


Baru-baru ini, diketuai oleh Profesor Yan Shuicheng, Institut Penyelidikan Global Teknologi Kunlun 2050, Universiti Nasional Singapura, dan pasukan Universiti Teknologi Nanyang Singapura bersama-sama mengeluarkan dan bersumber terbuka Vitron sejagat tahap piksel visual model bahasa besar berbilang modal .
Ini ialah model besar multi-modal visual tugas berat yang menyokong satu siri tugasan visual daripada pemahaman visual kepada penjanaan visual, daripada tahap rendah ke tahap tinggi dan menyelesaikan masalah imej yang telah melanda model bahasa besar industri untuk jangka masa yang lama. meletakkan asas untuk model besar visual umum generasi seterusnya. Bentuk muktamad meletakkan asas dan menandakan satu lagi langkah besar ke arah kecerdasan buatan (AGI) umum untuk model besar. Vitron, sebagai model bahasa besar berbilang mod visual tahap piksel bersatu, mencapai sokongan menyeluruh untuk tugas visual daripada peringkat rendah ke peringkat tinggi ,
mampu mengendalikan tugas visual yang kompleks,dan Fahami dan jana kandungan imej dan video, memberikan pemahaman visual yang kuat dan keupayaan pelaksanaan tugas. Pada masa yang sama, Vitron menyokong operasi berterusan dengan pengguna, membolehkan interaksi manusia-komputer yang fleksibel, menunjukkan potensi besar ke arah model universal multi-modal visual yang lebih bersatu. Kertas, kod dan tunjuk cara berkaitan Vitron semuanya telah
didedahkan kepada umumIa telah menunjukkan kelebihan dan potensi unik dari segi kelengkapan, inovasi teknologi, interaksi manusia-komputer dan potensi aplikasi hanya mempromosikan Ia bukan sahaja menggalakkan pembangunan model besar berbilang modal, tetapi juga menyediakan hala tuju baharu untuk penyelidikan model besar visual masa hadapan. Kunlun Wanwei 2050Institut Penyelidikan Global telah komited untuk membina
sebuah institusi penyelidikan saintifik yang cemerlang untuk dunia masa depan, dan bekerjasama dengan komuniti saintifik untuk menyeberangi ”, terokai dunia yang tidak diketahui, cipta masa depan yang lebih baik. Sebelum ini, Kunlun Wanwei 2050Institut Penyelidikan Global telah mengeluarkan dan sumber terbuka kit alat penyelidikan dan pembangunan ejen digitalAgentStudio Pada masa hadapan, institut penyelidikan akan terus mempromosikan kecerdasan buatan. penemuan , menyumbang kepada pembinaan ekologi kecerdasan buatan China. Perkembangan semasa model bahasa besar visual (LLM) telah mencapai kemajuan yang memuaskan. Masyarakat semakin percaya bahawa membina model besar berbilang modal (MLLM) yang lebih umum dan berkuasa akan menjadi satu-satunya cara untuk mencapai kecerdasan buatan am (AGI). Walau bagaimanapun, masih terdapat beberapa cabaran utama dalam proses menuju ke arah model umum pelbagai modal (Generalis). Sebagai contoh, sebahagian besar kerja tidak mencapai pemahaman visual tahap piksel yang terperinci atau tidak mempunyai sokongan bersatu untuk imej dan video. Atau sokongan untuk pelbagai tugas visual tidak mencukupi, dan ia jauh dari model besar sejagat. Untuk mengisi jurang ini, baru-baru ini, Institut Penyelidikan Global Kunlun Worldwide 2050, Universiti Nasional Singapura, dan pasukan Universiti Teknologi Nanyang Singapura telah bersama-sama mengeluarkan model bahasa besar berbilang mod visual peringkat piksel universal sumber terbuka Vitron. . Vitron menyokong satu siri tugas visual daripada pemahaman visual kepada penjanaan visual, daripada tahap rendah kepada tahap tinggi, termasuk pemahaman komprehensif, penjanaan, pembahagian dan penyuntingan imej statik dan kandungan video dinamik. Vitron telah menerangkan secara komprehensif sokongan fungsian untuk empat tugas utama berkaitan penglihatan. dan kelebihan utamanya. Vitron juga menyokong operasi berterusan dengan pengguna untuk mencapai interaksi manusia-mesin yang fleksibel. Projek ini menunjukkan potensi besar untuk model am berbilang modal penglihatan yang lebih bersatu, meletakkan asas bagi bentuk muktamad model besar penglihatan am generasi seterusnya. Kertas, kod dan demo berkaitan Vitron kini semuanya terbuka.
Tajuk kertas: Vitron: Visi Tahap Pixel Bersatu LLM untuk Memahami, Menjana, Membahagikan, MengeditLaman utama projek & Demo: https://vitron-llm.github.io/
Pautan kertas: https:/ / is.gd/aGu0VV
Kod sumber terbuka: https://github.com/SkyworkAI/Vitron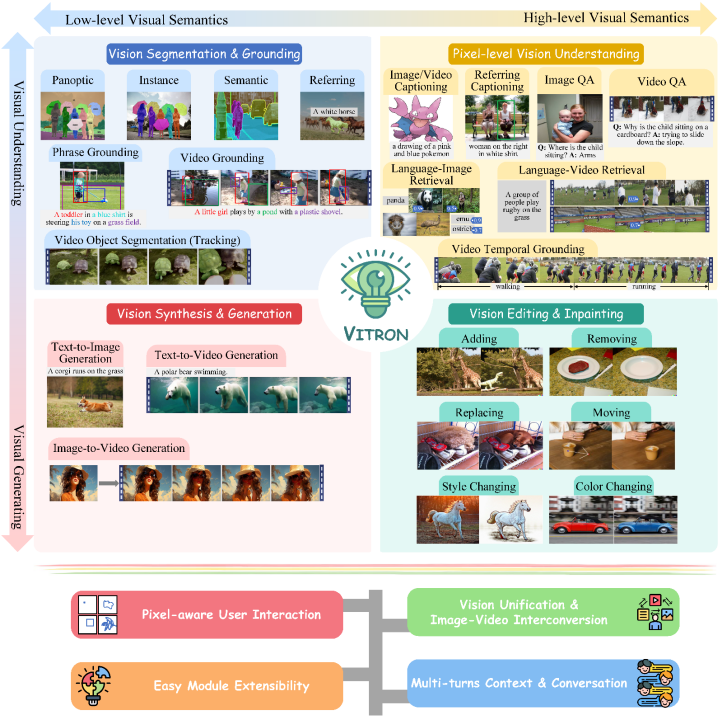
Dalam beberapa tahun kebelakangan ini, model bahasa besar (LLM) telah menunjukkan kuasa yang tidak pernah berlaku sebelum ini, dan telah terbukti secara beransur-ansur sebagai laluan teknikal ke AGI. Model bahasa besar multimodal (MLLM) berkembang pesat dalam banyak komuniti dan muncul dengan pantas Dengan memperkenalkan modul yang boleh melakukan persepsi visual, LLM berasaskan bahasa tulen diperluaskan kepada MLLM yang hebat dan cemerlang dalam pemahaman imej. seperti BLIP-2, LLaVA, MiniGPT-4, dsb. Pada masa yang sama, MLLM yang memfokuskan pada pemahaman video juga telah dilancarkan, seperti VideoChat, Video-LLaMA, Video-LLaVA, dsb.
Seterusnya, penyelidik terutamanya cuba mengembangkan lagi keupayaan MLLM daripada dua dimensi. Di satu pihak, penyelidik cuba mendalami pemahaman MLLM tentang penglihatan, beralih daripada pemahaman peringkat contoh kasar kepada pemahaman terperinci imej peringkat piksel, dengan itu mencapai keupayaan kedudukan wilayah visual (Pembuatan Serantau), seperti GLaMM, PixelLM , NExT-Chat dan MiniGPT-v2 dsb. Sebaliknya, penyelidik cuba mengembangkan fungsi visual yang boleh disokong oleh MLLM. Beberapa penyelidikan telah mula mengkaji bagaimana MLLM bukan sahaja memahami isyarat visual input, tetapi juga menyokong penjanaan kandungan visual output. Contohnya, MLLM seperti GILL dan Emu boleh menjana kandungan imej secara fleksibel, dan GPT4Video dan NExT-GPT merealisasikan penjanaan video.
Pada masa ini, komuniti kecerdasan buatan telah secara beransur-ansur mencapai kata sepakat bahawa trend masa depan MLLM visual pasti akan berkembang ke arah keupayaan yang sangat bersatu dan lebih kukuh. Walau bagaimanapun, walaupun terdapat banyak MLLM yang dibangunkan oleh komuniti, jurang yang jelas masih wujud.
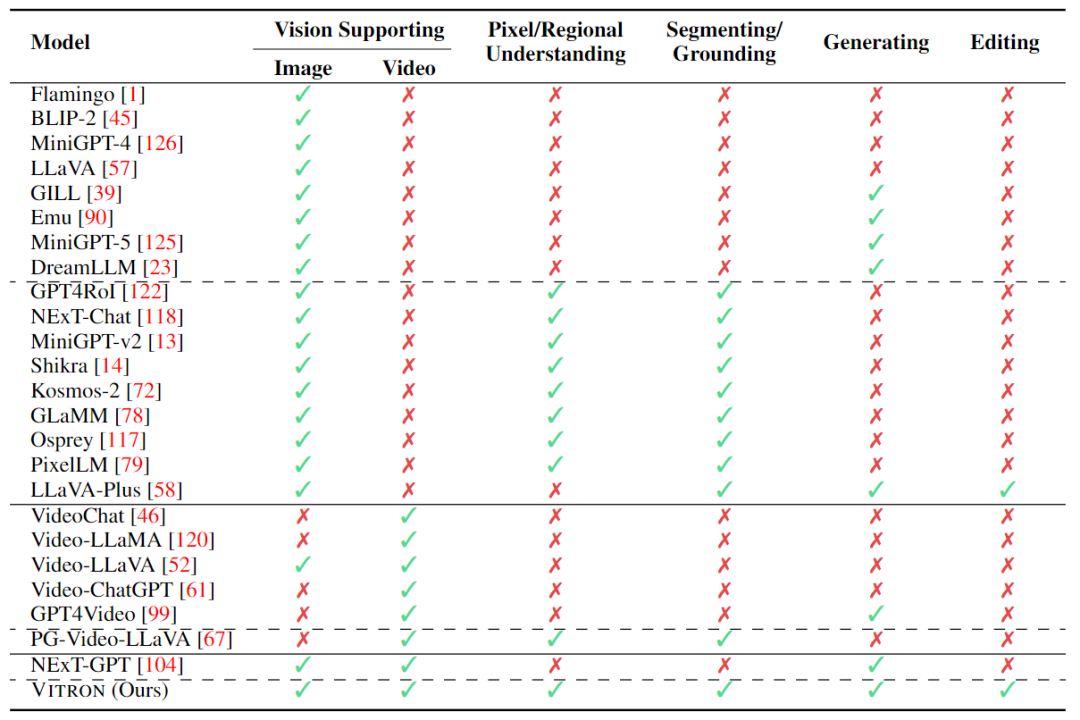
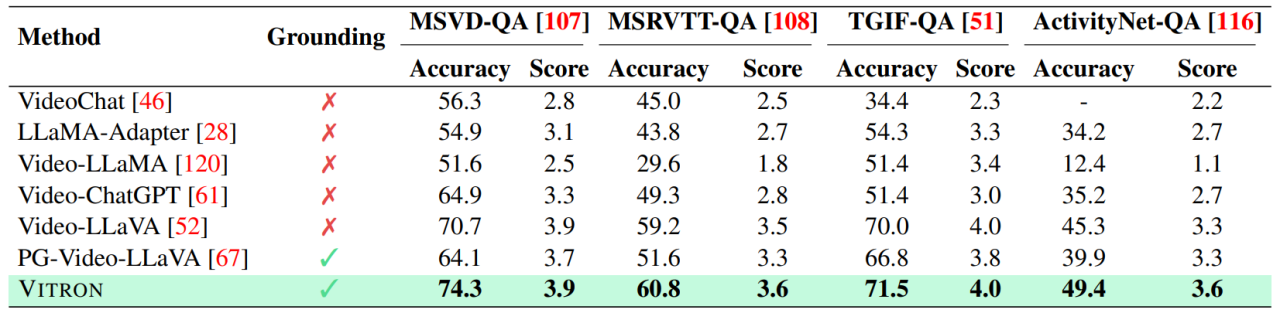
Jadual di atas hanya meringkaskan keupayaan MLLM visual sedia ada (hanya beberapa model disertakan secara representatif dan liputan tidak lengkap). Untuk merapatkan jurang ini, pasukan mencadangkan Vitron, MLLM visual peringkat piksel umum.
02 Seni bina sistem Vitron : tiga modul utama
Rangka kerja keseluruhan Vitron ditunjukkan dalam rajah di bawah. Vitron menggunakan seni bina yang serupa dengan MLLM berkaitan sedia ada, termasuk tiga bahagian penting: 1) modul pengekodan visual & bahasa bahagian hadapan, 2) modul pemahaman dan penjanaan teks LLM pusat, dan 3) respons pengguna dan panggilan modul belakang untuk kawalan visual modul.
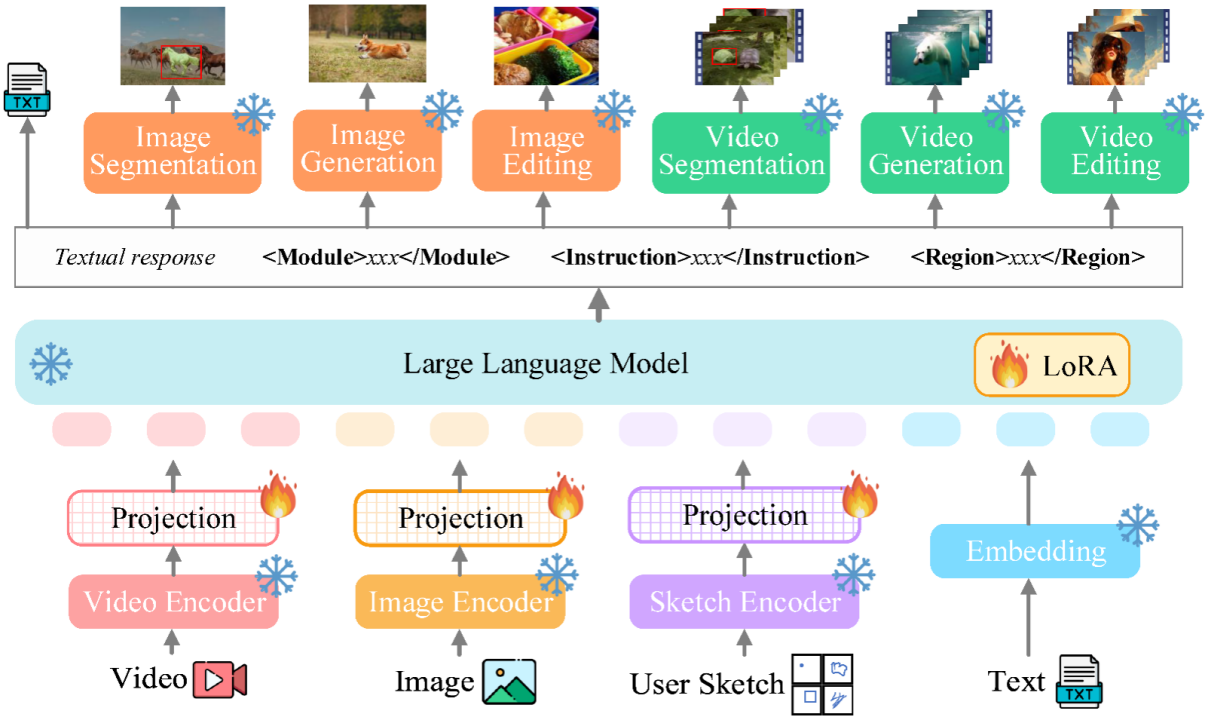
1) Output respons pengguna, membalas terus kepada pengguna input .
2) Nama modul, menunjukkan fungsi atau tugas yang perlu dilakukan.
3) Panggil arahan untuk mencetuskan meta-arahan modul tugas.
4) Rantau (output pilihan) yang menentukan ciri visual terperinci yang diperlukan untuk tugasan tertentu, seperti dalam penjejakan video atau penyuntingan visual, di mana modul hujung belakang memerlukan maklumat ini. Untuk wilayah, berdasarkan pemahaman tahap piksel LLM, kotak sempadan yang diterangkan mengikut koordinat akan dikeluarkan. . Vitron menunjukkan keupayaan kukuh dalam empat kumpulan tugas visual utama (segmentasi, pemahaman, penjanaan kandungan dan penyuntingan), sementara pada masa yang sama ia mempunyai keupayaan interaksi manusia-komputer yang fleksibel. Berikut secara perwakilan menunjukkan beberapa hasil perbandingan kualitatif:

Hasil pembahagian imej yang merujuk imej
Penglihatan Berbutir halus
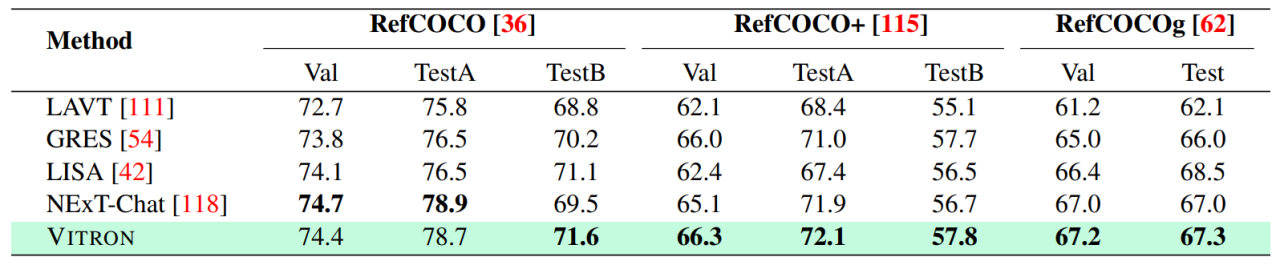
Keputusan pada QA video hasil pengeditan

Tinjauan Hala Tuju Masa Depan
 Secara keseluruhannya, kerja ini menunjukkan potensi besar untuk membangunkan model besar visual multi-modal bersatu, meletakkan asas untuk generasi penyelidikan besar seterusnya . Ia mengambil bentuk baharu dan mengambil langkah pertama ke arah ini. Walaupun sistem Vitron yang dicadangkan oleh pasukan menunjukkan keupayaan umum yang kuat, ia masih mempunyai batasannya sendiri. Penyelidik berikut menyenaraikan beberapa arah yang boleh diterokai dengan lebih lanjut pada masa hadapan.
Secara keseluruhannya, kerja ini menunjukkan potensi besar untuk membangunkan model besar visual multi-modal bersatu, meletakkan asas untuk generasi penyelidikan besar seterusnya . Ia mengambil bentuk baharu dan mengambil langkah pertama ke arah ini. Walaupun sistem Vitron yang dicadangkan oleh pasukan menunjukkan keupayaan umum yang kuat, ia masih mempunyai batasannya sendiri. Penyelidik berikut menyenaraikan beberapa arah yang boleh diterokai dengan lebih lanjut pada masa hadapan.
Sistem Vitron masih menggunakan pendekatan separa sendi, separa ejen untuk memanggil alat luaran. Walaupun kaedah berasaskan panggilan ini memudahkan pengembangan dan penggantian modul yang berpotensi, ini juga bermakna modul hujung belakang struktur saluran paip ini tidak mengambil bahagian dalam pembelajaran bersama modul teras hadapan dan LLM. Had ini tidak kondusif untuk pembelajaran keseluruhan sistem, yang bermaksud bahawa had atas prestasi tugas penglihatan yang berbeza akan dihadkan oleh modul bahagian belakang. Kerja masa depan harus mengintegrasikan pelbagai modul tugas visi ke dalam unit bersatu. Mencapai pemahaman bersatu dan output imej dan video sambil menyokong keupayaan penjanaan dan penyuntingan melalui paradigma generatif tunggal kekal sebagai cabaran. Pada masa ini, pendekatan yang menjanjikan adalah untuk menggabungkan tokenisasi berterusan modulariti untuk meningkatkan penyatuan sistem pada input dan output yang berbeza dan pelbagai tugas.
Tidak seperti model sebelumnya yang memfokuskan pada tugas penglihatan tunggal (cth., Stable Diffusion dan SEEM), Vitron bertujuan untuk memudahkan interaksi mendalam antara LLM dan pengguna, serupa dengan OpenAI dalam industri siri DALL-E , Pertengahan, dsb. Mencapai interaktiviti pengguna yang optimum ialah salah satu matlamat teras kerja ini. Vitron memanfaatkan LLM berasaskan bahasa sedia ada, digabungkan dengan pelarasan arahan yang sesuai, untuk mencapai tahap interaktiviti tertentu. Sebagai contoh, sistem boleh bertindak balas secara fleksibel kepada sebarang input mesej yang dijangkakan oleh pengguna dan menghasilkan hasil operasi visual yang sepadan tanpa memerlukan input pengguna untuk sepadan dengan keadaan modul bahagian belakang. Walau bagaimanapun, kerja ini masih meninggalkan banyak ruang untuk penambahbaikan dari segi meningkatkan interaktiviti. Sebagai contoh, mendapat inspirasi daripada sistem Midjourney sumber tertutup, tidak kira apa keputusan yang dibuat oleh LLM pada setiap langkah, sistem harus secara aktif memberikan maklum balas kepada pengguna untuk memastikan tindakan dan keputusannya konsisten dengan niat pengguna.
Keupayaan modal
Pada masa ini, Vitron menyepadukan model 7B Vicuna, yang mungkin mempunyai had tertentu pada keupayaannya untuk memahami bahasa, imej dan video. Hala tuju penerokaan masa hadapan adalah untuk membangunkan sistem hujung ke hujung yang komprehensif, seperti mengembangkan skala model untuk mencapai pemahaman visi yang lebih teliti dan menyeluruh. Tambahan pula, usaha perlu dilakukan untuk membolehkan LLM menyatukan sepenuhnya pemahaman modaliti imej dan video.
Atas ialah kandungan terperinci Di bawah kepimpinan Yan Shuicheng, Institut Penyelidikan Global Kunlun Wanwei 2050 bersama-sama mengeluarkan Vitron dengan NUS dan NTU, mewujudkan bentuk muktamad model besar multimodal visual universal.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



