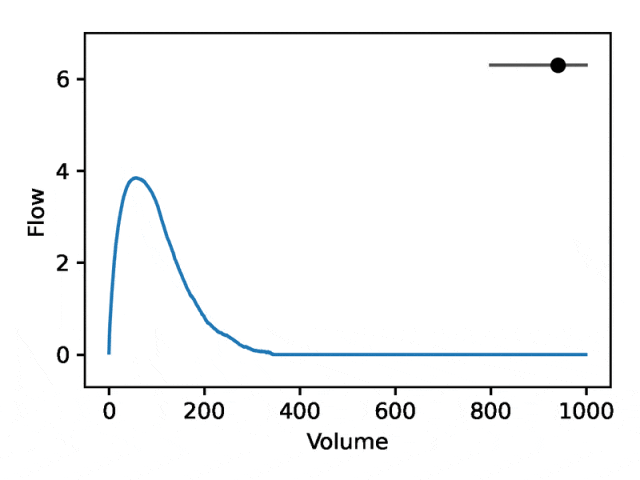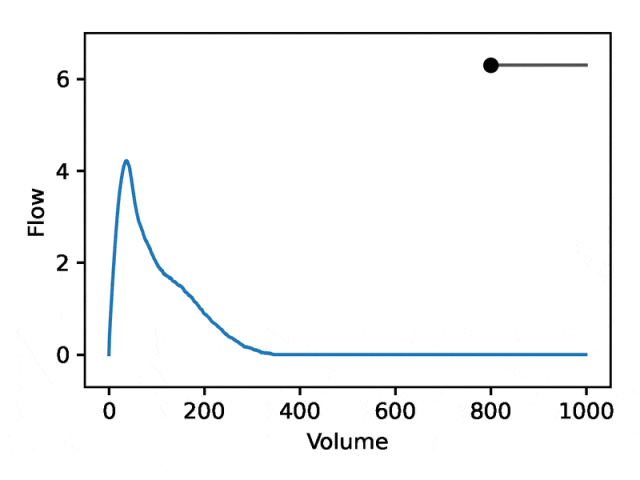
REGLE의 생성 속성을 활용하여 전문가가 정의한 기능의 값을 고정하고 다른 인코딩 좌표를 유지하면서 하나의 인코딩 좌표를 변경함으로써 폐활량 측정에 대한 인코딩 좌표의 효과를 연구합니다. 인코딩 좌표는 0입니다. 그런 다음 훈련된 모델의 디코더 부분만 사용하여 해당 폐활량 측정 맵이 생성됩니다.
일반적인 유량-체적 폐활량 측정은 두 가지 별개의 부분으로 구성됩니다. (1) 유량이 증가함에 따라 단조롭게 증가하는 최대 유량에 도달하는 상대적으로 짧은 섹션, (2) 유량이 감소하는 폐활량 측정 섹션의 주요 부분 단조롭게.
아래 이미지는 첫 번째 좌표를 변경하는 것이 첫 번째 부분을 상대적으로 고정한 상태에서 두 번째 부분(음의 기울기)을 확장하거나 축소하는 것과 동일함을 보여줍니다. 실제로, 폐질환 전문의가 딥(dip)이라고 부르는 곡선의 두 번째 부분에 있는 오목함은 표준 EDF로 잘 표현되지 않는 기도 폐쇄의 지표입니다.
REGLE은 유전자 분석, 향상된 새로운 유전자좌 발견 및 위험 예측을 수행하는 비지도 학습 방법입니다. EDF는 대규모로 수동으로 발견하기 어렵기 때문에 HDCD 표현에 대한 비지도 학습은 게놈 발견에 매력적입니다.
REGLE 프레임워크는 기존 VAE 아키텍처를 수정하여 모델링에서 이러한 기능의 원칙적인 사용을 지원합니다. REGLE은 임상 환경에서 일상적으로 측정하거나 스마트폰이나 웨어러블 장치를 통해 수동적 및 비침습적으로 측정할 수 있는 두 가지 임상 데이터 방식(폐활량 측정법 및 PPG)으로 입증됩니다.
REGLE은 레이블이 지정된 데이터 없이 기관 기능에 대한 유전적 영향을 식별하는 메커니즘을 제공하고 전문가 기능을 모델에 통합할 수 있도록 합니다. 또한 몇 가지 레이블을 사용하여 질병 및 특성별 PRS를 생성하는 방법을 제공합니다. 앞으로 이와 같은 접근법은 인간의 특성과 질병의 유전적 기초를 더욱 밝히기 위해 점점 더 많이 사용될 것입니다.
참고 내용: https://research.google/blog/harnessing-hidden-genetic-information-in-clinical-data-with-regle/
以上是效率高,無標籤,Google團隊用AI挖掘臨床數據,改善基因發現與疾病預測,登Nature子刊的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















