


题主会计学二专毕业设计论文DDL在即,做的是分析食品企业会计信息与股价的实证课题,目前需要从新浪财经上收集100家食品企业近五年的财报,如果手动收集的话是根据证监会2014年4季度上市公司行业分类结果上的上市公司股票代码输到股票首页_新浪财经的搜索框,然后再从所选公司的网页(如康达尔(000048)股票股价,行情,新闻,财报数据)上点选“公司年报”,下载近五年的年报数据。
所选企业是2014年4季度上市公司行业分类结果上所有13、14、15大类,有100多家,全部手动收集的话工作量略大,想问下有没有办法用Python写一个脚本完成以上工作?(大学修过一门用python讲的计算思维,算是有一点点python基础吧)
感激不尽~
提问后一周已经搞定了,用了excel power query+yahoo finance api 等这周忙完毕业设计回来更新问题…还是非常感谢~!就当练手了~问题的解决办法有很多。利用现有的api挺方便。不过我还是按照题主原来的思路笨办法写写试试。
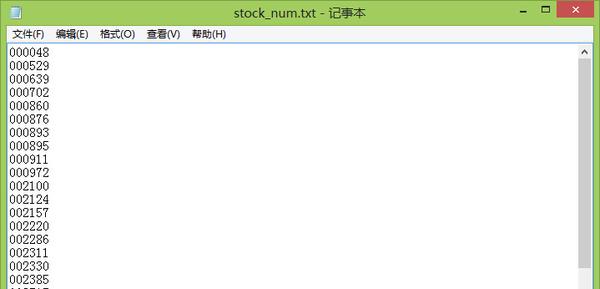
 然后我们需要让Python按行读入文本文档里的内容并存入一个列表。很简单。
然后我们需要让Python按行读入文本文档里的内容并存入一个列表。很简单。
f=open('stock_num.txt') stock = [] for line in f.readlines(): #print(line,end = '') line = line.replace('\n','') stock.append(line) f.close() print(stock) def xml_Error_C(filename): fp_xml=open(filename) fp_x=''#中文乱码改正 for i in range(os.path.getsize(filename)): i+=1 a=fp_xml.read(1) if a=='&': fp_xml.seek(-1,1) if fp_xml.read(6)==' ': i+=5 continue else: fp_xml.seek(-5,1) fp_x+=a fp_xml=open(filename,'w+') fp_xml.write(fp_x) fp_xml.flush() fp_xml.close() 




























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



