This article brings you relevant knowledge about connection queries in MySQL, including issues related to inner joins, outer joins, multi-table joins and subqueries. I hope it will be helpful to everyone.

We have been using two tables student_info and student_score to store them separately In fact, it is not impossible to merge the students' basic information and students' performance information into one table. Assume that the name of the new table after merging the two tables is student_merge, then it should look like this:
student_merge table
| number | name | sex | id_number | department | major | enrollment_time | subject | score |
|---|---|---|---|---|---|---|---|---|
| 20180101 | Du Ziteng | Male | 158177199901044792 | School of Computer Science | Computer Science and Engineering | 2018-09- 01 | Postpartum care of sows | 78 |
| 20180101 | Du Ziteng | Male | 158177199901044792 | School of Computer Science | Computer Science and Engineering | 2018-09-01 | On Saddam’s War Preparations | 88 |
| Du Qiyan | 女 | 151008199801178529 | School of Computer Science | Computer Science and Engineering | 2018-09-01 | Postpartum care of sows | 100 | |
| DuQiyan | 女 | 151008199801178529 | School of Computer Science | Computer Science and Engineering | 2018-09-01 | On Saddam's War Preparations | 98 | |
| Fan Tong | male | 17156319980116959X | School of Computer Science | Software Engineering | 2018-09-01 | Postpartum care of sows | 59 | |
| Fan Tong | Male | 17156319980116959X | School of Computer Science | Software Engineering | 2018-09-01 | On Saddam’s War Preparations | 61 | ##20180104 |
| 女 | 141992199701078600 | School of Computer Science | Software Engineering | 2018-09-01 | Postpartum care of sows | 55 | 20180104 | |
| 女 | 141992199701078600 | Computer College | Software Engineering | 2018-09-01 | On Saddam’s War Preparations | 46 | 20180105 | |
| Male | ##181048200008156368 | Space Academy | Aircraft Design | 2018-09-01 | NULL | NULL | 20180106 | |
| Male | 197995199801078445 | Space Academy | Electronic Information | 2018-09-01 | NULL | NULL | With this merged table, we can query not only the basic information of the students, but also the student's performance information in one query statement, such as this query statement: SELECT number, name, major, subject, score FROM student_merge; Copy after login The query list
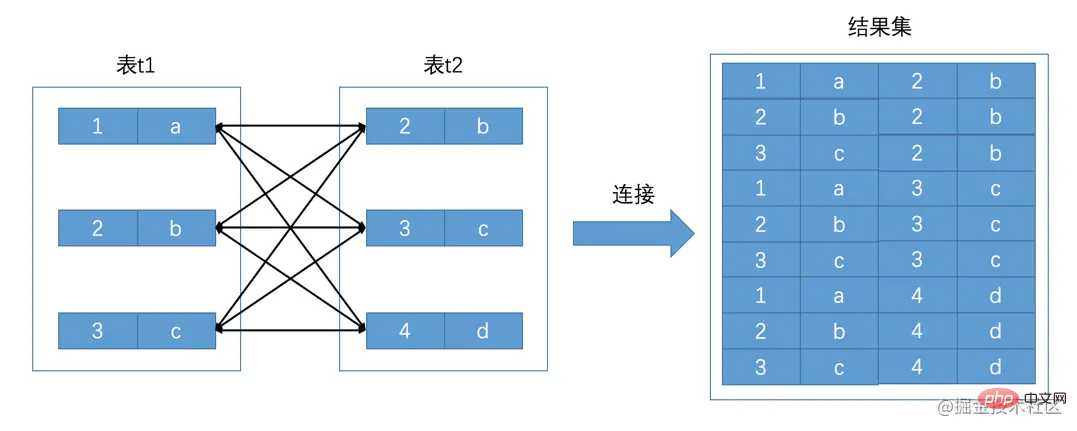
So in order to store as little redundant information as possible, we split the so-called number Tips: Although the subquery we introduced earlier can involve multiple tables in one query statement, the final result set generated by the entire query statement is still used to display the results of the outer query. , the results of the subquery are only used as intermediate results.The era is calling for a way to display information from multiple tables in one query statement result set. Connection Query mysql> CREATE TABLE t1 (m1 int, n1 char(1)); Query OK, 0 rows affected (0.02 sec) mysql> CREATE TABLE t2 (m2 int, n2 char(1)); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO t1 VALUES(1, 'a'), (2, 'b'), (3, 'c'); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> INSERT INTO t2 VALUES(2, 'b'), (3, 'c'), (4, 'd'); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> Copy after login t1 mysql> SELECT * FROM t1; +------+------+ | m1 | n1 | +------+------+ | 1 | a | | 2 | b | | 3 | c | +------+------+ 3 rows in set (0.00 sec) mysql> SELECT * FROM t2; +------+------+ | m2 | n2 | +------+------+ | 2 | b | | 3 | c | | 4 | d | +------+------+ 3 rows in set (0.00 sec) mysql> Copy after login The essence of connection
Cartesian product mysql> SELECT * FROM t1, t2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 1 | a | 2 | b | | 2 | b | 2 | b | | 3 | c | 2 | b | | 1 | a | 3 | c | | 2 | b | 3 | c | | 3 | c | 3 | c | | 1 | a | 4 | d | | 2 | b | 4 | d | | 3 | c | 4 | d | +------+------+------+------+ 9 rows in set (0.00 sec) Copy after login *
generated by joining these tables The Cartesian product
下边我们就要看一下携带过滤条件的连接查询的大致执行过程了,比方说下边这个查询语句: SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 Copy after login
那么这个连接查询的大致执行过程如下:
从上边两个步骤可以看出来,我们上边唠叨的这个两表连接查询共需要查询1次 内连接和外连接了解了连接查询的执行过程之后,视角再回到我们的 mysql> SELECT student_info.number, name, major, subject, score FROM student_info, student_score WHERE student_info.number = student_score.number; +----------+-----------+--------------------------+-----------------------------+-------+ | number | name | major | subject | score | +----------+-----------+--------------------------+-----------------------------+-------+ | 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 | | 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 | | 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 | | 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 | | 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 | | 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 | +----------+-----------+--------------------------+-----------------------------+-------+ 8 rows in set (0.00 sec) mysql> Copy after login
从上述查询结果中我们可以看到,各个同学对应的各科成绩就都被查出来了,可是有个问题,
可是这样仍然存在问题,即使对于外连接来说,有时候我们也并不想把驱动表的全部记录都加入到最后的结果集。这就犯难了,有时候匹配失败要加入结果集,有时候又不要加入结果集,这咋办,有点儿愁啊。。。噫,把过滤条件分为两种不就解决了这个问题了么,所以放在不同地方的过滤条件是有不同语义的:
一般情况下,我们都把只涉及单表的过滤条件放到
左(外)连接的语法 左(外)连接的语法还是挺简单的,比如我们要把 SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件]; Copy after login 其中中括号里的 mysql> SELECT student_info.number, name, major, subject, score FROM student_info LEFT JOIN student_score ON student_info.number = student_score.number; +----------+-----------+--------------------------+-----------------------------+-------+ | number | name | major | subject | score | +----------+-----------+--------------------------+-----------------------------+-------+ | 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 | | 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 | | 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 | | 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 | | 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 | | 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 | | 20180105 | 范剑 | 飞行器设计 | NULL | NULL | | 20180106 | 朱逸群 | 电子信息 | NULL | NULL | +----------+-----------+--------------------------+-----------------------------+-------+ 10 rows in set (0.00 sec) mysql> Copy after login 从结果集中可以看出来,虽然 右(外)连接的语法 右(外)连接和左(外)连接的原理是一样一样的,语法也只是把 SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件]; Copy after login 只不过驱动表是右边的表,被驱动表是左边的表,具体就不唠叨了。 内连接的语法 内连接和外连接的根本区别就是在驱动表中的记录不符合 SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件]; Copy after login 也就是说在
上边的这些写法和直接把需要连接的表名放到 SELECT * FROM t1, t2; Copy after login 现在我们虽然介绍了很多种内连接的书写方式,不过熟悉一种就好了,这里我们推荐INNER JOIN的形式书写内连接(因为INNER JOIN语义很明确嘛,可以和LEFT JOIN和RIGHT JOIN很轻松的区分开)。这里需要注意的是,由于在内连接中ON子句和WHERE子句是等价的,所以内连接中不要求强制写明ON子句。 我们前边说过,连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔积肯定是一样的。而对于内连接来说,由于凡是不符合ON子句或WHERE子句中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果。但是对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合ON子句连接条件的记录也会被加入结果集,所以此时驱动表和被驱动表的关系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。 小结 上边说了很多,给大家的感觉不是很直观,我们直接把表t1和t2的三种连接方式写在一起,这样大家理解起来就很easy了: mysql> SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 2 | b | 2 | b | | 3 | c | 3 | c | +------+------+------+------+ 2 rows in set (0.00 sec) mysql> SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 2 | b | 2 | b | | 3 | c | 3 | c | | 1 | a | NULL | NULL | +------+------+------+------+ 3 rows in set (0.00 sec) mysql> SELECT * FROM t1 RIGHT JOIN t2 ON t1.m1 = t2.m2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 2 | b | 2 | b | | 3 | c | 3 | c | | NULL | NULL | 4 | d | +------+------+------+------+ 3 rows in set (0.00 sec) Copy after login 连接查询产生的结果集就好像把散布到两个表中的信息被重新粘贴到了一个表,这个粘贴后的结果集可以方便我们分析数据,就不用老是两个表对照的看了。 多表连接上边说过,如果我们乐意的话可以连接任意数量的表,我们再来创建一个简单的 mysql> CREATE TABLE t3 (m3 int, n3 char(1)); ERROR 1050 (42S01): Table 't3' already exists mysql> INSERT INTO t3 VALUES(3, 'c'), (4, 'd'), (5, 'e'); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> Copy after login 与 mysql> SELECT * FROM t1 INNER JOIN t2 INNER JOIN t3 WHERE t1.m1 = t2.m2 AND t1.m1 = t3.m3; +------+------+------+------+------+------+ | m1 | n1 | m2 | n2 | m3 | n3 | +------+------+------+------+------+------+ | 3 | c | 3 | c | 3 | c | +------+------+------+------+------+------+ 1 row in set (0.00 sec) mysql> Copy after login 其实上边的查询语句也可以写成这样,用哪个取决于你的心情: SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2 INNER JOIN t3 ON t1.m1 = t3.m3; Copy after login 这个查询的执行过程用伪代码表示一下就是这样: for each row in t1 {
for each row in t2 which satisfies t1.m1 = t2.m2 {
for each row in t3 which satisfies t1.m1 = t3.m3 {
send to client;
}
}
}Copy after login 其实不管是多少个表的 表的别名我们前边曾经为列命名过别名,比如说这样: mysql> SELECT number AS xuehao FROM student_info; +----------+ | xuehao | +----------+ | 20180104 | | 20180102 | | 20180101 | | 20180103 | | 20180105 | | 20180106 | +----------+ 6 rows in set (0.00 sec) mysql> Copy after login 我们可以把列的别名用在 mysql> SELECT number AS xuehao FROM student_info ORDER BY xuehao DESC; +----------+ | xuehao | +----------+ | 20180106 | | 20180105 | | 20180104 | | 20180103 | | 20180102 | | 20180101 | +----------+ 6 rows in set (0.00 sec) mysql> Copy after login 与列的别名类似,我们也可以为表来定义别名,格式与定义列的别名一致,都是用空白字符或者 mysql> SELECT s1.number, s1.name, s1.major, s2.subject, s2.score FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number; +----------+-----------+--------------------------+-----------------------------+-------+ | number | name | major | subject | score | +----------+-----------+--------------------------+-----------------------------+-------+ | 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 | | 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 | | 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 | | 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 | | 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 | | 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 | +----------+-----------+--------------------------+-----------------------------+-------+ 8 rows in set (0.00 sec) mysql> Copy after login 这个例子中,我们在 自连接我们上边说的都是多个不同的表之间的连接,其实同一个表也可以进行连接。比方说我们可以对两个 mysql> SELECT * FROM t1, t1; ERROR 1066 (42000): Not unique table/alias: 't1' mysql> Copy after login 咦,报了个错,这是因为设计MySQL的大叔不允许 mysql> SELECT * FROM t1 AS table1, t1 AS table2; +------+------+------+------+ | m1 | n1 | m1 | n1 | +------+------+------+------+ | 1 | a | 1 | a | | 2 | b | 1 | a | | 3 | c | 1 | a | | 1 | a | 2 | b | | 2 | b | 2 | b | | 3 | c | 2 | b | | 1 | a | 3 | c | | 2 | b | 3 | c | | 3 | c | 3 | c | +------+------+------+------+ 9 rows in set (0.00 sec) mysql> Copy after login 这里相当于我们为 mysql> SELECT s2.number, s2.name, s2.major FROM student_info AS s1 INNER JOIN student_info AS s2 WHERE s1.major = s2.major AND s1.name = '史珍香' ; +----------+-----------+--------------+ | number | name | major | +----------+-----------+--------------+ | 20180103 | 范统 | 软件工程 | | 20180104 | 史珍香 | 软件工程 | +----------+-----------+--------------+ 2 rows in set (0.01 sec) mysql> Copy after login
连接查询与子查询的转换有的查询需求既可以使用连接查询解决,也可以使用子查询解决,比如 SELECT * FROM student_score WHERE number IN (SELECT number FROM student_info WHERE major = '计算机科学与工程'); Copy after login 这个子查询就可以被替换: SELECT s2.* FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number AND s1.major = '计算机科学与工程'; Copy after login 大家在实际使用时可以按照自己的习惯来书写查询语句。
推荐学习:mysql视频教程 |
The above is the detailed content of Let's talk about the basics of MySQL connection query. For more information, please follow other related articles on the PHP Chinese website!














 0
0 1
1 376
376
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)