


Sekelip mata, paradigma pembelajaran mesin akan berubah!
Hari ini, infrastruktur yang mendominasi bidang pembelajaran mendalam ialah multilayer perceptron (MLP) - yang meletakkan fungsi pengaktifan pada neuron.
Jadi, selain ini, adakah laluan baru yang boleh kita lalui?


Hanya hari ini, pasukan dari MIT, California Institute of Technology, Northeastern University dan institusi lain mengeluarkan struktur rangkaian neural baharu-Kolmogorov–Arnold Networks (KAN).

Para penyelidik membuat perubahan mudah kepada MLP, iaitu memindahkan fungsi pengaktifan yang boleh dipelajari daripada nod (neuron) ke tepi (berat)!

Alamat kertas: https://arxiv.org/pdf/2404.19756
Perubahan ini mungkin kelihatan tidak berasas pada mulanya, tetapi ia berkaitan dengan "teori perkiraan" dalam matematik yang mendalam
Ternyata perwakilan Kolmogorov-Arnold sepadan dengan rangkaian dua lapisan, dan terdapat fungsi pengaktifan yang boleh dipelajari di tepi, bukan pada nod.
Diilhamkan oleh teorem perwakilan, penyelidik menggunakan rangkaian saraf untuk secara eksplisit membuat parameter perwakilan Kolmogorov-Arnold.
Perlu disebut bahawa asal usul nama KAN adalah untuk memperingati dua ahli matematik mendiang Andrey Kolmogorov dan Vladimir Arnold.

Hasil eksperimen menunjukkan bahawa KAN mempunyai prestasi unggul berbanding MLP tradisional, meningkatkan ketepatan dan kebolehtafsiran rangkaian saraf.

Perkara yang paling tidak dijangka ialah visualisasi dan interaktiviti KAN memberikan potensi nilai aplikasi dalam penyelidikan saintifik dan boleh membantu saintis menemui undang-undang matematik dan fizikal baharu.
Dalam penyelidikan, penulis menggunakan KAN untuk menemui semula hukum matematik dalam teori simpulan!
Selain itu, KAN mereplikasi keputusan DeepMind pada 2021 dengan rangkaian dan automasi yang lebih kecil.

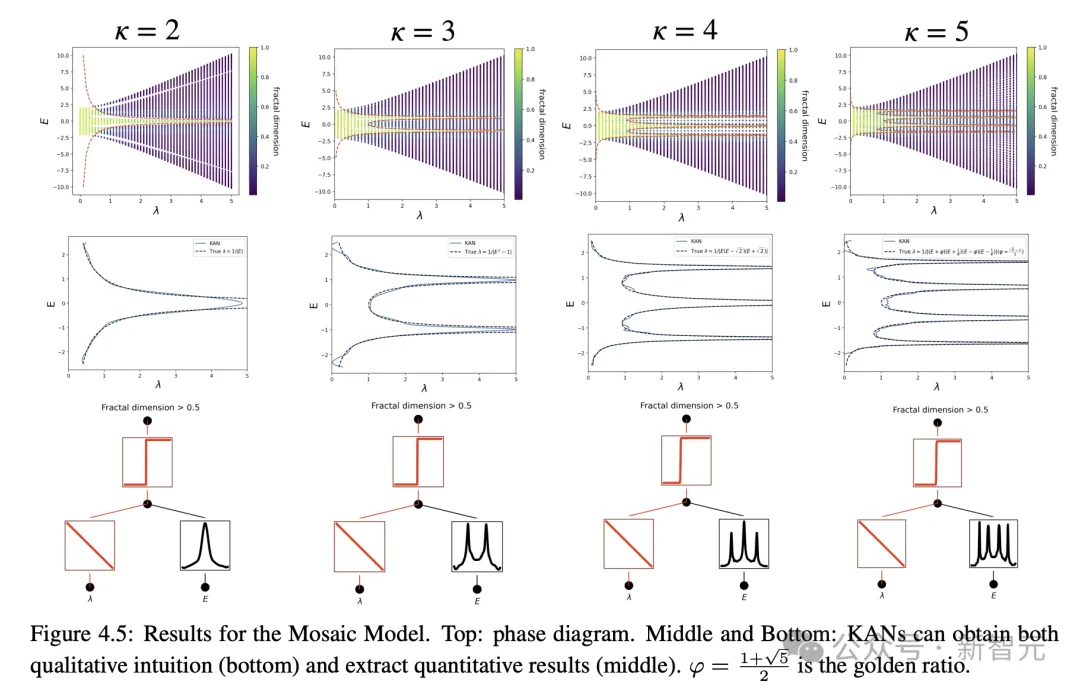
Dalam fizik, KAN boleh membantu ahli fizik mengkaji penyetempatan Anderson (iaitu peralihan fasa dalam fizik jirim pekat).
Sebenarnya, semua contoh KAN dalam kajian (kecuali pengimbasan parameter) boleh diterbitkan semula dalam masa kurang daripada 10 minit pada satu CPU.

Kemunculan KAN secara langsung mencabar seni bina MLP yang sentiasa mendominasi bidang pembelajaran mesin dan menimbulkan kekecohan di seluruh rangkaian.
Sesetengah orang mengatakan bahawa era baharu pembelajaran mesin telah bermula!

Saintis penyelidikan Google DeepMind berkata, "Kolmogorov-Arnold menyerang lagi! Fakta yang kurang diketahui: teorem ini muncul dalam kertas mani mengenai rangkaian neural invariant-invarian (set kedalaman), menunjukkan perwakilan ini Sambungan yang kompleks dengan cara ensembel/ Agregator GNN dibina (sebagai kes khas)".

Sebuah seni bina rangkaian neural yang serba baharu telah dilahirkan! KAN akan mengubah secara mendadak cara kecerdasan buatan dilatih dan diperhalusi.


Adakah AI telah memasuki era 2.0?

Sesetengah netizen menggunakan bahasa popular untuk membuat metafora jelas tentang perbezaan antara KAN dan MLP:
Kolmogorov-Arnold Network (KAN) adalah seperti rangkaian tiga dimensi. . Resipi kek lapis, manakala Multi-Layer Perceptron (MLP) ialah kek tersuai dengan bilangan lapisan yang berbeza-beza. MLP adalah lebih kompleks tetapi lebih umum, manakala KAN adalah statik tetapi lebih mudah dan lebih cepat untuk satu tugas.

Pengarang kertas kerja, profesor MIT Max Tegmark, berkata bahawa kertas terbaru menunjukkan bahawa seni bina yang sama sekali berbeza daripada rangkaian neural standard boleh mencapai hasil yang lebih baik dengan parameter yang lebih sedikit apabila menangani masalah fizikal dan matematik yang menarik. Ketepatan tinggi.

Seterusnya, mari kita lihat bagaimana KAN, yang mewakili masa depan pembelajaran mendalam, dilaksanakan?
Teorem perwakilan Kolmogorov–Arnold (teorem perwakilan Kolmogorov–Arnold) menyatakan bahawa jika f ialah suatu fungsi selanjar berbilang pembolehubah , maka fungsi itu boleh dinyatakan sebagai gabungan terhingga bagi pelbagai pembolehubah uni, fungsi berterusan aditif.

Untuk pembelajaran mesin, masalahnya boleh digambarkan sebagai: proses pembelajaran fungsi dimensi tinggi boleh dipermudahkan kepada mempelajari fungsi satu dimensi kuantiti polinomial.
Tetapi fungsi satu dimensi ini mungkin tidak licin, atau bahkan fraktal, dan mungkin tidak dipelajari dalam amalan Ia adalah tepat kerana "tingkah laku patologi" inilah teorem perwakilan Kolmogorov-Arnold Dalam bidang mesin. pembelajaran, ia pada asasnya dihukum "mati", iaitu, teori itu betul, tetapi ia tidak berguna dalam amalan.
Dalam artikel ini, penyelidik masih optimis tentang aplikasi teorem ini dalam bidang pembelajaran mesin, dan mencadangkan dua penambahbaikan:
1 Dalam persamaan asal, hanya terdapat dua lapisan ketaklinieran dan satu lapisan Tersembunyi (2n+1), yang boleh menyamaratakan rangkaian kepada lebar dan kedalaman sewenang-wenangnya
2 Kebanyakan fungsi dalam sains dan kehidupan seharian kebanyakannya licin dan mempunyai struktur gabungan yang jarang, yang boleh membantu Membentuk Kolmogorov- yang licin. Perwakilan Arnold. Sama seperti perbezaan antara ahli fizik dan ahli matematik, ahli fizik lebih mementingkan senario biasa, manakala ahli matematik lebih mementingkan senario terburuk.
Idea teras reka bentuk Kolmogorov-Arnold Network (KAN) adalah untuk mengubah masalah anggaran fungsi berbilang pembolehubah kepada masalah mempelajari set fungsi pembolehubah tunggal. Dalam rangka kerja ini, setiap fungsi univariat boleh diparameterkan dengan B-spline, lengkung polinomial setempat, sekeping yang pekalinya boleh dipelajari.

Untuk memanjangkan rangkaian dua lapisan dalam teorem asal dengan lebih mendalam dan luas, para penyelidik mencadangkan versi teorem yang lebih "umum" untuk menyokong reka bentuk KAN:
Dipengaruhi oleh struktur bertindan MLP Diilhamkan dengan menambah baik kedalaman rangkaian, artikel itu juga memperkenalkan konsep yang sama, lapisan KAN, yang terdiri daripada matriks fungsi satu dimensi, setiap fungsi mempunyai parameter yang boleh dilatih.

Mengikut teorem Kolmogorov-Arnold, lapisan KAN asal terdiri daripada fungsi dalaman dan fungsi luaran, masing-masing sepadan dengan dimensi input dan output yang berbeza Kaedah reka bentuk menyusun lapisan KAN ini bukan sahaja mengembang Ia meningkatkan kedalaman KAN dan mengekalkan kebolehtafsiran dan ekspresif rangkaian Setiap lapisan terdiri daripada fungsi pembolehubah tunggal, dan fungsi boleh dipelajari dan difahami secara bebas.
f dalam formula berikut adalah bersamaan dengan KAN

Walaupun konsep reka bentuk KAN nampak mudah dan bergantung semata-mata pada penyusunan I. mempelajari beberapa teknik semasa proses latihan.
1 Fungsi pengaktifan sisa: Dengan memperkenalkan gabungan fungsi asas b(x) dan fungsi spline, dan menggunakan konsep sambungan baki untuk membina fungsi pengaktifan ϕ(x), ia menyumbang kepada kestabilan latihan proses.

2. Skala permulaan (skala): Permulaan fungsi pengaktifan ditetapkan kepada fungsi spline hampir kepada sifar, dan berat w menggunakan kaedah permulaan Xavier, yang membantu mengekalkan kestabilan kecerunan pada peringkat awal latihan.
3 Kemas kini grid spline: Memandangkan fungsi spline ditakrifkan dalam selang terhad, dan nilai pengaktifan mungkin melebihi selang ini semasa proses latihan rangkaian saraf, mengemas kini grid spline secara dinamik boleh memastikan fungsi spline sentiasa Beroperasi. dalam julat yang sesuai.
1 Kedalaman rangkaian: L
2 Lebar setiap lapisan: N
3. k pesanan (biasanya k=3)
Jadi jumlah parameter KAN adalah kira-kira 
Sebagai perbandingan, jumlah parameter MLP ialah O(L*N^2), yang nampaknya lebih daripada KAN lebih cekap, tetapi KAN boleh menggunakan lebar lapisan (N) yang lebih kecil, yang bukan sahaja meningkatkan prestasi generalisasi tetapi juga meningkatkan kebolehtafsiran.
Bagaimana KAN lebih baik daripada MLP? Prestasi yang lebih kukuh , meliputi julat G sebagai {3,5,10,20,50,100,200,500,1000}
Seperti yang anda boleh lihat daripada keputusannya, keluk KAN lebih gelisah, boleh menumpu dengan cepat, dan mencapai keadaan yang stabil; dan ia lebih baik daripada keluk penskalaan MLP, terutamanya dalam situasi berdimensi tinggi.
Ia juga dapat dilihat bahawa prestasi KAN tiga lapisan jauh lebih kuat daripada dua lapisan, menunjukkan bahawa KAN yang lebih dalam mempunyai keupayaan ekspresif yang lebih kuat, selaras dengan jangkaan.
Para penyelidik mereka bentuk eksperimen regresi mudah untuk menunjukkan bahawa pengguna boleh memperoleh hasil yang paling boleh ditafsir semasa interaksi dengan KAN.

Andaikan pengguna berminat untuk mengetahui formula simbolik, sebanyak 5 langkah interaktif diperlukan.

Langkah 1: Latihan dengan sparsifikasi.
Bermula dari KAN yang bersambung sepenuhnya, latihan dengan regularization yang jarang boleh menjadikan rangkaian lebih jarang, sehingga dapati didapati bahawa 4 daripada 5 neuron dalam lapisan tersembunyi kelihatan tidak memberi kesan.
Langkah 2: Pemangkasan
Selepas pemangkasan automatik, buang semua neuron tersembunyi yang tidak berguna, tinggalkan hanya satu KAN, dan padankan fungsi pengaktifan dengan fungsi tanda yang diketahui. . atau tidak tahu ini Apakah fungsi simbolik fungsi pengaktifan mungkin, penyelidik menyediakan fungsi suggest_symbolic untuk mencadangkan calon simbolik.
Stept 4: Latihan selanjutnya selepas semua fungsi pengaktifan dalam rangkaian dilambangkan, satu -satunya parameter yang tinggal adalah parameter afin; ketepatan), anda menyedari bahawa model telah menemui ungkapan simbolik yang betul.
Langkah 5: Output formula simbolik
 Gunakan Sympy untuk mengira formula simbolik nod output dan sahkan jawapan yang betul.
Gunakan Sympy untuk mengira formula simbolik nod output dan sahkan jawapan yang betul.
Pengesahan Kebolehtafsiran
Para penyelidik mula-mula mereka bentuk enam sampel dalam set data mainan yang diselia untuk menunjukkan keupayaan struktur gabungan rangkaian KAN di bawah formula simbolik.
Dapat dilihat bahawa KAN telah berjaya mempelajari fungsi pembolehubah tunggal yang betul, dan melalui visualisasi, ia dapat menerangkan proses pemikiran KAN.
Dalam tetapan tanpa pengawasan, set data hanya mengandungi ciri input x Dengan mereka bentuk sambungan antara pembolehubah tertentu (x1, x2, x3), keupayaan model KAN untuk mencari kebergantungan antara pembolehubah boleh diuji.
Berdasarkan keputusan, model KAN berjaya menemui kebergantungan fungsi antara pembolehubah, tetapi penulis juga menegaskan bahawa eksperimen masih hanya dijalankan pada data sintetik, dan kaedah yang lebih sistematik dan terkawal diperlukan untuk menemui hubungan yang lengkap.

Pareto Optimal
Dengan memasangkan fungsi khas, pengarang menunjukkan Pareto Frontier KAN dan MLP dalam pesawat yang merangkumi bilangan parameter model dan kehilangan RMSE.
Di antara semua fungsi istimewa, KAN sentiasa mempunyai bahagian hadapan Pareto yang lebih baik daripada MLP. 

Dalam tugas menyelesaikan persamaan pembezaan separa, penyelidik memplot kerugian kuasa dua L2 dan H1 antara penyelesaian yang diramalkan dan benar.
Dalam rajah di bawah, dua yang pertama ialah dinamik latihan kehilangan, dan yang ketiga dan keempat ialah Undang-undang Sacling bagi bilangan fungsi kehilangan.
Seperti yang ditunjukkan dalam keputusan di bawah, KAN menumpu lebih cepat, mempunyai kerugian yang lebih rendah, dan mempunyai undang-undang pengembangan yang lebih curam berbanding dengan MLP.

Kita semua tahu bahawa pelupaan bencana adalah masalah serius dalam pembelajaran mesin.
Perbezaan antara rangkaian saraf tiruan dan otak ialah otak mempunyai modul berbeza yang berfungsi secara tempatan di angkasa. Apabila mempelajari tugas baharu, penyusunan semula struktur berlaku hanya di kawasan tempatan yang bertanggungjawab untuk kemahiran yang berkaitan, manakala kawasan lain kekal tidak berubah.
Walau bagaimanapun, kebanyakan rangkaian saraf tiruan, termasuk MLP, tidak mempunyai konsep lokaliti ini, yang mungkin menjadi sebab untuk melupakan bencana.
Penyelidikan telah membuktikan bahawa KAN mempunyai keplastikan tempatan dan boleh menggunakan lokaliti splines untuk mengelakkan pelupaan bencana.
Ideanya sangat mudah, memandangkan splin adalah setempat, sampel hanya akan mempengaruhi beberapa pekali splin berdekatan, manakala pekali jauh kekal tidak berubah.
Sebaliknya, memandangkan MLP biasanya menggunakan pengaktifan global (seperti ReLU/Tanh/SiLU), sebarang perubahan setempat mungkin merebak secara tidak terkawal ke kawasan yang jauh, memusnahkan maklumat yang disimpan di sana.
Para penyelidik menggunakan tugas regresi satu dimensi (terdiri daripada 5 puncak Gaussian). Data di sekeliling setiap puncak dibentangkan kepada KAN dan MLP secara berurutan (bukan sekali gus).
Hasilnya ditunjukkan dalam rajah di bawah KAN hanya membina semula kawasan di mana data wujud dalam peringkat semasa, meninggalkan kawasan sebelumnya tidak berubah.
Dan MLP akan membentuk semula keseluruhan kawasan selepas melihat sampel data baharu, yang membawa kepada pelupaan bencana.

Apakah makna kelahiran KAN untuk aplikasi pembelajaran mesin pada masa hadapan?
Teori simpulan ialah satu disiplin dalam topologi dimensi rendah Ia mendedahkan masalah topologi tiga-manifold dan empat-manifold, dan mempunyai aplikasi yang luas dalam bidang seperti biologi dan pengkomputeran kuantum topologi.

Pada tahun 2021, pasukan DeepMind menggunakan AI untuk membuktikan teori simpulan buat kali pertama dalam Alam Semula Jadi.

Alamat kertas: https://www.nature.com/articles/s41586-021-04086-x
Dalam kajian ini, melalui pembelajaran diselia dan pakar domain manusia, a invarian simpulan algebra dan geometri.
Iaitu, kecerunan kecerunan mengenal pasti invarian utama masalah penyeliaan, yang menyebabkan pakar domain mencadangkan satu tekaan yang kemudiannya diperhalusi dan terbukti.
Sehubungan itu, penulis mengkaji sama ada KAN boleh mencapai keputusan yang boleh ditafsirkan dengan baik pada masalah yang sama untuk meramalkan tandatangan simpulan.
Dalam eksperimen DeepMind, hasil utama kajian mereka terhadap dataset teori simpulan ialah:
1 Menggunakan kaedah atribusi rangkaian, didapati tandatangan 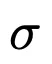 terutamanya bergantung pada jarak pertengahan
terutamanya bergantung pada jarak pertengahan  dan jarak membujur λ.
dan jarak membujur λ.
2 , menganggap tandatangan sebagai output.  Serupa dengan persediaan dalam DeepMind, tandatangan (nombor genap) dikodkan sebagai vektor satu panas, dan rangkaian dilatih dengan kehilangan entropi silang.
Serupa dengan persediaan dalam DeepMind, tandatangan (nombor genap) dikodkan sebagai vektor satu panas, dan rangkaian dilatih dengan kehilangan entropi silang.  Hasilnya mendapati bahawa KAN yang sangat kecil boleh mencapai ketepatan ujian sebanyak 81.6%, manakala DeepMind lebar 4 lapisan 300MLP hanya mencapai ketepatan ujian sebanyak 78%.
Hasilnya mendapati bahawa KAN yang sangat kecil boleh mencapai ketepatan ujian sebanyak 81.6%, manakala DeepMind lebar 4 lapisan 300MLP hanya mencapai ketepatan ujian sebanyak 78%. 
Seperti yang ditunjukkan dalam jadual di bawah, KAN (G = 3, k = 3) mempunyai kira-kira 200 parameter, manakala MLP mempunyai kira-kira 300,000 parameter.
Perlu diperhatikan bahawa KAN bukan sahaja lebih tepat; Pada masa yang sama, parameter adalah lebih cekap daripada MLP.
Dari segi kebolehtafsiran, para penyelidik menskalakan ketelusan setiap pengaktifan berdasarkan saiznya, jadi ia segera jelas, tanpa atribusi ciri, pembolehubah input mana yang penting.
Kemudian, KAN dilatih pada tiga pembolehubah penting dan memperoleh ketepatan ujian sebanyak 78.2%. 
Seperti berikut, melalui KAN, penulis menemui semula tiga hubungan matematik dalam set data knot.
Penyetempatan Anderson fizikal telah diselesaikan
 Dan dalam aplikasi fizik, KAN juga telah memainkan nilai yang besar.
Dan dalam aplikasi fizik, KAN juga telah memainkan nilai yang besar.
Anderson ialah fenomena asas di mana gangguan dalam sistem kuantum membawa kepada penyetempatan fungsi gelombang elektron, menyebabkan semua penghantaran terhenti.

Sebaliknya, dalam tiga dimensi, tenaga kritikal membentuk sempadan fasa yang memisahkan keadaan lanjutan daripada keadaan setempat, yang dipanggil kelebihan mobiliti.
Memahami tepi mobiliti ini adalah penting untuk menerangkan pelbagai fenomena asas seperti peralihan penebat logam dalam pepejal, dan kesan penyetempatan cahaya dalam peranti fotonik.
Penulis mendapati melalui penyelidikan bahawa KAN menjadikannya sangat mudah untuk mengekstrak tepi mobiliti, sama ada secara numerik atau simbolik.
Jelas sekali, KAN telah menjadi pembantu yang berkuasa dan kolaborator penting untuk saintis.
Secara keseluruhannya, KAN akan menjadi model/alat yang berguna untuk AI+Science berkat kelebihannya dalam ketepatan, kecekapan parameter dan kebolehtafsiran.
Pada masa hadapan, aplikasi lanjut KAN dalam bidang saintifik masih belum diterokai.

Atas ialah kandungan terperinci MLP dibunuh semalaman! MIT Caltech dan KAN revolusioner lain memecahkan rekod dan menemui teorem matematik yang menghancurkan DeepMind. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



