


This article mainly introduces the example code of PHP concurrent query of MySQL. The editor thinks it is quite good. Now I will share it with you and give it as a reference. Let’s follow the editor to take a look.
I have been studying PHP recently and I like it very much. I encountered the problem of concurrent query of MySQL in PHP. I studied it and left a note by the way:
Synchronization Query
This is our most common calling mode. The client calls Query[function], initiates a query command, waits for the result to be returned, reads the result; then sends the second query command, and waits for the result to be returned. , read the result. The total time taken will be the sum of the time of the two queries. Simplify the process, for example, as shown in the figure below:
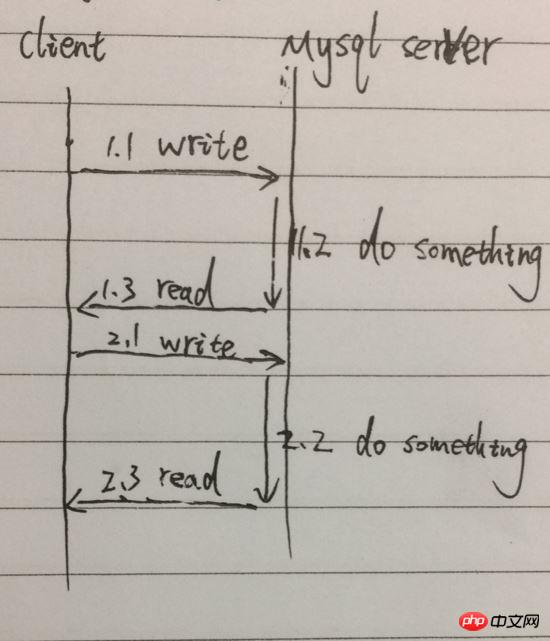
As shown in the figure, from 1.1 to 1.3 is the call of a Query [function]. Two queries require serialization of 1.1, 1.2, 1.3, 2.1, 2.2, 2.3, especially 1.2 and 2.2 will block waiting, and the process cannot do other things.
The advantage of synchronous calling is that it conforms to our intuitive thinking and is simple to call and process. The disadvantage is that the process is blocked waiting for the result to be returned, adding extra running time.
If there are multiple query requests, or the process has other things to deal with, then it is obviously possible to make reasonable use of the waiting time and improve the processing capacity of the process.
Split
Now, we break the Query[function] into pieces. The client returns immediately after 1.1. The client skips 1.2 and has data in 1.3. Read the data after reaching it. In this way, the process is freed from the original 1.2 stage and can do more things, such as...initiate another SQL query [2.1], have you seen the prototype of concurrent query?
Concurrent query
Compared to the synchronous query, the next query is initiated after the previous query is completed. Concurrent queries can be initiated immediately after the previous query request is initiated. Initiate the next query request. Simplify the process, as shown below:
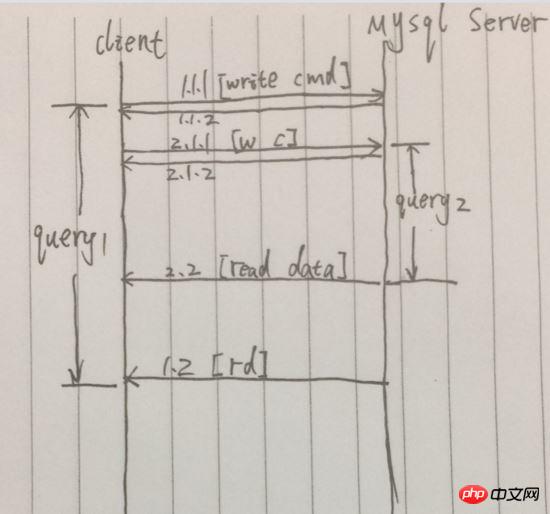
Example picture, after successfully sending the request in 1.1.1, [1.1.2] is returned immediately, and the final query result is returned in Distant 1.2. However, between 1.1.1 and 1.2, another query request was initiated. During this time period, two query requests were initiated at the same time. 2.2 arrived before 1.2, so the total time of the two queries was only equivalent to The time of the first query.
The advantage of concurrent query is that it can improve the utilization rate of the process, avoid blocking and waiting for the server to process the query, and shorten the time of multiple queries. But the disadvantages are also obvious. To initiate N concurrent queries, you need to establish N database links. For applications with database connection pools, this situation can be avoided.
Degeneration
Ideally, we want to concurrently run N queries, and the total time consumption is equal to the query with the longest query time. But it is also possible that concurrent queries will [degenerate] into [synchronous queries]. What? In the example diagram, if 1.2 is returned before 2.1.1, then the concurrent query will [degenerate] into [synchronous query], but the cost will be higher than that of synchronous query.
Multiplexing
Initiate query1
Initiate query2
Initiate query3
PHP implements concurrent query MySQL
PHP's mysqli (mysqlnd driver) provides multiplexed polling IO (mysqli_poll) and asynchronous query (MYSQLI_ASYNC, mysqli_reap_async_query), Use these two features to implement concurrent queries, sample code:query($sql, MYSQLI_ASYNC); // 发起异步查询,立即返回 $links[$link->thread_id] = $link; } $llen = count($links); $process = 0; do { $r_array = $e_array = $reject = $links; // 多路复用轮询IO if(!($ret = mysqli_poll($r_array, $e_array, $reject, 2))) { continue; } // 读取有结果返回的查询,处理结果 foreach ($r_array as $link) { if ($result = $link->reap_async_query()) { print_r($result->fetch_row()); if (is_object($result)) mysqli_free_result($result); } else { } // 操作完后,把当前数据链接从待轮询集合中删除 unset($links[$link->thread_id]); $link->close(); $process++; } foreach ($e_array as $link) { die; } foreach ($reject as $link) { die; } }while($process < $llen); $tvs = microtime(); $tv = explode(' ', $tvs); $end = $tv[1] * 1000 + (int)($tv[0] * 1000); echo $end - $start,PHP_EOL;
#ifndef PHP_WIN32 #define php_select(m, r, w, e, t) select(m, r, w, e, t) #else #include "win32/select.h" #endif /* {{{ mysqlnd_poll */ PHPAPI enum_func_status mysqlnd_poll(MYSQLND **r_array, MYSQLND **e_array, MYSQLND ***dont_poll, long sec, long usec, int * desc_num) { struct timeval tv; struct timeval *tv_p = NULL; fd_set rfds, wfds, efds; php_socket_t max_fd = 0; int retval, sets = 0; int set_count, max_set_count = 0; DBG_ENTER("_mysqlnd_poll"); if (sec < 0 || usec < 0) { php_error_docref(NULL, E_WARNING, "Negative values passed for sec and/or usec"); DBG_RETURN(FAIL); } FD_ZERO(&rfds); FD_ZERO(&wfds); FD_ZERO(&efds); // 从所有mysqli链接中获取socket链接描述符 if (r_array != NULL) { *dont_poll = mysqlnd_stream_array_check_for_readiness(r_array); set_count = mysqlnd_stream_array_to_fd_set(r_array, &rfds, &max_fd); if (set_count > max_set_count) { max_set_count = set_count; } sets += set_count; } // 从所有mysqli链接中获取socket链接描述符 if (e_array != NULL) { set_count = mysqlnd_stream_array_to_fd_set(e_array, &efds, &max_fd); if (set_count > max_set_count) { max_set_count = set_count; } sets += set_count; } if (!sets) { php_error_docref(NULL, E_WARNING, *dont_poll ? "All arrays passed are clear":"No stream arrays were passed"); DBG_ERR_FMT(*dont_poll ? "All arrays passed are clear":"No stream arrays were passed"); DBG_RETURN(FAIL); } PHP_SAFE_MAX_FD(max_fd, max_set_count); // select轮询阻塞时间 if (usec > 999999) { tv.tv_sec = sec + (usec / 1000000); tv.tv_usec = usec % 1000000; } else { tv.tv_sec = sec; tv.tv_usec = usec; } tv_p = &tv; // 轮询,等待多个IO可读,php_select是select的宏定义 retval = php_select(max_fd + 1, &rfds, &wfds, &efds, tv_p); if (retval == -1) { php_error_docref(NULL, E_WARNING, "unable to select [%d]: %s (max_fd=%d)", errno, strerror(errno), max_fd); DBG_RETURN(FAIL); } if (r_array != NULL) { mysqlnd_stream_array_from_fd_set(r_array, &rfds); } if (e_array != NULL) { mysqlnd_stream_array_from_fd_set(e_array, &efds); } // 返回可操作的IO数量 *desc_num = retval; DBG_RETURN(PASS); }
Concurrent query operation results
In order to see it more intuitively As a result, I found a table with 130 million data volumes and which has not been optimized for operation.

Comparison of multiple queries with shorter query times
Use multiple sql queries with shorter query times for comparison
Concurrent query test 1 Result (database link time is also counted):
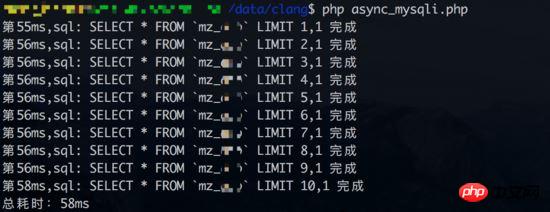
Result of synchronous query (database link time is also counted):

Test 2 results of concurrent query (database link time is not counted):

Judging from the results, concurrent query test 1 did not benefit. From the perspective of synchronous queries, each query takes about 3-4ms. But if the database connection time is not included in the statistics (synchronous query only has one database connection), the advantages of concurrent query can be reflected again.
Conclusion
Here we discussed the implementation of concurrent query MySQL in PHP, and intuitively understood the advantages and disadvantages of concurrent query from the experimental results. The time to establish a database connection still accounts for a large proportion of an optimized SQL query. #There is no connection pool, what is your use?
The above is the detailed content of PHP concurrency example about querying MySQL (picture). For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



