AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Richard Sutton 在「The Bitter Lesson」中做過這樣的評價: 「從70年的人工智慧研究中可以得出的最重要教訓是,那些利用計算的通用方法最終是最有效的,而且優勢巨大。」
- ##自我博弈(self play)就是這樣一種同時利用搜尋和學習從而充分利用和擴大計算規模的方法。
-
今年年初,加州大學洛杉磯分校(UCLA)的顧全全教授團隊提出了一種
自我博弈微調方法(Self-Play Fine-Tuning, SPIN )
,可不使用額外微調數據,僅靠自我博弈就能大幅提升LLM 的能力。
最近,顧全全教授團隊和卡內基美隆大學(CMU)Yiming Yang教授團隊合作開發了一種名為「自我博弈偏好優化(Self-Play Preference Optimization, SPPO)」的對齊技術,此新方法旨在透過自我博弈的框架來優化大語言模型的行為,使其更好地符合人類的偏好。左右互搏再顯神通!
論文標題:Self-Play Preference Optimization for Language Model Alignment論文連結:https://arxiv.org/pdf/2405.00675.pdf
技術背景與挑戰
#大語言模型(LLM)正成為人工智慧領域的重要推動力,憑藉其出色的文本生成和理解能力在種任務中表現卓越。儘管LLM的能力令人矚目,但要讓這些模型的輸出行為更符合實際應用中的需求,通常需要透過對準(alignment)過程進行微調。
這個過程關鍵在於調整模型以更好地反映人類的偏好和行為準則。常見的方法包括基於人類回饋的強化學習(RLHF)或直接偏好優化(Direct Preference Optimization,DPO)。 基於人類回饋的強化學習(RLHF)依賴於顯式的維護一個獎勵模型用來調整和細化大語言模型。換言之,例如,InstructGPT就是基於人類偏好資料先訓練一個服從Bradley-Terry模型的獎勵函數,然後使用像近似策略優化(Proximal Policy Optimization,PPO)的強化學習演算法去優化大語言模型。去年,研究者提出了直接偏好優化(Direct Preference Optimization,DPO)。 不同於RLHF維護一個明確的獎勵模型,DPO演算法隱含的服從Bradley-Terry模型,但可以直接用於大語言模型最佳化。已有工作試圖透過多次迭代的使用DPO來進一步微調大模型 (圖1)。 
###卷######如Bradley-Terry這樣的參數模型會為每個選擇提供一個數值分數。這些模型雖然提供了合理的人類偏好近似,但未能完全捕捉人類行為的複雜性。 ###############這些模型往往假設不同選擇之間的偏好關係是單調和傳遞的,而實證證據卻常常顯示出人類決策的非一致性和非線性,例如Tversky的研究觀察到人類決策可能會受到多種因素的影響,並表現出不一致性。 ##################SPPO的理論基礎與方法################## 圖2.中非常想上排性愛的兩個語言模型上進行常態與遊戲。 在這些背景下,作者提出了一個新的自我博弈框架SPPO,該框架不僅具有解決兩個玩家常和博弈(two-player constant-sum game)的可證明保證,而且可以擴展到大規模的高效微調大型語言模型。 具體來說,文章將RLHF問題嚴格定義為一個兩玩家常和博弈 (圖2)。工作的目標是識別納許均衡策略,這種策略在平均意義上始終能提供比其他任何策略更受偏好的回應。 為了近似地識別納許均衡策略,作者採用了具有乘法權重的經典線上自適應演算法作為解決兩玩家博弈的高層框架演算法。 在該框架的每一步內,演算法可以透過自我博弈機制來近似乘法權重更新,其中在每一輪中,大語言模型都在針對上一輪的自身進行微調,透過模型產生的合成資料和偏好模型的註解來進行最佳化。 具體來說,大語言模型在每一輪迴會針對每個提示產生若干回應;依據偏好模型的標註,演算法可以估計出每個回覆的勝率;演算法從而可以進一步微調大語言模型的參數使得那些勝率高的回應擁有更高的出現機率(圖3)。 在實驗中,研究團隊採用了一種Mistral-7B作為基準模型,並使用了UltraFeedback資料集的60,000個提示(prompt)進行無監督訓練。他們發現,透過自我博弈的方式,模型能夠顯著提高在多個評估平台上的表現,例如AlpacaEval 2.0和MT-Bench。這些平台廣泛用於評估模型生成文本的品質和相關性。
透過SPPO方法,模型不僅在
生成文字的流暢性和準確性上得到了改進,更重要的是:「它在符合人類價值和偏好方面表現得更加出色」。 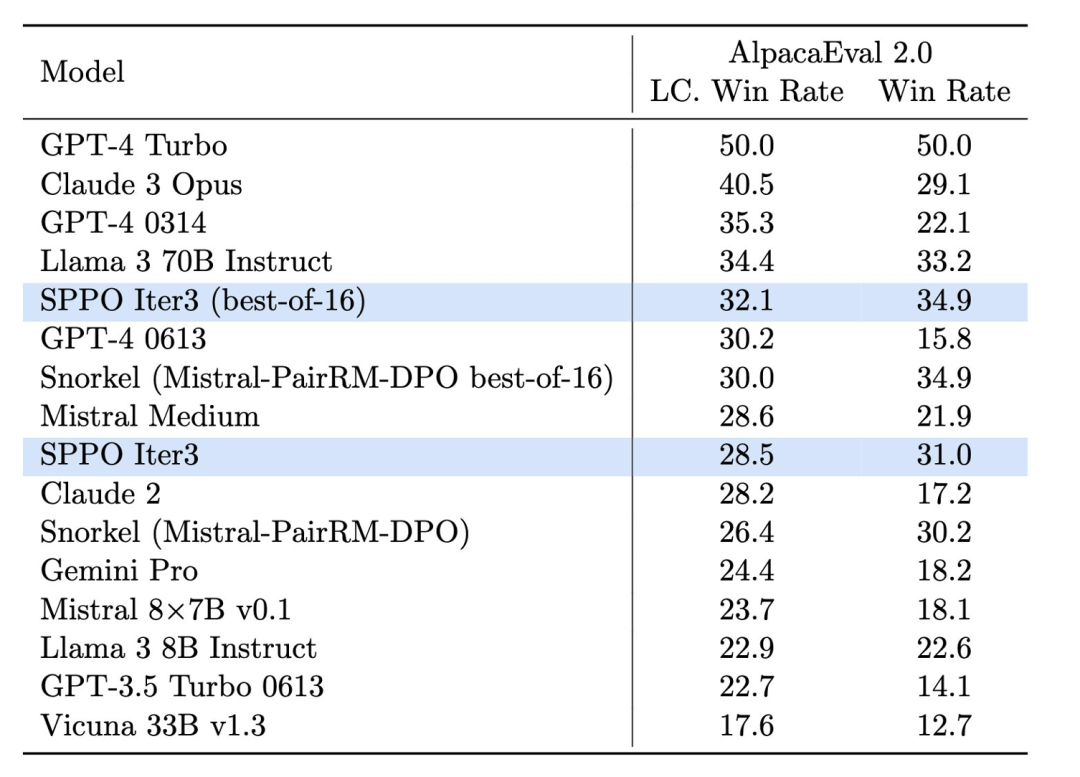
圖中 4.SPPO模型在AlpacaEval 2.0020672.0% 上的高度提升。 在AlpacaEval 2.0的測試中(圖4),經過SPPO優化的模型在長度控制勝率方面從基線模型的17.11%提升到了28.53%,顯示了其對人類偏好理解的顯著提高。經過三輪SPPO優化的模型在AlpacaEval2.0上顯著優於多輪迭代的DPO, IPO和自我獎勵的語言模型(Self-Rewarding LM)。
此外,模型在MT-Bench上的表現也超過了傳統透過人類回饋調優的模型。這證明了SPPO在自動調整模型行為以適應複雜任務的有效性。
#自我博弈偏好最佳化(SPPO)為大語言模型提供了一個全新的最佳化路徑,不僅提高了模型的生成質量,更重要的是提高了模型與人類偏好的對齊度。
隨著技術的不斷發展和優化,預計SPPO及其衍生技術將在人工智慧的可持續發展和社會應用中發揮更大的作用,為構建更智慧和負責任的AI系統鋪路。
以上是人類偏好就是尺! SPPO對齊技術讓大語言模型左右互搏、自我博弈的詳細內容。更多資訊請關注PHP中文網其他相關文章!







































