


Python method to parse and read the contents of PDF files

This article mainly introduces the method of Python parsing and reading the content of PDF files. It also describes the relevant operating techniques of Python2.7 in win32 and win64 environments to read PDF in the form of examples. Friends in need can refer to the following
The examples in this article describe how Python parses and reads the contents of PDF files. Share it with everyone for your reference, the details are as follows:
1. Problem description
Use python to read the PDF text content.
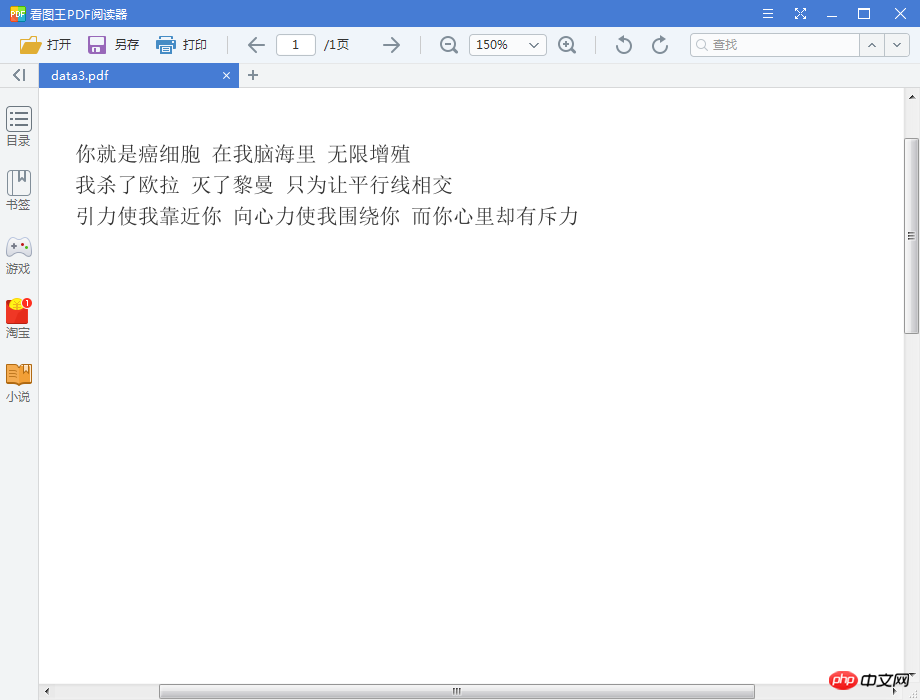
2. Effect
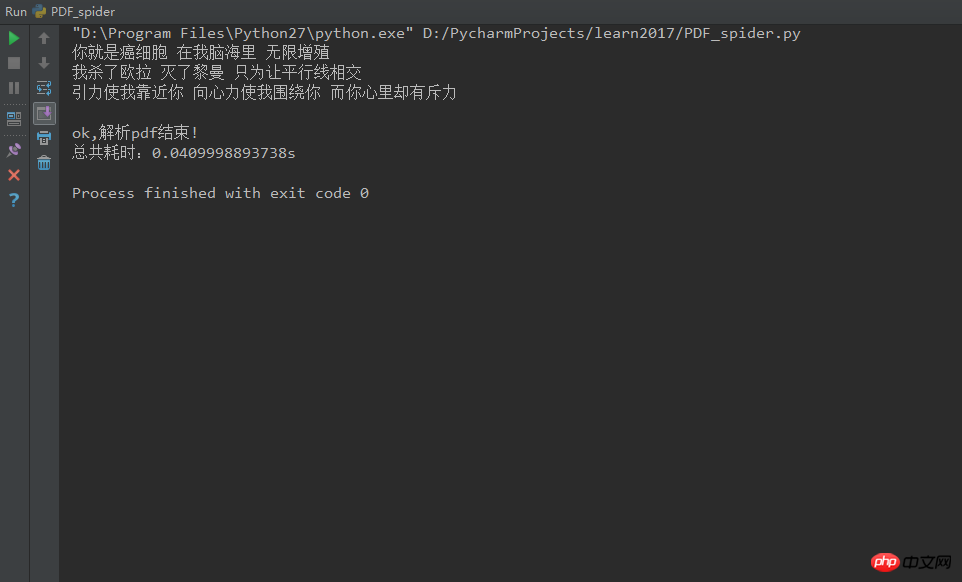
# #3. Running environment
python2.74. Libraries that need to be installed
pip install pdfminer
5. Implementation source code
Code 1 (win64)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/data3.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'Code 2 (win32)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument(praser)
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in PDFPage.create_pages(doc): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/36.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'Python implements the method of grabbing HTML web pages and saving them as PDF files
The above is the detailed content of Python method to parse and read the contents of PDF files. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MinIO Object Storage: High-performance deployment under CentOS system MinIO is a high-performance, distributed object storage system developed based on the Go language, compatible with AmazonS3. It supports a variety of client languages, including Java, Python, JavaScript, and Go. This article will briefly introduce the installation and compatibility of MinIO on CentOS systems. CentOS version compatibility MinIO has been verified on multiple CentOS versions, including but not limited to: CentOS7.9: Provides a complete installation guide covering cluster configuration, environment preparation, configuration file settings, disk partitioning, and MinI
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
When installing PyTorch on CentOS system, you need to carefully select the appropriate version and consider the following key factors: 1. System environment compatibility: Operating system: It is recommended to use CentOS7 or higher. CUDA and cuDNN:PyTorch version and CUDA version are closely related. For example, PyTorch1.9.0 requires CUDA11.1, while PyTorch2.0.1 requires CUDA11.3. The cuDNN version must also match the CUDA version. Before selecting the PyTorch version, be sure to confirm that compatible CUDA and cuDNN versions have been installed. Python version: PyTorch official branch
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
