Jumlah kandungan berkaitan 10000

Dengan menukar satu baris kod, latihan PyTorch adalah tiga kali lebih pantas 'teknologi lanjutan' ini adalah kuncinya
Pengenalan Artikel:Baru-baru ini, Sebastian Raschka, seorang penyelidik terkenal dalam bidang pembelajaran mendalam dan ketua pendidik kecerdasan buatan LightningAI, menyampaikan ucaptama "ScalingPyTorchModelTrainingWithMinimalCodeChanges" di CVPR2023. Untuk berkongsi hasil penyelidikan dengan lebih ramai orang, Sebastian Raschka menyusun ucapan itu ke dalam artikel. Artikel ini meneroka cara untuk menskalakan latihan model PyTorch dengan perubahan kod yang minimum dan menunjukkan bahawa tumpuan adalah pada memanfaatkan kaedah ketepatan campuran dan mod latihan berbilang GPU berbanding pengoptimuman mesin peringkat rendah. Pandangan penggunaan artikel
2023-08-14
komen 0
923

Penyelidikan tentang bias dan kaedah pembetulan diri model bahasa
Pengenalan Artikel:Kecondongan model bahasa ialah ia mungkin berat sebelah terhadap kumpulan orang, tema atau topik tertentu apabila menghasilkan teks, menyebabkan teks tidak berat sebelah, neutral atau diskriminasi. Bias ini mungkin timbul daripada faktor seperti pemilihan data latihan, reka bentuk algoritma latihan atau struktur model. Untuk menyelesaikan masalah ini, kita perlu memberi tumpuan kepada kepelbagaian data dan memastikan data latihan merangkumi pelbagai latar belakang dan perspektif. Selain itu, kita harus menyemak algoritma latihan dan struktur model untuk memastikan keadilan dan berkecualinya untuk meningkatkan kualiti dan keterangkuman teks yang dijana. Sebagai contoh, mungkin terdapat terlalu berat sebelah terhadap kategori tertentu dalam data latihan, menyebabkan model memihak kepada kategori tersebut apabila menjana teks. Kecondongan ini boleh menyebabkan model berprestasi buruk apabila berurusan dengan kategori lain, menjejaskan prestasi model. Di samping itu, mungkin terdapat beberapa percanggahan dalam reka bentuk model.
2024-01-22
komen 0
432

Python melaksanakan klasifikasi mesin vektor sokongan (SVM): penjelasan terperinci tentang prinsip algoritma
Pengenalan Artikel:Dalam pembelajaran mesin, mesin vektor sokongan (SVM) sering digunakan untuk klasifikasi data dan analisis regresi, dan merupakan model algoritma diskriminasi berdasarkan satah besar pemisahan. Dalam erti kata lain, memandangkan data latihan berlabel, algoritma mengeluarkan hyperplane optimum untuk mengklasifikasikan contoh baharu. Model algoritma mesin vektor sokongan (SVM) mewakili contoh sebagai titik dalam ruang Selepas pemetaan, contoh kategori berbeza dibahagikan sebanyak mungkin. Selain melaksanakan pengelasan linear, mesin vektor sokongan (SVM) boleh melaksanakan pengelasan tak linear dengan cekap, secara tersirat memetakan input mereka ke dalam ruang ciri berdimensi tinggi. Apakah yang dilakukan oleh mesin vektor sokongan? Memandangkan satu set contoh latihan, setiap contoh latihan ditandakan dengan kategori mengikut dua kategori, dan kemudian model dibina melalui algoritma latihan mesin vektor sokongan (SVM) untuk mengklasifikasikan contoh baharu ke dalam
2024-01-24
komen 0
1131

Menerobos dinding dimensi, X-Dreamer membawa teks berkualiti tinggi kepada penjanaan 3D, menyepadukan bidang penjanaan 2D dan 3D.
Pengenalan Artikel:Dalam tahun-tahun kebelakangan ini, kemajuan ketara telah dicapai dalam menukar teks secara automatik kepada kandungan 3D, didorong oleh pembangunan model resapan terlatih [1, 2, 3]. Antaranya, DreamFusion[4] memperkenalkan kaedah cekap yang memanfaatkan model resapan 2D terlatih[5] untuk menjana aset 3D secara automatik daripada teks tanpa memerlukan set data aset 3D khusus Inovasi utama yang diperkenalkan oleh DreamFusion ialah Pensampelan penyulingan pecahan (SDS) algoritma. Algoritma ini menggunakan model resapan 2D yang telah dilatih untuk menilai perwakilan 3D tunggal, seperti NeRF [6], dengan itu mengoptimumkannya untuk memastikan imej yang diberikan daripada mana-mana perspektif kamera mengekalkan konsistensi yang tinggi dengan teks yang diberikan. Diilhamkan oleh algoritma SDS mani, beberapa
2023-12-15
komen 0
559

ConvNeXt V2 ada di sini, hanya menggunakan seni bina lilitan yang paling mudah, prestasinya tidak kalah dengan Transformer
Pengenalan Artikel:Selepas beberapa dekad penyelidikan asas, bidang pengecaman visual telah membawa kepada era baharu pembelajaran perwakilan visual berskala besar. Model penglihatan berskala besar yang telah dilatih telah menjadi alat penting untuk pembelajaran ciri dan aplikasi penglihatan. Prestasi sistem pembelajaran perwakilan visual sangat dipengaruhi oleh tiga faktor utama: seni bina rangkaian neural model, kaedah yang digunakan untuk melatih rangkaian dan data latihan. Penambahbaikan dalam setiap faktor menyumbang kepada peningkatan dalam prestasi model keseluruhan. Inovasi dalam reka bentuk seni bina rangkaian saraf sentiasa memainkan peranan penting dalam bidang pembelajaran perwakilan. Seni bina rangkaian neural convolutional (ConvNet) telah memberi kesan yang ketara ke atas penyelidikan penglihatan komputer, membolehkan penggunaan kaedah pembelajaran ciri universal dalam pelbagai tugas pengecaman visual tanpa bergantung pada kecerdasan buatan.
2023-04-11
komen 0
1416

Prinsip asas dan contoh klasifikasi algoritma KNN
Pengenalan Artikel:Algoritma KNN ialah algoritma pengelasan yang mudah dan mudah digunakan sesuai untuk set data berskala kecil dan ruang ciri berdimensi rendah. Ia berprestasi baik dalam bidang seperti klasifikasi imej dan klasifikasi teks, dan digemari kerana kesederhanaan pelaksanaan dan kemudahan pemahaman. Idea asas algoritma KNN adalah untuk mencari jiran K terdekat dengan membandingkan ciri-ciri sampel yang akan dikelaskan dengan ciri-ciri sampel latihan, dan menentukan kategori sampel yang akan dikelaskan berdasarkan kategori-kategori ini. K jiran. Algoritma KNN menggunakan set latihan dengan kategori berlabel dan set ujian untuk dikelaskan. Proses pengelasan algoritma KNN merangkumi langkah-langkah berikut: pertama, hitung jarak antara sampel yang akan dikelaskan dan semua sampel latihan kedua, pilih jiran terdekat K kemudian, undi mengikut kategori jiran K untuk mendapatkan; kategori sampel pengelasan;
2024-01-23
komen 0
745

Pengenalan permainan padang latihan bersama 'White Wattle Corridor'.
Pengenalan Artikel:Bagaimana untuk bermain di Padang Latihan Bersama Koridor Baijing? Padang Latihan Bersama ialah salah satu mod permainan Koridor Wattle Putih Ramai pemain tidak tahu cara memainkannya secara khusus Pemain boleh merujuk kepada kandungan artikel untuk mengetahui tentang permainan Padang Latihan Bersama Pengenalan permainan White Wattle Corridor Joint Training Ground Saya percaya Ia pasti akan membantu anda, mari lihat. Permainan Padang Latihan Bersama "Koridor Baijing" Pengenalan Permainan: 1. Pertama, pemain perlu menawan empat zon pertahanan A, B, C, dan D mengikut urutan masa A, B, C, dan D dibahagikan kepada tiga bahagian. 2. Pemain meletakkan watak masing-masing di sudut kem persegi dan profesion rombus untuk melawan dan akan ditempatkan di sini. 3. Akhir sekali, markah adalah berdasarkan keputusan pertempuran. Peraturan pemarkahan: 1. Setiap 1,000 markah meningkatkan bilangan kerusi potongan sebanyak 5%, dan kemajuan potongan menunjukkan maksimum
2024-01-12
komen 0
1191

Algoritma simbolik untuk kembali ke asal
Pengenalan Artikel:Algoritma regresi simbolik ialah algoritma pembelajaran mesin yang membina model matematik secara automatik. Matlamat utamanya adalah untuk meramalkan nilai pembolehubah keluaran dengan menganalisis hubungan fungsi antara pembolehubah dalam data input. Algoritma ini menggabungkan idea-idea algoritma genetik dan strategi evolusi untuk meningkatkan ketepatan model secara beransur-ansur dengan menjana dan menggabungkan ungkapan matematik secara rawak. Dengan terus mengoptimumkan model, algoritma regresi simbolik boleh membantu kami memahami dan meramalkan hubungan data yang kompleks dengan lebih baik. Proses algoritma regresi simbolik adalah seperti berikut: 1. Tentukan masalah: tentukan pembolehubah input dan pembolehubah output. 2. Memulakan populasi: Menjana satu set ungkapan matematik secara rawak sebagai populasi. Nilaikan kecergasan: Gunakan ungkapan matematik setiap individu untuk meramal data dalam set latihan dan mengira ralat antara nilai ramalan dan nilai sebenar sebagai penyesuaian
2024-01-23
komen 0
1406

Fungsi dan kaedah untuk mengoptimumkan hiperparameter
Pengenalan Artikel:Hiperparameter ialah parameter yang perlu ditetapkan sebelum melatih model Ia tidak boleh dipelajari daripada data latihan dan perlu dilaraskan secara manual atau ditentukan oleh carian automatik. Hiperparameter biasa termasuk kadar pembelajaran, pekali regularisasi, bilangan lelaran, saiz kelompok, dsb. Penalaan hiperparameter ialah proses mengoptimumkan prestasi algoritma dan sangat penting untuk meningkatkan ketepatan dan prestasi algoritma. Tujuan penalaan hiperparameter adalah untuk mencari gabungan hiperparameter terbaik untuk meningkatkan prestasi dan ketepatan algoritma. Jika penalaan tidak mencukupi, ia mungkin membawa kepada prestasi algoritma yang lemah dan masalah seperti pemasangan lampau atau kurang kemas. Penalaan boleh meningkatkan keupayaan generalisasi model dan menjadikannya lebih baik pada data baharu. Oleh itu, adalah penting untuk menala hiperparameter sepenuhnya. Terdapat banyak kaedah untuk penalaan hiperparameter Kaedah biasa termasuk carian grid, carian rawak dan pengoptimuman Bayesian.
2024-01-22
komen 0
764

Mesin pembelajaran automatik (AutoML)
Pengenalan Artikel:Pembelajaran Mesin Automatik (AutoML) ialah pengubah permainan dalam bidang pembelajaran mesin. Ia boleh memilih dan mengoptimumkan algoritma secara automatik, menjadikan proses latihan model pembelajaran mesin lebih mudah dan cekap. Walaupun anda tidak mempunyai pengalaman pembelajaran mesin, anda boleh melatih model dengan prestasi cemerlang dengan mudah dengan bantuan AutoML. AutoML menyediakan pendekatan AI yang boleh dijelaskan untuk meningkatkan kebolehtafsiran model. Dengan cara ini, saintis data boleh mendapatkan cerapan tentang proses ramalan model. Ini amat berguna dalam bidang penjagaan kesihatan, kewangan dan sistem autonomi. Ia boleh membantu mengenal pasti berat sebelah dalam data dan mencegah ramalan yang salah. AutoML memanfaatkan pembelajaran mesin untuk menyelesaikan masalah dunia nyata, termasuk tugas seperti pemilihan algoritma, pengoptimuman hiperparameter dan kejuruteraan ciri. Berikut adalah beberapa kaedah yang biasa digunakan: Tuhan
2024-01-22
komen 0
908

Deep Thinking |. Di manakah sempadan keupayaan model besar?
Pengenalan Artikel:Jika kita mempunyai sumber tak terhingga, seperti data tak terhingga, kuasa pengkomputeran tak terhingga, model tak terhingga, algoritma pengoptimuman sempurna dan prestasi generalisasi, bolehkah model pra-latihan yang terhasil digunakan untuk menyelesaikan semua masalah? Ini adalah soalan yang sangat dibimbangkan oleh semua orang, tetapi teori pembelajaran mesin yang sedia ada tidak dapat menjawabnya. Ia tidak ada kena mengena dengan teori kebolehan ekspresif, kerana model itu tidak terhingga dan kebolehan ekspresif secara semula jadi tidak terhingga. Ia juga tidak berkaitan dengan teori pengoptimuman dan generalisasi, kerana kami menganggap bahawa prestasi pengoptimuman dan generalisasi algoritma adalah sempurna. Dalam erti kata lain, masalah kajian teori terdahulu tidak lagi wujud di sini! Hari ini, saya ingin memperkenalkan kepada anda kertas kerja OnthePowerofFoundationModels yang saya terbitkan di ICML'2023 Dari perspektif teori kategori,
2023-09-08
komen 0
1267

Mampu menyelaraskan manusia tanpa RLHF, prestasi setanding dengan ChatGPT! Pasukan China mencadangkan model Wombat
Pengenalan Artikel:ChatGPT OpenAI dapat memahami pelbagai jenis arahan manusia dan berfungsi dengan baik dalam tugas bahasa yang berbeza. Ini boleh dilakukan berkat kaedah penalaan halus model bahasa berskala besar baru yang dipanggil RLHF (Maklum Balas Manusia Sejajar melalui Pembelajaran Pengukuhan). Kaedah RLHF membuka kunci keupayaan model bahasa untuk mengikut arahan manusia, menjadikan keupayaan model bahasa konsisten dengan keperluan dan nilai manusia. Pada masa ini, kerja penyelidikan RLHF menggunakan algoritma PPO untuk mengoptimumkan model bahasa. Walau bagaimanapun, algoritma PPO mengandungi banyak hiperparameter dan memerlukan berbilang model bebas untuk bekerjasama antara satu sama lain semasa proses lelaran algoritma, jadi butiran pelaksanaan yang salah boleh membawa kepada hasil latihan yang lemah. Pada masa yang sama, algoritma pembelajaran pengukuhan tidak diperlukan dari perspektif penjajaran manusia. Hujah
2023-05-03
komen 0
1323

Masalah overfitting dalam algoritma pembelajaran mesin
Pengenalan Artikel:Masalah pemasangan berlebihan dalam algoritma pembelajaran mesin memerlukan contoh kod khusus Dalam bidang pembelajaran mesin, masalah model terlalu sesuai adalah salah satu cabaran biasa. Apabila model mengatasi data latihan, ia menjadi terlalu sensitif kepada hingar dan outlier, menyebabkan model berprestasi buruk pada data baharu. Untuk menyelesaikan masalah over-fitting, kita perlu mengambil beberapa kaedah yang berkesan semasa proses latihan model. Pendekatan biasa ialah menggunakan teknik regularization seperti regularization L1 dan regularization L2. Teknik ini mengehadkan kerumitan model dengan menambahkan istilah penalti untuk mengelakkan model daripada melampaui batas
2023-10-09
komen 0
984

Bagaimanakah ciri mempengaruhi pilihan jenis model?
Pengenalan Artikel:Ciri memainkan peranan penting dalam pembelajaran mesin. Apabila membina model, kita perlu berhati-hati memilih ciri untuk latihan. Pemilihan ciri secara langsung akan mempengaruhi prestasi dan jenis model. Artikel ini meneroka cara ciri mempengaruhi jenis model. 1. Bilangan ciri Bilangan ciri adalah salah satu faktor penting yang mempengaruhi jenis model. Apabila bilangan ciri adalah kecil, algoritma pembelajaran mesin tradisional seperti regresi linear, pepohon keputusan, dsb. biasanya digunakan. Algoritma ini sesuai untuk memproses sebilangan kecil ciri dan kelajuan pengiraan agak pantas. Walau bagaimanapun, apabila bilangan ciri menjadi sangat besar, prestasi algoritma ini biasanya merosot kerana mereka menghadapi kesukaran memproses data berdimensi tinggi. Oleh itu, dalam kes ini, kita perlu menggunakan algoritma yang lebih maju seperti mesin vektor sokongan, rangkaian saraf, dll. Algoritma ini mampu mengendalikan dimensi tinggi
2024-01-24
komen 0
998
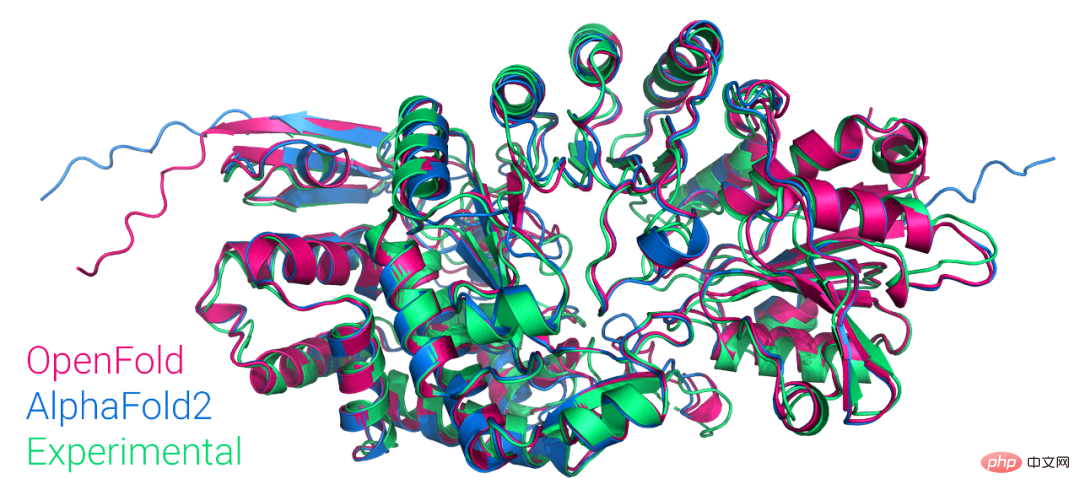
Versi PyTorch pertama AlphaFold2 yang tersedia untuk awam diterbitkan semula, sumber terbuka oleh Universiti Columbia, dan mempunyai lebih daripada 1,000 bintang
Pengenalan Artikel:Baru-baru ini, Mohammed AlQuraishi, penolong profesor biologi sistem di Columbia University, mengumumkan di Twitter bahawa mereka telah melatih model yang dipanggil OpenFold dari awal, yang merupakan kemunculan semula PyTorch AlphaFold2 yang boleh dilatih. Mohammed AlQuraishi juga berkata bahawa ini adalah pengeluaran semula pertama AlphaFold2 yang tersedia untuk orang ramai. AlphaFold2 secara berkala boleh meramalkan struktur protein dengan ketepatan atom, menggunakan teknologi yang direka untuk memanfaatkan penjajaran berbilang jujukan dan algoritma pembelajaran mendalam, digabungkan dengan pengetahuan fizikal dan biologi tentang struktur protein untuk meningkatkan ramalan. Ia mencapai keputusan cemerlang dalam meramalkan 2/3 struktur protein.
2023-04-13
komen 0
1206

Petua Penilaian Model Pembelajaran Mesin dalam Python
Pengenalan Artikel:Pembelajaran mesin ialah bidang kompleks yang merangkumi pelbagai teknik dan kaedah yang memerlukan ujian dan penilaian yang kerap terhadap prestasi model apabila menyelesaikan masalah dunia sebenar. Teknik penilaian model pembelajaran mesin merupakan kemahiran yang sangat penting dalam Python kerana ia membantu pembangun menentukan masa model boleh dipercayai dan cara ia berprestasi pada set data tertentu. Berikut ialah beberapa teknik penilaian model pembelajaran mesin biasa dalam Python: Pengesahan silang Pengesahan silang ialah teknik statistik yang biasa digunakan untuk menilai prestasi algoritma pembelajaran mesin. Set data dibahagikan kepada latihan
2023-06-10
komen 0
1670

LLM pertama yang menyokong pengkuantitian titik terapung 4-bit ada di sini, menyelesaikan masalah penggunaan LLaMA, BERT, dsb.
Pengenalan Artikel:Mampatan model bahasa besar (LLM) sentiasa menarik perhatian ramai, dan pengkuantitian selepas latihan (Post-training Quantization) adalah salah satu daripada algoritma yang biasa digunakan Walau bagaimanapun, kebanyakan kaedah PTQ yang sedia ada adalah kuantisasi integer, dan apabila bilangan bit adalah kurang daripada 8, selepas pengkuantitian Ketepatan model akan menurun dengan ketara. Berbanding dengan kuantifikasi Integer (INT), kuantifikasi FloatingPoint (FP) boleh mewakili pengedaran ekor panjang dengan lebih baik, jadi semakin banyak platform perkakasan mula menyokong kuantifikasi FP. Artikel ini memberikan penyelesaian kepada kuantifikasi FP model besar. Artikel itu diterbitkan di EMNLP2023. Alamat kertas: https://arxiv.org/abs/2310.16
2023-11-18
komen 0
1122

Prestasi penggambaran malam Redmi K70 Pro telah dipertingkatkan dengan baik, terima kasih kepada bantuan algoritma Xiaomi Night Owl
Pengenalan Artikel:Menurut berita pada 27 November, Redmi baru-baru ini mengeluarkan telefon bimbit terbarunya K70Pro. Telefon ini bukan sahaja dilengkapi dengan teknologi anti-goncang optik OIS, tetapi juga memperkenalkan algoritma Night Owl yang dibangunkan oleh Xiaomi buat kali pertama, memberikan pengguna pengalaman penggambaran malam yang tidak pernah berlaku sebelum ini Menurut pemahaman editor, algoritma Night Owl pada asalnya pada Xiaomi 11 Ultra Satu ciri penting. Algoritma ini menumpukan pada menyelesaikan masalah hingar biasa dalam fotografi malam Melalui sistem penentukuran hingar pemandangan malam yang dibangunkan secara bebas, ia menjalankan pemodelan matematik yang tepat bagi taburan dan bentuk hingar pemandangan malam. Untuk menambah baik kesan algoritma Night Owl, pasukan kejuruteraan Xiaomi mengguna pakai kaedah inovatif untuk meningkatkan kepelbagaian data hingar simulasi dengan menambahkan hingar pada simulasi, dengan itu memperkaya data latihan algoritma dan membuat proses denoising
2023-11-27
komen 0
1646

Fahami pembelajaran pengukuhan dan senario aplikasinya
Pengenalan Artikel:Cara terbaik untuk melatih anjing ialah menggunakan sistem ganjaran untuk memberi ganjaran kepadanya untuk tingkah laku yang baik dan menghukumnya untuk tingkah laku yang buruk. Strategi yang sama boleh digunakan untuk pembelajaran mesin, dipanggil pembelajaran pengukuhan. Pembelajaran pengukuhan ialah satu cabang pembelajaran mesin yang melatih model melalui pembuatan keputusan untuk mencari penyelesaian terbaik kepada masalah. Untuk meningkatkan ketepatan model, ganjaran positif boleh digunakan untuk menggalakkan algoritma mendekati jawapan yang betul, manakala ganjaran negatif boleh diberikan untuk menghukum penyelewengan daripada sasaran. Anda hanya perlu menjelaskan matlamat dan kemudian memodelkan data Model akan mula berinteraksi dengan data dan mencadangkan penyelesaian sendiri tanpa campur tangan manual. Contoh Pembelajaran Pengukuhan Mari kita ambil latihan anjing sebagai contoh Kami menyediakan ganjaran seperti biskut anjing untuk membuat anjing melakukan pelbagai tindakan. Anjing itu akan mengejar ganjaran mengikut strategi tertentu, jadi ia akan mematuhi arahan dan mempelajari tindakan baru, seperti mengemis.
2024-01-22
komen 0
1377

China Unicom mengeluarkan model AI imej dan teks besar yang boleh menjana imej dan klip video daripada teks
Pengenalan Artikel:Memandu China News pada 28 Jun 2023, hari ini semasa Kongres Dunia Mudah Alih di Shanghai, China Unicom mengeluarkan model grafik "Honghu Graphic Model 1.0". China Unicom berkata bahawa model grafik Honghu ialah model besar pertama untuk perkhidmatan tambah nilai pengendali. Wartawan China Business News mengetahui bahawa model grafik Honghu pada masa ini mempunyai dua versi 800 juta parameter latihan dan 2 bilion parameter latihan, yang boleh merealisasikan fungsi seperti gambar berasaskan teks, penyuntingan video dan gambar berasaskan gambar. Di samping itu, Pengerusi Unicom China Liu Liehong juga berkata dalam ucaptama hari ini bahawa AI generatif membawa ketunggalan pembangunan, dan 50% pekerjaan akan terjejas teruk oleh kecerdasan buatan dalam tempoh dua tahun akan datang.
2023-06-29
komen 0
1476

