

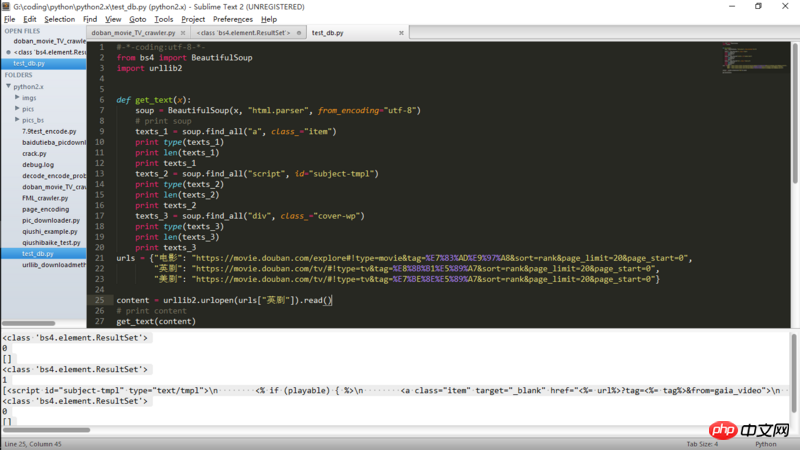
目的:在网页 https://movie.douban.com/tv/#!type=tv&tag=%E8%8B%B1%E5%89%A7&sort=rank&page_limit=20&page_start=0上抓取评分超过x的所有英剧。
问题:在得到网页内容后,无法用find_all 方法找到<p class="wp"这个标签的内容,
<a class="item"也无法找出,而其他内容能正常找出。(初学........)
部分网页源码:
<script id="subject-tmpl" type="text/tmpl">
<% if (playable) { %>
<a class="item" target="_blank" href="<%= url%>?tag=<%= tag%>&from=gaia_video">
<% } else {%>
<a class="item" target="_blank" href="<%= url%>?tag=<%= tag%>&from=gaia">
<% } %>
<p class="cover-wp" data-isnew="<%= is_new%>" data-id="<%= id%>">
<img src="<%= cover%>" alt="<%= title%>" data-x="<%= cover_x%>" data-y="<%= cover_y%>" onload="loadImg(this)" />
</p>
<p>
<% if (is_new) { %>
<span class="green">
<img src="https://img3.doubanio.com/f/movie/caa8f80abecee1fc6f9d31924cef8dd9a24c7227/pics/movie/ic_new.png" width="16" class="new" />
</span>
<% } %>
<%= title%>
<% if (rate !== '0.0') { %>
<strong><%= rate%></strong>
<% } else {%>
<span>暂无评分</span>
<% } %>
</p>
<% if (is_beetle_subject) { %>
<p style="width:140px;float:left;margin-top:-22px;cursor:default">
<img class="biz-beetle-rec" style="width:88px;height:12px;opacity:1" src="https://img3.doubanio.com/img/biz/beetle/home/biz-beetle-icon@2x.png">
</p>
<% } %>
</a>
</script>程序代码(问题部分):
#-*-coding:utf-8-*-
from bs4 import BeautifulSoup
import urllib2
def get_text(x):
soup = BeautifulSoup(x, "html.parser", from_encoding="utf-8")
# print soup
texts_1 = soup.find_all("a", class_="item")
print type(texts_1)
print len(texts_1)
print texts_1
texts_2 = soup.find_all("script", id="subject-tmpl")
print type(texts_2)
print len(texts_2)
print texts_2
texts_3 = soup.find_all("p", class_="cover-wp")
print type(texts_3)
print len(texts_3)
print texts_3
urls = {"电影": "https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=rank&page_limit=20&page_start=0",
"英剧": "https://movie.douban.com/tv/#!type=tv&tag=%E8%8B%B1%E5%89%A7&sort=rank&page_limit=20&page_start=0",
"美剧": "https://movie.douban.com/tv/#!type=tv&tag=%E7%BE%8E%E5%89%A7&sort=rank&page_limit=20&page_start=0"}
content = urllib2.urlopen(urls["英剧"]).read()
# print content
get_text(content)输出结果:
<class 'bs4.element.ResultSet'>
0
[]
<class 'bs4.element.ResultSet'>
1
[<script id="subject-tmpl" type="text/tmpl">\n <% if (playable) { %>\n <a class="item" target="_blank" href="<%= url%>?tag=<%= tag%>&from=gaia_video">\n <% } else {%>\n <a class="item" target="_blank" href="<%= url%>?tag=<%= tag%>&from=gaia">\n <% } %>\n <p class="cover-wp" data-isnew="<%= is_new%>" data-id="<%= id%>">\n <img src="<%= cover%>" alt="<%= title%>" data-x="<%= cover_x%>" data-y="<%= cover_y%>" onload="loadImg(this)" />\n </p>\n <p>\n <% if (is_new) { %>\n <span class="green">\n <img src="https://img3.doubanio.com/f/movie/caa8f80abecee1fc6f9d31924cef8dd9a24c7227/pics/movie/ic_new.png" width="16" class="new" />\n </span>\n <% } %>\n\n <%= title%>\n\n <% if (rate !== '0.0') { %>\n <strong><%= rate%></strong>\n <% } else {%>\n <span>\u6682\u65e0\u8bc4\u5206</span>\n <% } %>\n </p>\n <% if (is_beetle_subject) { %>\n <p style="width:140px;float:left;margin-top:-22px;cursor:default">\n <img class="biz-beetle-rec" style="width:88px;height:12px;opacity:1" src="https://img3.doubanio.com/img/biz/beetle/home/biz-beetle-icon@2x.png">\n </p>\n <% } %>\n </a>\n </script>]
<class 'bs4.element.ResultSet'>
0
[]
[Finished in 0.9s]截图:




























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




You can see from the code that this p tag is in the js code block. It must be run before the js code can become part of the DOM node.
But you only read the HTML source code and did not execute the js code in it.
So the HTML parser used by beautifulsoup does not consider
p class=”wp”to be part of the DOM tree, so find_all will have no result.As for the solution, it would be better if you directly write a regular match, but I’m afraid bs4 won’t work.
As for how to write regular expressions, you can read the book "You Must Know Regular Expressions" and you can finish it in 10 minutes.