


This article mainly introduces methods to reducePHPRedismemory usage. Has very good reference value. Let’s take a look at it with the editor
1. Advantages of reducing redis memory usage
1. Helps reduce the time spent creating and loading snapshots
2. Improve the efficiency when loading AOF files and rewriting AOF files
3. Shorten the time required to synchronize from the server
4. No need to add additional hardware This allows redis to store more data
2. Short structure
Redis provides a set of configuration options for lists, sets, hashes, and ordered sets. , these options allow redis to store shorter structures in a more economical way.
2.1,ziplistCompressed list (list, hash, with sequel and)
Usually used storage method

When the length of the list, hash, or ordered set is short or the volume is small, redis will use a A compact storage method called ziplist is used to store these structures.
Ziplist is an unstructured representation of three different types of objects: list, hash, and ordered set. It stores data in a serialized manner. These serialized data are read every time. It needs to be decoded every time it is retrieved, and encoded every time it is written.
The difference between two-way lists and compressed lists:
In order to understand that compressed lists save more memory than other data structures, we take the list structure as an example Do in-depth research.
Typical two-way list
In a typical two-way list, each value will be represented by a node. Each node will have a pointer to the previous node and the next node in the linked list, as well as a pointer to thestringvalue contained in the node.
The string value contained in each node will be divided into three parts for storage. Includes the string length, the number of available bytes remaining in the string value, and the null-terminated string itself.
Example:
If a certain node stores the 'abc' string, it is conservatively estimated to require 21 bytes of additional overhead (three pointers + two int+null character is: 3*4+2*4+1=21)
It can be seen from the example that storing a 3-byte string requires at least 21 bytes of additional overhead.
ziplist
A ziplist is a sequence of nodes, each containing two lengths and a string. The first length records the length of the previous node (used for traversing the compressed list from back to front); the second length is the length of the current point in the record; the stored string.
Example:
To store the string 'abc', both lengths can be stored with 1 byte, so the additional overhead is 2 bytes (the two lengths are 1 +1=2)
Conclusion:
Compressed lists reduce additional overhead by avoiding storing additional pointers and metadata. .
Configuration:
#list list-max-ziplist-entries 512 #表示允许包含的最大元素数量 list-max-ziplist-value 64 #表示压缩节点允许存储的最大体积 #hash #当超过任一限制后,将不会使用ziplist方式进行存储 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 #zset zset-max-ziplist-entries 128 zset-max-ziplist-value 64
Test list:
1. Create the test.php file
#test.php connect('192.168.95.11','6379'); for ($i=0; $i<512 ; $i++) { $redis->lpush('test-list',$i.'-test-list'); #往test-list推入512条数据 } ?>

The test-list at this time contains 512 pieces of data, which does not exceed the limit in theconfig file
2. Push to the test-list again Enter a piece of data

At this time, the test-list contains 513 pieces of data, which is larger than the 512 pieces limited in the configuration file.Indexwill abandon the ziplist storage method. Adopt its original linkedlist storage method
Hashing is the same as ordered set.
2.2, intsetIntegerSet (set)
Prerequisite, all members included in the set can be Parses as a decimal integer.
Storing collections in orderedarrayscan not only reduce memory consumption, but also improve the execution speed of collection operations.
Configuration:
set-max-intset-entries 512 #Limit the number of members in the set. If it exceeds, intset will not be used. Storage
Test:
Create test.php file
#test.php connect('192.168.95.11','6379'); for ($i=0; $i<512 ; $i++) { $redis->sadd('test-set',$i); #给集合test-set插入512个member } ?>

2.3、性能问题
不管列表、散列、有序集合、集合,当超出限制的条件后,就会转换为更为典型的底层结构类型。因为随着紧凑结构的体积不断变大,操作这些结构的速度将会变得越来越慢。
测试:
#将采用list进行代表性测试
测试思路:
1、在默认配置下往test-list推入50000条数据,查看所需时间;接着在使用rpoplpush将test-list数据全部推入到新列表list-new中,查看所需时间
2、修改配置,list-max-ziplist-entries 100000,再执行上面的同样操作
3、对比时间,得出结论
默认配置下测试:
1、插入数据,查看时间
#test1.php connect('192.168.95.11','6379'); $start=time(); for ($i=0; $i<50000 ; $i++) { $redis->lpush('test-list',$i.'-aaaassssssddddddkkk'); } $end=time(); echo "插入耗时为:".($end-$start).'s'; ?>
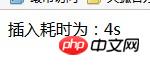

结果耗时4秒
2、执行相应命令,查看耗时
#test2.php connect('192.168.95.11','6379'); $start=time(); $num=0; while($redis->rpoplpush('test-list','test-new')) { $num+=1; } echo '执行次数为:'.$num."
"; $end=time(); echo "耗时为:".($end-$start).'s'; ?>

更改配置文件下测试
1、先修改配置文件
list-max-ziplist-entries 100000 #将这个值修改大一点,可以更好的凸显对性能的影响
list-max-ziplist-value 64 #此值可不做修改
2、插入数据
执行test1.php
结果为:耗时12s

3、执行相应命令,查看耗时
执行test2.php
结果为:执行次数:50000,耗时12s
结论:
在本机中执行测试50000条数据就相差8s,若在高并发下,长压缩列表和大整数集合将起不到任何的优化,反而使得性能降低。
3、片结构
分片的本质就是基于简单的规则将数据划分为更小的部分,然后根据数据所属的部分来决定将数据发送到哪个位置上。很多数据库使用这种技术来扩展存储空间,并提高自己所能处理的负载量。
结合前面讲到的,我们不难发现分片结构对于redis的重要意义。因此我们需要在配置文件中关于ziplist以及intset的相关配置做出适当的调整。
3.1、分片式散列
#ShardHash.class.php
redis=new Redis(); $this->redis->connect($host,$port); } /** * @desc 计算某key的分片ID * * @param $base string | 基础散列 * @param $key string | 要存储到分片散列里的键名 * @param $total int | 预计非数字分片总数 * * @return string | 返回分片键key */ public function shardKey ($base,$key,$total) { if(is_numeric($key)) { $shard_id=decbin(substr(bindec($key),0,5)); #取$key二进制高五位的十进制值 } else { $shard_id=crc32($key)%$shards; #求余取模 } return $base.'_'.$shard_id; } /** * @desc 分片式散列hset操作 * * @param $base string | 基础散列 * @param $key string | 要存储到分片散列里的键名 * @param $total int | 预计元素总数 * @param $value string/int | 值 * * @return bool | 是否hset成功 */ public function shardHset($base,$key,$total,$value) { $shardKey=$this->shardKey($base,$key,$total); return $this->redis->hset($shardKey,$key,$value); } /** * @desc 分片式散列hget操作 * * @param $base string | 基础散列 * @param $key string | 要存储到分片散列里的键名 * @param $total int | 预计元素总数 * * @return string/false | 成功返回value */ public function shardHget($base,$key,$total) { $shardKey=$this->shardKey($base,$key,$total); return $this->redis->hget($shardKey,$key); } } $obj=new ShardHash('192.168.95.11'); echo $obj->shardHget('hash-','key',500); ?>
散列分片主要是根据基础键以及散列包含的键计算出分片键ID,然后再与基础键拼接成一个完整的分片键。在执行hset与hget以及大部分hash命令时,都需要先将key(field)通过shardKey方法处理,得到分片键才能够进行下一步操作。
3.2、分片式集合
如何构造分片式集合才能够让它更节省内存,性能更加强大呢?主要的思路就是,将集合里面的存储的数据尽量在不改变其原有功能的情况下转换成可以被解析为十进制的数据。根据前面所讲到的,当集合中的所有成员都能够被解析为十进制数据时,将会采用intset存储方式,这不仅能够节省内存,而且还可以提高响应的性能。
例子:
假若要某个大型网站需要存储每一天的唯一用户访问量。那么就可以使用将用户的唯一标识符转化成十进制数字,再存入分片式set中。
#ShardSet.class.php
redis=new Redis(); $this->redis->connect($host,$port); } /** * @desc 根据基础键以及散列包含的键计算出分片键 * * @param $base string | 基础散列 * @param $key string | 要存储到分片散列里的键名 * @param $total int | 预计分片总数 * * @return string | 返回分片键key */ public function shardKey ($base,$member,$total=512) { $shard_id=crc32($member)%$shards; #求余取模 return $base.'_'.$shard_id; } /** * @desc 计算唯一用户日访问量 * * @param $member int | 用户唯一标识符 * * @return string | ok表示count加1 false表示用户今天已经访问过不加1 */ public function count($member) { $shardKey=$this->shardKey('count',$member,$total=10); #$totla调小一点用于测试 $exists=$this->redis->sismember($shardKey,$member); if(!$exists) #判断member今天是否访问过 { $this->redis->sadd($shardKey,$member); $this->redis->incr('count'); $ttl1=$this->redis->ttl('count'); if($ttl1===-1) $this->redis->expireat('count',strtotime(date('Y-m-d 23:59:59'))); #设置过期时间 $ttl2=$this->redis->ttl($shardKey); if($ttl2===-1) { $this->redis->expireat("$shardKey",strtotime(date('Y-m-d 23:59:59'))); #设置过期时间 #echo $shardKey; #测试使用 } #echo $shardKey; #测试使用 return 'ok'; } return 'false'; } } $str=substr(md5(uniqid()), 0, 8); #取出前八位 #将$str作为客户的唯一标识符 $str=hexdec($str); #将16进制转换为十进制 $obj=new ShardSet('192.168.95.11'); $obj->count($str); ?>
4、将信息打包转换成存储字节
结合前面所讲的分片技术,采用string分片结构为大量连续的ID用户存储信息。
使用定长字符串,为每一个ID分配n个字节进行存储相应的信息。
接下来我们将采用存储用户国家、省份的例子进行讲解:
假若某个用户需要存储中国、广东省这两个信息,采用utf8字符集,那么至少需要消耗5*3=15个字节。如果网站的用户量大的话,这样的做法将会占用很多资源。接下来我们采用的方法每个用户仅仅只需要占用两个字节就可以完成存储信息。
具体思路步骤:
1、首先我们为国家、以及各国家的省份信息建立相应的'信息表格'
2、将'信息表格'建好后,也意味着每个国家,省份都有相应的索引号
3、看到这里大家应该都想到了吧,对就是使用两个索引作为用户存储的信息,不过需要注意的是我们还需要对这两个索引进行相应的处理
4、将索引当做ASCII码,将其转换为对应ASCII(0~255)所指定的字符
5、使用前面所讲的分片技术,定长分片string结构,将用户的存储位置找出来(redis中一个string不能超过512M)
6、实现信息的写入以及取出(getrange、setrange)
实现代码:
#PackBytes.class.php
redis=new Redis(); $this->redis->connect($host,$port); } /** * @desc 处理并缓存国家省份数据 * @param $countries string | 第一类数据,国家字符串 * @param $provinces 二维array | 第二类数据,各国省份数组 * @param $cache 1/0 | 是否使用缓存,默认0不使用 * * @return array | 返回总数据 */ public function dealData($countries,$provinces,$cache=0) { if($cache) { $result=$this->redis->get('cache_data'); if($result) return unserialize($result); } $arr=explode(' ',$countries); $areaArr[]=$arr; $areaArr[]=$provinces; $cache_data=serialize($areaArr); $this->redis->set('cache_data',$cache_data); return $areaArr; } /** * @desc 将具体信息按表索引转换成编码信息 * * @param $countries,$provinces,$cache| 参考dealData方法 * @param $country string | 具体信息--国家 * @param $province string | 具体信息--省份 * * @return string | 返回转换的编码信息 */ public function getCode($countries,$provinces,$country,$province,$cache=0) { $dataArr=$this->dealData($countries,$provinces,$cache=0); $result=array_search($country, $dataArr[0]); #查找数组中是否含有data1 if($result===false) #判断是否存在 return chr(0).chr(0); #不存在则返回初始值 $code=chr($result); $result=array_search($province, $dataArr[1][$country]); #查找数组中是否含有data2 if($result===false) return $code.chr(0); return $code.chr($result); #返回对应ASCII(0~255)所指定的字符 } /** * @desc 计算用户存储编码数据的相关位置信息 * * @param $userID int | 用户的ID * * @return array | 返回一个数组 包含数据存储时的分片ID、以及属于用户的存储位置(偏移量) */ public function savePosition($userID) { $shardSize=pow(2, 3); #每个分片的大小 $position=$userID*2; #user的排位 $arr['shardID']=floor($position/$shardSize); #分片ID $arr['offset']=$position%$shardSize; #偏移量 return $arr; } /** * @desc | 整合方法,将编码信息存入redis中string相应的位置 * * @param $userID int | 用户ID * @param $countries string | 第一类数据,国家字符串 * @param $provinces 二维array | 第二类数据,各国省份数组 * @param $country string | 具体信息--国家 * @param $province string | 具体信息--省份 * @param $cache 1/0 | 是否使用缓存,默认0不使用 * * @return 成功返回写入位置/失败false */ public function saveCode($userID,$countries,$provinces,$country,$province,$cache=0) { $code=$this->getCode($countries,$provinces,$country,$province,$cache=0); $arr=$this->savePosition($userID); #存储相关位置信息 return $this->redis->setrange('save_code_'.$arr['shardID'],$arr['offset'],$code); } /** * @desc 获取用户的具体国家与省份信息 * * @param $userID int | 用户ID * * @return array | 返回包含国家和省份信息的数组 */ public function getMessage($userID) { $position=$this->savePosition($userID); $code=$this->redis->getrange('save_code_'.$position['shardID'],$position['offset'],$position['offset']+1); $arr=str_split($code); $areaArr=$this->dealData('', '',$cache=1); #使用缓存数据 $message['country']=$areaArr[0][ord($arr[0])]; $message['province']=$areaArr[1][$message['country']][ord($arr[1])]; return $message; } } header("content-type: text/html;charset=utf8;"); $countries="无 中国 日本 越南 朝鲜 俄罗斯 巴基斯坦 美国"; $provinces=array( '无'=>array('无'), '中国'=>array('无','广东','湖南','湖北','广西','云南','湖南','河北'), '日本'=>array('无','龟孙子区','王八区','倭国鬼区','鬼子区','萝卜头区'), ); $obj=new PackBytes('192.168.95.11'); /* #数据处理,并将其缓存到redis中 $b=$obj->dealData($countries,$provinces); echo ""; print_r($b); echo "
";die; */ /* #存储用户国家省份信息 $country='中国'; $province='广东'; $result=$obj->saveCode(0,$countries,$provinces,$country,$province); echo "
"; print_r($result); echo "
"; */ /* #取出用户国家省份信息 $a=$obj->getMessage(15); echo "
"; print_r($a); echo "
";die; */ ?>
Copy after login
测试:
1、dealData处理后的信息,即为'信息表表格'

2、saveCode()
| userID | 国家 | 省份 |
| 0 | 中国 | 广东 |
| 13 | 日本 | 龟孙子区 |
| 15 | 日本 | 王八区 |

3、getMessage()

The above is the detailed content of How to reduce the memory usage of PHP Redis (picture and text). For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



