

 圖片
圖片
Yuan+2.0-M32是一種基礎架構,與Yuan-2.0+2B相似,採用了一個包含32位專家的專家混合架構。其中2位專家處於活躍狀態。提出並採用了一個包含32位專家的專家混合架構,以更有效率地選擇專家,相比採用經典路由網路的模型,其準確率提升了3.8%。 Yuan+2.0-M32從零開始訓練,使用了2000B的token,其訓練消耗僅為同等參數規模密集集合模型的9.25%。為了更好地選擇專家,引入了注意力路由器,該路由器具有快速感知的能力,從而能更好地選擇專家。
Yuan 2.0-M32在編碼、數學及多個專業領域展現了競爭力的能力,僅使用了400億總參數中的37億活躍參數,以及每token7.4 GFlops的前向計算,這兩項指標皆僅Llama3-70B的1/19。 Yuan 2.0-M32在MATH和ARC-Challenge基準測試中超越了Llama3-70B,準確率分別達到55.89%和95.8%。 Yuan 2.0-M32的模型及原始碼已在GitHub:https://github.com/IEIT-Yuan/Yuan2.0-M32。
在每一個token在固定計算量的情況下,採用專家混合(MoE)結構的模型可以透過增加專家數量輕鬆建構得比密集集模型更大規模,從而實現更高的準確性表現。實際上,在有限的運算資源下訓練模型,MoE被視為減少與模型、資料集規模和有限運算能力相關的成本的卓越選擇方案。
MoE(Mixture of Experts)的概念可追溯至1991年。總損失是每個專家加權損失的組合,這些專家具有獨立判決的能力。稀疏門控MoE的概念最初由Shazeer等人(2017年)在翻譯模型中提出。採用這種路由策略,提理時只有極少數專家被激活,而非所有專家同時被調用。這種稀疏性使得模型在計算效率損失極小的情況下,堆疊的LSTM層之間擴展了1000倍。雜訊可調的Top-K閘控路由由網路向softmax函數引入可調雜訊並維持K值,以平衡專家利用率。近年來,隨著模型規模的不斷擴大,路由策略在高效分配運算資源方面受到了更多關注。
專家路由網路是MoE結構的核心。該結構透過計算token分配給每個專家的機率來選擇參與計算的候選專家。目前,在大多數流行的MoE結構中,普遍採用經典路由演算法,該演算法執行token與每個專家特徵向量之間的點積,並選擇具有最大點積的專家作為獲勝者。在這個選擇中,專家的特徵向量是獨立的,忽略了專家之間的相關性。然而,MoE結構通常每次不只選擇一個專家,並且不同專家之間的特徵可能存在相關性。因此,在這種情況下,選擇的特徵向量對於每個參與計算的專家之間的點積可能存在重疊和衝突,進而影響結果的準確性。但是,MoE結構通常每次選擇不只一個專家,並且不同專家之間的特徵可能存在相關性,因此在這種情況下,經典路由演算法選擇的特徵向量可能會存在重疊和衝突,影響計算準確性。為了解決這個問題,MoE結構經常採用獨立的專家特徵向量,這意味著每個專家被視為完全獨立,而忽略了專家之間的相關性。然而,這種做法可能會導致一些問題。因此,在選擇專家時,MoE結構通常不只選擇一個專家,不同專家之間的特徵可能存在相關性。在這種情況下,選擇的特徵向量對於每個參與計算的專家之間的點積可能存在重疊和衝突,進而影響結果的準確性。因此,MoE結構需要更準確的路由演算法來選擇最佳的專家,並且在選擇時需要考
基於Yuan 2.0-2B的模型結構,Yuan 2.0引入了基於局部濾波的注意力(LFA)以考慮輸入token的局部依賴性,從而提高模型的準確性。在Yuan 2.0-M32中,每一層的密集前饋網路(FFN)被替換為MoE組件。
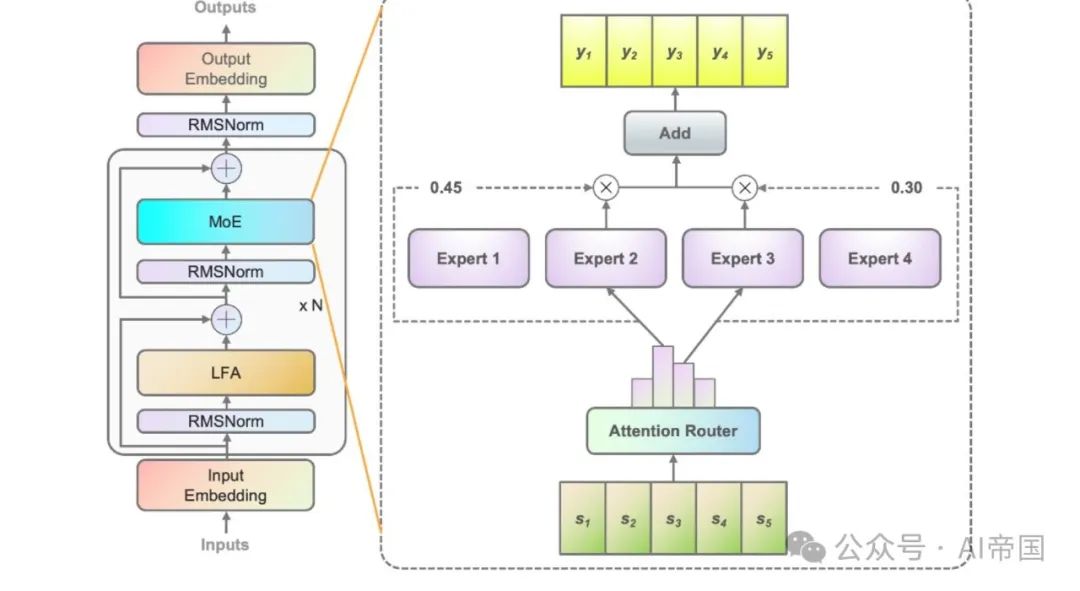
圖1展示了論文模型中應用的MoE層的架構。以四個FFN為例(實際上有32個專家),每個MoE層由一個獨立的FFN作為專家組成。由於專家的路徑網路將輸入的token分派給相關的專家,經典的路徑網路為每個專家建立了一個特徵向量。並計算輸入的token與每個專家特徵向量之間的點積,以獲得token與每個專家之間的相似度。具有最高相似度的專家將用於計算輸出。最強的相似度的專家被選中激活,並參與後續計算。
 圖片
圖片
圖1:Yuan 2.0-M32的說明。左側圖展示了Yuan 2.0架構中MoE層的擴展。 MoE層取代了Yuan 2.0中的前饋層。右側圖展示了MoE層的結構。在論文的模型中,每個輸入token將被分配給總共32個專家中的2個,而在圖中論文以4個專家為例進行展示。 MoE的輸出是所選專家的加權和。 N表示層的數目每個專家的特徵向量彼此獨立,計算機率時忽略了專家之間的相關性。實際上,在大多數MoE模型中,通常會選擇兩個或更多的專家參與後續計算,自然帶來了專家間的強相關性。考慮專家間的相關性無疑有助於提高準確性。 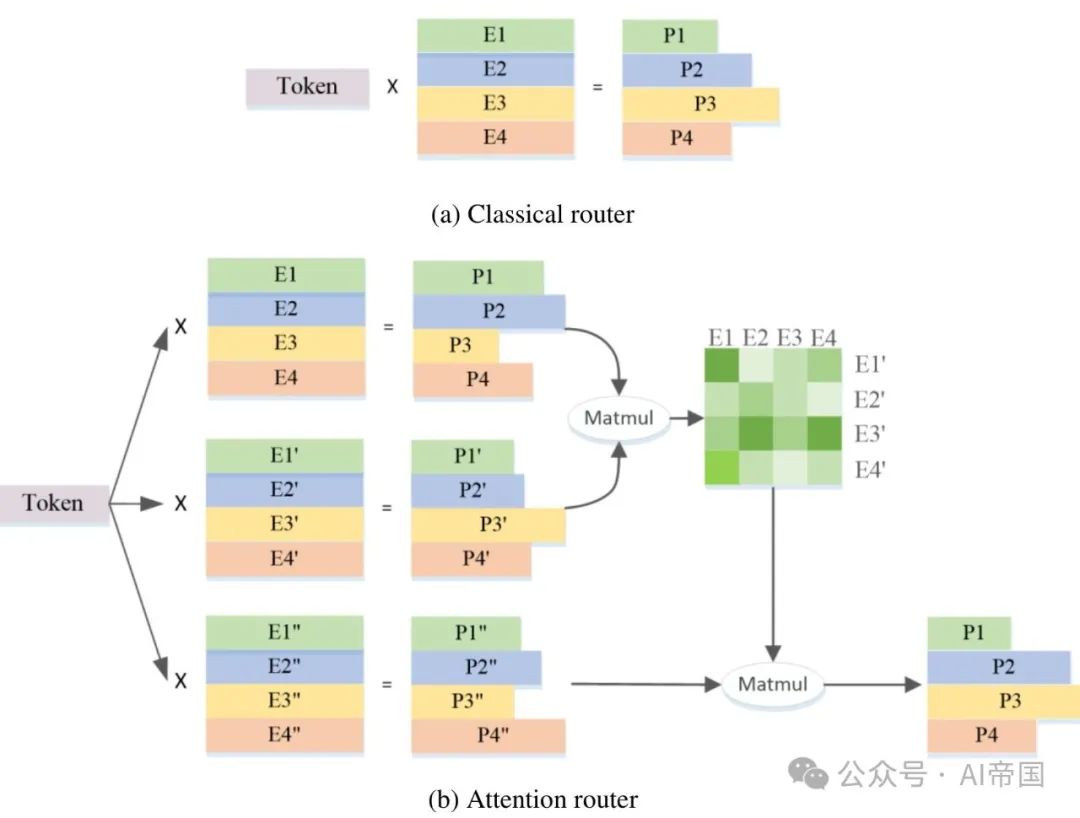
表1:不同路由結構的比較
表1列出了不同路由器的準確度結果。論文的模型在8個可訓練專家上測試了注意力路由器。經典路由器模型有8個可訓練專家,以確保相似的參數規模,且路由結構與應用於Mixtral 8*7B的結構相同,即一個線性層上的Softmax。共享專家路由器採用共享專家隔離策略與經典路由架構。有兩個固定專家捕捉通用知識,以及14個可選專家中前兩名作為專業專家。 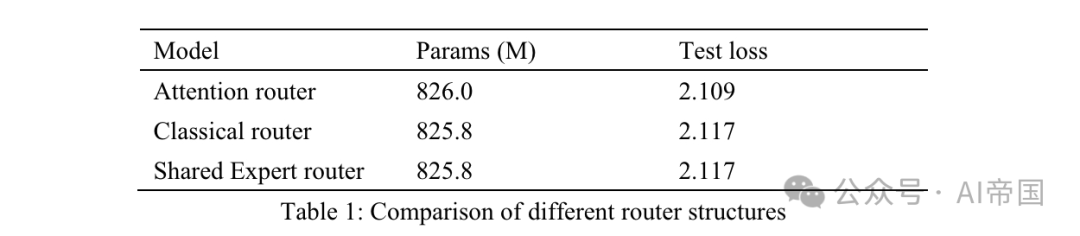
論文透過增加專家數量並固定每個專家的參數大小來測試模型的可擴展性。訓練專家數量的增加僅改變模型容量,而不改變實際活化的模型參數。所有模型均使用500億個token進行訓練,並使用另外的100億個token進行測試。論文將啟動的專家設定為2,三個模型的訓練超參數相同。專家擴展效果是透過訓練500億個token後的測試損失來衡量(表2)。與8個可訓練專家的模型相比,具有16個專家的模型顯示出2%的損失降低,而具有32個專家的模型顯示出3.6%的損失降低。考慮到其準確性,論文為Yuan 2.0-M32選擇了32個專家。
表2:擴展實驗結果
#2.2.2 模型訓練
圖3:Yuan2.0-M32在2000Btoken上的預訓練損失

在微調過程中,論文將序列長度擴展至16384。遵循CodeLLama(Roziere et al.,2023)的工作,論文重置旋轉位置嵌入(RoPE)的基頻值,以避免隨著序列長度增加,注意力分數的衰減。論文沒有簡單地將基值從1000增加到一個非常大的值(例如1000000),而是使用NTK感知(bloc97,2023)來計算新的基值。
論文也比較了預先訓練的Yuan 2.0-M32模型與NTK感知風格的新基值,以及與其他基值在序列長度高達16K的針檢索任務中的表現。論文發現NTK感知風格的新基值40890表現較好。因此,在微調過程中應用了40890。
Yuan 2.0-M32 從零開始使用包含 2000B token 的雙語資料集進行預訓練。預訓練的原始資料包含超過 3400B token,並根據資料品質和數量調整每個類別的權重。
綜合預訓練語料庫由以下內容組成:
#44個子資料集,涵蓋了網路爬取資料、維基百科、學術論文、書籍、程式碼、數學和公式以及特定領域的專業知識。其中一些是開源資料集,其餘由Yuan 2.0創建。
部分常見的網路爬蟲資料、中文書籍、對話及中文新聞資料繼承自 Yuan 1.0(吳等人,2021年)。 Yuan 2.0 中的大部分預訓練資料也都被重新利用了。
關於每個資料集的建構和來源的詳細資訊如下:
網路(25.2%):網站爬蟲資料是從開源資料集和論文先前工作(Yuan 1.0)中處理過的公共爬蟲資料中收集的。關於從網路上下文中提取高品質內容的Massive Data Filtering System(MDFS)的更多詳情,請參考Yuan 1.0。
百科全書(1.2%)、論文(0.84%)、書籍(6.49%)和翻譯(1.1%):資料繼承自Yuan 1.0和Yuan 2.0資料集。
程式碼(47.5%):與Yuan 2.0相比,程式碼資料集得到了極大的擴展。論文採用了Stack v2(Lozhkov等人,2024年)中的程式碼。 Stack v2中的註解被翻譯成中文。透過與Yuan 2.0相似的方法產生了程式碼合成資料。
數學(6.36%):所有來自Yuan 2.0的數學資料都被重新使用。這些資料主要來自開源資料集,包括proof-pile vl(Azerbayev,2022年)和v2(Paster等人,2023年),AMPS(Hendrycks等人,2021年),MathPile(Wang,Xia和Liu,2023年)以及StackMathQA(Zhang,2024年)。使用Python創建了一個數值計算的合成資料集,以利於四則運算。
特定領域(1.93%):這是一個包含不同背景知識的資料集。
#微調資料集基於Yuan 2.0中應用的資料集進行了擴展。
程式碼指令資料集。所有帶有中文指令及部分帶有英文註釋的程式資料均由大型語言模型(LLMs)產生。約30%的代碼指令資料為英文,其餘為中文。合成資料在提示產生和資料清洗策略上模仿了帶有中文註解的Python程式碼。
帶有英文註解的Python程式碼收集自Magicoder-Evol-Instruct-110K和CodeFeedback-Filtered-Instruction。從資料集中提取帶有語言標籤(如“python”)的指令資料。
其他如C/C++/Go/Java/SQL/Shell等語言的程式碼,附有英文註釋,源自開源資料集,處理方式與Python程式碼類似。清洗策略與Yuan 2.0中的方法相似。設計了一個沙箱以提取生成的程式碼中可編譯和可執行的行,並保留至少通過一個單元測試的行。
數學指令資料集。數學指令資料集全部繼承自Yuan 2.0中的微調資料集。為提高模型透過程式方法解決數學問題的能力,論文建構了Thoughts(PoT)提示的數學數據。 PoT將數學問題轉換為使用Python進行計算的程式碼產生任務。
安全指令資料集。除了元2.0的聊天資料集外,論文還基於一個開源的安全對齊資料集建構了一個雙語安全對齊資料集。論文僅從公共資料集中提取問題,並增加問題的多樣性,利用大型語言模型重新生成中文和英文答案。
#對於 Yuan 2.0-M32,英文和中文分詞器繼承自 Yuan 2.0 中應用的分詞器。
論文在HumanEval上評估了Yuan 2.0-M32的程式碼產生能力,在GSM8K和MATH上評估了數學問題解決能力,在ARC上評估了科學知識和推理能力,並在MMLU上作為一個綜合基準進行評估。
#程式碼產生能力的評估使用HumanEval基準。評估方法和提示與元2.0中提到的相似。
 表3:Yuan 2.0-M32與其他模型在HumanEval pass @1上的比較
表3:Yuan 2.0-M32與其他模型在HumanEval pass @1上的比較
模型預期在後完成函數。產生的函數將透過單元測試進行評估。表3展示了Yuan 2.0-M32在零樣本學習中的結果,並與其它模型進行了比較。 Yuan 2.0-M32的結果僅次於DeepseekV2和Llama3-70B,遠超其他模型,即使其活躍參數和計算消耗遠低於其他模型。
與DeepseekV2相比,論文的模型使用的活躍參數不到其四分之一,每token的計算量不到其五分之一,同時達到了其超過90%的準確度水準。與Llama3-70B相比,模型參數和計算量的差距更大,論文仍能達到其91%的水平。 Yuan 2.0-M32展示了可靠的程式設計能力,通過了四分之三的問題。 Yuan 2.0-M32擅長小樣本學習,透過14次嘗試將HumanEval的準確率提高到78.0。
Yuan 2.0-M32的數學能力透過GSM8K和MATH基準進行評估。 GSM8K的提示和測試策略與應用於Yuan 2.0的相似,唯一不同的是論文使用8次嘗試(表4)。
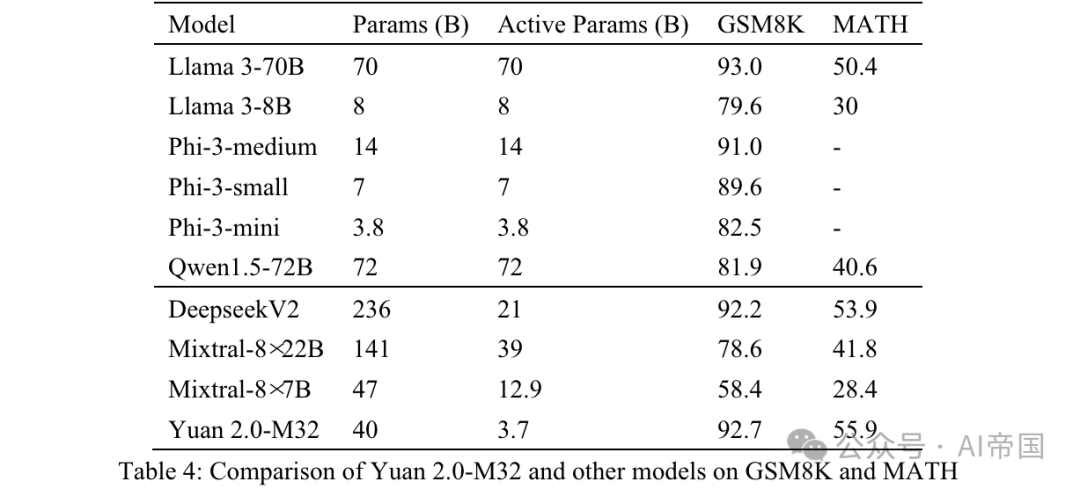 表4:Yuan 2.0-M32與其他模型在GSM8K和MATH上的比較
表4:Yuan 2.0-M32與其他模型在GSM8K和MATH上的比較
MATH是一個包含12, 500個挑戰性數學競賽問答問題的資料集。該資料集中的每個問題都有完整的逐步解決方案,引導模型產生答案推導和解釋。問題的答案可以是數值,或數學表達式(如y=2x+5,x-+2x-1,2a+b等)。 Yuan 2.0-M32使用鍊式思維(CoT)方法,透過4次嘗試產生最終答案。答案將從分析中提取並轉換為統一格式。
對於數值結果,所有格式的數學等價輸出都被接受。例如,分數1/2,12,0.5,0.50都轉換為0.5並被視為相同結果。對於數學表達式,論文移除製表符和空格符號,並統一了節奏或音符的正規表示式。 55 '5'均被接受為相同答案。處理後的最終結果與標準答案進行比較,並使用EM(精確匹配)分數進行評估。
從表4所示的結果可以看出,Yuan 2.0-M32在MATH基準上得分最高。與Mixtral-8x7B相比,後者活躍參數是Yuan 2.0-M32的3.48倍,但Yuan的得分幾乎是其兩倍。在GSM8K上,Yuan 2.0-M32的得分也非常接近Llama 3-70B,並且優於其他模型。
#大規模多任務語言理解(MMLU)涵蓋了STEM、人文科學、社會科學等57個學科,從基礎語言任務到高階邏輯推理任務不等。 MMLU中的所有問題都是英語的多選QA問題。模型預期產生正確的選項或相應的分析。
Yuan 2.0-M32的輸入資料組織如附錄B所示。先前的文字被發送給模型,所有與正確答案或選項標籤相關的答案被視為正確。
最終準確度是透過MC1(表5)來衡量。 MMLU上的結果展示了論文模型在不同領域的能力。 Yuan 2.0-M32在性能上超過了Mixtral-8x7B、Phi-3-mini和Llama 3-8B。
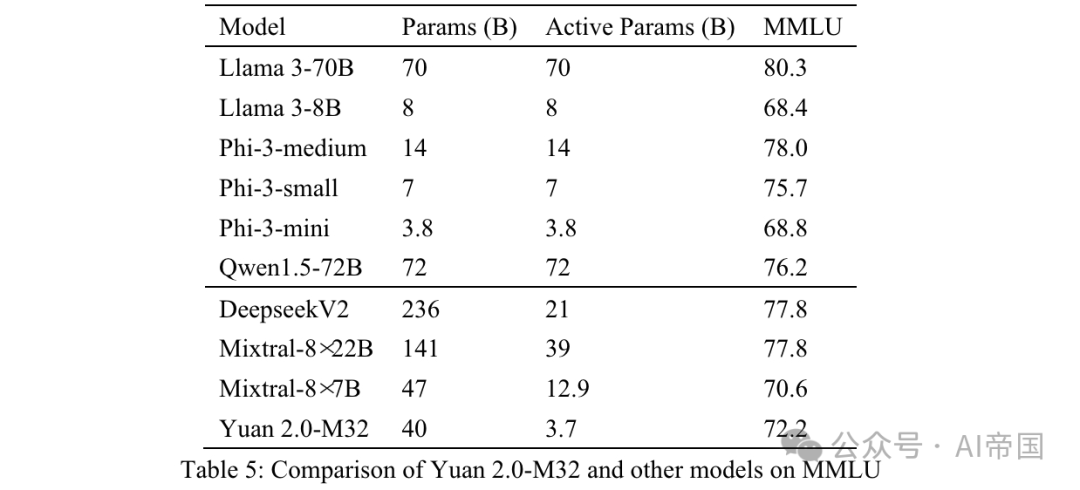 表5:Yuan 2.0-M32與其他模型在MMLU上的比較
表5:Yuan 2.0-M32與其他模型在MMLU上的比較
AI2推理挑戰(ARC)基準是一個多選QA資料集,包含從3年級到9年級科學考試的問題。它分為簡單和挑戰兩部分,後者包含需要進一步推理的更複雜部分。論文在挑戰部分測試論文的模型。
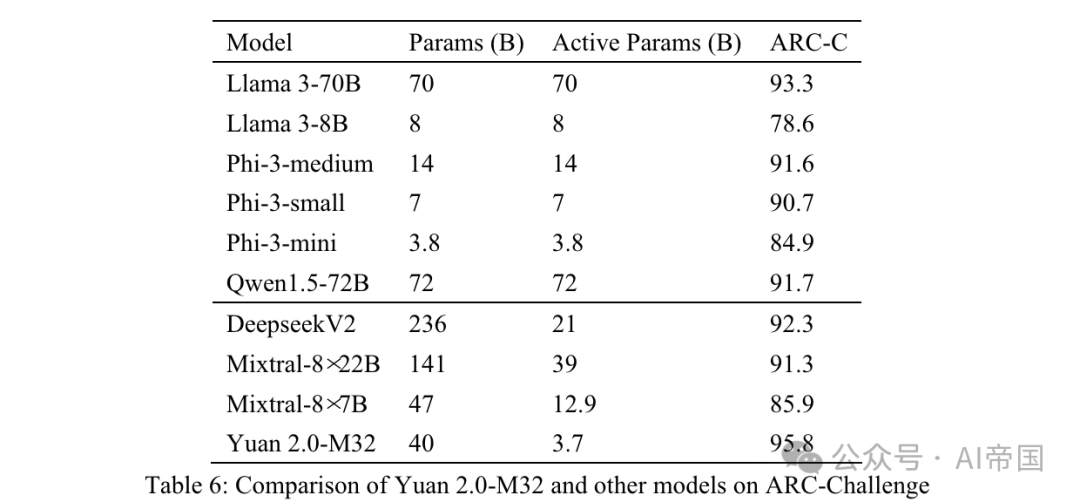 表6:Yuan 2.0-M32 與其他模型在ARC-Challenge 上的比較
表6:Yuan 2.0-M32 與其他模型在ARC-Challenge 上的比較
問題和選項直接連接並用分隔。 先前的文字發送給模型,模型預期產生一個標籤或相應的答案。產生的答案與真實答案進行比較,結果使用 MC1 目標計算。
表 6 顯示的結果 ARC-C 表明,Yuan 2.0-M32 在解決複雜科學問題方面表現出色——它在這一基準上超越了 Llama3-70B。
 圖片
圖片
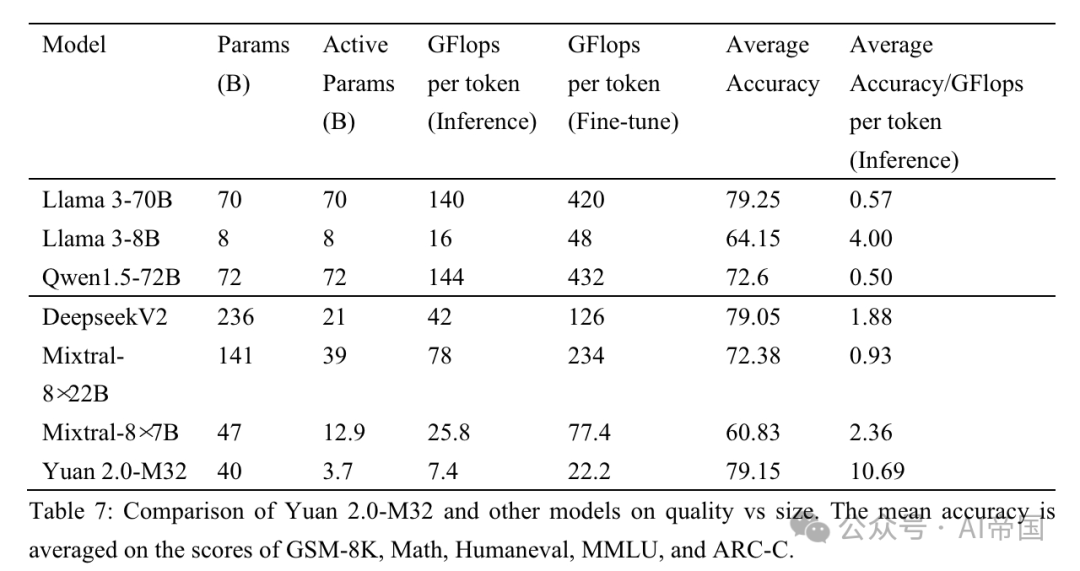
表 7:Yuan 2.0-M32 與其他模型在品質與大小上的比較。平均準確度是根據 GSM-8K、Math、Humaneval、MMLU 和 ARC-C 的分數平均得出的
論文將論文的表現與三種MoE模型(Mixtral家族、Deepseek)和六種密集模型(Qwen(Bai等,2023)、Llama家族和Phi-3家族(Abdin等,2024))進行比較,以評估Yuan 2.0-M32在不同領域的表現。表7展示了Yuan 2.0-M32與其他模型在準確度與計算量之間的比較。 Yuan 2.0-M32僅使用3.7B活躍參數和每token 22.2 GFlops進行微調,這是最經濟的,以獲得與表中列出的其他模型相當甚至超越的結果。表7暗示了論文模型在推理過程中的卓越計算效率和性能。 Yuan 2.0-M32的平均準確度為79.15,與Llama3-70B相當。而平均準確度/每token GFlops的值為10.69,是Llama3-70B的18.9倍。
論文標題:Yuan 2.0-M32: Mixture of Experts with Attention Router
論文連結:# //m.sbmmt.com/link/cc7d159d6ff3ea6f39b9419877dfc81f
以上是LLM | Yuan 2.0-M32:注意力路由的專家混合模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















