


Introduce the scrapy crawler framework
Installation method pip install scrapy can be installed. I use the anaconda command to conda install scrapy.

1 Engine obtains the crawling request (Request) from Spider
2Engine will The crawling request is forwarded to Scheduler for scheduling
3 Engine obtains the next request to crawl from Scheduler
4 Engine sends the crawling request to Downloader through middleware
5 Crawl After the web page, the Downloader forms a response (Response) and sends it to the Engine through the middleware
6 The Engine sends the received response to the Spider through the middleware for processing. The Engine forwards the crawling request to the Scheduler for scheduling
7 After Spider processes the response, it generates scraped Item
and new crawling requests (Requests) to Engine
8 Engine sends the scraped item to Item Pipeline (framework exit)
9 Engine will The crawling request is sent to the Scheduler
Engine controls the data flow of each module and continuously obtains crawling requests from the Scheduler
until the request is empty
Frame entry: Spider's initial crawling request
Frame export: Item Pipeline
Engine Downloader
Download web pages according to requests
No user modification required
SchedulerScheduling and management of all crawling requests
No user modification required
Downloader MiddlewarePurpose: Implement user-configurable control between Engine, Scheduler and Downloader
Function: modify, discard, add request or response
Spider
(1) Parse the response returned by Downloader
(2) Generate scraped item
(3) Generate Additional crawling requests (Request)
Item Pipelines
(1) Process the crawled items generated by Spider in a pipeline manner
( 2) It consists of a set of operation sequences, similar to a pipeline. Each operation
is an Item Pipeline type
HTML data in the crawled items , Storing data into the databaseRequires users to write configuration code
After understanding the basic concepts, let’s start writing the first scrapy crawler.
First, create a new crawler project scrapy startproject xxx (project name)
This crawler will simply crawl the title and author of a novel website. .
We have created the reptile project book now to edit his configuration

This is the introduction of the configuration file. Before modifying these
修 We now create a start.py in the first -level Book directory to use it for the Scrapy reptile to run in the IDE
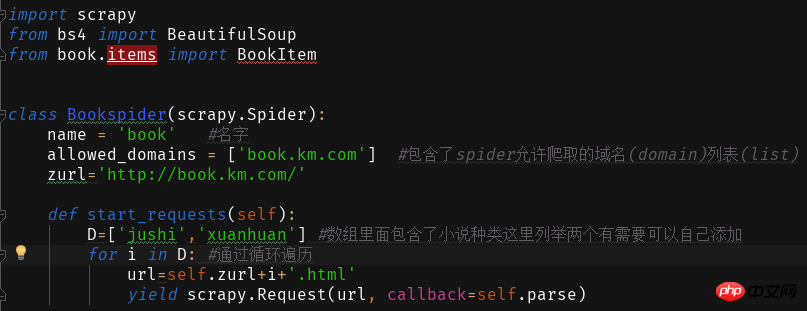
## noodles. Write the following code in the file. The first two parameters are fixed, and the third parameter is the name of your spider
The first two parameters are fixed, and the third parameter is the name of your spider
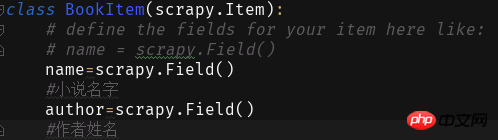
Next we fill in the fields in items:
By clicking on the different types of novels on the website, you will find that the website address is+Novel Type Pinyin.html
Through this we write and read the content of the web page
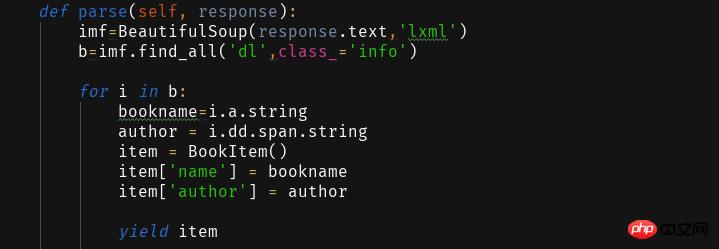
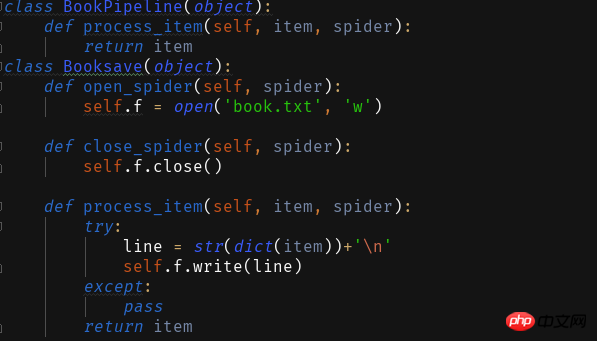
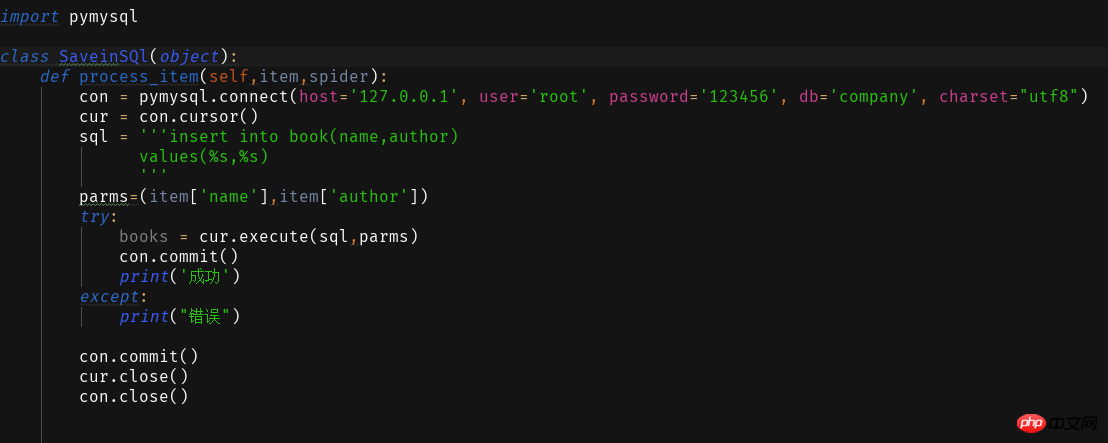
ITEM_PIPELINES = { 'book.pipelines.xxx': 300,}
xxx为存储方法的类名,想用什么方法存储就改成那个名字就好运行结果没什么看头就略了
第一个爬虫框架就这样啦期末忙没时间继续完善这个爬虫之后有时间将这个爬虫完善成把小说内容等一起爬下来的程序再来分享一波。
附一个book的完整代码:
import scrapyfrom bs4 import BeautifulSoupfrom book.items import BookItemclass Bookspider(scrapy.Spider): name = 'book' #名字 allowed_domains = ['book.km.com'] #包含了spider允许爬取的域名(domain)列表(list) zurl=''def start_requests(self): D=['jushi','xuanhuan'] #数组里面包含了小说种类这里列举两个有需要可以自己添加for i in D: #通过循环遍历 url=self.zurl+i+'.html'yield scrapy.Request(url, callback=self.parse) def parse(self, response): imf=BeautifulSoup(response.text,'lxml') b=imf.find_all('dl',class_='info')for i in b: bookname=i.a.stringauthor = i.dd.span.stringitem = BookItem() item['name'] = bookname item['author'] = authoryield item
The above is the detailed content of Introduction to scrapy crawler framework. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



