

基於圖像的3D重建是一項具有挑戰性的任務,涉及從一組輸入圖像推斷目標或場景的3D形狀。基於學習的方法因其直接估計3D形狀的能力而受到關注。這篇綜述論文的重點是最先進的3D重建技術,包括產生新穎的、看不見的視野。概述了高斯飛濺方法的最新發展,包括輸入類型、模型結構、輸出表示和訓練策略。也討論了尚未解決的挑戰和未來的方向。鑑於該領域的快速進展以及增強3D重建方法的眾多機會,對演算法進行全面檢查似乎至關重要。因此,本研究對高斯散射的最新進展進行了全面的概述。
(大拇指往上滑,點擊最上方的卡片追蹤我,整個操作只會花你1.328 秒,然後帶走未來、所有、免費的乾貨,萬一有內容對您有幫助呢~)
3D重建和NVS是電腦圖形學中兩個密切相關的領域,旨在捕捉和渲染物理場景的逼真3D表示。 3D重建涉及從通常從不同視點捕獲的一系列2D影像中提取幾何和外觀資訊。儘管有許多用於3D掃描的技術,但這種對不同2D影像的捕捉是收集關於3D環境的資訊的非常簡單且計算成本低廉的方式。然後,這些資訊可以用於創建場景的3D模型,該3D模型可用於各種目的,例如虛擬實境(VR)應用、擴增實境(AR)覆蓋或電腦輔助設計(CAD)建模。
另一方面,NVS專注於從先前取得的3D模型產生場景的新2D視圖。這允許從任何期望的視點創建場景的逼真圖像,即使原始圖像不是從該角度拍攝的。深度學習的最新進展導致了3D重建和NVS的顯著改進。深度學習模型可用於有效地從影像中提取3D幾何結構和外觀,此類模型也可用於從3D模型中產生逼真的新穎視圖。因此,這些技術在各種應用中越來越受歡迎,預計它們在未來將發揮更重要的作用。
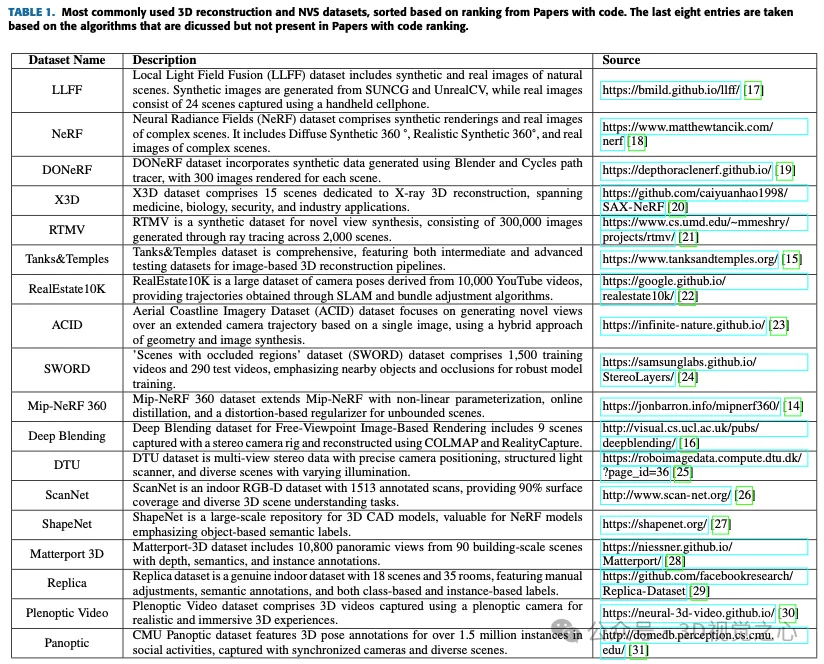
本節將介紹如何儲存或表示3D數據,然後介紹用於該任務的最常用的公開數據集,然後將擴展各種演算法,主要關注高斯飛濺。
三維資料的複雜空間性質,包括體積維度,提供了目標和環境的詳細表示。這對於在各個研究領域創建沉浸式模擬和精確模型至關重要。三維資料的多維結構允許結合深度、寬度和高度,從而在建築設計和醫學成像技術等學科中取得重大進展。
資料表示的選擇在眾多3D深度學習系統的設計中扮演著至關重要的角色。點雲缺乏網格狀結構,通常無法直接進行卷積。另一方面,以網格狀結構為特徵的體素表示通常會產生高的計算記憶體需求。
3D表示的演變伴隨著3D資料或模型的儲存方式。最常用的3D資料表示可以分為傳統方法和新穎方法。
Traditional Approaches:

Novel Approaches:
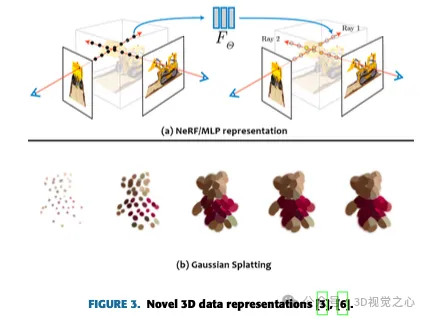
為了評估該領域的當前進展,進行了一項文獻研究,確定並仔細審查了相關的學術著作。分析特別集中在兩個關鍵領域:三維重建和NVS。從多個相機影像進行3D體積重建的發展跨越了幾十年,在電腦圖形、機器人和醫學影像中有著不同的應用。下一部分將探討該技術的現狀。
攝影測量:自1980年代以來,出現了先進的攝影測量和立體視覺技術,自動辨識立體影像對中的對應點。攝影測量是一種將攝影和電腦視覺結合來產生物件或場景的3D模型的方法。它需要從各種角度捕捉影像,利用Agisoft Metashape等軟體來估計相機位置並產生點雲。該點雲隨後被轉換為有紋理的3D網格,從而能夠創建重建目標或場景的詳細和照片級真實感視覺化。
Structure from motion:在20世紀90年代,SFM技術獲得了突出地位,能夠從2D影像序列中重建3D結構和相機運動。 SFM是從一組2D影像中估計場景的3D結構的過程。 SFM需要影像之間的點相關性。透過匹配特徵或追蹤多個影像中的點來找到對應的點,並進行三角測量以找到3D位置。
深度學習:近年來,深度學習技術,特別是卷積神經網路(CNNs)得到了融合。基於深度學習的方法在三維重建中加快了步伐。最值得注意的是3D佔用網絡,這是一種為3D場景理解和重建而設計的神經網路架構。它透過將3D空間劃分為小的體積單元或體素來操作,每個體素表示它是包含目標還是為空空間。這些網路使用深度學習技術,如3D卷積神經網絡,來預測體素佔用率,使其對機器人、自動駕駛汽車、擴增實境和3D場景重建等應用具有價值。這些網路在很大程度上依賴卷積和變換器。它們對於避免碰撞、路徑規劃和與物理世界的即時互動等任務至關重要。此外,3D佔用網路可以估計不確定性,但在處理動態或複雜場景時可能存在計算限制。神經網路架構的進步不斷提高其準確性和效率。
神經輻射場:NeRF於2020年推出,它將神經網路與經典的三維重建原理相結合,在電腦視覺和圖形學中引起了顯著關注。它透過建模體積函數、透過神經網路預測顏色和密度來重建詳細的3D場景。 NeRFs在電腦圖形學和虛擬實境中得到了廣泛應用。最近,NeRF透過廣泛的研究提高了準確性和效率。最近的研究也探討了NeRF在水下場景中的適用性。雖然提供3D場景幾何的穩健表示,但計算需求等挑戰仍然存在。未來的NeRF研究需要專注於可解釋性、即時渲染、新穎的應用程式和可擴展性,為虛擬實境、遊戲和機器人技術開闢道路。
高斯散射:最後,在2023年,3D高斯散射作為一種新的即時3D渲染技術出現了。在下一節中,將詳細討論這種方法。
高斯飛濺使用許多3D高斯或粒子來描繪3D場景,每個高斯或粒子都配有位置、方向、比例、不透明度和顏色資訊。若要渲染這些粒子,請將其轉換為二維空間,並對其進行策略性組織以實現最佳渲染。
圖4顯示了高斯飛濺演算法的體系結構。在原始演算法中,採取了以下步驟:
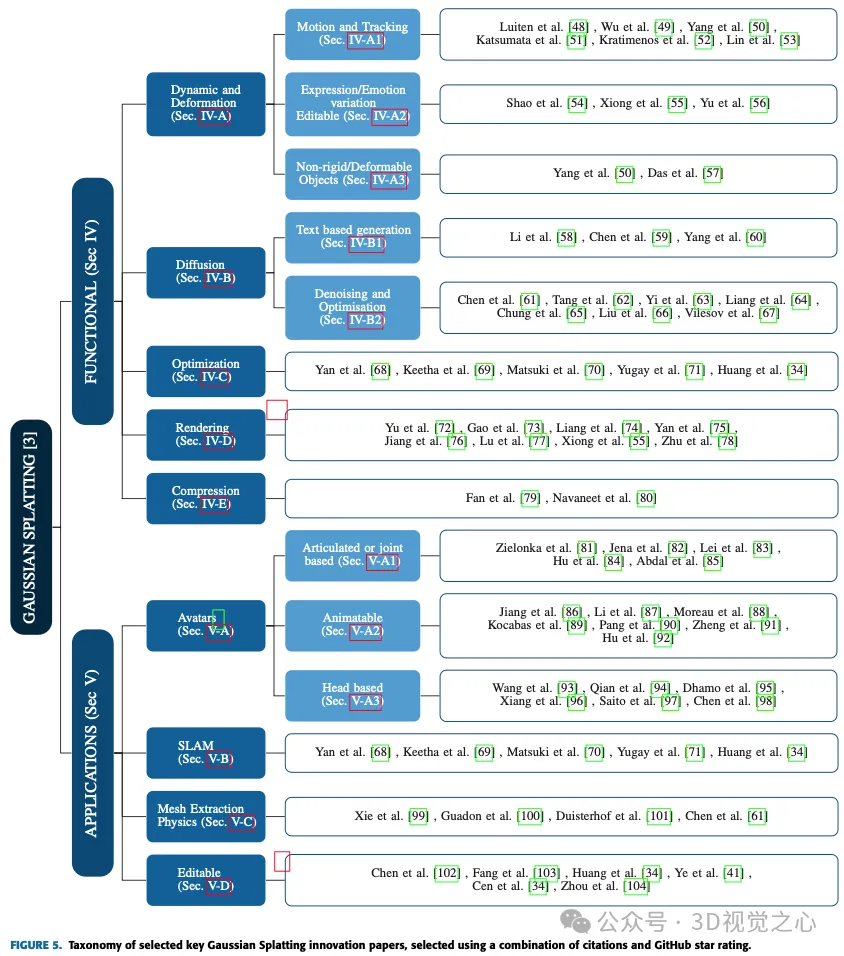
在接下來的兩節中,將探索高斯飛濺的各種應用和進步,深入研究其在自動駕駛、化身、壓縮、擴散、動力學和變形、編輯、基於文字的生成、網格提取和物理、正則化和優化、渲染、稀疏表示以及同時定位和映射(SLAM)等領域的不同實現。將對每個子類別進行檢查,以深入了解高斯飛濺方法在應對特定挑戰和在這些不同領域取得顯著進展方面的多用途。圖5顯示了所有方法的完整清單。
本節檢視了自首次引入高斯飛濺演算法以來在功能能力方面取得的進展。
與一般的高斯飛濺相比,其中3D協方差矩陣的所有參數僅取決於輸入影像,在這種情況下,為了捕捉飛濺隨時間的動態,有些參數取決於時間或時間步長。例如,位置取決於時間步長或幀。該位置可以由下一幀以時間一致的方式更新。還可以學習一些潛在的編碼,這些編碼可以用於在渲染期間的每個時間步長中編輯或傳播高斯,以實現某些效果,如化身中的表情變化,以及向非剛體施加力。圖6顯示了一些基於動力學和變形的方法。
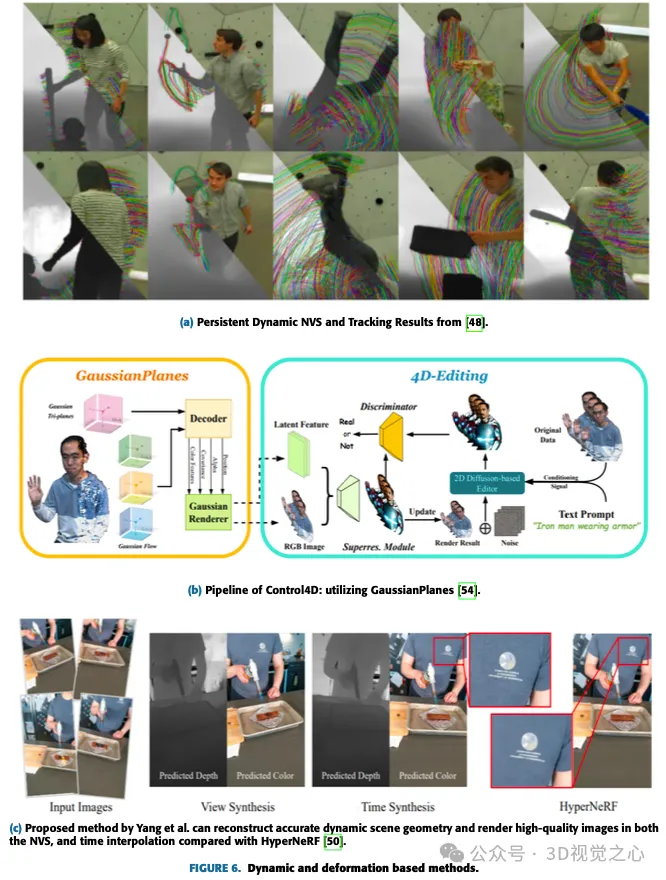
動態和可變形模型可以很容易地透過原始高斯飛濺表示的輕微修改來表示:

Motion and Tracking
大多數與動態高斯飛濺相關的工作都擴展到跨時間步長的3D高斯運動跟踪,而不是每個時間步長都有一個單獨的飛濺。 Katsumata等人提出了位置的傅立葉近似和旋轉四元數的線性近似。
Luiten等人的论文介绍了一种在动态场景中捕获所有3D点的全6个自由度的方法。通过结合局部刚度约束,动态3D高斯表示一致的空间旋转,实现了密集的6自由度跟踪和重建,而无需对应或流输入。该方法在2D跟踪中优于PIP,实现了10倍低的中值轨迹误差、更高的轨迹精度和100%的生存率。这种通用的表示方式有助于4维视频编辑、第一人称视图合成和动态场景生成等应用。
Lin等人介绍了一种新的双域变形模型(DDDM),该模型被明确设计为对每个高斯点的属性变形进行建模。该模型使用频域的傅立叶级数拟合和时域的多项式拟合来捕获与时间相关的残差。DDDM擅长处理复杂视频场景中的变形,无需为每帧训练单独的3D高斯飞溅(3D-GS)模型。值得注意的是,离散高斯点显式变形建模保证了快速训练和4D场景渲染,类似于用于静态3D重建的原始3D-GS。这种方法具有显著的效率提高,与3D-GS建模相比,训练速度几乎快了5倍。然而,在最终渲染中,在保持高保真度薄结构方面存在增强的机会。
Expression or Emotion variation and Editable in Avatars
Shao等人介绍了GaussianPlanes,这是一种通过在三维空间和时间中基于平面的分解实现的4D表示,提高了4D编辑的有效性。此外,Control4D利用4D生成器优化不一致照片的连续创建空间,从而获得更好的一致性和质量。所提出的方法使用GaussianPlanes来训练4D肖像场景的隐式表示,然后使用高斯渲染将其渲染为潜在特征和RGB图像。基于生成对抗性网络(GAN)的生成器和基于2D扩散的编辑器对数据集进行细化,并生成真实和虚假图像进行区分。判别结果有助于生成器和鉴别器的迭代更新。然而,由于依赖于具有流量表示的规范高斯点云,该方法在处理快速和广泛的非刚性运动方面面临挑战。该方法受ControlNet的约束,将编辑限制在粗略级别,并阻止精确的表达或动作编辑。此外,编辑过程需要迭代优化,缺少一个单一步骤的解决方案。
Non-Rigid or deformable objects
隐式神经表示在动态场景重建和渲染中带来了重大变革。然而,当代动态神经渲染方法在捕捉复杂细节和实现动态场景实时渲染方面遇到了挑战。
为了应对这些挑战,Yang等人提出了用于高保真单目动态场景重建的可变形3D高斯。提出了一种新的可变形3D-GS方法。该方法利用了在具有变形场的规范空间中学习的3D高斯,该变形场专门为单目动态场景设计。该方法引入了一种为真实世界的单目动态场景量身定制的退火平滑训练(AST)机制,有效地解决了错误姿势对时间插值任务的影响,而不引入额外的训练开销。通过使用差分高斯光栅化器,可变形的3D高斯不仅提高了渲染质量,而且实现了实时速度,在这两个方面都超过了现有的方法。该方法被证明非常适合于诸如NVS之类的任务,并且由于其基于点的性质而为后期生产任务提供了多功能性。实验结果强调了该方法优越的渲染效果和实时性,证实了其在动态场景建模中的有效性。
DIFFUSION
扩散和高斯飞溅是一种从文本描述/提示生成3D目标的强大技术。它结合了两种不同方法的优点:扩散模型和高斯散射。扩散模型是一种神经网络,可以学习从有噪声的输入中生成图像。通过向模型提供一系列越来越干净的图像,模型学会扭转图像损坏的过程,最终从完全随机的输入中生成干净的图像。这可以用于从文本描述生成图像,因为模型可以学习将单词与相应的视觉特征相关联。具有扩散和高斯飞溅的文本到3D管道的工作原理是首先使用扩散模型从文本描述生成初始3D点云。然后使用高斯散射将点云转换为一组高斯球体。最后,对高斯球体进行渲染,以生成目标的3D图像。
Text based generation
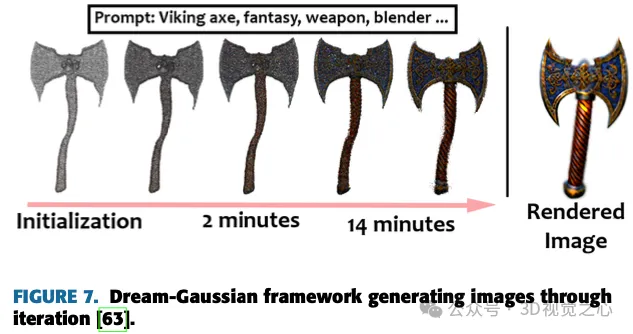
Yi等人的工作介紹了Gaussian Dreamer,這是一種文本到3D的方法,透過高斯分裂無縫連接3D和2D擴散模型,確保3D一致性和複雜的細節生成。圖7顯示了所提出的生成影像的模型。為了進一步豐富內容,引入了噪音點增長和顏色擾動來補充初始化的3D高斯。此方法的特點是簡單有效,在單一GPU上15分鐘內產生3D實例,與先前的方法相比,速度優越。產生的三維實例可以直接即時渲染,突顯了此方法的實用性。整體框架包括使用3D擴散模型先驗進行初始化,並使用2D擴散模型進行最佳化,透過利用兩個擴散模型的優勢,能夠從文字提示創建高品質和多樣化的3D資產。
Chen等人提出了基於高斯散射的文本到3D生成(GSGEN),這是一種利用3D高斯作為表示的文本到三維生成方法。透過利用幾何先驗,強調高斯散點在文本到三維生成的獨特優勢。兩階段優化策略結合了二維和三維擴散的聯合指導,在幾何優化中形成連貫的粗糙結構,然後在基於緊湊性的外觀細化中緻密化。
Denoising and Optimisation
李等人的GaussianDiffusion框架代表了一種新穎的文本到三維方法,利用高斯飛濺和Langevin動力學擴散模型來加速渲染並實現無與倫比的真實感。結構化雜訊的引入解決了多視圖幾何挑戰,而變分高斯散射模型則緩解了收斂問題和偽影。雖然目前的結果顯示真實性有所提高,但正在進行的研究旨在細化變分高斯引入的模糊度和霧度,以進一步增強。
楊等人對現有的擴散先驗進行了徹底的檢查,提出了一個統一的框架,透過優化去噪分數來改進這些先驗。該方法的多功能性擴展到各種用例,始終如一地提供實質的效能增強。在實驗評估中,我們的方法取得了前所未有的性能,超過了當代的方法。儘管它在細化3D生成的紋理方面取得了成功,但在增強生成的3D模型的幾何結構方面仍有改進的空間。
本小節將討論研究人員為更快的訓練和/或推理速度而開發的技術。在Chung等人的研究中,引入了一種方法來優化高斯散射,以使用有限數量的圖像進行3D場景表示,同時緩解過度擬合問題。以高斯散點表示3D場景的傳統方法可能導致過擬合,特別是當可用影像有限時。該技術使用來自預先訓練的單目深度估計模型的深度圖作為幾何指南,並與來自SFM管道的稀疏特徵點對齊。這些有助於優化3D高斯散射,減少浮動偽影並確保幾何相干性。所提出的深度引導優化策略在LLFF資料集上進行了測試,與僅使用影像相比,顯示了改進的幾何結構。研究包括引入提前停止策略和深度圖的平滑項,這兩項都有助於提高效能。然而,也承認存在局限性,例如依賴單目深度估計模型的準確性以及依賴COLMAP的性能。建議未來的工作探索相互依存的估計深度,並解決深度估計困難地區的挑戰,例如無紋理平原或天空。
傅等人介紹了COLMAP Free 3D Gaussian Splatting(CF-3DGS),這是一種新的端到端框架,用於從序列圖像中同時進行相機姿態估計和NVS,解決了以前方法中相機運動量大和訓練持續時間長帶來的挑戰。與NeRF的隱式表示不同,CF-3DGS利用顯式點雲來表示場景。此方法依序處理輸入幀,逐步擴展3D高斯以重建整個場景,在具有挑戰性的場景(如360°視訊)上展示了增強的效能和穩健性。此方法以順序的方式共同優化相機姿勢和3D-GS,使其特別適合視訊串流或有序的影像擷取。高斯飛濺的使用能夠實現快速的訓練和推理速度,展示了這種方法相對於先前方法的優勢。在證明有效性的同時,人們承認,順序優化將應用程式主要限制在有序的圖像集合上,這為在未來的研究中探索無序圖像集合的擴展留下了空間。
Yu等人在3D-GS中觀察到,特別是當改變取樣率時,NVS中會出現偽影。引入的解決方案包括結合3D平滑濾波器來調節3D高斯基元的最大頻率,從而解決分佈外渲染中的偽影。此外,2D膨脹濾波器被2D Mip濾波器取代,以解決混疊和膨脹問題。對基準資料集的評估證明了Mip Splatting的有效性,尤其是在修改採樣率時。所提出的修改是原則性的、直截了當的,需要對原始3D-GS程式碼進行最小的更改。然而,也存在公認的局限性,例如高斯濾波器近似引入的誤差和訓練開銷的輕微增加。該研究將Mip Splatting作為一種具有競爭力的解決方案,展示了其與最先進的方法的性能相當,以及在分發外場景中的卓越泛化能力,展示了它在實現任意規模的無別名渲染方面的潛力。
Gao等人提出了一種新的3D點雲渲染方法,該方法能夠從多視圖影像中分解材質和照明。該框架支援以可區分的方式對場景進行編輯、光線追蹤和即時重新照明。場景中的每個點都由「可重新照明」的3D高斯表示,攜帶有關其法線方向、雙向反射分佈函數(BRDF)等材料特性以及來自不同方向的入射光的資訊。為了精確的照明估計,入射光被分為全局和局部分量,並考慮基於視角的可見性。場景最佳化利用3D高斯飛濺,而基於物理的可微分渲染處理BRDF和照明分解。一種創新的基於點的光線追蹤方法利用邊界體層次結構,在即時渲染過程中實現了高效的可見性烘焙和逼真的陰影。實驗表明,與現有方法相比,BRDF估計值和視圖渲染效果更好。然而,對於沒有明確邊界和優化過程中需要目標遮罩的場景,仍存在挑戰。未來的工作可以探索整合多視圖立體(MVS)線索,以提高透過3D高斯散射產生的點雲的幾何精度。這種「可靠的3D高斯」管道展示了很有前途的即時渲染功能,並透過基於點雲的方法為革命性地基於網格的圖形打開了大門,該方法允許重新照明、編輯和光線追蹤。
Fan等人介紹了一種用於壓縮渲染中使用的3D高斯表示的新技術。他們的方法根據其重要性識別並刪除冗餘高斯,類似於網路修剪,確保對視覺品質的影響最小。利用知識提取和偽視圖增強,LightGaussian將訊息傳遞到具有較少球面諧波的較低複雜度表示,從而進一步減少冗餘。此外,一種稱為VecTree量化的混合方案透過量化屬性值來最佳化表示,從而在精度沒有顯著損失的情況下實現更小的尺寸。與標準方法相比,LightGaussian實現了超過15倍的平均壓縮比,在Mip NeRF 360和Tanks&Temples等資料集上,渲染速度從139 FPS顯著提高到215 FPS。所涉及的關鍵步驟是計算全局顯著性、修剪高斯、用偽視圖提取知識以及使用VecTree量化屬性。總的來說,LightGaussian為將基於大點的表示轉換為緊湊格式提供了一個突破性的解決方案,從而顯著減少了資料冗餘,並大幅提高了渲染效率。
本節深入探討了自2023年7月高斯飛濺演算法問世以來,該演算法在應用方面的顯著進步。這些進步在各種領域都有特定的用途,如化身、SLAM、網格提取和物理模擬。當應用於這些專門的用例時,Gaussian Splatting在不同的應用場景中展示了它的多功能性和有效性。
隨著AR/VR應用熱潮的興起,高斯飛濺的大量研究都集中在開發人類的數位化身上。從較少的視角捕捉主題並建立3D模型是一項具有挑戰性的任務,高斯飛濺正幫助研究人員和產業實現這一目標。
Joint angles or articulation
這種高斯散射技術專注於根據關節角度對人體進行建模。這類模型的一些參數反映了三維關節的位置、角度和其他類似的參數。對輸入影格進行解碼以找出目前影格的3D關節位置和角度。
Zielonka等人提出了一種使用高斯散射的人體表示模型,並利用創新的3D-GS技術實現了即時渲染。與現有的照片級真實感可駕駛化身不同,可駕駛3D高斯飛濺(D3GA)不依賴訓練期間的精確3D配準或測試期間的密集輸入影像。相反,它利用密集校準的多視圖視訊進行即時渲染,並引入了由關節中的關鍵點和角度驅動的基於四面體籠的變形,使其對涉及通訊的應用程式有效,如圖9所示。

Animatable
#這些方法通常訓練依賴位姿的高斯圖來捕捉複雜的動態外觀,包括服裝中更精細的細節,從而產生高品質的化身。其中一些方法還支援即時渲染功能。

薑等人提出了HiFi4G,這個方法可以有效地渲染真實的人類。 HiFi4G將3D高斯表示與非剛性追蹤結合,採用運動先驗的對偶圖機制和具有自適應時空正則化器的4D高斯優化。 HiFi4G實現了約25倍的壓縮率,每幀需要不到2MB的儲存空間,在優化速度、渲染品質和儲存開銷方面表現出色,如圖10所示。它提出了一種緊湊的4D高斯表示,橋接高斯飛濺和非剛性追蹤。然而,對分割的依賴性、對導致偽影的較差分割的敏感性,以及對每幀重建和網格追蹤的需求都造成了限制。未來的研究可能著重於加速最佳化過程和減少GPU排序依賴性,以便在網路檢視器和行動裝置上進行更廣泛的部署。
Head based
先前的頭部化身方法大多依賴固定的顯式基元(網格、點)或隱式曲面(SDF)。基於高斯散射的模型將為AR/VR和基於濾鏡的應用的興起鋪平道路,讓使用者嘗試不同的妝容、色調、髮型等。
王等人利用規範的高斯變換來表示動態場景。使用顯式「動態」三平面作為參數化頭部幾何的有效容器,與底層幾何和三平面中的因子很好地對齊,作者獲得了正則高斯的對齊正則因子。使用微小的MLP,因子被解碼為3D高斯基元的不透明度和球面諧波係數。 Quin等人創造了具有可控視角、姿勢和表情的超逼真頭部化身。在化身重構過程中,作者同時對變形模型參數和高斯splat參數進行了最佳化。該作品展示了化身在各種具有挑戰性的場景中的動畫能力。 Dhamo等人提出了HeadGaS,這是一種混合模型,以可學習的潛在特徵為基礎,擴展了3D-GS的顯式表示。然後,這些特徵可以與來自參數化頭部模型的低維參數線性混合,以導出依賴表情的最終顏色和不透明度值。圖11顯示了一些範例影像。
SLAM
SLAM是自動駕駛汽車中使用的一種技術,用於同時建立地圖並確定車輛在該地圖內的位置。它使車輛能夠導航和繪製未知環境的地圖。顧名思義,視覺SLAM(vSLAM)依賴來自相機和各種影像感測器的影像。這種方法適用於各種相機類型,包括簡單、複眼和RGB-D相機,使其成為具有成本效益的解決方案。透過相機,可以將地標偵測與基於圖形的最佳化相結合,增強SLAM實現的靈活性。單眼SLAM是vSLAM的一個子集,使用單一相機,在深度感知方面面臨挑戰,這可以透過結合額外的感測器來解決,如里程計和慣性測量單元(IMU)的編碼器。與vSLAM相關的關鍵技術包括SFM、視覺里程計和束調整。視覺SLAM演算法分為兩大類:稀疏方法,採用特徵點匹配(例如,平行追蹤和映射,ORB-SLAM),密集方法,利用整體影像亮度(例如,DTAM,LSD-SLAM,DSO,SVO)。
高斯散射可以用於基於物理的模擬和渲染。透過在三維高斯核中添加更多的參數,可以對速度、應變和其他力學特性進行建模。這就是為什麼在幾個月內開發了各種方法,包括使用高斯散射模擬物理學。

謝等人介紹了一種基於連續體力學的三維高斯運動學方法,採用偏微分方程(PDE)來驅動高斯核及其相關球面諧波的演化。這項創新允許使用統一的模擬渲染管道,透過消除對顯式目標網格的需求來簡化運動生成。他們的方法透過在各種材料上進行全面的基準測試和實驗,展示了多功能性,在具有簡單動力學的場景中展示了即時性能。作者介紹了PhysGaussian,這是一個同時無縫生成基於物理的動力學和照片逼真渲染的框架。在承認框架中缺乏陰影演化和使用單點求積進行體積積分等局限性的同時,作者提出了未來工作的途徑,包括在材料點法(MPM)中採用高階求積,並探索神經網路的整合以實現更真實的建模。該框架可以擴展到處理各種材料,如液體,並結合利用大型語言模型(LLM)進步的使用者控制。圖13顯示了PhysGaussian框架的訓練過程。
高斯飛濺也將翅膀擴展到場景的3D編輯和點操縱。使用將要討論的最新進展,甚至可以對場景進行基於提示的3D編輯。這些方法不僅將場景表示為3D高斯圖,而且對場景具有語義和爭議性的理解。
Chen等人介紹了GaussianEditor,這是一種基於高斯Splatting的新型三維編輯演算法,旨在克服傳統三維編輯方法的局限性。雖然依賴網格或點雲的傳統方法難以進行逼真的描繪,但像NeRF這樣的隱式3D表示面臨著處理速度慢和控制有限的挑戰。 GaussianEditor透過利用3D-GS來解決這些問題,透過高斯語義追蹤增強精度和控制,並引入層次高斯飛濺(HGS),在生成指導下獲得穩定和精細的結果。該演算法包括一種專門的3D修復方法,用於有效地去除和整合物體,在廣泛的實驗中顯示出卓越的控制能力、功效和快速性能。圖14顯示了Chen等人測試的各種文字提示。 GaussianEditor標誌著3D編輯的重大進步,提供了增強的有效性、速度和可控性。研究的貢獻包括引入高斯語義追蹤進行詳細編輯控制,提出HGS在生成指導下實現穩定收斂,開發用於快速刪除和添加目標的3D修復演算法,以及大量實驗證明該方法優於先前的3D編輯方法。儘管GaussianEditor取得了進步,但它依賴於二維擴散模型進行有效監督,在處理複雜提示方面存在局限性,這是基於類似模型的其他三維編輯方法面臨的共同挑戰。

傳統上,3D場景是使用網格和點來表示的,因為它們的明確性質以及與基於GPU/CUDA的快速光柵化的兼容性。然而,最近的進步,如NeRF方法,專注於連續場景表示,採用了多層感知器優化等技術,透過體積射線行進進行新的視圖合成。雖然連續表示有助於最佳化,但渲染所需的隨機取樣會引入昂貴的雜訊。高斯飛濺透過利用3D高斯表示進行最佳化,實現最先進的視覺品質和有競爭力的訓練時間,彌補了這一差距。此外,基於瓦片的飛濺解決方案可確保即時渲染具有頂級品質。在渲染3D場景時,高斯飛濺在品質和效率方面提供了一些最佳結果。
高斯飛濺已經發展到透過修改其原始表示來處理動態和可變形目標。這涉及到合併參數,例如3D位置、旋轉、縮放因子和顏色和不透明度的球面諧波係數。該領域的最新進展包括引入稀疏性損失以鼓勵ba-sis軌跡共享,引入雙域變形模型以捕捉與時間相關的殘差,以及將生成器網路與3D高斯渲染連接起來的高斯殼映射。也努力解決非剛性追蹤、化身表情變化和高效渲染逼真人類表現等挑戰。這些進步共同致力於在處理動態和可變形目標時實現即時渲染、優化效率和高品質結果。
在另一個方面,擴散和高斯飛濺協同作用,從文字提示建立3D目標。擴散模型是一種神經網絡,它透過一系列越來越乾淨的影像來逆轉影像損壞的過程,從而學習從有雜訊的輸入中生成影像。在文字到三維管道中,擴散模型根據文字描述產生初始三維點雲,然後使用高斯散射將其轉換為高斯球體。渲染的高斯球體產生最終的三維目標影像。此領域的進展包括使用結構化雜訊來解決多視圖幾何挑戰,引入變分高斯散射模型來解決收斂問題,以及優化去噪分數以增強擴散先驗,旨在實現基於文字的3D生成中無與倫比的真實性和性能。
高斯飛濺已被廣泛應用於AR/VR應用的數位化身的創建。這涉及從最小數量的視點捕捉目標並建立3D模型。該技術已被用於建模人體關節、關節角度和其他參數,從而能夠產生富有表現力和可控的化身。這一領域的進步包括開發捕捉高頻面部細節、保留誇張表情和有效變形化身的方法。此外,還提出了混合模型,將明確表示與可學習的潛在特徵相結合,以實現與表達相關的最終顏色和不透明度值。這些進步旨在增強生成的3D模型的幾何形狀和紋理,以滿足AR/VR應用中對逼真和可控化身日益增長的需求。
Gaussian Splatting也在SLAM中找到了多功能的應用,在GPU上提供即時追蹤和建圖功能。透過使用3D高斯表示和可微分的飛濺光柵化管道,它實現了真實世界和合成場景的快速和真實感渲染。該技術擴展到網格提取和基於物理的模擬,允許在沒有明確目標網格的情況下對機械特性進行建模。連續介質力學和偏微分方程的進步使高斯核得以進化,簡化了運動生成。值得注意的是,最佳化涉及高效的資料結構,如OpenVDB、用於對齊的正則化項和用於減少誤差的物理啟發項,從而提高了整體效率和準確性。在壓縮和提高高斯散射渲染效率方面也做了其他工作。
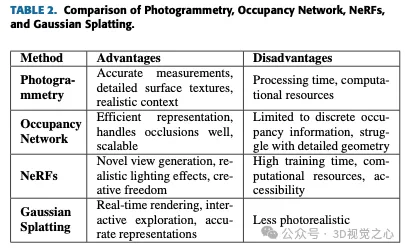
從表2可以清楚看出,在撰寫本文時,高斯飛濺是最接近即時渲染和動態場景表示的選項。佔用網路根本不是為NVS用例量身訂做的。攝影測量是創建具有強烈背景感的高度準確和逼真的模型的理想選擇。 NeRF擅長產生新穎的視野和逼真的照明效果,提供創作自由和處理複雜場景。高斯飛濺在其實時渲染功能和互動式探索方面大放異彩,使其適用於動態應用程式。每種方法都有其利基市場,並相互補充,為3D重建和視覺化提供了各種各樣的工具。
儘管高斯飛濺是一種非常穩健的技術,但它也有一些需要注意的地方。其中一些列出如下:
即時3D重建技術將實現電腦圖形學和相關領域的多種功能,例如即時互動探索3D場景或模型,透過即時回饋操縱視點和目標。它還可以即時渲染具有移動目標或不斷變化的環境的動態場景,增強真實感和沈浸感。即時3D重建可用於模擬和訓練環境,為汽車、航空航太和醫學等領域的虛擬場景提供逼真的視覺回饋。它還將支援沉浸式AR和VR體驗的即時渲染,用戶可以即時與虛擬目標或環境互動。整體而言,即時高斯飛濺增強了電腦圖形、視覺化、模擬和沈浸式技術中各種應用的效率、互動性和真實性。
在本文中,我們討論了與用於三維重建和新視圖合成的高斯散射相關的各種功能和應用方面。它涵蓋了動態和變形建模、運動追蹤、非剛性/可變形目標、表情/情緒變化、基於文字的生成擴散、去噪、優化、化身、可動畫目標、基於頭部的建模、同步定位和規劃、網格提取和物理、最佳化技術、編輯功能、渲染方法、壓縮等主題。
具體而言,本文深入探討了基於影像的3D重建的挑戰和進展,基於學習的方法在改進3D形狀估計中的作用,以及高斯飛濺技術在處理動態場景、互動式目標操作、3D分割和場景編輯中的潛在應用和未來方向。
高斯飛濺在不同領域具有變革意義,包括電腦生成圖像、VR/AR、機器人、電影和動畫、汽車設計、零售、環境研究和航空航天應用。然而,值得注意的是,與NeRFs等其他方法相比,高斯散射在實現真實感方面可能存在局限性。此外,還應考慮與過擬合、計算資源和渲染品質限制相關的挑戰。儘管有這些局限性,但高斯散射的持續研究和進步仍在繼續解決這些挑戰,並進一步提高該方法的有效性和適用性。
以上是不只3D高斯!最新綜述一覽最先進的3D重建技術的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































