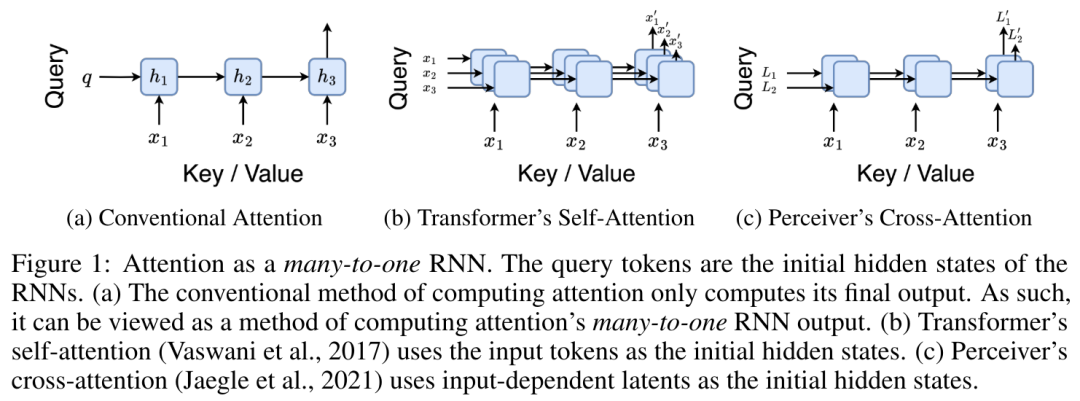
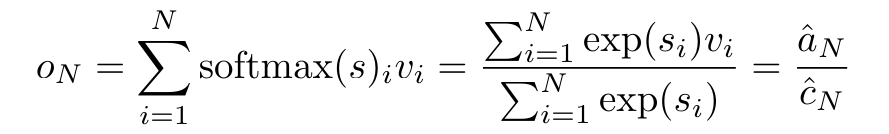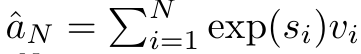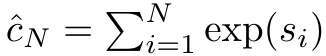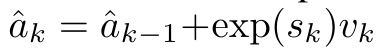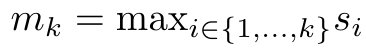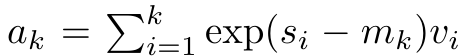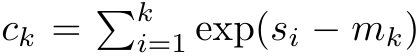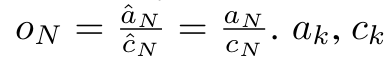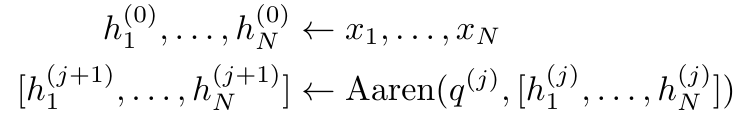序列建模的進展具有極大的影響力,因為它們在廣泛的應用中發揮著重要作用,包括強化學習(例如,機器人和自動駕駛)、時間序列分類(例如,金融詐欺檢測和醫學診斷)等。 在過去的幾年裡,Transformer 的出現標誌著序列建模中的一個重大突破,這主要得益於Transformer 提供了一種能夠利用GPU 並行處理的高性能架構。 然而,Transformer 在推理時計算開銷很大,主要在於記憶體和計算需求呈二次擴展,從而限制了其在低資源環境中的應用(例如,行動和嵌入式設備)。儘管可以採用 KV 快取等技術來提高推理效率,但 Transformer 對於低資源領域來說仍然非常昂貴,原因在於:(1)隨 token 數量線性增加的內存,以及(2)緩存所有先前的 token 到模型中。在具有長上下文(即大量 token)的環境中,這個問題對 Transformer 推理的影響更大。 為了解決這個問題,加拿大皇家銀行 AI 研究所 Borealis AI、蒙特利爾大學的研究者在論文《Attention as an RNN 》中給出了解決方案。值得一提的是,我們發現圖靈獎得主 Yoshua Bengio 出現在作者一欄裡。
- #論文網址:https://arxiv.org/ pdf/2405.13956
具體而言,研究者首先檢查了Transformer 中的注意力機制,這是導致Transformer 計算複雜度呈二次增長的元件。該研究表明注意力機制可以被視為一種特殊的循環神經網路(RNN),具有高效計算的多對一(many-to-one)RNN 輸出的能力。利用注意力的 RNN 公式,該研究展示了流行的基於注意力的模型(例如 Transformer 和 Perceiver)可以被視為 RNN 變體。 然而,與 LSTM、GRU 等傳統 RNN 不同,Transformer 和 Perceiver 等流行的注意力模型雖然可以被視為 RNN 變體。但遺憾的是,它們無法有效率地使用新 token 進行更新。 為了解決這個問題,該研究引入了一個基於平行前綴掃描(prefix scan)演算法的新的注意力公式,該公式能夠有效地計算注意力的多對多(many-to-many)RNN 輸出,從而實現高效的更新。 在此新註意力公式的基礎上,研究提出了Aaren([A] ttention [a] s a [re] current neural [n] etwork),這是一種運算效率很高的模組,不僅可以像Transformer 一樣並行訓練,還可以像RNN 一樣有效地更新。 實驗結果表明,Aaren 在38 個資料集上的表現與Transformer 相當,這些資料集涵蓋了四種常見的序列資料設定:強化學習、事件預測、時間序列分類和時間序列預測任務,同時在時間和記憶體方面更有效率。 #為了解決上述問題,作者提出了一個基於注意力的高效模組,它能夠利用GPU 並行性,同時又能有效率地更新。 首先,作者在第3.1 節中表明,注意力可被視為一種RNN,具有高效計算多對一RNN(圖1a)輸出的特殊能力。利用注意力的 RNN 形式,作者進一步說明,基於注意力的流行模型,如 Transformer(圖 1b)和 Perceiver(圖 1c),可以被視為 RNN。然而,與傳統的 RNN 不同的是,這些模型無法根據新 token 有效地更新自身,這限制了它們在資料以流的形式到達的序列問題中的潛力。 為了解決這個問題,作者在第3.2 節中介紹了一種基於平行前綴掃描演算法的多對多RNN 計算注意力的高效方法。在此基礎上,作者在第3.3 節中介紹了Aaren—— 一個計算效率高的模組,它不僅可以並行訓練(就像Transformer),還可以在推理時用新token 高效更新,推理只需要恆定的記憶體(就像傳統RNN)。查詢向量q 的注意力可視為一個函數,它透過N 個上下文token x_1:N 的鍵和值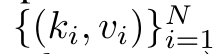 將其對應到單一輸出o_N = Attention (q, k_1:N , v_1:N ) 。給定s_i = dot (q,k_i),輸出o_N 可表述為:
將其對應到單一輸出o_N = Attention (q, k_1:N , v_1:N ) 。給定s_i = dot (q,k_i),輸出o_N 可表述為: 
#################################### #########其中分子為###,分母為###。將注意力視為 RNN,可以在 k = 1,...,...... 時,以滾動求和的方式迭代計算###和###。然而,在實踐中,這種實現方式並不穩定,會因有限的精度表示和可能非常小或非常大的指數(即 exp (s))而遇到數值問題。為了緩解這個問題,作者用累積最大值項### 來重寫遞推公式,計算###和###。值得注意的是,最終結果是相同的###,m_k 的迴圈計算如下:############
透過從a_(k-1)、c_(k-1) 和m_(k-1) 對a_k、c_k 和m_k 的循環計算進行封裝,作者引入了一個RNN 單元,它可以迭代計算注意力的輸出(見圖2)。注意力的 RNN 單元以(a_(k-1), c_(k-1), m_(k-1), q)為輸入,計算(a_k, c_k, m_k, q)。請注意,查詢向量 q 在 RNN 單元中被傳遞。注意力 RNN 的初始隱藏狀態為 (a_0, c_0, m_0, q) = (0, 0, 0, q)。  計算注意力的方法:透過將注意力視為一個RNN,可以看到計算注意力的不同方法:在O (1) 記憶體中逐個token 迴圈計算(即順序計算) ;或以傳統方式計算(即平行計算),需要線性O (N) 記憶體。由於注意力可以被看作是一個RNN,因此計算注意力的傳統方法也可以被看作是計算注意力多對一RNN 輸出的高效方法,即RNN 的輸出以多個上下文token 為輸入,但在RNN 結束時只輸出一個token(見圖1a)。最後,也可以將注意力計算為一個逐塊處理 token 的 RNN,而不是完全按順序或完全並行計算,這需要 O (b) 內存,其中 b 是區塊的大小。 將現有的注意力模型視為 RNN。透過將注意力視為 RNN,現有的基於注意力的模型也可以被視為 RNN 的變體。例如,Transformer 的自註意力是 RNN(圖 1b),而上下文 token 是其初始隱藏狀態。 Perceiver 的交叉注意力是 RNN(圖 1c),其初始隱藏狀態是與上下文相關的潛在變數。透過利用其註意力機制的 RNN 形式,這些現有模型可以有效地計算其輸出儲存。 然而,當將現有的基於注意力的模型(如Transformers)視為RNN 時,這些模型又缺乏傳統RNN(如LSTM 和GRU)中常見的重要屬性。 值得注意的是,LSTM 和GRU 能夠僅在O (1) 常數記憶體和計算中使用新token 有效地更新自身,相較之下, Transformer 的RNN 視圖(見圖1b)會透過將一個新的token 作為初始狀態新增一個新的RNN 來處理新token。這個新的 RNN 處理所有先前的 token,需要 O (N) 的線性計算量。 在Perceiver 中,由於其架構的原因,潛在變數(圖1c 中的L_i)是依賴輸入的,這意味著它們的值在接收新token時會發生變化。由於其 RNN 的初始隱藏狀態(即潛在變數)發生變化,Perceiver 因此需要從頭開始重新計算其 RNN,需要 O (NL) 的線性計算量,其中 N 是 token 的數量,L 是潛在變數的數量。 針對這些局限性,作者建議開發一種基於注意力的模型,利用RNN 公式的能力來執行高效更新。為此,作者首先引入了一種高效的平行化方法,將注意力作為多對多 RNN 計算,即並行計算
計算注意力的方法:透過將注意力視為一個RNN,可以看到計算注意力的不同方法:在O (1) 記憶體中逐個token 迴圈計算(即順序計算) ;或以傳統方式計算(即平行計算),需要線性O (N) 記憶體。由於注意力可以被看作是一個RNN,因此計算注意力的傳統方法也可以被看作是計算注意力多對一RNN 輸出的高效方法,即RNN 的輸出以多個上下文token 為輸入,但在RNN 結束時只輸出一個token(見圖1a)。最後,也可以將注意力計算為一個逐塊處理 token 的 RNN,而不是完全按順序或完全並行計算,這需要 O (b) 內存,其中 b 是區塊的大小。 將現有的注意力模型視為 RNN。透過將注意力視為 RNN,現有的基於注意力的模型也可以被視為 RNN 的變體。例如,Transformer 的自註意力是 RNN(圖 1b),而上下文 token 是其初始隱藏狀態。 Perceiver 的交叉注意力是 RNN(圖 1c),其初始隱藏狀態是與上下文相關的潛在變數。透過利用其註意力機制的 RNN 形式,這些現有模型可以有效地計算其輸出儲存。 然而,當將現有的基於注意力的模型(如Transformers)視為RNN 時,這些模型又缺乏傳統RNN(如LSTM 和GRU)中常見的重要屬性。 值得注意的是,LSTM 和GRU 能夠僅在O (1) 常數記憶體和計算中使用新token 有效地更新自身,相較之下, Transformer 的RNN 視圖(見圖1b)會透過將一個新的token 作為初始狀態新增一個新的RNN 來處理新token。這個新的 RNN 處理所有先前的 token,需要 O (N) 的線性計算量。 在Perceiver 中,由於其架構的原因,潛在變數(圖1c 中的L_i)是依賴輸入的,這意味著它們的值在接收新token時會發生變化。由於其 RNN 的初始隱藏狀態(即潛在變數)發生變化,Perceiver 因此需要從頭開始重新計算其 RNN,需要 O (NL) 的線性計算量,其中 N 是 token 的數量,L 是潛在變數的數量。 針對這些局限性,作者建議開發一種基於注意力的模型,利用RNN 公式的能力來執行高效更新。為此,作者首先引入了一種高效的平行化方法,將注意力作為多對多 RNN 計算,即並行計算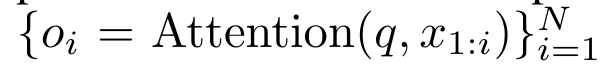 的方法。為此,作者利用平行前綴掃描演算法(見演算法 1),這是一種透過關聯算子 ⊕ 從 N 個連續資料點計算 N 個前綴的平行計算方法。此演算法可高效計算
的方法。為此,作者利用平行前綴掃描演算法(見演算法 1),這是一種透過關聯算子 ⊕ 從 N 個連續資料點計算 N 個前綴的平行計算方法。此演算法可高效計算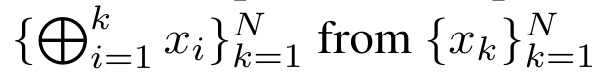 #回顧
#回顧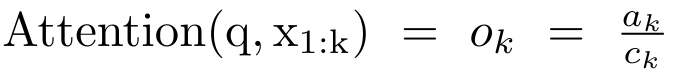 ,其中
,其中 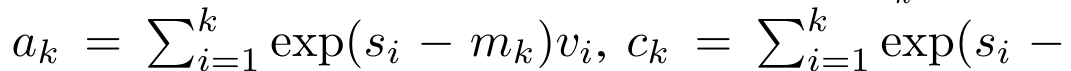
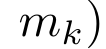 ,
,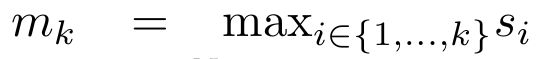 為了高效計算
為了高效計算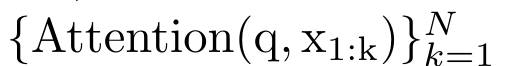 ,可以透過平行掃描演算法計算
,可以透過平行掃描演算法計算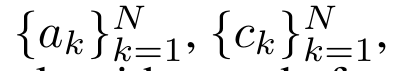 和
和 ,然後結合a_k 和c_k 計算
,然後結合a_k 和c_k 計算 。 為此,作者提出了以下關聯算子⊕,該算子作用於形式為(m_A、u_A、w_A)的三元組,其中A 是一組索引,
。 為此,作者提出了以下關聯算子⊕,該算子作用於形式為(m_A、u_A、w_A)的三元組,其中A 是一組索引,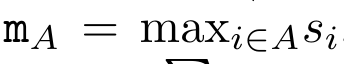 ,
,
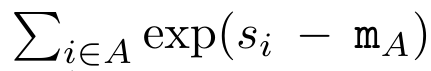 ,
,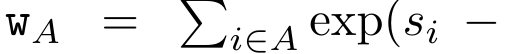
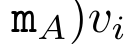 。並行掃描演算法的輸入為
。並行掃描演算法的輸入為 。此演算法遞歸應用算子 ⊕,其工作原理如下:
。此演算法遞歸應用算子 ⊕,其工作原理如下: #,其中,
#,其中,


 #。
#。
在完成遞歸應用算子後,演算法輸出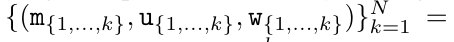
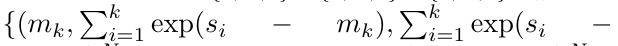
 。也被稱作
。也被稱作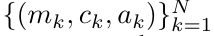 。結合輸出元組的最後兩個值,檢索
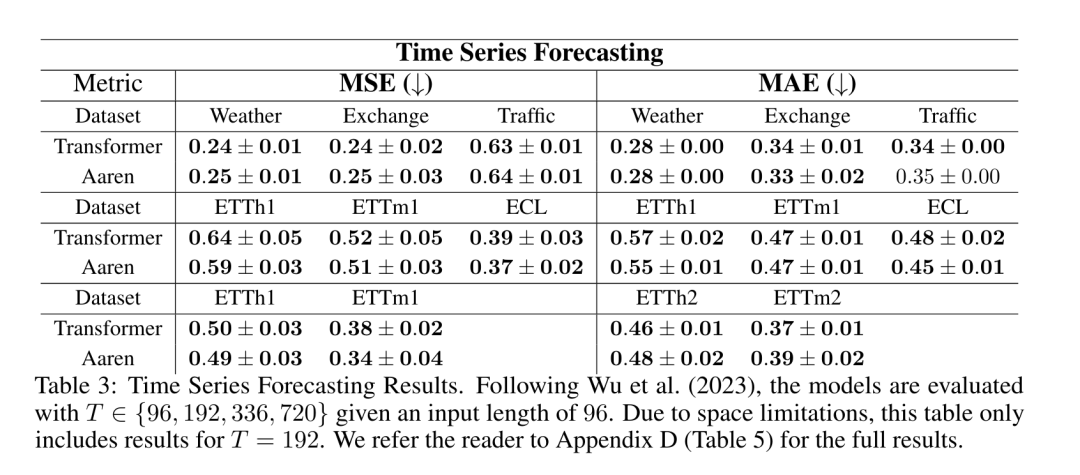
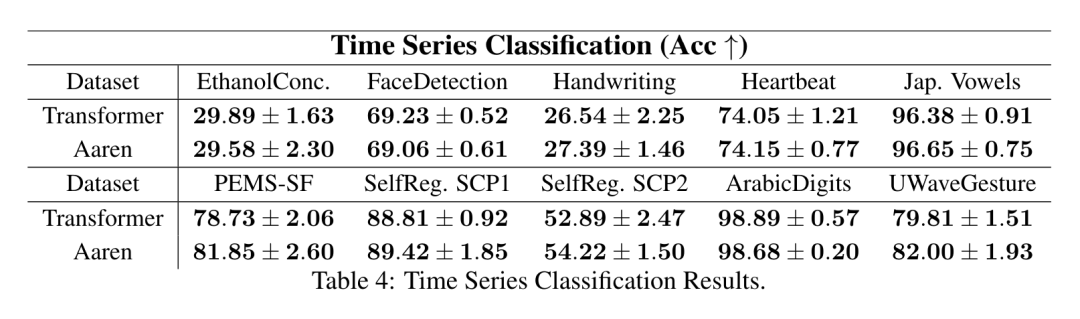
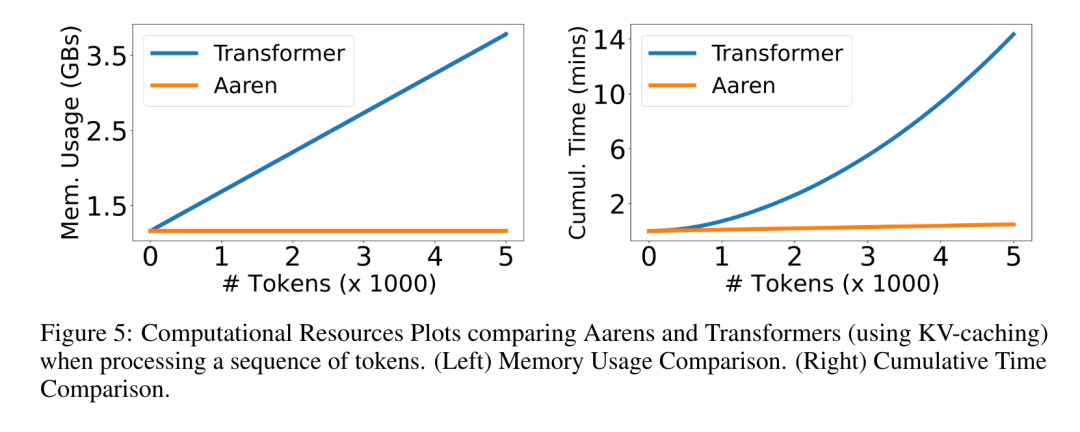
。結合輸出元組的最後兩個值,檢索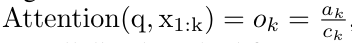 從而產生一種高效的平行方法,將注意力計算為多對多 RNN(圖 3)。 #Aaren:[A] ttention [a] s a [re] current neural [n] etworkAaren 的介面與Transformer 相同,即將N 個輸入對應到N 個輸出,而第i 個輸出是第1 到第i 個輸入的聚合。此外,Aaren 還自然可堆疊,並且能夠計算每個序列 token 的單獨損失項。然而,與使用因果自註意力的 Transformers 不同,Aaren 使用上述計算注意力的方法作為多對多 RNN,使其更有效率。 Aaren 形式如下:與Transformer 不同,在Transformer 中查詢是輸入到注意力的token 之一,而在Aaren 中,查詢token q 是在訓練過程中透過反向傳播學習得到的。 下圖展示了一個堆疊 Aaren 模型的例子,模型的輸入上下文 token 為 x_1:3,輸出為 y_1:3。值得注意的是,由於 Aaren 利用了 RNN 形式的注意力機制,堆疊 Aarens 也相當於堆疊 RNN。因此,Aarens 也能夠有效率地用新 token 進行更新,即 y_k 的迭代計算只需要常數計算,因為它只依賴 h_k-1 和 x_k。 #基於Transformer 的模型需要線性記憶體(使用KV 快取時)並且需要儲存所有先前的token ,包括中間Transformer 層中的那些,但基於Aaren 的模型只需要常量內存,並且不需要存儲所有先前的token ,這使得Aarens 在計算效率上顯著優於Transformer。 #實驗部分的目標是比較Aaren 和Transformer 在效能和所需資源(時間和記憶體)方面的表現。為了進行全面比較,作者在四個問題上進行了評估:強化學習、事件預測、時間序列預測和時間序列分類。 #作者首先比較了Aaren 和Transformer 在強化學習方面的表現。強化學習在機器人、推薦引擎和交通控制等互動式環境中很受歡迎。 表 1 中的結果表明,在所有 12 個資料集和 4 個環境中,Aaren 與 Transformer 的效能都不相上下。不過,與 Transformer 不同的是,Aaren 也是一種 RNN,因此能夠在持續運算中高效處理新的環境交互,從而更適合強化學習。 接下來,作者比較了Aaren 和Transformer 在事件預測上的表現。事件預測在許多現實環境中都很流行,例如金融(如交易)、醫療保健(如患者觀察)和電子商務(如購買)。 表 2 的結果顯示,Aaren 在所有資料集上的表現都與 Transformer 相當。Aaren 能夠有效率地處理新輸入,這在事件預測環境中尤其有用,因為在這種環境中,事件會以不規則流的形式出現。 #然後,作者比較了Aaren 和Transformer 在時間序列預測方面的表現。時間序列預測模型通常用在與氣候(如天氣)、能源(如供需)和經濟(如股票價格)相關的領域。 表 3 中的結果顯示,在所有資料集上,Aaren 與 Transformer 的效能相當。不過,與 Transformer 不同的是,Aaren 能高效處理時間序列數據,因此更適合與時間序列相關的領域。 #接下來,作者比較了Aaren 和Transformer 在時間序列分類方面的表現。時間序列分類在許多重要的應用中很常見,例如模式識別(如心電圖)、異常檢測(如銀行詐欺)或故障預測(如電網波動)。 從表 4 可以看出,在所有資料集上,Aaren 與 Transformer 的表現不相上下。 #最後,作者比較了 Aaren 和 Transformer 所需的資源。 記憶體複雜度:在圖 5(左)中,作者比較了 Aaren 和 Transformer(使用 KV 快取)在推理時的記憶體使用情況。可以看到,伴隨 KV 快取技術的使用,Transformer 的記憶體使用量呈現線性成長。相比之下,Aaren 只使用恆定的內存,無論 token 數量如何增長,因此它的效率要高得多。 時間複雜度:在圖5(右圖)中,作者比較了Aaren 和Transformer(使用KV 快取)依序處理一串token 所需的累積時間。對於 Transformer,累積計算量是 token 數的二次方,即 O (1 + 2 + ... + N) = O (N^2 )。相比之下,Aaren 的累積計算量是線性的。在圖中,可以看到模型所需的累積時間也是類似的結果。具體來說,Transformer 所需的累積時間呈現二次成長,而 Aaren 所需的累積時間呈線性成長。 參數數:由於要學習初始隱藏狀態 q,Aaren 模組所需的參數略多於 Transformer 模組。不過,由於 q 只是一個向量,因此差異不大。透過在同類模型中進行實證測量,作者發現 Transformer 使用了 3, 152, 384 個參數。相較之下,等效的 Aaren 使用了 3, 152, 896 個參數,參數增加量僅為 0.016%—— 對於記憶體和時間複雜性的顯著差異來說,這只是微不足道的代價。
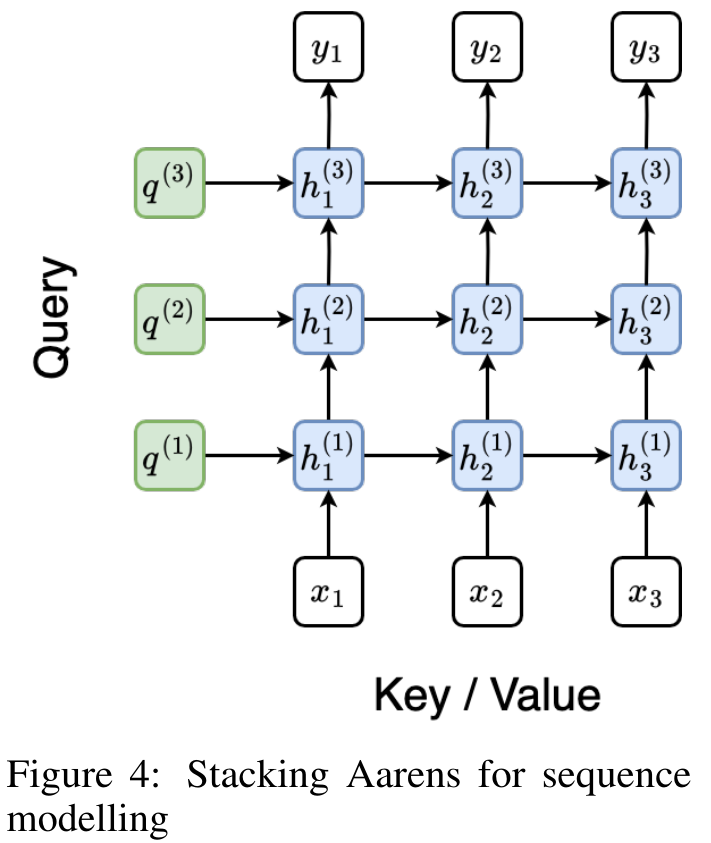
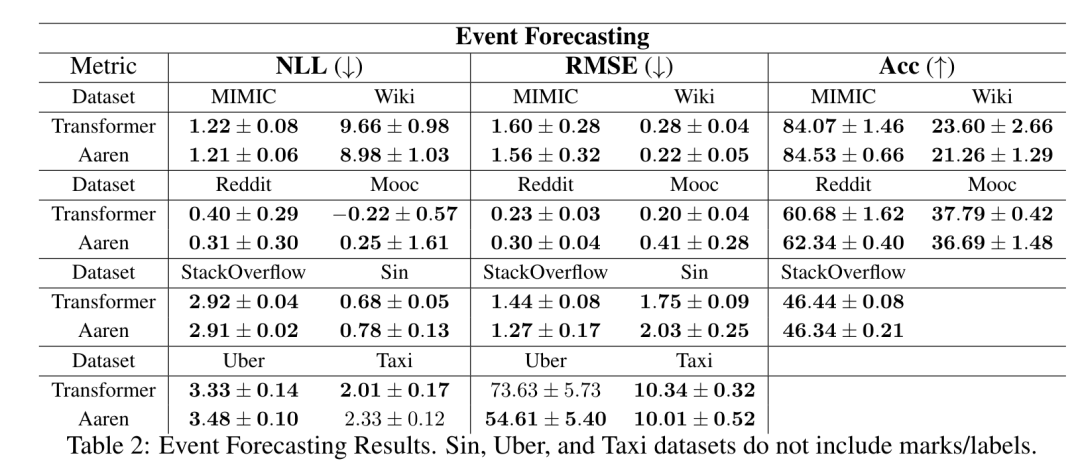
從而產生一種高效的平行方法,將注意力計算為多對多 RNN(圖 3)。 #Aaren:[A] ttention [a] s a [re] current neural [n] etworkAaren 的介面與Transformer 相同,即將N 個輸入對應到N 個輸出,而第i 個輸出是第1 到第i 個輸入的聚合。此外,Aaren 還自然可堆疊,並且能夠計算每個序列 token 的單獨損失項。然而,與使用因果自註意力的 Transformers 不同,Aaren 使用上述計算注意力的方法作為多對多 RNN,使其更有效率。 Aaren 形式如下:與Transformer 不同,在Transformer 中查詢是輸入到注意力的token 之一,而在Aaren 中,查詢token q 是在訓練過程中透過反向傳播學習得到的。 下圖展示了一個堆疊 Aaren 模型的例子,模型的輸入上下文 token 為 x_1:3,輸出為 y_1:3。值得注意的是,由於 Aaren 利用了 RNN 形式的注意力機制,堆疊 Aarens 也相當於堆疊 RNN。因此,Aarens 也能夠有效率地用新 token 進行更新,即 y_k 的迭代計算只需要常數計算,因為它只依賴 h_k-1 和 x_k。 #基於Transformer 的模型需要線性記憶體(使用KV 快取時)並且需要儲存所有先前的token ,包括中間Transformer 層中的那些,但基於Aaren 的模型只需要常量內存,並且不需要存儲所有先前的token ,這使得Aarens 在計算效率上顯著優於Transformer。 #實驗部分的目標是比較Aaren 和Transformer 在效能和所需資源(時間和記憶體)方面的表現。為了進行全面比較,作者在四個問題上進行了評估:強化學習、事件預測、時間序列預測和時間序列分類。 #作者首先比較了Aaren 和Transformer 在強化學習方面的表現。強化學習在機器人、推薦引擎和交通控制等互動式環境中很受歡迎。 表 1 中的結果表明,在所有 12 個資料集和 4 個環境中,Aaren 與 Transformer 的效能都不相上下。不過,與 Transformer 不同的是,Aaren 也是一種 RNN,因此能夠在持續運算中高效處理新的環境交互,從而更適合強化學習。 接下來,作者比較了Aaren 和Transformer 在事件預測上的表現。事件預測在許多現實環境中都很流行,例如金融(如交易)、醫療保健(如患者觀察)和電子商務(如購買)。 表 2 的結果顯示,Aaren 在所有資料集上的表現都與 Transformer 相當。Aaren 能夠有效率地處理新輸入,這在事件預測環境中尤其有用,因為在這種環境中,事件會以不規則流的形式出現。 #然後,作者比較了Aaren 和Transformer 在時間序列預測方面的表現。時間序列預測模型通常用在與氣候(如天氣)、能源(如供需)和經濟(如股票價格)相關的領域。 表 3 中的結果顯示,在所有資料集上,Aaren 與 Transformer 的效能相當。不過,與 Transformer 不同的是,Aaren 能高效處理時間序列數據,因此更適合與時間序列相關的領域。 #接下來,作者比較了Aaren 和Transformer 在時間序列分類方面的表現。時間序列分類在許多重要的應用中很常見,例如模式識別(如心電圖)、異常檢測(如銀行詐欺)或故障預測(如電網波動)。 從表 4 可以看出,在所有資料集上,Aaren 與 Transformer 的表現不相上下。 #最後,作者比較了 Aaren 和 Transformer 所需的資源。 記憶體複雜度:在圖 5(左)中,作者比較了 Aaren 和 Transformer(使用 KV 快取)在推理時的記憶體使用情況。可以看到,伴隨 KV 快取技術的使用,Transformer 的記憶體使用量呈現線性成長。相比之下,Aaren 只使用恆定的內存,無論 token 數量如何增長,因此它的效率要高得多。 時間複雜度:在圖5(右圖)中,作者比較了Aaren 和Transformer(使用KV 快取)依序處理一串token 所需的累積時間。對於 Transformer,累積計算量是 token 數的二次方,即 O (1 + 2 + ... + N) = O (N^2 )。相比之下,Aaren 的累積計算量是線性的。在圖中,可以看到模型所需的累積時間也是類似的結果。具體來說,Transformer 所需的累積時間呈現二次成長,而 Aaren 所需的累積時間呈線性成長。 參數數:由於要學習初始隱藏狀態 q,Aaren 模組所需的參數略多於 Transformer 模組。不過,由於 q 只是一個向量,因此差異不大。透過在同類模型中進行實證測量,作者發現 Transformer 使用了 3, 152, 384 個參數。相較之下,等效的 Aaren 使用了 3, 152, 896 個參數,參數增加量僅為 0.016%—— 對於記憶體和時間複雜性的顯著差異來說,這只是微不足道的代價。 以上是Bengio等人新作:注意力可視為RNN,新模型媲美Transformer,但超級省內存的詳細內容。更多資訊請關注PHP中文網其他相關文章!