

論文標題:
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
#論文作者:
Peijin Jia, Tuopu Wen, Ziang Luo, Mengmeng Yang, Kun Jiang, Zhiquan Lei, Xuewei Tang, Ziyuan Liu, Le Cui, Kehua Sheng, Bo Zhang, Diange Yang
自動駕駛車輛輛來說,高清(HD)地圖能夠足以幫助其提高對環境理解(感知)的準確度和導航的精度。然而,人工建圖面臨臨繁雜和高成本的問題。為此,目前研究將地圖建構整合到BEV(鳥瞰視角)感知任務中,在BEV空間中建構柵格化HD地圖視為分割任務,可以理解為獲得BEV特徵後增加使用類似於FCN(全卷積網)的分割頭。例如,HDMapNet透過LSS(Lift,Splat,Shoot)編碼感測器特徵,然後採用多解析度FCN進行語意分割、實例偵測和方向預測來建構地圖。
然而,目前此類方法(基於像素的分類方法)仍存在固有局限性,包括可能忽略特定分類屬性,這可能導致分隔帶扭曲和中斷、行人橫道模糊以及其他類型的偽影和噪聲,如圖1(a)所示。這些問題不僅影響地圖的結構精度,也可能直接影響自動駕駛系統的下游路徑規劃模組。
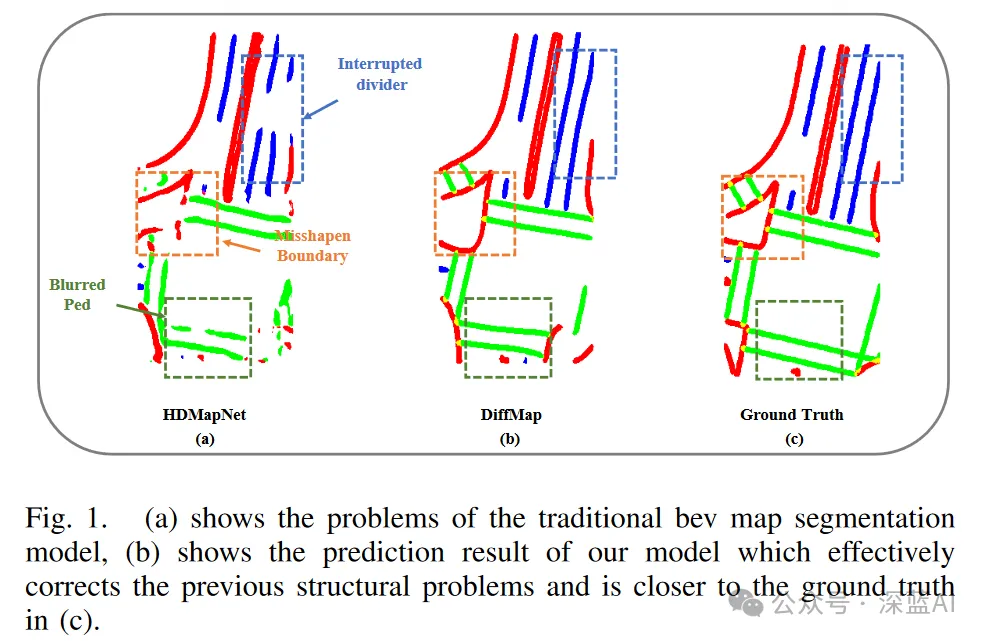
▲圖1|HDMapNet,DiffMap和GroundTruth效果比較
因此,模型最好能考慮HD地圖的結構先驗訊息,如車道線的平行和筆直特性。一些生成模型在捕捉影像真實性和固有特性備這樣的能力。例如,LDM(潛在擴散模型)在高保真影像生成方面展現了巨大潛力,並在與分割增強相關的任務中證明了其有效性。另外,還可以透過引入控制變量,進一步指導影像生成以滿足特定的控制要求。因此,將生成模型應用於捕捉地圖結構先驗,可望減少分割偽影並提高地圖建構效能。
在本文中,作者提到DiffMap網路。該網路首次透過使用改進的LDM作為增強模組,對現有的分割模型進行地圖結構化先驗建模並支援即插即用。 DiffMap不僅能透過添加和刪除雜訊的過程學習地圖先驗,以確保輸出與當前幀觀測相匹配,還可以將BEV特徵集成為控制訊號,以確保輸出與當前幀觀測相匹配。實驗結果表明,DiffMap能夠有效地產生更平滑合理的地圖分割結果,同時大大減少了偽影,提高了整體的地圖建構效能。
2.1 語意地圖建構
在傳統的高清(HD)在地圖建構中,語意地圖通常是基於光達點雲手動或半自動標註的。一般基於SLAM的演算法來建立全域一致的地圖,並手動為地圖添加語意標註。然而,這種方法費時費力,同時在更新地圖方面也存在極大挑戰,這限制了其可擴展性和即時效能。
HDMapNet提出了一種使用車載感測器動態建構局部語意地圖的方法。它將雷射雷達點雲和全景圖像特徵編碼到鳥瞰視圖(BEV)空間,並使用三個不同的頭部進行解碼,最終產生一個向量化的局部語義地圖。 SuperFusion專注於建立遠程高精度語義地圖,利用光達深度資訊增強影像深度估計,並使用影像特徵引導遠端雷射雷達特徵預測。接著採用類似HDMapNet的地圖偵測頭獲得語意地圖。 MachMap將任務劃分為折線檢測和多邊形實例分割,並使用後處理來細化遮罩以獲得最終結果。後續的研究聚焦在端到端線上建圖,直接獲得向量化的高清地圖。無需手動標註的語義地圖動態構建有效地降低了構建成本。
2.2 擴散模型應用於分割和偵測
去雜訊擴散機率模型(DDPMs)是基於馬可夫鏈的一類生成模型,在影像生成等領域展現出優異的性能,並逐步擴展到分割和偵測等各種任務。 SegDiff將擴散模型應用於影像分割任務,其中使用的UNet編碼器進一步解耦為三個模組:E、F和G。模組G和F分別編碼輸入影像I和分割圖,然後在E中透過加法合併,以迭代地細化分割圖。 DDPMS使用基礎分割模型產生初始預測先驗,並利用擴散模型對先驗進行細化。 DiffusionDet將擴散模型擴展到目標偵測框架,將目標偵測建模為從雜訊框到目標框的去雜訊擴散過程。
擴散模型也應用於自動駕駛領域,如MagicDrive利用幾何約束合成街景,以及Motiondiffuser將擴散模型擴展到多智能體運動預測問題。
2.3 地圖先驗
#目前有幾種方法可以利用先驗資訊(包含顯式的標準地圖資訊和隱式的時間資訊)來增強模型穩健性,減少車載感測器的不確定性。 MapLite2.0以標準定義(SD)先驗地圖為起點,並結合車載感測器即時推斷局部高清地圖。 MapEx和SMERF利用標準地圖資料改善車道感知和拓樸理解。 SMERF採用基於Transformer的標準地圖編碼器編碼車道線和車道類型,然後計算標準地圖資訊與基於感測器的鳥瞰視圖(BEV)特徵之間的交叉注意力,以整合標準地圖資訊。 NMP透過將過去的地圖先驗數據與當前感知數據相結合,為自動駕駛汽車提供長期記憶能力。 MapPrior結合判別式和生成式模型,在預測階段將基於現有模型產生的初步預測編碼為先驗,注入生成模型的離散潛在空間,然後使用生成模型進行細化預測。 PreSight利用先 前行程的資料優化城市尺度的神經輻射場,產生神經先驗,增強後續導航中的線上感知。
3.1 準備工作


3.2 整體架構
如圖2所示。 DiffMap作為解碼器,將擴散模型納入語義地圖分割模型,該模型以周圍多視角影像和LiDAR點雲作為輸入,將其編碼為BEV空間並獲得融合的BEV特徵。再採用DiffMap作為解碼器產生分割圖。在DiffMap模組中,將BEV特徵作為條件來引導去噪過程。
 ▲圖2|DiffMap架構©️【深藍AI】編譯
▲圖2|DiffMap架構©️【深藍AI】編譯
◆語義地圖建構的基線:基線主要遵循BEV編碼器-解碼器範式。編碼器部分負責從輸入資料(LiDAR和/或相機資料)中提取特徵,將其轉換為高維表示。同時,解碼器通常作為分割頭,將高維特徵表示映射到相應的分割圖。基線在整個框架中起兩個主要作用:監督者和控制器。作為監督者,基線產生分割結果作為輔助監督。同時,作為控制器,它提供中間BEV特徵作為條件控制變量,以引導擴散模型的生成過程。
◆DiffMap模組:沿襲LDM,作者在基準框架中引入DiffMap模組作為解碼器。 LDM主要由兩部分組成:一個影像感知壓縮模組(如VQVAE)和一個使用UNet建構的擴散模型。首先,編碼器將地圖分割ground truth 編碼為潛在空間中的,其中表示潛在空間的低維度。隨後,在低維潛在變數空間中執行擴散和去噪,然後使用解碼器將潛在空間恢復到原始像素空間。
首先透過擴散過程添加噪聲,在每個時間步獲得噪聲潛在圖,其中。然後在去噪過程中,UNet作為噪音預測的主幹網路。為了增強分割結果的監督部分,並希望DiffMap模型在訓練期間直接為實例相關預測提供語意特徵。因此,作者將UNet網路結構分為兩個分支,一個分支用於預測噪聲,如傳統擴散模型,另一個分支用於預測潛在空間中的。
如圖3所示。獲得潛在圖預測後,將其解碼到原始像素空間,作為語義特徵圖。接著就可以依照HDMapNet提出的方法從中獲得實例預測,輸出三種不同頭的預測:語意分割、實例嵌入和車道方向。這些預測隨後用於後處理步驟以向量化地圖。

▲圖3|去雜訊模組
整個過程是一個有條件的生成過程,根據當前感測器輸入下獲得地圖分割結果。其結果的機率分佈可以建模為,其中表示地圖分割結果,表示條件控制變量,即BEV特徵。作者這裡用了兩種方式融合控制變因。首先,由於和BEV特徵在空間域上具有相同的類別和尺度,將調整為潛在空間大小,然後將它們串聯作為去噪過程的輸入,如公式5所示。
其次,將交叉注意力機制融入UNet網路的每一層,其中作為key/value,作為query。交叉注意力模組的公式如下:
3.3 具體實現
##◆訓練:

◆推理:

4.1 實驗細節
#◆資料集:在nuScenes資料集上驗證DiffMap。 nuScenes資料集包含1000個場景的多視角影像和點雲,其中700個場景用於訓練,150個用於驗證,150個用於測試。 nuScenes資料集還包含註釋的高清地圖語義標籤。
◆架構:使用ResNet-101作為相機分支的主幹網絡,使用PointPillars作為模型的LiDAR分支主幹網路。基準模型中的分割頭是基於ResNet-18的FCN網路。對於自編碼器,採用VQVAE,該模型在nuScenes分割地圖資料集上進行了預訓練,以提取地圖特徵並將地圖壓縮為基本潛在空間。最後使用UNet來建構擴散網路。
◆訓練細節:使用AdamW優化器訓練VQVAE模型30個epoch。使用的學習率調度器是LambdaLR,它以指數衰減模式逐漸降低學習率,衰減因子為0.95。初始學習率設定為,批次大小為8。然後,使用AdamW優化器從頭開始訓練擴散模型30個epoch,初始學習率為2e-4。採用MultiStepLR調度器,該調度器根據指定的里程碑時間點(0.7、0.9、1.0)和在不同訓練階段的縮放因子1/3來調整學習率。最後將BEV分割結果設定為0.15m的分辨率,並將LiDAR點雲體素化。 HDMapNet的偵測範圍為[-30m,30m]×[-15m,15m]m,因此對應的BEV地圖大小為400×200,而Superfusion使用[0m,90m]×[-15m,15m]並得到600× 200的結果。由於LDM的維度限制(在VAE和UNet中下取樣8倍),需要將語意地面實況地圖的大小填入64的倍數。
◆推理細節:透過在目前BEV特徵條件下對雜訊地圖執行去雜訊過程20次來獲得預測結果。使用3次採樣的平均值作為最終的預測結果。
4.2 評估指標
#主要針對地圖語意分割和實例偵測任務進行平評估。且主要集中在三個靜態地圖元素:車道邊界、車道分隔線和行人橫道。


4.3 評估結果
表1顯示了語意地圖分割的IoU 分數比較。 DiffMap 在所有區間都顯示出顯著的改善,尤其在車道分隔線和行人橫道上取得了最佳結果。
 ▲表1|IoU分數比較
▲表1|IoU分數比較
如表2所示,DiffMap方法在平均精確度(AP)方面也有顯著提升,驗證了DiffMap 的效能。
 ▲表2|MAP分數比較#
▲表2|MAP分數比較#
如表3所示,將DiffMap範式整合到HDMapNet中時,可以觀察到,無論是僅使用相機還是相機-雷射雷達融合方法,DiffMap都能提升HDMapNet的效能。這說明DiffMap方法在各類分割任務上都很有效,包括遠距離和近距離檢測。然而對於邊界,DiffMap的表現並不出色,這是因為邊界的形狀結構不固定,而存在許多難以預測的扭曲,從而使捕捉先驗結構特徵變得困難。
 ▲表3|定量分析結果
▲表3|定量分析結果
#4.4 消融實驗


表4顯示了VQVAE中不同下取樣因子對偵測結果的影響。透過分析DiffMap在下採樣因子為4、8、16時的行為可以看到,當下採樣因子設定為8x時,結果最佳。
▲表4|消融實驗結果
#此外,作者也測量了刪除與實例相關的預測模組對模型的影響,如表5所示。實驗表明,添加此預測進一步提高了IOU。

4.5視覺化
以上是DiffMap:首個利用LDM來增強高精地圖建構的網絡的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















