


Kuantiti, pemangkasan, penyulingan, jika anda sering memberi perhatian kepada model bahasa yang besar, anda pasti akan melihat kata-kata ini, sukar untuk kita memahami apa yang mereka lakukan, tetapi perkataan ini sangat penting untuk pembangunan model bahasa besar pada peringkat ini. Artikel ini akan membantu anda mengenali mereka dan memahami prinsip mereka.
Kuantisasi, pemangkasan dan penyulingan sebenarnya adalah teknologi pemampatan model rangkaian saraf umum, bukan eksklusif kepada model bahasa besar.
Selepas pemampatan, fail model akan menjadi lebih kecil, ruang cakera keras yang digunakan juga akan menjadi lebih kecil, ruang cache yang digunakan semasa memuatkan ke dalam memori atau dipaparkan juga akan menjadi lebih kecil, dan berjalan model juga akan menjadi lebih kecil. Mungkin juga terdapat beberapa peningkatan kelajuan.
Melalui pemampatan, menggunakan model akan menggunakan kurang sumber pengkomputeran, yang boleh meluaskan senario aplikasi model, terutamanya tempat di mana saiz model dan kecekapan pengkomputeran lebih dititikberatkan, seperti telefon mudah alih, peranti terbenam, dsb.
Apa yang dimampatkan ialah parameter model.
Anda mungkin pernah mendengar bahawa pembelajaran mesin semasa menggunakan model rangkaian saraf Model rangkaian saraf meniru rangkaian saraf dalam otak manusia.
Di sini saya lukis gambar rajah mudah, anda boleh lihat.
 Gambar
Gambar
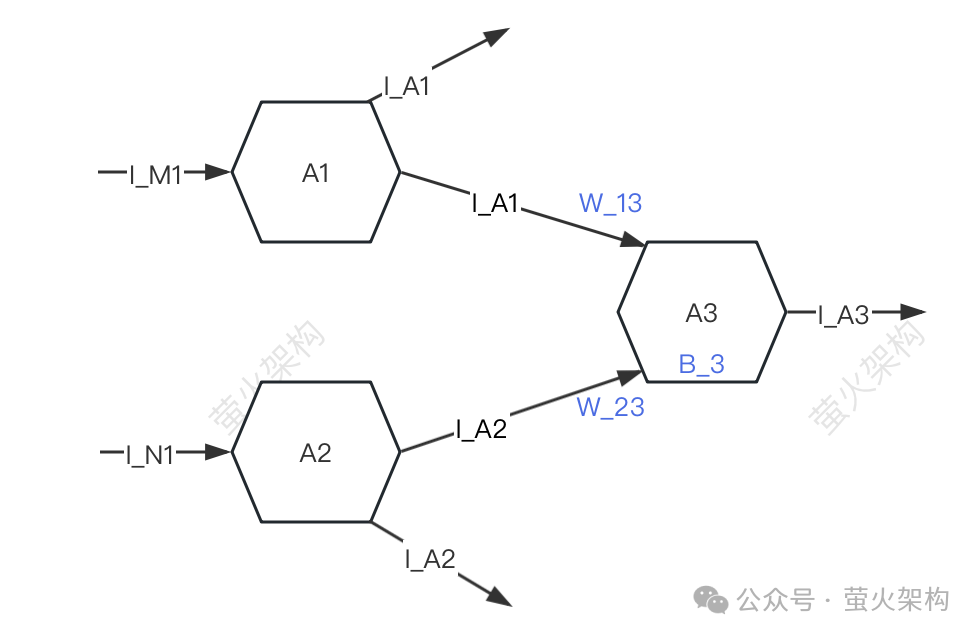
Untuk kesederhanaan, hanya tiga neuron diterangkan: A1, A2, A3. Setiap neuron menerima isyarat daripada neuron lain dan menghantar isyarat kepada neuron lain.
A3 akan menerima isyarat I_A1 dan I_A2 daripada A1 dan A2, tetapi kekuatan isyarat yang diterima oleh A3 daripada A1 dan A2 adalah berbeza (kekuatan ini dipanggil "berat"). W_23 masing-masing , A3 akan memproses data isyarat yang diterima.
Apabila menggunakan model bahasa yang besar untuk menghasilkan teks, parameter ini sudah dilatih dan kami tidak boleh mengubah suainya seperti pekali polinomial dalam matematik Kami hanya boleh lulus dalam xyz yang tidak diketahui dan mendapatkan hasil Output .
Mampatan model adalah untuk memampatkan parameter model ini Pertimbangan utama adalah berat dan berat sebelah Kaedah khusus yang digunakan ialah kuantisasi, pemangkasan dan penyulingan, yang menjadi tumpuan artikel ini.
Quantization
Ia seperti mengikut resipi, anda perlu menentukan berat setiap bahan. Anda boleh menggunakan penimbang elektronik yang sangat tepat iaitu tepat hingga 0.01 gram, yang sangat bagus kerana anda boleh mengetahui berat setiap bahan dengan sangat tepat. Walau bagaimanapun, jika anda hanya membuat hidangan potluck dan sebenarnya tidak memerlukan ketepatan yang tinggi, anda boleh menggunakan skala yang mudah dan murah dengan skala minimum 1 gram, yang tidak seberapa tepat tetapi cukup untuk membuat hidangan yang lazat. makan malam.
Gambar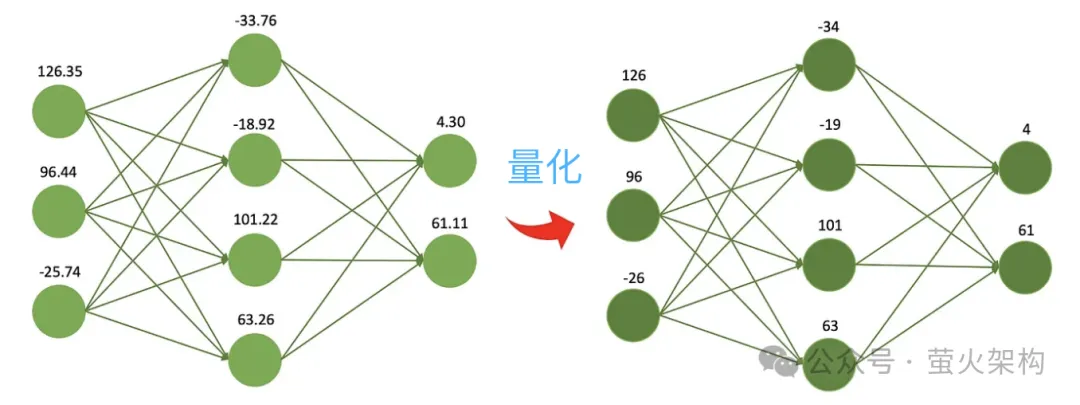
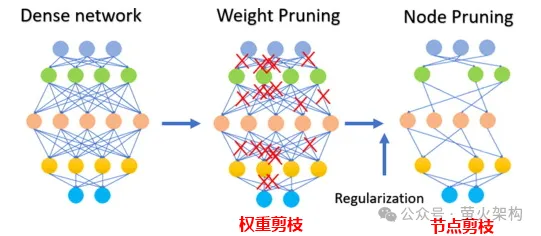
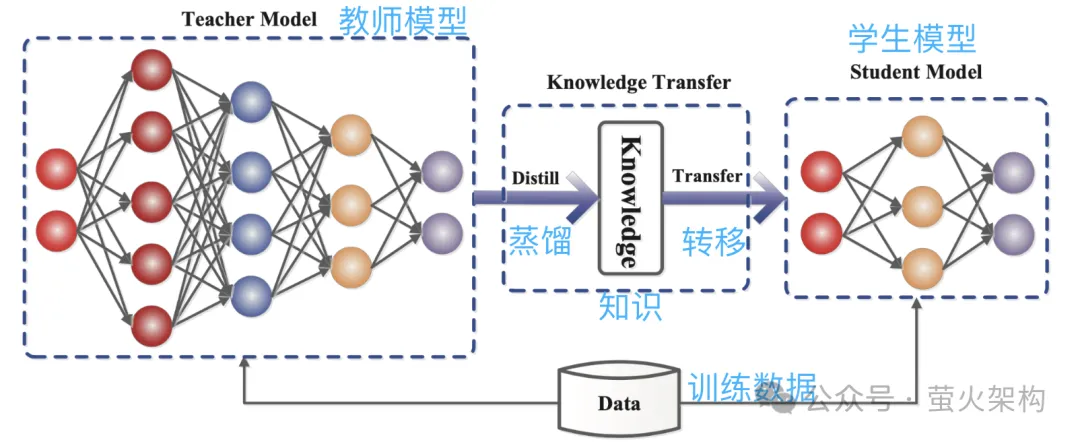
Berikutan idea ini, orang ramai terus memampatkan model 8-bit, 4-bit dan 2-bit, yang bersaiz lebih kecil dan menggunakan kurang sumber pengkomputeran. Walau bagaimanapun, apabila ketepatan pemberat berkurangan, nilai pemberat yang berbeza akan menjadi lebih hampir atau sama, yang akan mengurangkan ketepatan dan ketepatan keluaran model, dan prestasi model akan menurun kepada tahap yang berbeza-beza. Teknologi kuantisasi mempunyai banyak strategi dan butiran teknikal yang berbeza, seperti kuantisasi dinamik, kuantisasi statik, kuantisasi simetri, kuantisasi asimetri, dll. Untuk model bahasa besar, strategi kuantisasi statik biasanya digunakan Selepas latihan model selesai, kami Parameter dikira sekali, dan pengiraan kuantitatif tidak lagi diperlukan apabila model dijalankan, menjadikannya mudah untuk diedarkan dan digunakan. Pemangkasan adalah untuk membuang pemberat yang tidak penting atau jarang digunakan dalam model Nilai pemberat ini secara amnya hampir kepada 0. Bagi sesetengah model, pemangkasan boleh menghasilkan nisbah mampatan yang lebih tinggi, menjadikan model lebih padat dan cekap. Ini amat berguna untuk menggunakan model pada peranti yang dikekang sumber atau apabila memori dan storan terhad. Pemangkasan juga meningkatkan kebolehtafsiran model. Dengan mengalih keluar komponen yang tidak diperlukan, pemangkasan menjadikan struktur asas model lebih telus dan lebih mudah untuk dianalisis. Ini penting untuk memahami proses membuat keputusan model kompleks seperti rangkaian saraf. Pemangkasan bukan sahaja melibatkan parameter berat pemangkasan, tetapi juga pemangkasan nod neuron tertentu, seperti yang ditunjukkan dalam rajah berikut: Perhatikan bahawa pemangkasan tidak sesuai untuk semua model. model (kebanyakan parameter adalah 0 atau hampir dengan 0), pemangkasan mungkin tidak mempunyai kesan; Ia tidak sesuai untuk pemangkasan model, seperti diagnosis perubatan, yang merupakan soal hidup dan mati. Apabila benar-benar menggunakan teknologi pemangkasan, biasanya perlu mempertimbangkan secara menyeluruh peningkatan kelajuan larian model dan kesan negatif pemangkasan ke atas prestasi model, dan menggunakan beberapa strategi, seperti menjaringkan setiap parameter dalam model, iaitu, menilai parameter. Berapa banyak ia menyumbang kepada prestasi model. Mereka yang mempunyai markah tinggi ialah parameter penting yang tidak boleh dipotong; mereka yang mempunyai markah rendah ialah parameter yang mungkin tidak begitu penting dan boleh dipertimbangkan untuk dipotong. Skor ini boleh dikira melalui pelbagai kaedah, seperti melihat saiz parameter (nilai mutlak yang lebih besar biasanya lebih penting), atau ditentukan melalui beberapa kaedah analisis statistik yang lebih kompleks. Penyulingan adalah untuk menyalin terus taburan kebarangkalian yang dipelajari oleh model besar ke dalam model kecil. Model yang disalin dipanggil model guru, yang secara amnya merupakan model yang sangat baik dengan sejumlah besar parameter dan prestasi yang kukuh Model baru dipanggil model pelajar, yang secara amnya merupakan model kecil dengan parameter yang agak sedikit. Semasa penyulingan, model guru akan menjana pengagihan kebarangkalian berbilang output yang mungkin berdasarkan input, dan kemudian model pelajar akan mempelajari pengagihan kebarangkalian input dan output ini. Selepas latihan yang meluas, model pelajar boleh meniru tingkah laku model guru, atau mempelajari pengetahuan model guru. Sebagai contoh, dalam tugas pengelasan imej, diberikan gambar, model guru mungkin mengeluarkan taburan kebarangkalian yang serupa dengan yang berikut: Kemudian serahkan gambar ini dan maklumat taburan kebarangkalian output kepada model pelajar untuk pembelajaran tiruan. Oleh kerana penyulingan memampatkan pengetahuan model guru menjadi model pelajar yang lebih kecil dan mudah, model baharu mungkin kehilangan beberapa maklumat di samping itu, model pelajar mungkin terlalu bergantung pada model guru, menyebabkan model kebolehan generalisasi yang lemah. Untuk menjadikan kesan pembelajaran model pelajar lebih baik, kita boleh mengamalkan beberapa kaedah dan strategi. Memperkenalkan parameter suhu: Andaikata ada guru yang mengajar sangat cepat dan kepadatan maklumat sangat tinggi, mungkin agak sukar untuk diikuti oleh pelajar. Pada masa ini, jika guru memperlahankan dan mempermudahkan maklumat, lebih mudah untuk pelajar memahami. Dalam penyulingan model, parameter suhu memainkan peranan yang serupa dengan "melaraskan kelajuan kuliah" untuk membantu model pelajar (model kecil) lebih memahami dan mempelajari pengetahuan model guru (model besar). Secara profesional, ia adalah untuk menjadikan output model sebagai taburan kebarangkalian yang lebih lancar, menjadikannya lebih mudah bagi model pelajar untuk menangkap dan mempelajari butiran output model guru. Laraskan struktur model guru dan model pelajar: Mungkin sukar untuk pelajar mempelajari sesuatu daripada pakar, kerana jurang pengetahuan antara mereka terlalu besar, dan pembelajaran langsung mungkin tidak faham pada masa ini tambah seorang guru di tengah, yang boleh sama-sama memahami kata-kata pakar dan menterjemahkannya ke dalam bahasa yang boleh difahami oleh pelajar. Guru menambah di tengah mungkin beberapa lapisan perantaraan atau rangkaian saraf tambahan, atau guru boleh membuat beberapa pelarasan pada model pelajar supaya ia dapat memadankan dengan lebih baik output model guru. Kami telah memperkenalkan tiga teknologi pemampatan model utama di atas Sebenarnya, masih terdapat banyak butiran di sini, tetapi ia hampir cukup untuk memahami prinsip Terdapat juga teknologi pemampatan model lain, seperti penguraian peringkat rendah dan perkongsian parameter , sambungan jarang, dsb. Pelajar yang berminat boleh menyemak lebih banyak kandungan yang berkaitan. Selain itu, selepas model dimampatkan, prestasinya mungkin menurun dengan ketara Pada masa ini, kita boleh membuat beberapa penalaan halus model, terutamanya untuk tugas yang memerlukan ketepatan model yang tinggi, seperti diagnosis perubatan, risiko kewangan. kawalan, dan automatik Untuk pemanduan, dsb., penalaan halus boleh memulihkan prestasi model pada tahap tertentu dan menstabilkan ketepatan dan ketepatannya dalam aspek tertentu. Bercakap tentang penalaan halus model, saya baru-baru ini telah berkongsi imej WebUI Penjanaan Teks pada AutoDL Penjanaan Teks WebUI ialah program web yang ditulis menggunakan Gradio, yang boleh melakukan inferens dan penalaan halus model bahasa besar dan sokongan. pelbagai Jenis model bahasa besar, termasuk Transformers, llama.cpp (GGUF), GPTQ, AWQ, EXL2 dan model lain dalam pelbagai format Dalam imej terkini, saya telah terbina dalam model besar Llama3 yang bersumberkan Meta . Pelajar yang berminat Anda boleh mencubanya, dan lihat cara menggunakannya: Belajar memperhalusi model bahasa yang besar dalam masa sepuluh minit Artikel rujukan: //m.sbmmt.com/link/d7852cd2408d9d3205dc75b59 a6ce22e //m.sbmmt.com/link/f204aab71691a8e18c3d //m.sbmmt.com/link/b31f0c758bb498b5d56b5fea80 f313a7Pemangkasan
 Gambar
GambarPenyulingan
 Gambar
Gambar Gambar
Gambar
Atas ialah kandungan terperinci Kuantiti, pemangkasan, penyulingan, apa sebenarnya yang dikatakan slanga model besar ini?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk memulihkan video yang telah dialih keluar secara rasmi daripada Douyin
Bagaimana untuk memulihkan video yang telah dialih keluar secara rasmi daripada Douyin
 js untuk menjana nombor rawak
js untuk menjana nombor rawak
 Berapa tinggi Ethereum akan pergi?
Berapa tinggi Ethereum akan pergi?
 Bagaimana untuk memulihkan fail yang dipadam pada komputer
Bagaimana untuk memulihkan fail yang dipadam pada komputer
 Berapa tahun anda perlu membayar insurans perubatan untuk menikmati insurans perubatan sepanjang hayat?
Berapa tahun anda perlu membayar insurans perubatan untuk menikmati insurans perubatan sepanjang hayat?
 Apa yang perlu dilakukan jika tiada kursor apabila mengklik pada kotak input
Apa yang perlu dilakukan jika tiada kursor apabila mengklik pada kotak input
 Apakah yang perlu saya lakukan jika huruf Inggeris muncul apabila komputer dihidupkan dan komputer tidak boleh dihidupkan?
Apakah yang perlu saya lakukan jika huruf Inggeris muncul apabila komputer dihidupkan dan komputer tidak boleh dihidupkan?
 Bagaimana untuk membuat wifi maya dalam win7
Bagaimana untuk membuat wifi maya dalam win7








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



