
I want to capture the scores of live broadcast events: live broadcast links, but I can only capture the date, home and away teams, etc. using Scrapy. My question is: are the scores loaded via Script? Is it in bf4.js in this script? How to accurately obtain the score as shown below in this Request Method: GET situation?
The source code of the web page viewed through the developer tools is as follows: < span> -
< span> -  Wuhan ZallWuhan Culture and Sports Guangzhou Competition PPTV Text Watch live broadcast on mobile phone score UEFA Champions League New football uniform
Wuhan ZallWuhan Culture and Sports Guangzhou Competition PPTV Text Watch live broadcast on mobile phone score UEFA Champions League New football uniform
That is, the score is not displayed in - . How can we capture the rendered score webpage?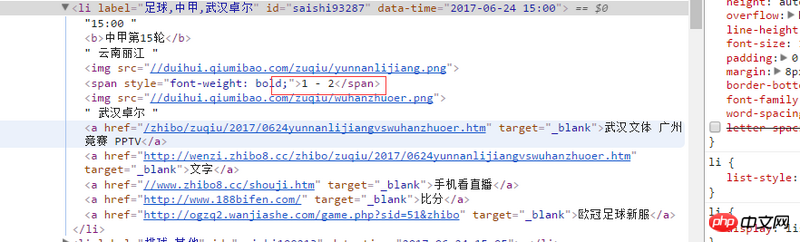




























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Then use Selenium to get it,
Link description