

四大 VLM,竟都在盲人摸象?
讓現在最火熱的 SOTA 模型們(GPT-4o,Gemini-1.5,Sonnet-3,Sonnet-3.5)數一數兩條線有幾個交點,他們表現會比人類好嗎?
答案很可能是否定的。
自 GPT-4V 推出以來,視覺語言模型 (VLMs) 讓大模型的智慧程度朝著我們想像中的人工智慧水準躍升了一大步。
VLMs 既能看懂畫面,又能用語言來描述看到的東西,並基於這些理解來執行複雜的任務。例如,給 VLM 模型發去一張餐桌的圖片,再發一張菜單的圖片,它就能從兩張圖中分別提取啤酒瓶的數量和菜單上的單價,算出這頓飯買啤酒花了多少錢。
VLMs 的進步如此之快,以至於讓模型找出這張圖中有沒有一些不合常理的“抽像元素”,例如,讓模型鑑定圖中有沒有一個人正在飛馳的出租車上熨衣服,成為了一種通行的測評方式。

然而,目前的基準測試集並不能很好地評估 VLMs 的視覺能力。以 MMMU 為例,其中有 42.9% 的問題不需要看圖,就能解決,也就是說,許多答案可以只透過文字問題和選項推斷出來。其次,現在 VLM 展現的能力,很大程度上是「背記」大規模網路數據的結果。這導致了 VLMs 在測試集中的得分很高,但這並不代表這個判斷成立:VLM 可以像人類一樣感知圖像嗎?
為了得到這個問題的答案,來自奧本大學和阿爾伯塔大學的研究者決定給 VLMs「測測視力」。從驗光師的「視力測試」處得到了啟發,他們讓:GPT-4o、Gemini-1.5 Pro 、Claude-3 Sonnet 和 Claude-3.5 Sonnet 這四款頂級 VLM 做了一套「視力測試題」。

論文標題:Vision language models are blind
論文連結:https://arxiv.org/pdf/2407.065811381
VLM 瞎不瞎?七大任務,一測便知
為了避免 VLMs 從網路資料集中直接「抄答案」,論文作者設計了一套全新的「視力測試」。論文作者選擇讓 VLMs 判斷空間中幾何圖形之間的關係,例如兩個圖形是否相交。因為這些圖案在白色畫布上的空間訊息,通常無法用自然語言描述。
人類在處理這些資訊時,將透過「視覺大腦」感知。但對於 VLMs 來說,它們所依賴的是在模型的初期階段將圖像特徵和文字特徵結合起來,將視覺編碼器整合到大型語言模型中,這本質上是一個沒有眼睛的知識大腦。 初步實驗表明,VLMs 在面對人類視力測試,例如我們每個人都測過的顛倒倒去的「E」視力表等等,它們的表現已經非常驚艷。檢定與結果
第一關:數一數線條之間有幾個交點?
論文作者在白色背景上創建了 150 幅含有兩條線段的圖像。這些線段的 x 座標固定並等間距分佈,而 y 座標則是隨機產生的。兩條線段之間的交點只有 0 個、1 個、2 個三種情況。
如圖 5 所示,在兩版提示詞和三版線段粗細不同的測試中,所有 VLMs 在這個簡單任務上表現都不佳。 
擁有最佳準確率的 Sonnet-3.5 也僅 77.33%(見表 1)。 
更具體地說,當兩條線之間的距離縮小時,VLMs 的表現往往更差(見下方圖 6)。由於每個線圖由三個關鍵點組成,因此兩條線之間的距離計算為三個對應點對的平均距離。 

該結果與 VLMs 在 ChartQA 上的高準確率形成鮮明對比,這表明 VLMs 能夠識別線圖的整體趨勢,但無法“放大”以看到類似於“哪些線條相交了”這種細節。
第二關:判斷兩個圓之間的位置關係
如圖所示,論文作者在一個給定大小的畫布上,隨機產生兩個大小一致的圓。兩個圓的位置關係只有三種情況:相交、相切、相離。 
令人驚訝的是,在這個對人類來說直觀可見,一眼就能看出答案的的任務中,沒有一個 VLM 能夠完美地給出答案(見圖 7)。

準確率最佳(92.78%)的模型是 Gemini-1.5(見表 2)。

在實驗中,有一種情況頻繁出現:當兩個圓靠得很近時,VLMs 往往表現不佳,但會做出有根據的推測。如下圖所示,Sonnet-3.5 通常保守地回答「否」。

如圖8 所示,即使當兩個圓之間的距離相差得很遠,有一個半徑(d = 0.5)這麼寬時,準確率最差的GPT-4o 也做不到100 % 準確。
也就是說,VLM 的視覺似乎不夠清晰,無法看到兩個圓之間的細小間隙或交點。

第三關:有幾個字母被紅圈圈起來了?
由於一個單字間字母之間的間隔很小,論文作者們假設:如果 VLMs「近視」,那麼它們是沒辦法識別出被紅圈圈出的字母的。
因此,他們選擇了「Acknowledgement」、「Subdermatoglyphic」和「tHyUiKaRbNqWeOpXcZvM」這樣的字串。隨機產生紅圈圈出字串中的某個字母,作為測試。

測試結果說明,被測模型在這一關的表現都很差(見圖 9 和表 3)。


例如,當字母被紅圈輕微遮擋時,視覺語言模型往往會出錯。它們經常混淆紅圈旁邊的字母。有時模型會產生幻覺,例如,儘管能夠準確拼寫單詞,但會在單詞中添加(例如,“9”,“n”,“©”)等亂碼。

除了 GPT-4o 之外,所有模型在單字上的表現都略好於隨機字串,這表明知道單字的拼字可能有助於視覺語言模型做出判斷,從而略微提高準確性。
Gemini-1.5 和 Sonnet-3.5 是排名前二的模型,準確率分別為 92.81% 和 89.22%,並且比 GPT-4o 和 Sonnet-3 的表現近乎高出近 20%。

第四關和第五關:重疊的圖形有幾個?有幾個「套娃」正方形?
假設 VLMs“近視”,那麼它們可能無法清晰地看到類似於“奧運五環”這樣的圖案,每兩個圓圈之間的交叉點。為此,論文作者隨機產生了 60 組類似於「奧運五環」的圖案,讓 VLMs 數一數它們重疊的圖形有幾個。他們也產生了五邊形版的「奧運五環」進一步測試。

由於 VLMs 計算相交圓圈的數量時表現不佳,論文作者進一步測試了當圖案的邊緣不相交,每個形狀完全嵌套在另一個形狀內部的情況。他們用 2-5 方塊產生了「套娃」式的圖案,並讓 VLMs 計算影像中的方格總數。

從下表中鮮紅的叉號不難看出,這兩關對於 VLMs 來說,也是難以逾越的障礙。

在嵌套正方形的測試中,各個模型的準確率差異很大:GPT-4o(準確率48.33%)和Sonnet-3(準確率55.00%)這兩種模型至少比Gemini-1.5 (準確率80.00%)和Sonnet-3.5(準確率87.50%)低30 個百分點。
這種差距在模型計數重疊的圓形和五邊形時則會更大,不過 Sonnet-3.5 的表現要比其他模型好上幾倍。如下表所示,當影像為五邊形時,Sonnet-3.5 以 75.83% 的準確率遠超 Gemini-1.5 的 9.16%。
令人驚訝的是,被測的四個模型在數 5 個圓環時都達到了 100% 的準確率,但僅僅額外添加一個圓環就足以使準確率大幅下降到接近零的水平。
然而,在計算五邊形時,所有 VLM(除 Sonnet-3.5 外)即使在計算 5 個五邊形時也表現不佳。 整體來看,計算 6 到 9 個形狀(包括圓形和五邊形)對所有模型來說都是困難的。

這表明,VLM 存在偏見,它們更傾向於輸出著名的「奧運五環」作為結果。例如,無論實際圓的數量是多少,Gemini-1.5 都會在 98.95% 的試驗中將結果預測為「5」(見表 5)。對於其他模型,這種圓環預測錯誤出現的頻率也遠高於五邊形的情況。

除了數量外,VLM 在形狀的顏色上也有不同的「偏好」。
GPT-4o 在彩色形狀上的表現優於純黑的形狀,而 Sonnet-3.5 隨著影像尺寸的增加預測的表現越來越好。然而,當研究人員改變顏色和影像解析度時,其他模型的準確率僅略有變化。
值得注意的是,在計算嵌套正方形的任務中,即使正方形的數量只有 2-3 個,GPT-4o 和 Sonnet-3 依然很難計算。當正方形的數量增加到四個和五個時,所有模型都遠未達到 100% 的準確率。這表明,即使形狀的邊緣不相交,VLM 也很難準確地提取目標形狀。

第六關:數一數表格有幾行?有幾列?
雖然 VLMs 在重疊或嵌套圖形時遇到了困難,但它們眼中的平鋪圖案又是怎樣的呢?在基礎測試集中,特別是包含許多含有表格任務的 DocVQA,被測模型的準確率都≥90%。論文作者隨機產生了 444 個行數列數各異的表格,讓 VLMs 數一數表格有幾行?有幾列?
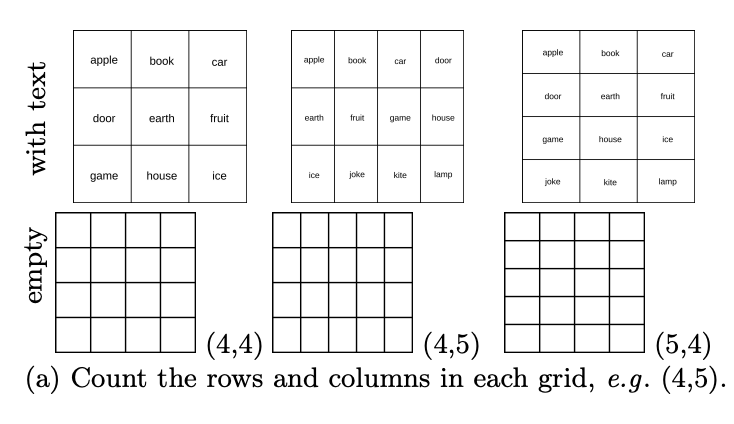
結果顯示,雖然在基礎資料集中拿到了高分,但如下圖所示,VLM 在計數空白表格中的行和列也表現不佳。

具體來說,它們通常會存在 1-2 格的偏差。如下圖所示,GPT-4o 把 4×5 的網格認成了 4×4,Gemini-1.5 則認成了 5×5。

這表明,雖然 VLMs 可以從表格中提取重要內容以回答 DocVQA 中的表格相關問題,但無法清晰地逐格識別表格。
這可能是因為文件中的表格大多是非空的,而 VLM 不習慣空表格。有趣的是,在研究人員透過嘗試在每個單元格中添加一個單字來簡化任務後,觀察到所有VLM 的準確率顯著提高,例如,GPT-4o 從26.13% 提高到了53.03%(見表6 ) 。然而,在這種情況中,被測模型的表現依舊不完美。如圖 15a 和 b 所示,表現最好的模型(Sonnet-3.5)在包含文字的網格中表現為 88.68%,而在空網格中表現為 59.84%。
而大多數模型(Gemini-1.5、Sonnet-3 和 Sonnet-3.5)在計算列數方面的表現始終優於計算行數(見圖 15c 和 d)。

第七關:從出發點到目的地,有幾條地鐵直達線路?
這項測試檢測的是 VLMs 跟隨路徑的能力,這對於模型解讀地圖、圖表以及能否理解用戶在輸入的圖片中添加的箭頭等標註至關重要。為此,論文作者隨機產生了 180 張地鐵線圖,每張圖有四個固定的站點。他們要求 VLMs 計算兩個網站之間有多少單色的路徑。

測試結果令人震驚,即使把兩個站點之間的路徑簡化到只有一條,所有模型也無法達到 100% 的準確率。如表 7 所示,表現最好的模型是 Sonnet-3.5,準確率為 95%;最差的模型是 Sonnet-3,準確率為 23.75%。

從下圖不難看出,VLM 的預測通常會有 1 到 3 條路徑的偏差。隨著地圖複雜度從 1 條路徑增加到 3 條路徑,大多數 VLM 的表現都變得更差。

面對當今主流 VLM 在圖像識別上表現極差這一“無情事實”,眾多網友先是拋開了自己“AI 辯護律師”的身份,留下了很多較為悲觀的評論。
一位網友表示:「SOTA 模型們(GPT-4o,Gemini-1.5 Pro,Sonnet-3,Sonnet-3.5)表現得如此糟糕真是令人尷尬,而這些模型居然在宣傳時還聲稱:它們可以理解圖像?大約100,000 個範例,並用真實資料進行訓練,這樣問題就解決了。存在極難調和的事實缺陷。
論文作者也收到了對更多這個測驗是否科學的質疑。 

實際上,這些視覺語言模型(VLMs)在處理這類任務時所面臨的挑戰,可能更多地與它們的推理能力和對圖像內容的解釋方式有關,而不僅僅是視覺分辨率的問題。換句話說,即使圖像的每個細節都清晰可見,如果模型缺乏正確的推理邏輯或對視覺訊息的深入理解,它們仍然可能無法準確地完成這些任務。因此,這項研究可能需要更深入地探討 VLMs 在視覺理解和推理方面的能力,而不僅僅是它們的影像處理能力。
還有網友認為,如果人類的視覺經過卷積處理,那麼人類本身也會在判斷線條交點的測試中遇到困難。
更多信息,請參考原論文。
參考連結:
https://arxiv.org/pdf/2407.06581
機機.472345032532 月
https://vlmsareblind.github.io/
以上是這些VLM竟都是盲人? GPT-4o、Sonnet-3.5相繼敗於「視力」測試的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















