

考慮到這一點,我們創建了一個逐步指南,介紹如何使用 Text-Generation-WebUI 在電腦上本地加載量化的 Llama 2 LLM。
人們選擇直接運行 Llama 2 的原因有很多。有些是出於隱私考慮,有些是為了定制,有些是為了離線功能。如果您正在為您的專案研究、微調或整合 Llama 2,那麼透過 API 存取 Llama 2 可能不適合您。在PC上本地運行LLM的目的是減少對第三方AI工具的依賴,並隨時隨地使用AI,而不必擔心將潛在的敏感資料外洩給公司和其他組織。
話雖如此,讓我們從本地安裝 Llama 2 的逐步指南開始。
為了簡化操作,我們將使用 Text-Generation-WebUI 的一鍵安裝程式(用於透過 GUI 載入 Llama 2 的程式) 。但是,要使此安裝程式正常運作,您需要下載 Visual Studio 2019 建置工具並安裝必要的資源。
下載:Visual Studio 2019(免費)
繼續下載軟體的社群版。 現在安裝 Visual Studio 2019,然後開啟該軟體。開啟後,勾選「使用C++ 進行桌面開發」複選框並點選安裝。 。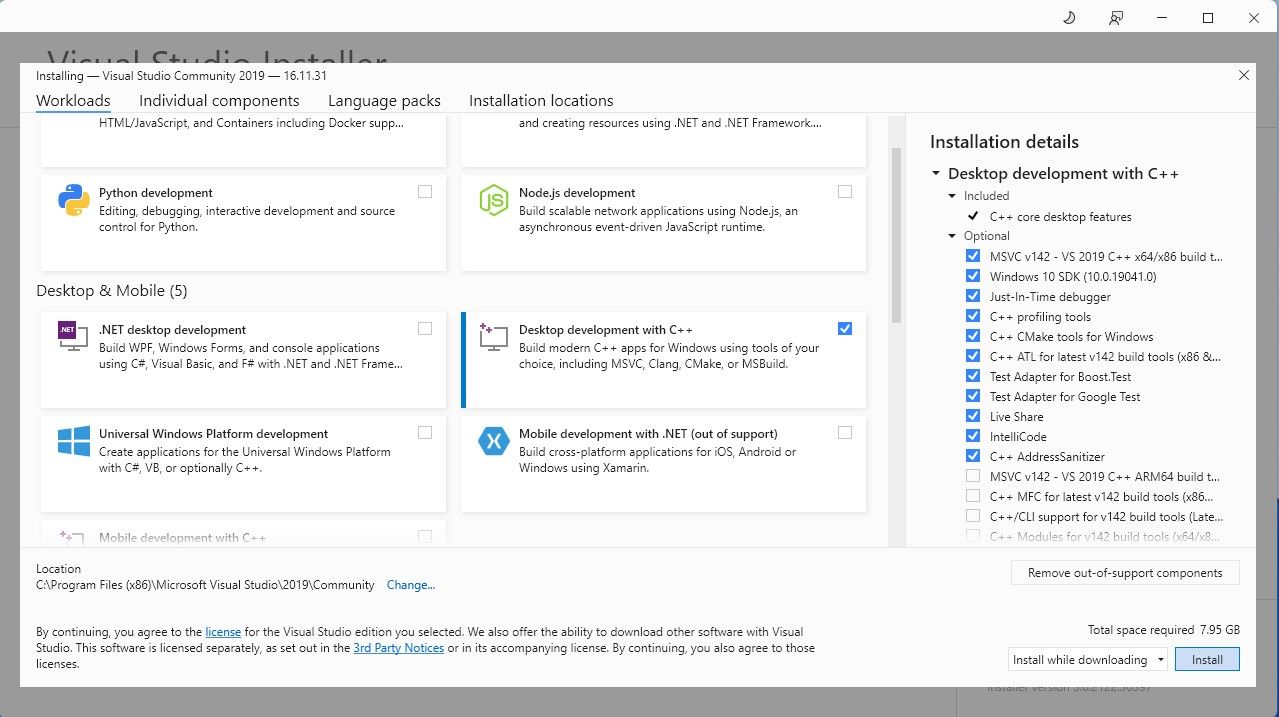
步驟2:安裝Text-Generation-WebUI
若要安裝腳本,請按一下“程式碼”>“下載一鍵安裝程式”下載 ZIP。
下載:Text-Generation-WebUI 安裝程式(免費)
下載後,將 ZIP 檔案解壓縮到您的首選位置,然後開啟解壓縮的資料夾。 在該資料夾中,向下捲動並尋找適合您的作業系統的啟動程序。透過雙擊相應的腳本來運行程式。如果您使用的是 Windows,則對於 MacOS 選擇 start_windows 批次文件,對於 Linux 選擇 start_macos shell script,對於 Linux 選擇 start_linux shell script。這可以。該提示只是運行批次檔或腳本的防毒誤報。仍然單擊“運行”。 終端將打開並開始設定。早些時候,安裝程式將暫停並詢問您正在使用什麼 GPU。選擇電腦上安裝的適當類型的 GPU,然後按 Enter 鍵。對於沒有專用顯示卡的,選擇無(我想在CPU模式下運行模型)。請記住,與使用專用 GPU 運行模型相比,在 CPU 模式下運行要慢得多。您可以透過開啟您喜歡的 Web 瀏覽器並在 URL 上輸入提供的 IP 位址來完成此操作。讓我們下載 Llama 2 以啟動模型載入器。 步驟 3:下載 Llama 2 模型
在決定您需要哪一個 Llama 2 版本時,需要考慮很多事情。其中包括參數、量化、硬體優化、大小和用法。所有這些資訊都可以在模型名稱中找到。
參數:用於訓練模型的參數數量。更大的參數可以產生更強大的模型,但會犧牲性能。用法:可以是標準的,也可以是聊天的。聊天模型經過最佳化可用作 ChatGPT 等聊天機器人,而標準模型是預設模型。硬體優化:指什麼硬體最能運行模型。 GPTQ 意味著模型針對在專用 GPU 上運行進行了最佳化,而 GGML 則針對在 CPU 上運行進行了最佳化。量化:表示模型中權重和活化的精確度。對於推理,q4 的精確度是最佳的。尺寸:指具體型號的尺寸。請注意,某些模型可能排列不同,甚至可能不顯示相同類型的信息。然而,這種類型的命名約定在 HuggingFace 模型庫中相當常見,因此仍然值得理解。

在此範例中,模型可以被識別為中型 Llama 2 模型,該模型使用專用 CPU 針對聊天推理進行了最佳化,並使用 130 億個參數進行訓練。
對於在專用 GPU 上運行的,選擇 GPTQ 模型,而對於使用 CPU 的,則選擇 GGML。如果您想像使用 ChatGPT 一樣與模型聊天,請選擇聊天,但如果您想試驗模型的全部功能,請使用標準模型。至於參數,要知道使用更大的模型會以犧牲性能為代價提供更好的結果。我個人建議您從 7B 型號開始。至於量化,請使用 q4,因為它僅用於推理。
下載:GGML(免費)
下載:GPTQ(免費)
既然您知道您需要什麼版本的 Llama 2,請繼續下載您想要的模型。
就我而言,由於我在超級本上運行此程序,因此我將使用針對聊天進行微調的 GGML 模型 llama-2-7b-chat-ggmlv3.q4_K_S.bin。
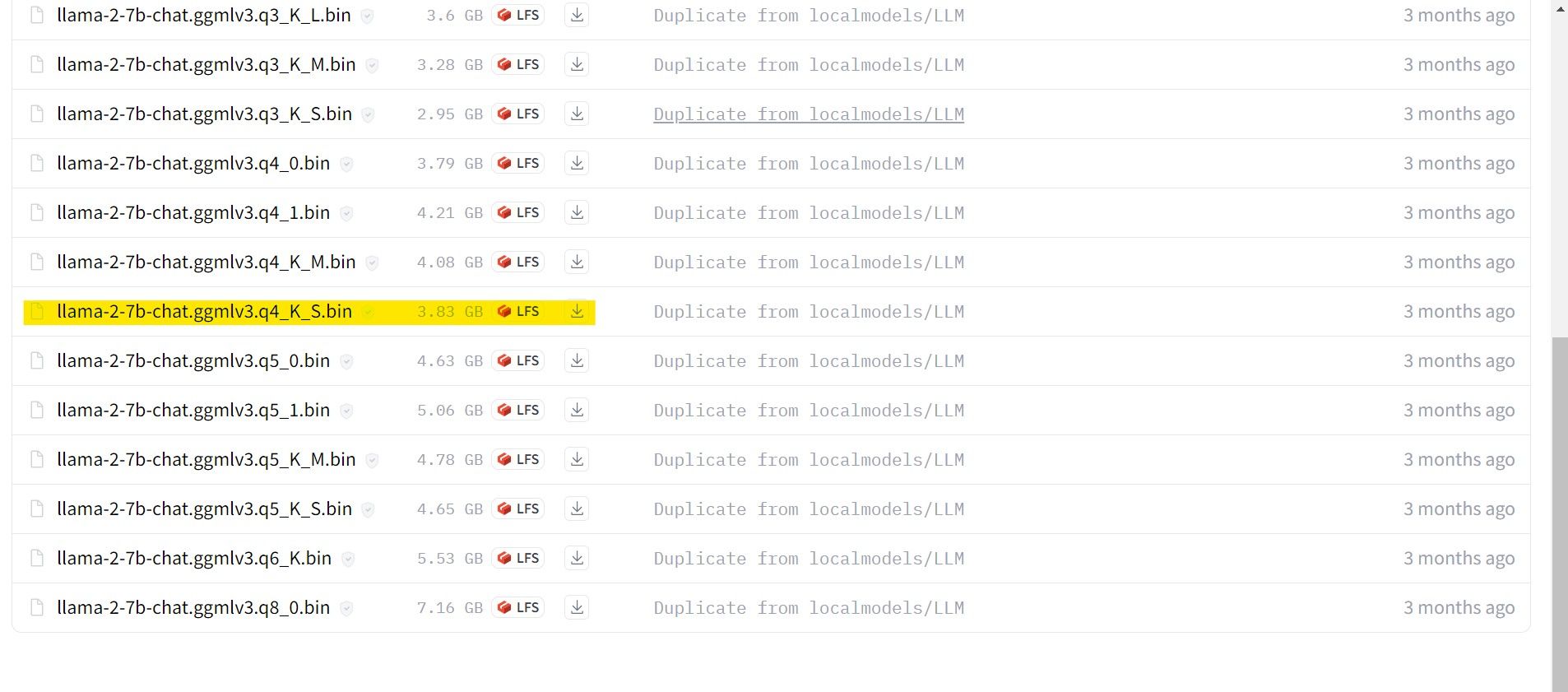
下載完成後,將模型放入text- Generation-webui-main >楷模。

現在您已下載模型並將其放置在模型資料夾中,是時候配置模型載入器了。
現在,讓我們開始設定階段。
再次透過執行 start_(您的作業系統)檔案開啟 Text-Generation-WebUI(請參閱上面的步驟)。 在 GUI 上方的標籤上,按一下模型。點擊模型下拉選單中的刷新按鈕並選擇您的模型。 現在點擊模型載入器的下拉式選單,並為使用 GTPQ 模型的使用者選擇 AutoGPTQ,為使用 GGML 模型的使用者選擇 ctransformers。最後,按一下「載入」以載入您的模型。加載Llama2!
 嘗試其他 LLM 既然您已經知道如何使用 Text-Generation-WebUI 直接在電腦上執行 Llama 2,那麼除了 Llama 之外,您還應該能夠運行其他 Llama。只需記住模型的命名約定,並且只有模型的量化版本(通常是 q4 精度)才能加載到常規 PC 上。 HuggingFace 上提供了許多量化的法學碩士。如果您想探索其他模型,請在 HuggingFace 的模型庫中搜尋 TheBloke,您應該會找到許多可用的模型。
嘗試其他 LLM 既然您已經知道如何使用 Text-Generation-WebUI 直接在電腦上執行 Llama 2,那麼除了 Llama 之外,您還應該能夠運行其他 Llama。只需記住模型的命名約定,並且只有模型的量化版本(通常是 q4 精度)才能加載到常規 PC 上。 HuggingFace 上提供了許多量化的法學碩士。如果您想探索其他模型,請在 HuggingFace 的模型庫中搜尋 TheBloke,您應該會找到許多可用的模型。
以上是如何在本地下載並安裝 Llama 2的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































