AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
##目前主流的視覺語言模型(VLM)主要基於大語言模型( LLM)進一步微調。因此需要透過各種方式將圖像映射到 LLM 的嵌入空間,然後使用自回歸方式根據圖像 token 預測答案。
在這個過程中,
模態的對齊是透過文字 token 隱式實現的,如何做好這一步的對齊非常關鍵。 針對這個問題,武漢大學、位元組跳動豆包大模型團隊和中國科學院大學的研究人員提出了一種
基於對比學習的文本token篩選方法(CAL),從文字中篩選出與影像高度相關的token,並加強其損失函數權重,從而實現更精準的多模態對齊。
- 論文連結:https://arxiv.org/pdf/2405.17871
- 程式碼連結:https://github.com/foundation-multimodal-models/CAL
#CAL 有以下幾個亮點:
- 可以直接嵌套到訓練過程,無需額外預訓練階段。
- 在 OCR 和 Caption benchmarks 上獲得了明顯的提升,從視覺化中可以發現 CAL 使得圖片模態對齊效果更好。
- CAL 使得訓練過程對雜訊資料抵抗能力更強。
##目前視覺語言模型依賴圖片模態的對齊,如何做好對齊非常關鍵。目前主流的方法是透過文字自回歸的方式進行隱式對齊,但是每個文字 token 對圖像對齊的貢獻是不一致的,對這些文字 token 進行區分是非常有必要的。
-
CAL 提出,在現有的視覺語言模型(VLM)訓練資料中,文字token 可以被分為三類:
-
:如實體(例如人、動物、物件)、數量、顏色、文字等。這些 token 與影像資訊直接對應,對多模態對齊至關重要。
-
:如承接詞或可以透過前文推論出的內容。這些 token 其實主要是在訓練 VLM 的純文字能力。
 與圖片內容相悖的文字
與圖片內容相悖的文字
:這些 token 與圖像訊息不一致,甚至可能提供誤導訊息,對多模態對齊過程產生負面影響。 ##################### 圖片中:綠色標記為與圖片高度相關#token,紅色為中性內容相悖,無色為中性為#token,紅色為中性內容相悖,無色為中性##11
在訓練過程中,後兩類token 整體而言實際上佔據了較大比例,但由於它們並不強依賴於圖片,對圖片的模態對齊作用不大。因此,為了實現更好的對齊,需要加大第一類文字 token,也就是與圖片高度相關部分 token 的權重。如何找出這一部分 token 成為了解決這個問題的關鍵。 #找出與圖片高度相關token這個問題可以透過condition contrastive 的方式來解決。
- 對於訓練資料中的每個圖文對,在沒有圖片輸入的情況下,每個文字token 上的logit 代表LLM基於上下文情況和已有知識對這種情況出現的估計值。
- 如果在前面添加圖片輸入,相當於提供額外的上下文信息,這種情況下每個 text token 的 logit 會基於新的情況進行調整。這兩種情況的 logit 變化量代表著圖片這個新的條件對每個文字 token 的影響大小。
具體來說,在訓練過程中,CAL 將圖文序列和單獨的文字序列分別輸入到大語言模型(LLM)中,得到每個文字token 的logit。透過計算這兩種情況下的 logit 差值,可以衡量圖片對每個 token 的影響程度。 logit 差值越大,表示圖片對該 token 的影響越大,因此該 token 與圖像越相關。下圖展示了文字 token 的 logit diff 和 CAL 方法的流程圖。 圖二:左圖為兩個情境中的流程的視覺化,右圖為可視化,右圖為可視化方法為視覺化方法為視覺化方法為視覺化方法為視覺化,為右圖為「可視化方法」的為視覺化,右圖為視覺化方法為視覺化,為視覺化方法為視覺化方法為視覺化,為視覺化方法為視覺化,為右圖為可視覺化方法的為視覺化,為視覺化是視覺化方法為視覺化方式為視覺化方式為視覺化方式為視覺化方式為視覺化方式為視覺化方式為視覺化方式為視覺化方式為視覺化方式為視覺化方法的右圖為視覺化,為右邊是視覺化方式為##實驗
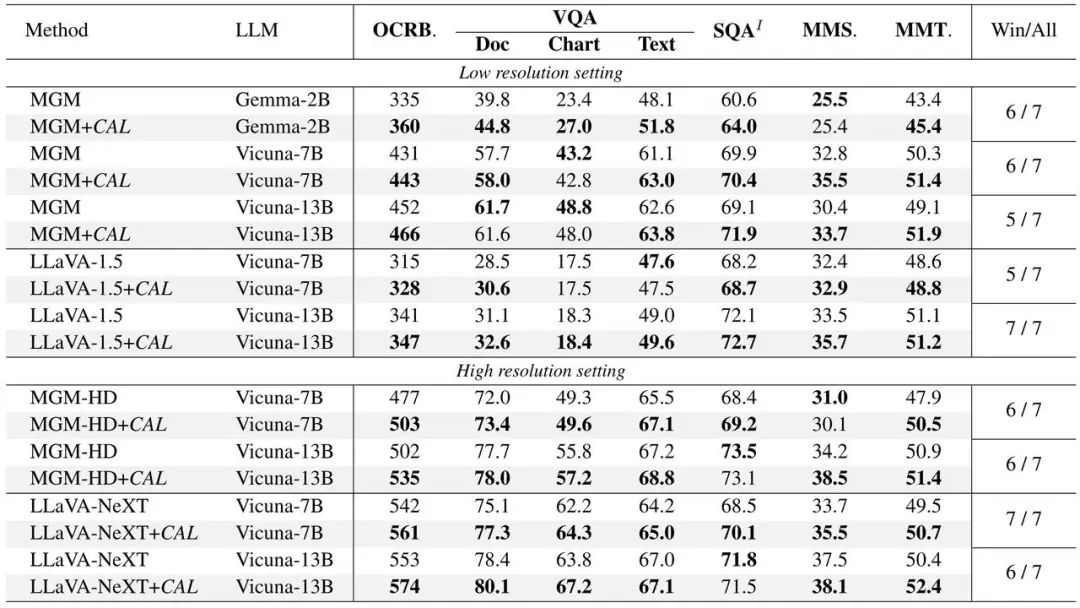
#CAL 在LLaVA 和MGM 兩個主流模型上進行了實驗驗證,在不同規模的模型下均實現了性能提升。
#(1)使用CAL 的模型在各項基準測試指標上表現更佳。 
#(2) 以比例隨機交換兩個圖文對中的文字來製造一批雜訊資料(圖文錯配),並用於模型訓練,CAL 使得訓練過程具有更強的資料抗噪效能。 圖三:在不同強度訓練噪聲情況下,CAL 與基線的性能表現
(3)對QA case 中的答案部分計算其與圖片token 的注意力分數分佈,並將其繪製在原圖上,CAL 訓練的模型擁有更清晰的注意力分佈圖。 圖四:基線與CAL 的attention map 可視化,每對中的右邊為CAL(4)將每個圖片token 映射為它最相似LLM 詞表中的文字token,將其繪製到原圖上,CAL 訓練的模型映射內容更接近圖片內容。  圖五:將image token 映射為最相似詞表token,並對應到原圖上#位元組跳動豆包大模型團隊成立於2023 年,致力於開發業界最先進的AI 大模型技術,成為世界級的研究團隊,為科技和社會發展做出貢獻。 豆包大模型團隊在AI 領域擁有長期願景與決心,研究方向涵蓋NLP、CV、語音等,在中國、新加坡、美國等地設有實驗室及研究職缺。團隊依托平台充足的數據、運算等資源,在相關領域持續投入,已推出自研通用大模型,提供多模態能力,下游支援豆包、釦子、即夢等50 + 業務,並透過火山引擎開放給企業客戶。目前,豆包 APP 已成為中國市場用戶量最大的 AIGC 應用程式。歡迎加入位元組跳動豆包大模型團隊。
圖五:將image token 映射為最相似詞表token,並對應到原圖上#位元組跳動豆包大模型團隊成立於2023 年,致力於開發業界最先進的AI 大模型技術,成為世界級的研究團隊,為科技和社會發展做出貢獻。 豆包大模型團隊在AI 領域擁有長期願景與決心,研究方向涵蓋NLP、CV、語音等,在中國、新加坡、美國等地設有實驗室及研究職缺。團隊依托平台充足的數據、運算等資源,在相關領域持續投入,已推出自研通用大模型,提供多模態能力,下游支援豆包、釦子、即夢等50 + 業務,並透過火山引擎開放給企業客戶。目前,豆包 APP 已成為中國市場用戶量最大的 AIGC 應用程式。歡迎加入位元組跳動豆包大模型團隊。 以上是字節豆包、武大提出 CAL:透過視覺相關的 token 增強多模態對齊效果的詳細內容。更多資訊請關注PHP中文網其他相關文章!