Di forum selari Kecerdasan BuatanForum Zhongguancun Umum yang diadakan pada 27 April, Sophon Engine, sebuah syarikat permulaan yang bergabung dengan Kongres Rakyat Kebangsaan, mengeluarkan model besar berbilang modal baharu Awaker 1.0, mengambil langkah penting ke arah AGI . Berbanding dengan model jujukan ChatImg generasi sebelumnya bagi Enjin Sophon, Awaker 1.0 menggunakan seni bina MOE baharu dan mempunyai keupayaan kemas kini bebas Ia merupakan model besar berbilang modal pertama dalam industri yang mencapai kemas kini bebas "sebenar". Dari segi penjanaan visual, Awaker 1.0 menggunakan asas penjanaan video yang dibangunkan sepenuhnya VDT, yang mencapai hasil yang lebih baik daripada Sora dalam penjanaan video foto, memecahkan kesukaran "last mile" untuk mendarat model besar. 
Awaker 1.0 ialah model besar berbilang modal yang sangat menyepadukan pemahaman visual dan penjanaan visual. Dari segi pemahaman, Awaker 1.0 berinteraksi dengan dunia digital dan dunia sebenar, dan menyalurkan kembali data gelagat adegan kepada model semasa pelaksanaan tugas untuk mencapai pengemaskinian dan latihan berterusan pada bahagian penjanaan, Awaker 1.0 boleh menjana berbilang berkualiti tinggi; kandungan modal, mensimulasikan dunia sebenar dan menyediakan lebih banyak data latihan untuk model sampingan pemahaman. Apa yang paling penting ialah kerana keupayaan kemas kini autonomi "sebenar", Awaker 1.0 sesuai untuk rangkaian senario industri yang lebih luas dan boleh menyelesaikan tugas praktikal yang lebih kompleks, seperti Ejen AI, kecerdasan yang terkandung, pengurusan komprehensif, dan Pemeriksaan keselamatan dsb. 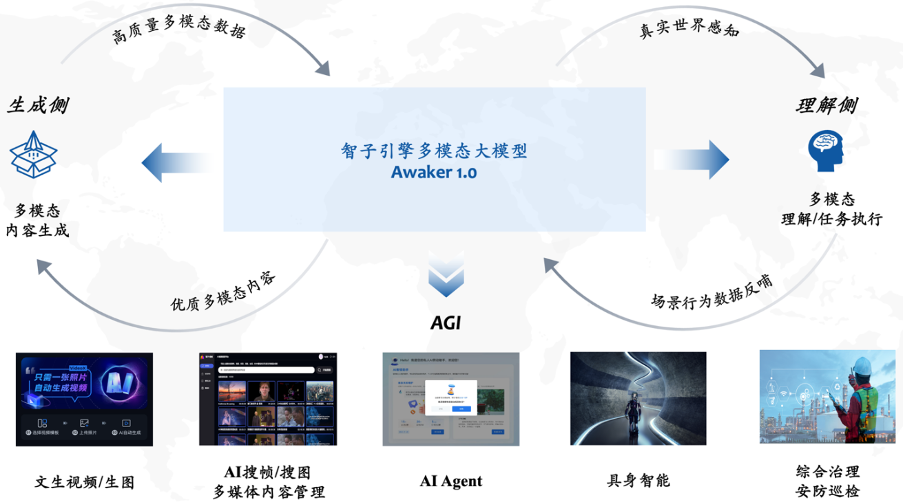
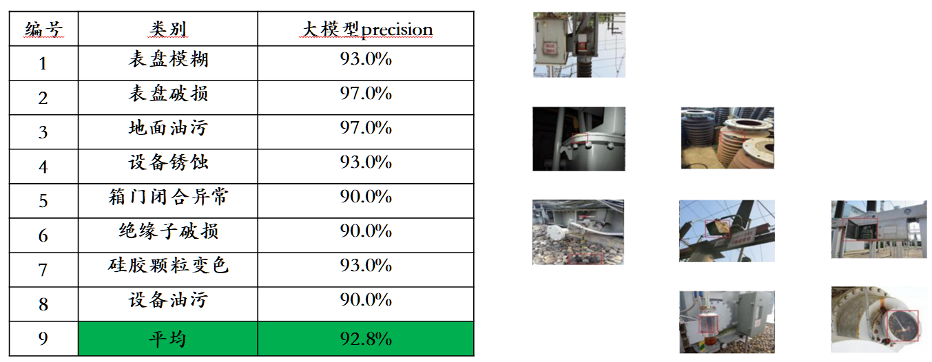
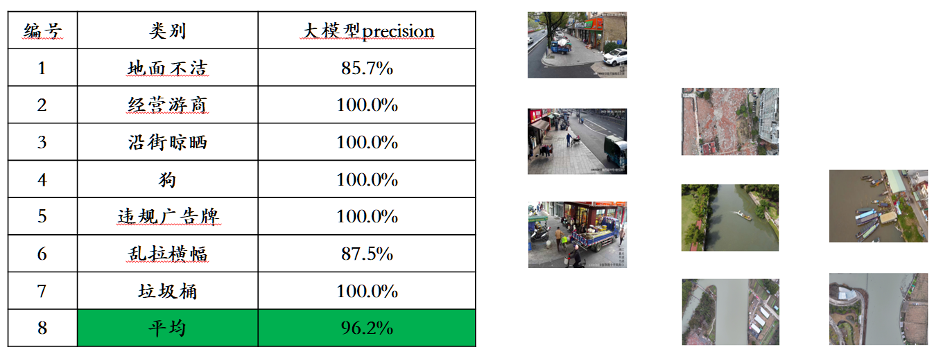
Dari segi pemahaman, model asas Awaker 1.0 terutamanya menyelesaikan masalah konflik serius dalam pelbagai modal pra-latihan. Mendapat manfaat daripada seni bina MOE berbilang tugas yang direka dengan teliti, model asas Awaker 1.0 bukan sahaja boleh mewarisi keupayaan asas model besar berbilang modal Enjin Sophon generasi sebelumnya ChatImg, tetapi juga mempelajari keupayaan unik yang diperlukan untuk setiap tugasan berbilang modal. . Berbanding dengan ChatImg model besar berbilang mod generasi sebelumnya, keupayaan model asas Awaker 1.0 telah dipertingkatkan dengan banyak dalam pelbagai tugas. Memandangkan masalah kebocoran data penilaian dalam senarai penilaian berbilang modal arus perdana, kami mengguna pakai piawaian yang ketat untuk membina set penilaian kami sendiri, di mana kebanyakan gambar ujian datang daripada album telefon mudah alih peribadi. Dalam set penilaian berbilang modal ini, kami menjalankan penilaian manual yang adil pada Awaker 1.0 dan tiga model besar berbilang modal yang paling maju di dalam dan luar negara Keputusan penilaian terperinci ditunjukkan dalam jadual di bawah. Ambil perhatian bahawa GPT-4V dan Intern-VL tidak menyokong tugas pengesanan secara langsung Hasil pengesanan mereka diperoleh dengan memerlukan model menggunakan bahasa untuk menerangkan orientasi objek. 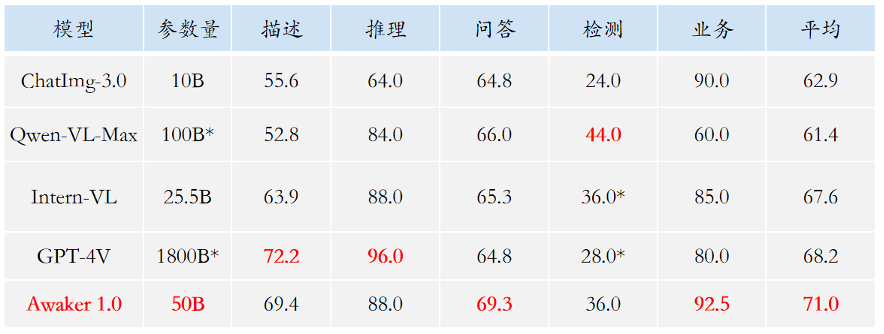
Kami mendapati bahawa model asas Awaker 1.0 mengatasi GPT-4V, Qwen-VL-Max dan Intern-VL dalam tugasan menjawab soalan visual dan aplikasi perniagaan, sementara ia juga mencapai Dapatkan hasil terbaik seterusnya. Secara keseluruhan, skor purata Awaker 1.0 melebihi tiga model paling maju di dalam dan luar negara, mengesahkan keberkesanan seni bina MOE berbilang tugas. Di bawah adalah beberapa contoh khusus analisis perbandingan. 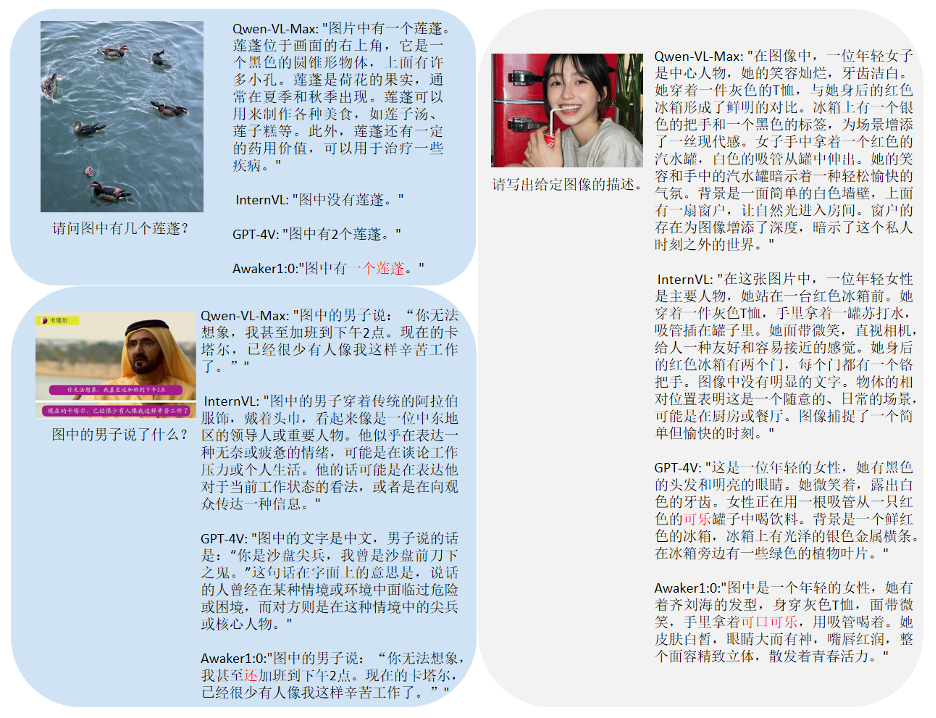
Seperti yang dapat dilihat daripada contoh perbandingan ini, Awaker 1.0 boleh memberikan jawapan yang betul kepada soalan pengiraan dan OCR, manakala tiga model lain semuanya menjawab dengan salah (atau sebahagiannya salah). Dalam tugas penerangan terperinci, Qwen-VL-Max lebih terdedah kepada halusinasi, dan Intern-VL boleh menerangkan dengan tepat kandungan gambar tetapi tidak tepat dan cukup spesifik dalam beberapa butiran. GPT-4V dan Awaker 1.0 bukan sahaja boleh menerangkan kandungan imej secara terperinci, tetapi juga mengenal pasti butiran dalam imej dengan tepat, seperti Coca-Cola yang ditunjukkan dalam gambar. Awaker + Embodied Intelligence: Ke Arah AGI
Gabungan model besar berbilang modal dan kecerdasan yang terkandung adalah sangat semula jadi kerana keupayaan pemahaman visual yang boleh digabungkan dengan model besar. kamera yang semula jadi dan diwujudkan kecerdasan. Dalam bidang kecerdasan buatan, "model besar berbilang mod + kecerdasan terkandung" malah dianggap sebagai jalan yang boleh dilaksanakan untuk mencapai kecerdasan buatan am (AGI).
Di satu pihak, orang menjangkakan kecerdasan yang terkandung dapat disesuaikan, iaitu, ejen boleh menyesuaikan diri dengan perubahan persekitaran aplikasi melalui pembelajaran berterusan Ia bukan sahaja boleh melakukan lebih baik pada tugas pelbagai modal yang diketahui, tetapi juga cepat menyesuaikan diri kepada tugas yang tidak diketahui.
Sebaliknya, orang ramai juga mengharapkan kecerdasan yang terkandung untuk menjadi benar-benar kreatif, berharap ia dapat menemui strategi dan penyelesaian baharu serta meneroka sempadan keupayaan kecerdasan buatan melalui penerokaan alam sekitar secara autonomi. Dengan menggunakan model besar multimodal sebagai "otak" kecerdasan yang terkandung, kami mempunyai potensi untuk meningkatkan kebolehsuaian dan kreativiti kecerdasan yang terkandung secara dramatik, akhirnya menghampiri ambang AGI (atau bahkan mencapai AGI).
Walau bagaimanapun, terdapat dua masalah yang jelas dengan model berbilang modal besar sedia ada: pertama, kitaran kemas kini berulang model adalah panjang, memerlukan banyak pelaburan manusia dan kewangan kedua, data latihan model datang daripada sedia ada Bagi sesetengah data, model tidak boleh terus memperoleh sejumlah besar pengetahuan baharu. Walaupun kemunculan pengetahuan baharu yang berterusan juga boleh disuntik melalui RAG dan konteks yang panjang, model besar berbilang modal itu sendiri tidak mempelajari pengetahuan baharu ini, dan kedua-dua kaedah pemulihan ini juga akan membawa masalah tambahan.
Pendek kata, model berbilang modal besar masa kini tidak begitu boleh disesuaikan dalam senario aplikasi sebenar, apatah lagi kreatif sehingga mengakibatkan pelbagai kesukaran apabila dilaksanakan dalam industri. 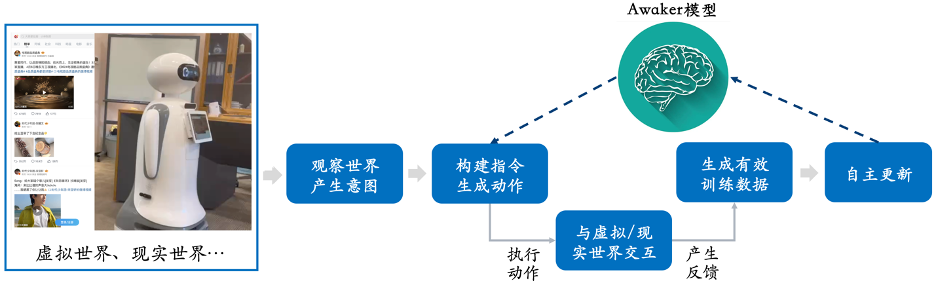 The Awaker 1.0 yang dikeluarkan oleh Sophon Engine kali ini ialah model besar berbilang modal pertama di dunia dengan mekanisme kemas kini autonomi, yang boleh digunakan sebagai "otak" kecerdasan yang terkandung. Mekanisme kemas kini autonomi Awaker 1.0 merangkumi tiga teknologi utama: penjanaan data aktif, refleksi dan penilaian model dan kemas kini model berterusan.
The Awaker 1.0 yang dikeluarkan oleh Sophon Engine kali ini ialah model besar berbilang modal pertama di dunia dengan mekanisme kemas kini autonomi, yang boleh digunakan sebagai "otak" kecerdasan yang terkandung. Mekanisme kemas kini autonomi Awaker 1.0 merangkumi tiga teknologi utama: penjanaan data aktif, refleksi dan penilaian model dan kemas kini model berterusan.
Berbeza daripada semua model berbilang modal besar yang lain, Awaker 1.0 adalah "hidup" dan parameternya boleh dikemas kini secara berterusan dalam masa nyata.
Seperti yang dapat dilihat daripada rajah bingkai di atas, Awaker 1.0 boleh digabungkan dengan pelbagai peranti pintar, memerhati dunia melalui peranti pintar, menjana niat tindakan, dan secara automatik membina arahan untuk mengawal peranti pintar untuk menyelesaikan pelbagai tindakan. Peranti pintar secara automatik akan menjana pelbagai maklum balas selepas menyelesaikan pelbagai tindakan Awaker 1.0 boleh mendapatkan data latihan yang berkesan daripada tindakan dan maklum balas ini untuk mengemas kini diri secara berterusan, dan terus mengukuhkan pelbagai keupayaan model.
Mengambil suntikan pengetahuan baharu sebagai contoh, Awaker 1.0 boleh terus mempelajari maklumat berita terkini di Internet dan menjawab pelbagai soalan rumit berdasarkan maklumat berita yang baru dipelajari. Berbeza daripada kaedah tradisional RAG dan konteks panjang, Awaker 1.0 benar-benar boleh mempelajari pengetahuan baharu dan "menghafal" parameter model. Seperti yang anda boleh lihat daripada contoh di atas, dalam tiga hari berturut-turut mengemas kini diri, Awaker 1.0 boleh mempelajari maklumat berita hari itu setiap hari dan menyebut maklumat yang sepadan dengan tepat semasa menjawab soalan. Pada masa yang sama, Awaker 1.0 tidak akan melupakan ilmu yang dipelajari semasa proses pembelajaran berterusan Contohnya, ilmu Hikmah S7 masih diingati atau difahami oleh Awaker 1.0 selepas 2 hari. Awaker 1.0 juga boleh digabungkan dengan pelbagai peranti pintar untuk mencapai kerjasama cloud-edge. Awaker 1.0 digunakan dalam awan sebagai "otak" untuk mengawal pelbagai peranti pintar tepi untuk melaksanakan pelbagai tugas. Maklum balas yang diperoleh apabila peranti pintar edge melakukan pelbagai tugas akan terus dihantar kembali ke Awaker 1.0, membolehkannya mendapatkan data latihan secara berterusan dan mengemas kini dirinya secara berterusan.  Laluan teknikal kolaborasi cloud-edge yang disebutkan di atas telah digunakan dalam senario aplikasi seperti pemeriksaan grid pintar dan bandar pintar Ia telah mencapai hasil pengiktirafan yang jauh lebih baik daripada model kecil tradisional dan telah diiktiraf tinggi oleh pelanggan industri.
Laluan teknikal kolaborasi cloud-edge yang disebutkan di atas telah digunakan dalam senario aplikasi seperti pemeriksaan grid pintar dan bandar pintar Ia telah mencapai hasil pengiktirafan yang jauh lebih baik daripada model kecil tradisional dan telah diiktiraf tinggi oleh pelanggan industri.
Simulator dunia sebenar: VDTSisi penjanaan Awaker 1.0 ialah asas penjanaan video seperti Sora VDT yang dibangunkan secara bebas oleh Sophon Engine. simulator dunia. Hasil penyelidikan VDT telah diterbitkan di laman web arXiv pada Mei 2023, 10 bulan sebelum OpenAI mengeluarkan Sora. Kertas akademik VDT telah diterima oleh ICLR 2024, persidangan kecerdasan buatan antarabangsa teratas. 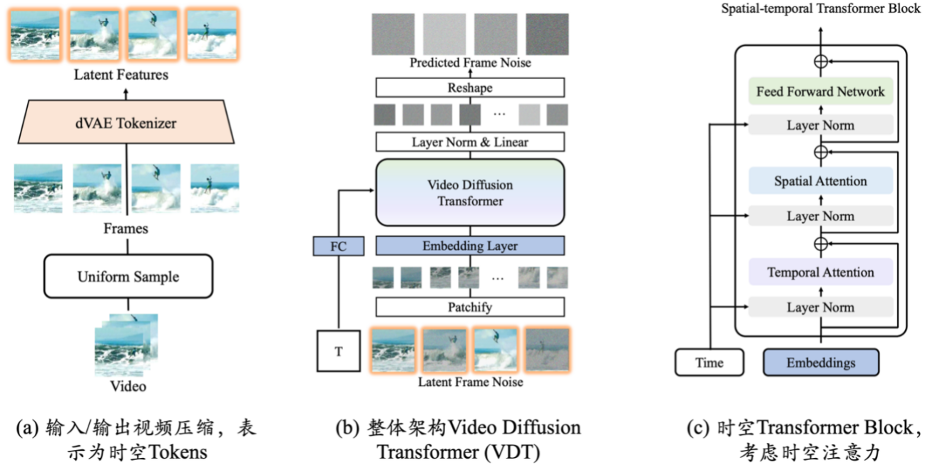
Inovasi asas penjanaan video VDT terutamanya merangkumi aspek berikut:
- Menggunakan teknologi Transformer untuk penjanaan video berasaskan penyebaran menunjukkan potensi besar Transformer dalam bidang penjanaan video Kelebihan VDT ialah keupayaan penangkapan bergantung masa yang sangat baik, membolehkan penjanaan bingkai video koheren sementara, termasuk mensimulasikan dinamik fizikal objek tiga dimensi dari semasa ke semasa.
- Cadangkan mekanisme pemodelan topeng spatio-temporal bersatu untuk membolehkan VDT mengendalikan pelbagai tugas penjanaan video, merealisasikan aplikasi luas teknologi ini. Kaedah pemprosesan maklumat bersyarat fleksibel VDT, seperti penyambungan ruang token yang mudah, menyatukan maklumat dengan panjang dan modaliti yang berbeza dengan berkesan. Pada masa yang sama, dengan menggabungkan dengan mekanisme pemodelan topeng spatiotemporal, VDT telah menjadi alat penyebaran video universal, yang boleh digunakan untuk penjanaan tanpa syarat, ramalan bingkai video berikutnya, interpolasi bingkai, video penjanaan gambar dan bingkai video tanpa mengubah suai struktur model. Penyiapan dan tugas penjanaan video lain.
Kami menumpukan pada penerokaan simulasi undang-undang fizikal mudah oleh VDT dan VDT terlatih pada set data Physion. Dalam contoh di bawah, kita dapati VDT berjaya mensimulasikan proses fizikal seperti bola bergerak sepanjang trajektori parabola dan bola bergolek di atas satah dan berlanggar dengan objek lain. Pada masa yang sama, ia juga dapat dilihat dari contoh kedua dalam baris 2 bahawa VDT menangkap kelajuan dan momentum bola, kerana bola akhirnya tidak menumbangkan tiang kerana daya hentaman yang tidak mencukupi. Ini membuktikan bahawa seni bina Transformer boleh mempelajari undang-undang fizikal tertentu. 
Kami juga menjalankan penerokaan mendalam mengenai tugas penjanaan video foto. Tugasan ini mempunyai keperluan yang sangat tinggi pada kualiti penjanaan video, kerana kami secara semula jadi lebih sensitif terhadap perubahan dinamik dalam wajah dan watak. Memandangkan kekhususan tugas ini, kita perlu menggabungkan VDT (atau Sora) dan penjanaan boleh dikawal untuk menangani cabaran penjanaan video foto. Pada masa ini, enjin Sophon telah menembusi kebanyakan teknologi utama penjanaan video foto dan mencapai kualiti penjanaan video foto yang lebih baik daripada Sora. Enjin Sophon akan terus mengoptimumkan algoritma penjanaan potret yang boleh dikawal, dan juga sedang meneroka pengkomersilan secara aktif. Pada masa ini, senario pendaratan komersial yang disahkan telah ditemui, dan ia dijangka dapat memecahkan kesukaran "perbatuan terakhir" untuk mendarat model besar dalam masa terdekat.  Pada masa hadapan, VDT yang lebih serba boleh akan menjadi alat yang berkuasa untuk menyelesaikan masalah sumber data model besar berbilang modal. Menggunakan penjanaan video, VDT akan dapat mensimulasikan dunia sebenar, meningkatkan lagi kecekapan pengeluaran data visual, dan memberikan bantuan untuk kemas kini bebas model besar berbilang mod Awaker. . Pasukan ini percaya bahawa keupayaan pembelajaran autonomi AI seperti penerokaan kendiri dan refleksi kendiri adalah kriteria penilaian penting untuk tahap kecerdasan dan sama pentingnya dengan peningkatan berterusan dalam saiz parameter (Undang-undang Penskalaan). Awaker 1.0 telah melaksanakan rangka kerja teknikal utama seperti "penjanaan data aktif, refleksi dan penilaian model, dan kemas kini model berterusan", mencapai kejayaan dalam kedua-dua bahagian pemahaman dan penjanaan Ia dijangka mempercepatkan pembangunan berbilang modal besar industri model dan akhirnya membolehkan manusia merealisasikan AGI .
Pada masa hadapan, VDT yang lebih serba boleh akan menjadi alat yang berkuasa untuk menyelesaikan masalah sumber data model besar berbilang modal. Menggunakan penjanaan video, VDT akan dapat mensimulasikan dunia sebenar, meningkatkan lagi kecekapan pengeluaran data visual, dan memberikan bantuan untuk kemas kini bebas model besar berbilang mod Awaker. . Pasukan ini percaya bahawa keupayaan pembelajaran autonomi AI seperti penerokaan kendiri dan refleksi kendiri adalah kriteria penilaian penting untuk tahap kecerdasan dan sama pentingnya dengan peningkatan berterusan dalam saiz parameter (Undang-undang Penskalaan). Awaker 1.0 telah melaksanakan rangka kerja teknikal utama seperti "penjanaan data aktif, refleksi dan penilaian model, dan kemas kini model berterusan", mencapai kejayaan dalam kedua-dua bahagian pemahaman dan penjanaan Ia dijangka mempercepatkan pembangunan berbilang modal besar industri model dan akhirnya membolehkan manusia merealisasikan AGI . Atas ialah kandungan terperinci Model multi-modal Kongres Rakyat Kebangsaan bergerak ke arah AGI: ia merealisasikan pengemaskinian bebas buat kali pertama, dan penjanaan video foto mengatasi Sora. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 nozoomer
nozoomer
 Bagaimana untuk membuka fail pdb
Bagaimana untuk membuka fail pdb
 Bagaimana untuk membaca data dalam fail excel dalam python
Bagaimana untuk membaca data dalam fail excel dalam python
 Perbezaan antara bahasa c dan python
Perbezaan antara bahasa c dan python
 Bagaimana untuk melihat prosedur tersimpan dalam MySQL
Bagaimana untuk melihat prosedur tersimpan dalam MySQL
 Cara menggunakan fungsi bulan
Cara menggunakan fungsi bulan
 Windows tidak dapat menyambung ke penyelesaian wifi
Windows tidak dapat menyambung ke penyelesaian wifi
 vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan
vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



