AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者來自上海交通大學,清華大學,劍橋大學和上海人工智慧實驗室。一作陳哲為上海交通大學博一學生,師從上海交通大學人工智慧學院王缽教授。通訊作者為王缽教授(首頁:https://yuwangsjtu.github.io/)與清華大學電子工程系張超教授(首頁:https://mi.eng.cam.ac.uk/~cz277)。 
- 論文連結:https://arxiv.org/abs/2403.14168
-
計畫首頁:https://jack-zc8.github./page 論文標題:M3AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
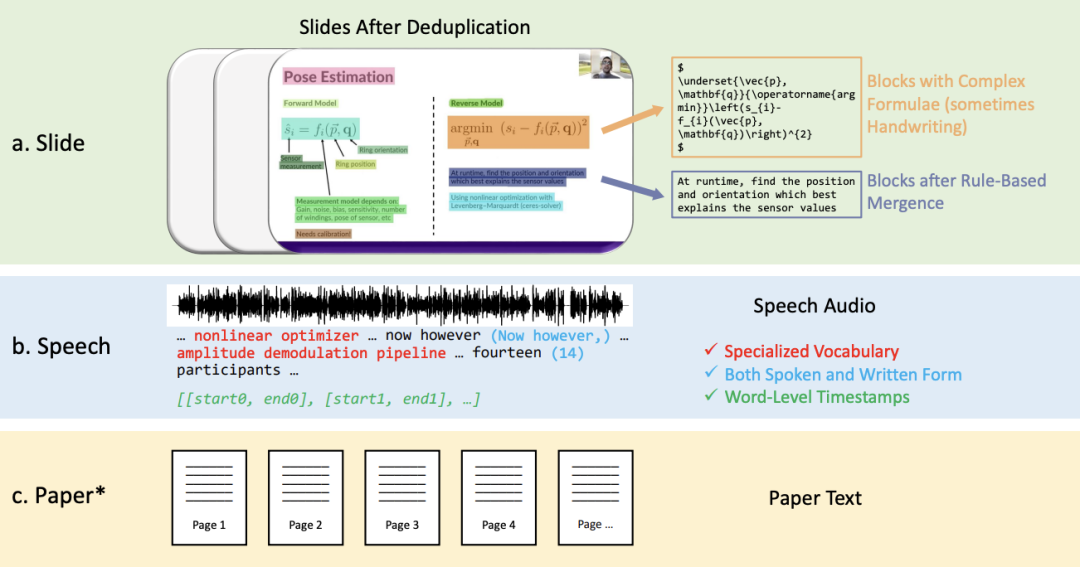
的方法。這些影片包含豐富的多模態訊息,包括演講者的語音、面部表情和身體動作,幻燈片中的文字和圖片,和對應的論文文字訊息。目前很少有資料集能夠同時支援多模態內容識別和理解任務,部分原因是缺乏高品質的人工標註。
該工作提出了一個新的多模態、多類型、多用途的視聽學術演講數據集(M3AV),它包含來自五個來源的近367 小時的視頻,涵蓋計算機科學、數學、醫學和生物學主題。憑藉高品質的人工標註,特別是高價值的命名實體,資料集可以用於多種視聽識別和理解任務。在情境語音辨識、語音合成以及幻燈片和腳本生成任務上進行的評估表明,M3AV 的多樣性使其成為一個具有挑戰性的資料集。目前該工作已被 ACL 2024 主會接收。
M3AV 資料集主要由以下幾個部分組成:
關係進行合併。
2. 口語和書面形式的,包含特殊詞彙以及單字級時間戳的語音轉寫文本。
3. 影片對應的論文文本。
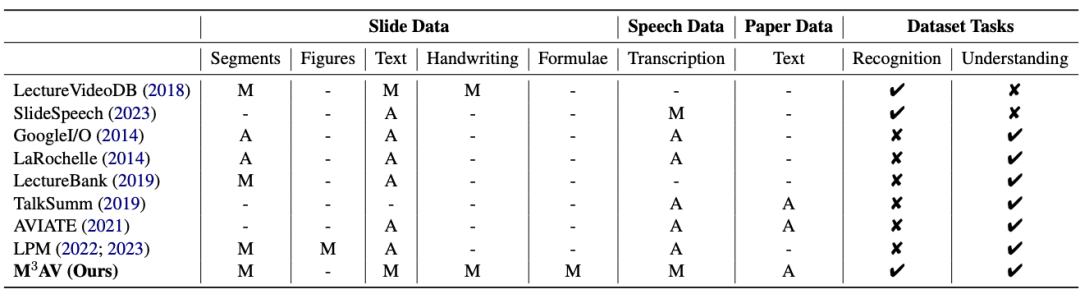
從下表可以看出,M3AV 資料集包含
最多人工標註的幻燈片、語音和論文資源,因此不僅支持多模態內容的識別任務,還支持高級學術知識的理解任務。
同時,M3AV 資料集在各方面與其他學術資料集相比,內容較為豐富,同時也是可存取的資源。
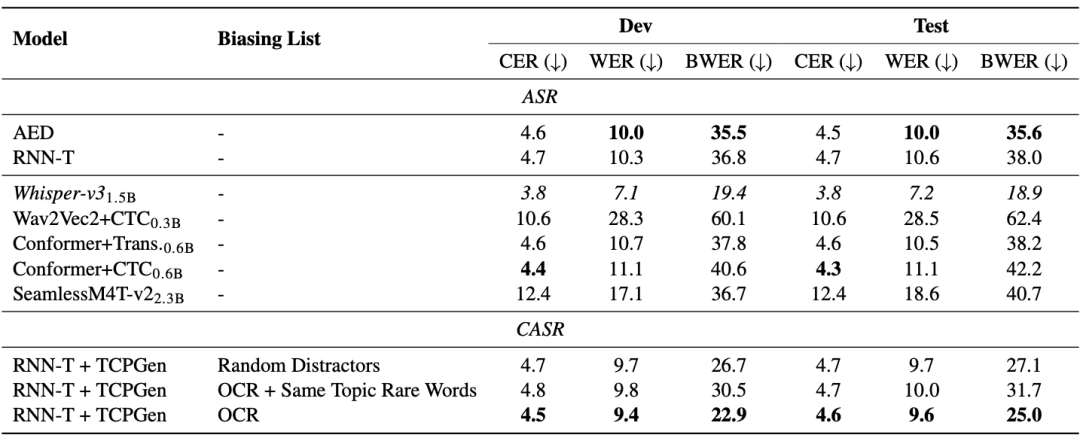
M3AV 資料集在多模態感知與理解方面設計了三個任務,分別是基於上下文的語音識別、自發風格的語音合成、幻燈片與腳本生成。 一般的端到端模型在稀有詞辨識上有問題。從下表的 AED 和 RNN-T 模型可以看出,稀有詞詞錯率(BWER)與全部詞錯率(WER)相比,增加了兩倍以上。透過使用 TCPGen 利用 OCR 資訊來進行基於上下文的語音識別,RNN-T 模型在開發和測試集上的 BWER 分別有相對 37.8% 和 34.2% 的降低。
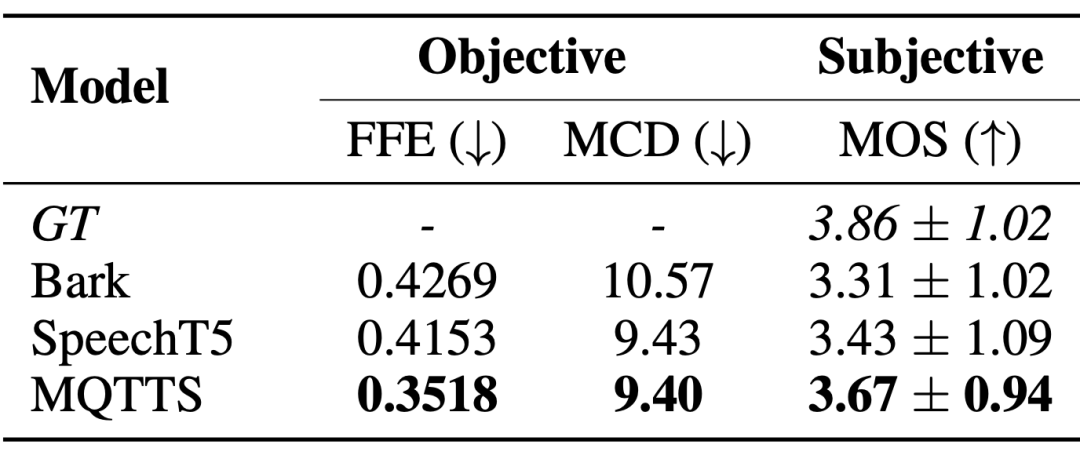
自發風格的語音合成系統迫切地需求真實場景下的語音數據,以產生更接近自然會話模式的語音。論文作者引入了 MQTTS 作為實驗模型,可以發現與各個預訓練模型相比,MQTTS 的各項評估指標最佳。這表明 M3AV 資料集中的真實語音可以驅動 AI 系統模擬出更自然的語音。
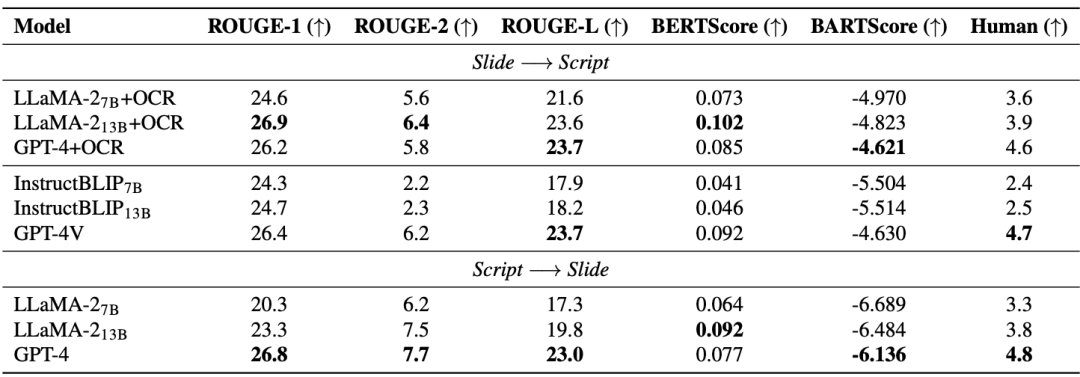
幻燈片和腳本生成(SSG)任務旨在快速處理AI 模型理解和重建先進的更新迭代的學術資料,有效地進行學術研究。 從下表可以看出,開源模型(LLaMA-2, InstructBLIP)在從 7B 提升到 13B 時,效能提升有限,落後於閉源模型(GPT-4 和 GPT-4V)。因此,除了提升模型尺寸,論文作者認為還需要有高品質的多模態預訓練資料。值得注意的是,先進的多模態大模型(GPT-4V)已經超過了由多個單模態模型組成的級聯模型。
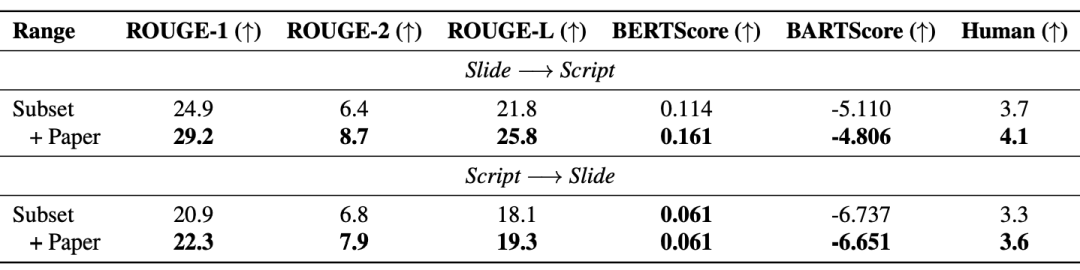
此外,檢索增強生成(RAG)有效提升了模型性能:下表顯示,引入的論文文本同時提升了生成的幻燈片與腳本的品質。
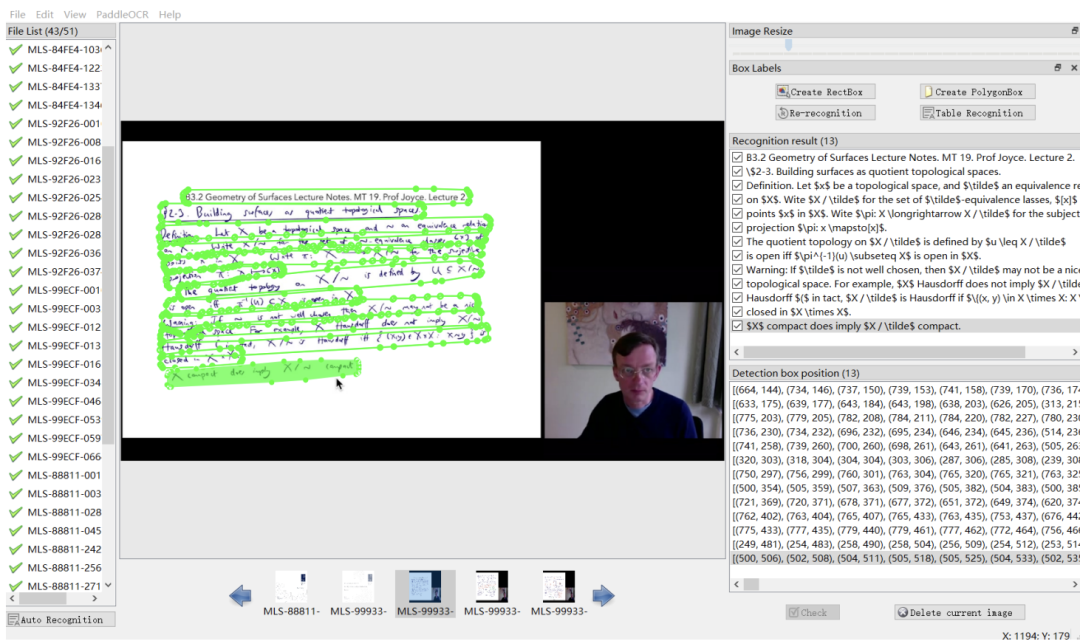
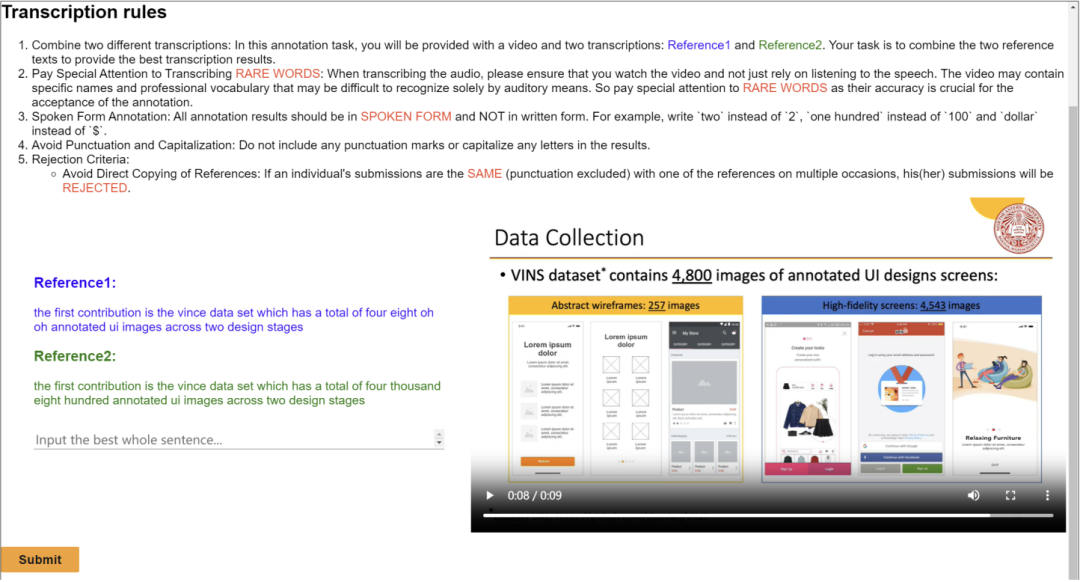
這篇工作發布了涵蓋多個學術領域的多模態、多類型、多用途視聽資料集(M3AV)。該資料集包含人工標註的語音轉錄、幻燈片和額外提取的論文文本,為評估 AI 模型識別多模態內容和理解學術知識的能力提供了基礎。論文作者詳細介紹了創建流程,並對該資料集進行了各種分析。此外,他們建立了基準並圍繞數據集進行了多項實驗。最終,論文作者發現現有的模型在感知和理解學術演講影片方面仍有較大的提升空間。 部分標註介面
以上是ACL 2024 | 引領學術視聽研究,上海交大、清華大學、劍橋大學、上海AILAB聯合發布學術視聽資料集M3AV的詳細內容。更多資訊請關注PHP中文網其他相關文章!