Use LFU algorithm to filter in all data| | | Talk about the LRU algorithm
is to filter data according to the least recently used principle. The least commonly used data will be filtered out, while the recently frequently used data will remain in the cache.
How exactly is it screened? LRU will organize all data into a linked list. The head and tail of the linked list represent the MRU end and the LRU end, respectively, representing the most recently used data and the most recently least commonly used data.
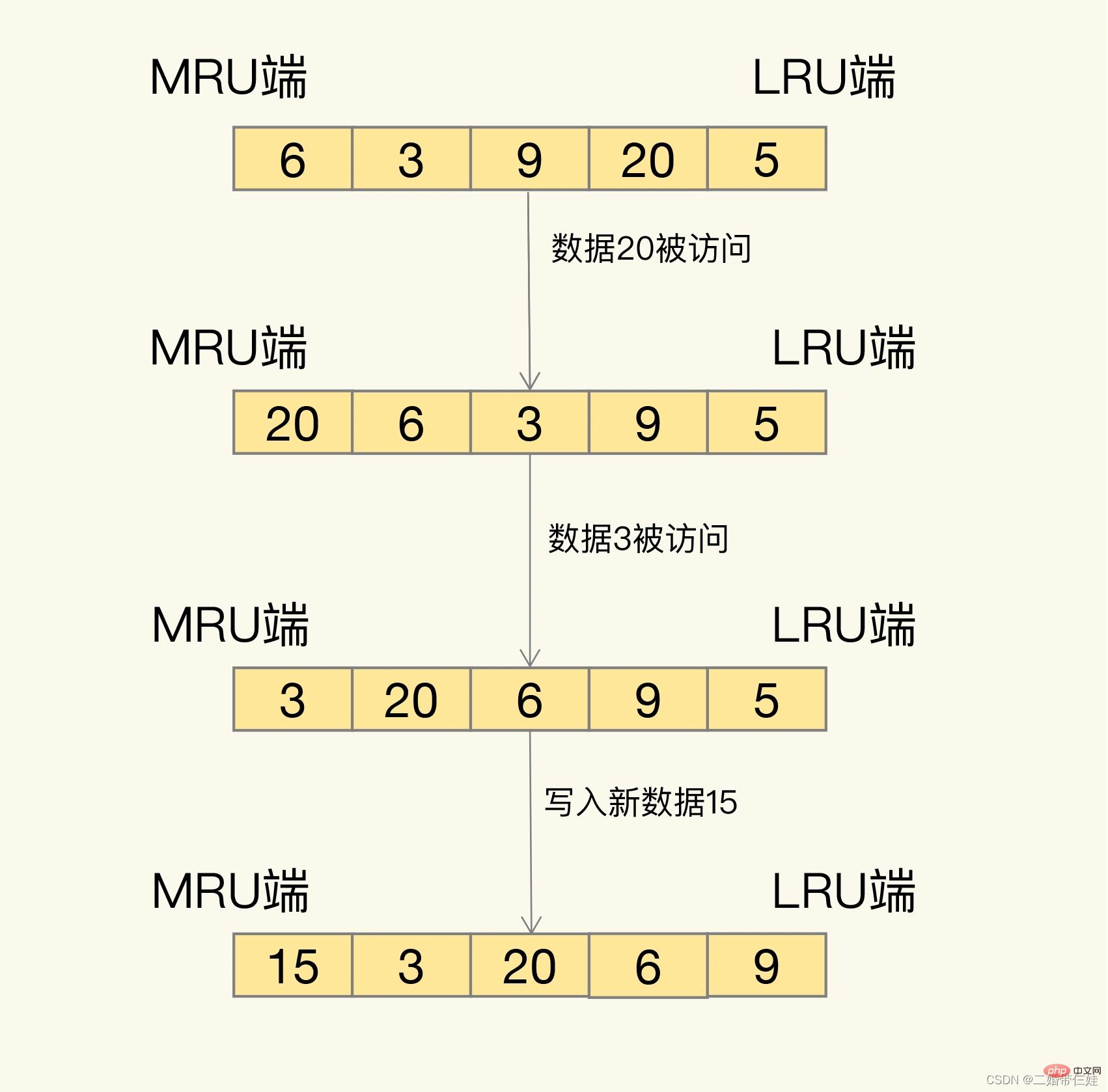
The idea behind the LRU algorithm is very simple: it believes that the data that has just been accessed will definitely be accessed again, so it is placed on the MRU side; data that has not been accessed for a long time will definitely not be accessed again. It will be accessed again, so let it gradually move back to the LRU side. When the cache is full, delete it first.
Problem: When the LRU algorithm is actually implemented, it is necessary to use a linked list to manage all cached data, which will bring additional space overhead. Moreover, when data is accessed, the data needs to be moved to the MRU on the linked list. If a large amount of data is accessed, many linked list movement operations will occur, which will be very time-consuming and reduce Redis cache performance.
Solution:
In Redis, the LRU algorithm has been simplified to reduce the impact of data eviction on cache performance. Specifically, Redis records the most recent access timestamp of each data by default (recorded by the lru field in the key-value pair data structure RedisObject). Then, when Redis determines the data to be eliminated, it will randomly select N pieces of data for the first time and use them as a candidate set. Next, Redis will compare the lru fields of these N data and eliminate the data with the smallest lru field value from the cache.
When data needs to be eliminated again, Redis needs to select the data into the candidate set created during the first elimination. The selection criterion here is: the lru field value of the data that can enter the candidate set must be less than the smallest lru value in the candidate set. When new data enters the candidate data set, if the number of data in the candidate data set reaches maxmemory-samples, Redis will eliminate the data with the smallest lru field value in the candidate data set.
Usage recommendations:
- Use allkeys-lru policy first. In this way, you can make full use of the advantages of LRU, a classic caching algorithm, to keep the most recently accessed data in the cache and improve application access performance. If there is an obvious distinction between hot and cold data in your business data, I recommend you use the allkeys-lru strategy.
- If the data access frequency in business applications is not much different, and there is no obvious distinction between hot and cold data, it is recommended to use the allkeys-random strategy and randomly select the eliminated data.
- If there is a need for pinned data in your business, such as pinned news and pinned videos, you can use the volatile-lru strategy and do not set an expiration time for these pinned data. In this way, the data that needs to be pinned will never be deleted, and other data will be filtered according to LRU rules when it expires.
How to deal with eliminated data?
Once the eliminated data is selected, if the data is clean data, then we will delete it directly; if the data is dirty data, we need to write it back to the database.
So how to judge whether a piece of data is clean or dirty?
- The difference between clean data and dirty data lies in whether it has been modified compared to the value originally read from the back-end database. Clean data has not been modified, so the data in the back-end database is also the latest value. When replacing, it can be deleted directly.
- Dirty data refers to data that has been modified and is no longer consistent with the data stored in the back-end database. At this time, if the dirty data is not written back to the database, the latest value of this data will be lost, which will affect the normal use of the application.
Even if the eliminated data is dirty data, Redis will not write them back to the database. Therefore, when we use Redis cache, if the data is modified, it needs to be written back to the database when the data is modified. Otherwise, when the dirty data is eliminated, it will be deleted by Redis, and there will be no latest data in the database.
How does Redis optimize memory?
1. Control the number of keys: When using Redis to store a large amount of data, there are usually a large number of keys, and too many keys will also consume a lot of memory. Redis is essentially a data structure server, which provides us with a variety of data structures, such as hash, list, set, zset and other structures. Don't get into a misunderstanding when using Redis, use APIs such as get/set extensively, and use Redis as Memcached. For storing the same data content, using the Redis data structure to reduce the number of outer keys can also save a lot of memory.
2. Reduce key-value objects. The most direct way to reduce Redis memory usage is to reduce the length of keys (keys) and values (values).
- Key length: When designing keys, when the business is fully described, the shorter the key value, the better.
- Value length: Value object reduction is more complicated. A common requirement is to serialize business objects into binary arrays and put them into Redis. First of all, business objects should be streamlined and unnecessary attributes should be removed to avoid storing invalid data. Secondly, in terms of serialization tool selection, a more efficient serialization tool should be selected to reduce the byte array size.
3. Coding optimization. Redis provides external types such as string, list, hash, set, zet, etc., but Redis internally has the concept of encoding for different types. The so-called encoding refers to the specific underlying data structure used to implement it. Different encodings will directly affect the memory usage and reading and writing efficiency of the data.
- 1. redisObject object
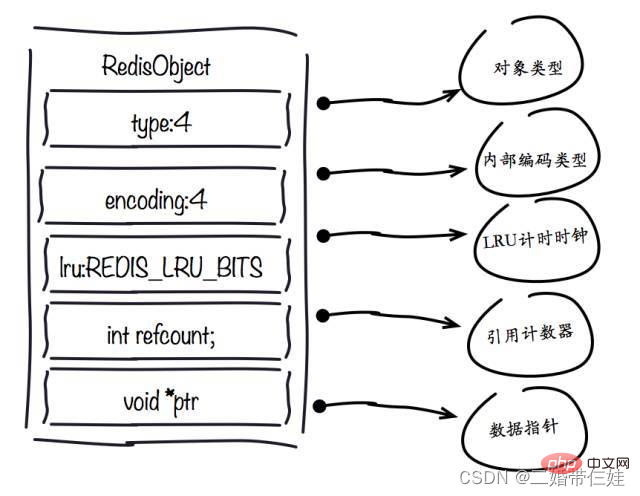
##type field:
Use collection type data , because usually many small Key-Values can be stored together in a more compact way. Use hashes as much as possible. Hash tables (meaning that the number stored in a hash table is small) use very small memory, so you should abstract your data model into a hash table as much as possible. For example, if there is a user object in your web system, do not set a separate key for the user's name, surname, email, and password. Instead, store all the user's information in a hash table.
encoding field:
There are obvious differences in memory usage using different encodings
lru field:
Development Tip: You can use the scan object idletime command to batch query which keys have not been accessed for a long time, find out the keys that have not been accessed for a long time, and clean them to reduce memory usage.
refcount field:
When the object is an integer and the range is [0-9999], Redis can use shared objects to save memory.
ptr field :
Development tip: In high concurrent writing scenarios, it is recommended that the string length be controlled within 39 bytes if conditions permit. , reduce the number of memory allocations to create redisObject and improve performance.
#2. Reduce key-value objects- The most direct way to reduce Redis memory usage is to reduce the length of keys and values.
You can use the general compression algorithm to compress json and xml before storing them in Redis, thereby reducing memory usage
##3. Shared object pool The object shared pool refers to the integer object pool [0-9999] maintained internally by Redis. There is memory overhead in creating a large number of integer type redisObjects. The internal structure of each redisObject occupies at least 16 bytes, which even exceeds the space consumption of the integer itself. Therefore, Redis memory maintains an integer object pool [0-9999] to save memory. In addition to integer value objects, other types such as list, hash, set, and zset internal elements can also use integer object pools. - Therefore, in development, on the premise of meeting the needs, try to use integer objects to save memory.
When maxmemory is set and LRU-related elimination strategies are enabled such as: volatile-lru, allkeys-lru, Redis prohibits the use of shared object pools.
Why is the object pool invalid after turning on maxmemory and LRU elimination strategy? The LRU algorithm needs to obtain the last access time of the object in order to eliminate the longest unaccessed data, each The last access time of the object is stored in the lru field of the redisObject object. Object sharing means that multiple references share the same redisObject. At this time, the lru field will also be shared, making it impossible to obtain the last access time of each object. If maxmemory is not set, Redis will not trigger memory recycling until the memory is exhausted, so the shared object pool can work normally. In summary, the shared object pool conflicts with the maxmemory LRU strategy, so you need to pay attention when using it.
Why is there only an integer object pool? First of all, the integer object pool has the highest probability of reuse. Secondly, a key operation of object sharing is to judge equality. The reason why Redis only has integer object pool is because the time complexity of the integer comparison algorithm is O(1). Only retain 10,000 integers to prevent object pool waste. If the equality of strings is judged, the time complexity becomes O(n), especially long strings consume more performance (floating point numbers are stored internally in Redis using strings). For more complex data structures such as hash, list, etc., equality judgment requires O(n2). For single-threaded Redis, such overhead is obviously unreasonable, so Redis only retains an integer shared object pool.
4. String optimization Redis does not use the string type of the native C language but implements its own string structure, internal simple dynamic string, referred to as SDS.
String structure:
Features: O(1) time complexity acquisition: string length, used length, Unused length. - Can be used to save byte arrays and supports secure binary data storage.
Internally implements a space pre-allocation mechanism to reduce the number of memory reallocations.
Lazy deletion mechanism, the space after string reduction is not released and is reserved as pre-allocated space.
Pre-allocation mechanism:- Development Tips: Try to reduce frequent string modification operations such as append and setrange, and instead directly use set to modify strings to reduce memory waste and memory fragmentation caused by pre-allocation.
String reconstruction: Secondary encoding method based on hash type.
- How to use secondary encoding?
The ID length used in the secondary encoding method is particular.
Involves a problem - when the underlying structure of the Hash type is less than the set value, a compressed list is used, and when it is greater than the set value, a hash table is used.
Once converted from a compressed list to a hash table, the Hash type will always be saved in the hash table and will not be converted back to the compressed list.
In terms of saving memory space, hash tables are not as efficient as compressed lists. In order to make full use of the compact memory layout of the compressed list, it is generally necessary to control the number of elements stored in the Hash.
- 5. Encoding optimization
The hash type encoded using the compressed list ziplist still saves a lot of memory than the set encoded using hashtable.
- #6. Control the number of keys
Development tip: After using ziplist hash to optimize keys, if you want to use the timeout deletion function, developers can Store the writing time of each object, and then use the hscan command to scan the data through a scheduled task to find the timed-out data items in the hash and delete them.
When Redis runs out of memory, the first thing to consider is not to add machines for horizontal expansion. You should try to optimize memory first. When you encounter a bottleneck, consider horizontal expansion. Even for clustering solutions, vertical level optimization is equally important to avoid unnecessary waste of resources and management costs after clustering.
Recommended learning: Redis tutorial




 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis















 0
0 1
1 374
374







![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)