Snowflake menyertai pergaduhan LLM.
Snowflake mengeluarkan model "kecerdasan perusahaan" tinggi Artik, memfokuskan pada aplikasi perusahaan dalaman. Sebentar tadi, pengurusan data dan penyedia gudang Snowflake mengumumkan bahawa ia telah menyertai pergaduhan LLM dan mengeluarkan model bahasa besar (LLM) peringkat atas yang memfokuskan pada aplikasi peringkat perusahaan - Snowflake Arctic. Sebagai LLM yang dilancarkan oleh syarikat pengkomputeran awan, Arctic terutamanya mempunyai dua kelebihan berikut:
- Kecerdasan Cekap: Arctic berfungsi dengan baik dalam tugas perusahaan, seperti penjanaan arahan SQL., , malah setanding dengan model sumber terbuka yang dilatih dengan kos pengiraan yang lebih tinggi. Arctic menetapkan garis dasar baharu untuk latihan kos efektif, membolehkan pelanggan Snowflake mencipta model tersuai berkualiti tinggi pada kos rendah untuk keperluan perusahaan mereka.
- Sumber terbuka: Arctic mengguna pakai lesen Apache 2.0, menyediakan akses terbuka kepada pemberat dan kod, dan Snowflake juga akan membuka sumber semua penyelesaian data dan penemuan penyelidikan.
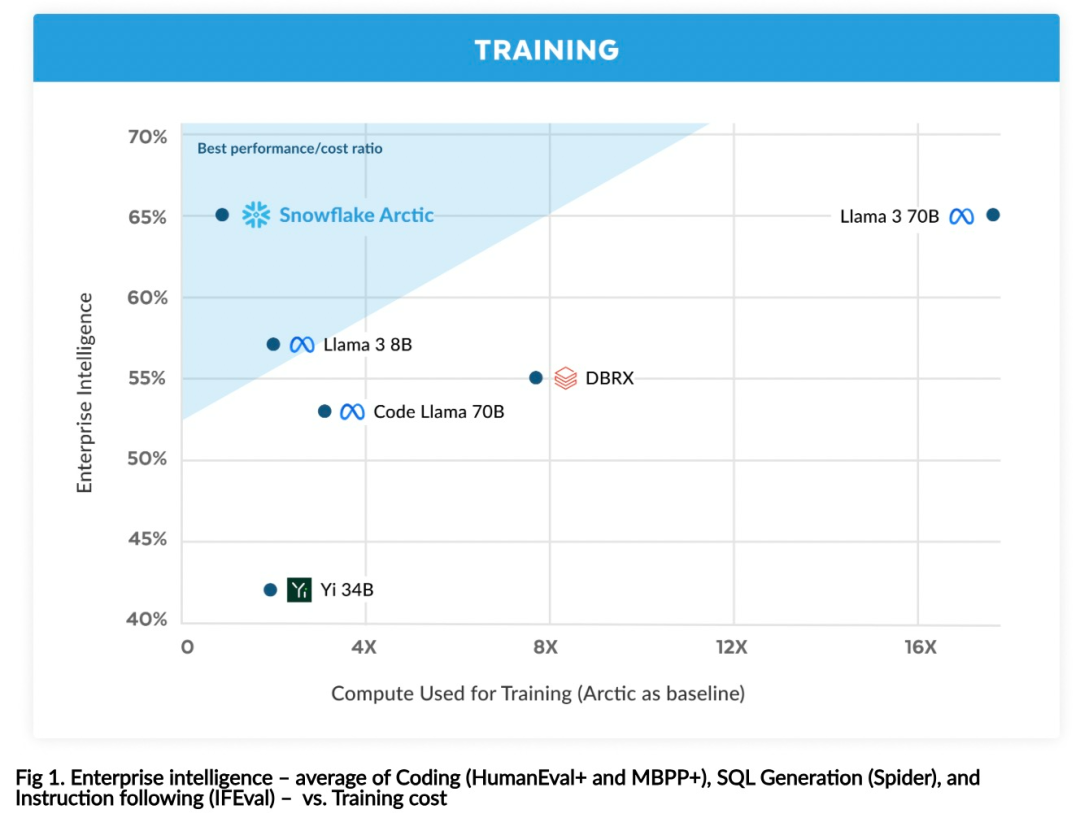
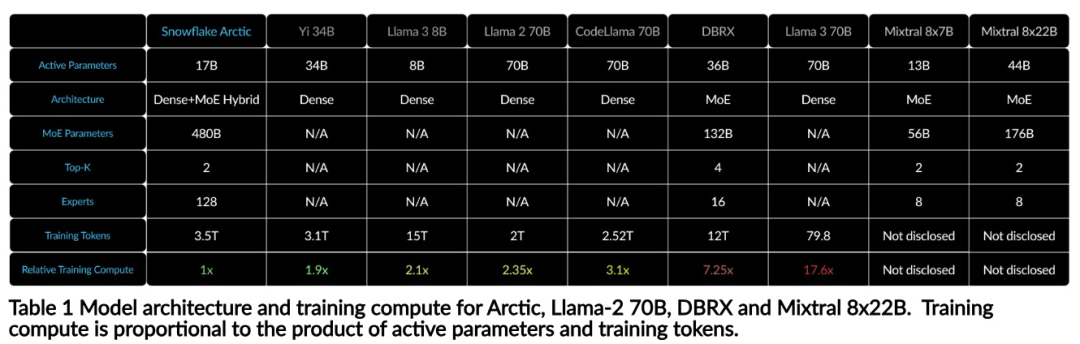
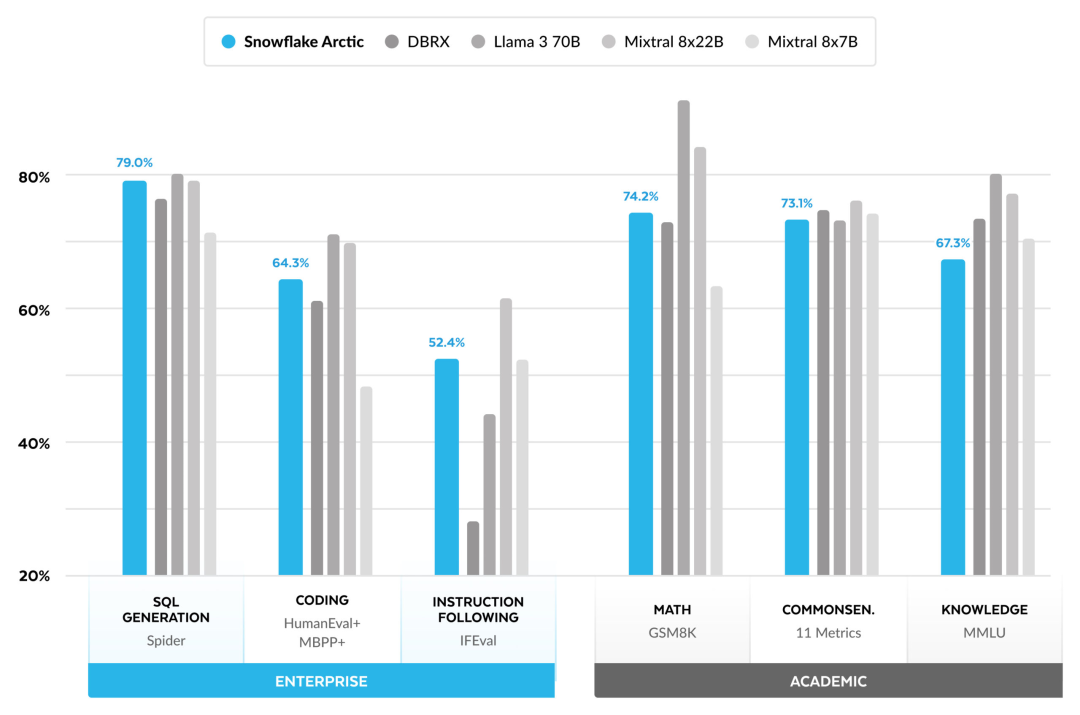
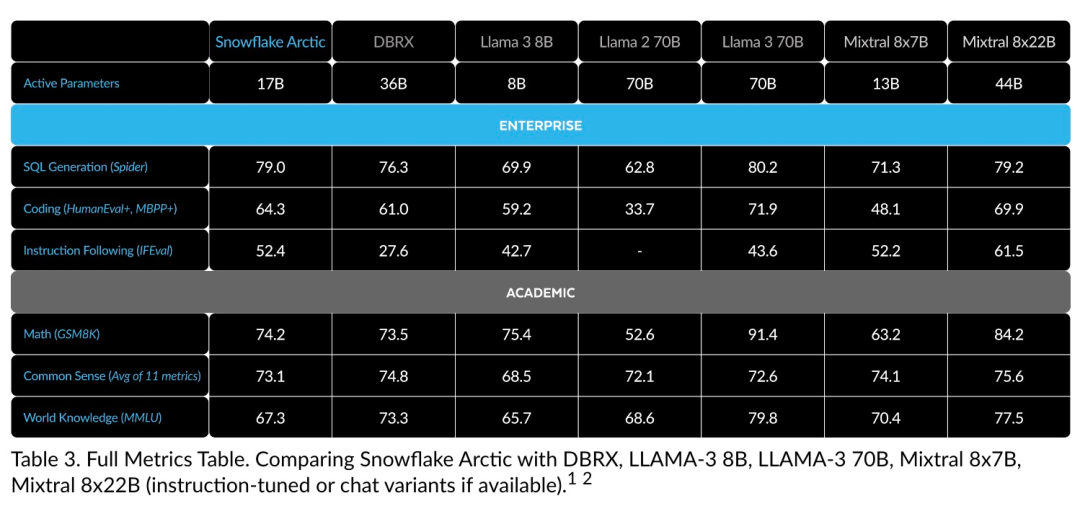
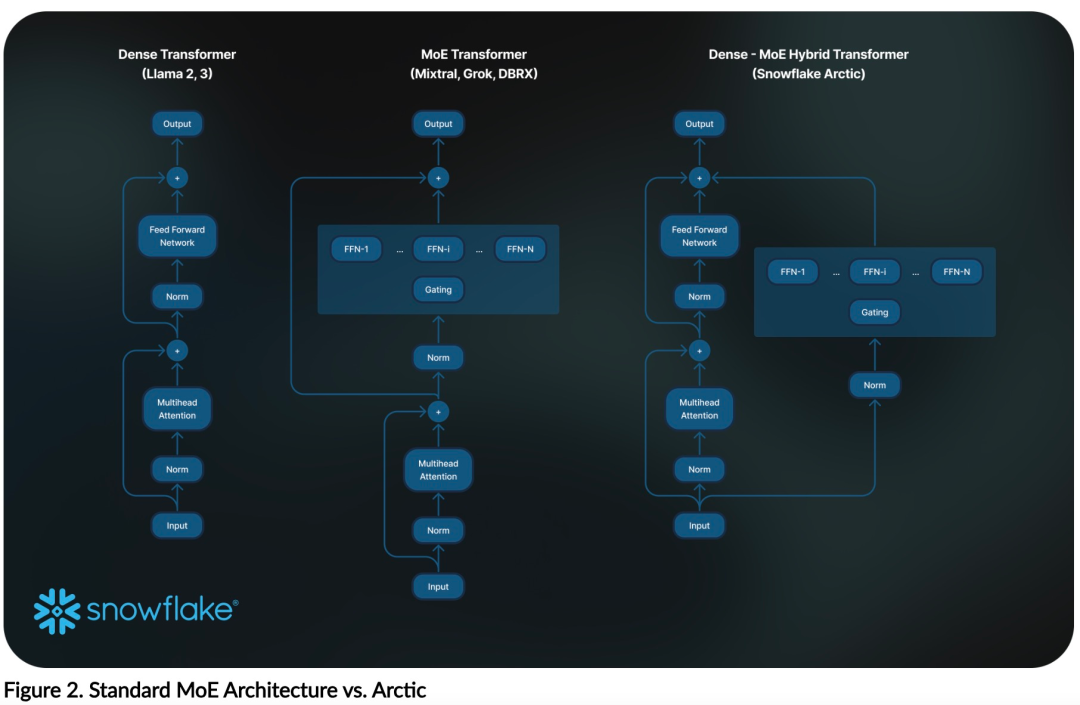
Kini anda boleh mengakses model Artik pada Muka Memeluk. Snowflake berkata: Pengguna tidak lama lagi akan dapat memperolehnya melalui beberapa perpustakaan model, termasuk Snowflake Cortex, AWS, Microsoft Azure, NVIDIA API, Lamini, Perplexity, Replicate and Together, dsb. Muka Memeluk: https://huggingface.co/Snowflake/snowflake-arctic-instructTetingkap konteks Artik ditetapkan kepada 4K, dan pasukan penyelidik sedang membangunkan tetingkap tenggelam perhatian berasaskan pelaksanaan akan menyokong penjanaan jujukan tanpa had dalam beberapa minggu akan datang dan akan dikembangkan kepada 32K tetingkap perhatian dalam masa terdekat. Prestasi tinggi, kos rendahPasukan penyelidik Snowflake melihat corak yang konsisten daripada keperluan AI dan kes penggunaan pelanggan perusahaan: perusahaan ingin menggunakan LLM untuk membina kod kod SQL perbualan copilot dan RAG chatbots. Ini bermakna LLM perlu cemerlang dalam SQL, kod, mengikut arahan yang kompleks dan menjana respons konkrit. Snowflake menggabungkan keupayaan ini ke dalam satu metrik yang dipanggil "Kecerdasan Perusahaan" dengan mengekod purata (HumanEval+ dan MBPP+), penjanaan SQL (Spider) dan tahap prestasi arahan (IFEval). Arctic mencapai tahap tertinggi "kecerdasan perusahaan" dalam LLM sumber terbuka, dan melakukannya pada kos pengiraan latihan lebih kurang $2 juta (kurang daripada 3K minggu GPU). Ini bermakna Artik lebih berkebolehan daripada model sumber terbuka lain yang dilatih dengan kos pengiraan yang serupa. Lebih penting lagi, Arctic cemerlang dalam kecerdasan perusahaan walaupun jika dibandingkan dengan model yang dilatih dengan kos pengiraan yang jauh lebih tinggi. Kecekapan latihan Arctic yang tinggi bermakna pelanggan Snowflake dan komuniti AI pada umumnya boleh melatih model tersuai dengan lebih menjimatkan kos. Seperti yang ditunjukkan dalam Rajah 1, Artik adalah setanding dengan LLAMA 3 8B dan LLAMA 2 70B pada metrik kecerdasan perusahaan sambil menggunakan kurang daripada separuh kos pengiraan latihan. Dan, walaupun hanya menggunakan 1/17 kali ganda kos pengkomputeran, Arctic adalah setanding dengan Llama3 70B dalam penunjuk seperti pengekodan (HumanEval+ dan MBPP+), SQL (Spider) dan arahan mengikut (IFEval), iaitu, Arctic mengekalkan daya saing prestasi keseluruhan melakukan ini pada masa yang sama. Selain itu, Snowflake juga menilai Artik pada penanda aras akademik, melibatkan pengetahuan dunia, penaakulan akal dan kebolehan matematik Keputusan penilaian lengkap ditunjukkan dalam rajah di bawah: 🎜🎜🎜🎜Untuk mencapai kecekapan latihan di atas, Artik menggunakan seni bina pengubah hibrid Dense-MoE yang unik. Ia menggabungkan model pengubah padat 10B dengan baki MLP MoE 128×3.66B, dengan jumlah parameter 480B dan parameter aktif 17B, menggunakan gating atas-2 untuk pemilihan. Apabila merancang dan melatih Artik, pasukan penyelidikan menggunakan tiga pandangan utama dan inovasi berikut: moe pakar dan teknologi mampatan Pada akhir 2021, pasukan deepspeed ditunjukkan bahawa MoE boleh digunakan untuk LLM autoregresif, dengan itu meningkatkan kualiti model dengan ketara tanpa meningkatkan kos pengiraan. Semasa mereka bentuk Artik, pasukan penyelidik menyedari bahawa berdasarkan idea ini, peningkatan kualiti model bergantung terutamanya pada bilangan pakar dan jumlah parameter dalam model MoE, serta bilangan gabungan pakar ini. Berdasarkan perkara ini, Arctic direka bentuk untuk mengedarkan parameter 480B di kalangan 128 pakar berbutir halus dan menggunakan gating 2 teratas untuk memilih parameter aktif 17B. . Snowflake mendapati bahawa overhed ini boleh dihapuskan jika komunikasi boleh bertindih dengan pengiraan. Oleh itu, Artik menggabungkan pengubah padat dengan komponen sisa MoE (Rajah 2) untuk mengira pertindihan melalui komunikasi, membolehkan sistem latihan mencapai kecekapan latihan yang baik, menyembunyikan kebanyakan overhed komunikasi. Pembelajaran Kurikulum Berfokus pada Data Perusahaan
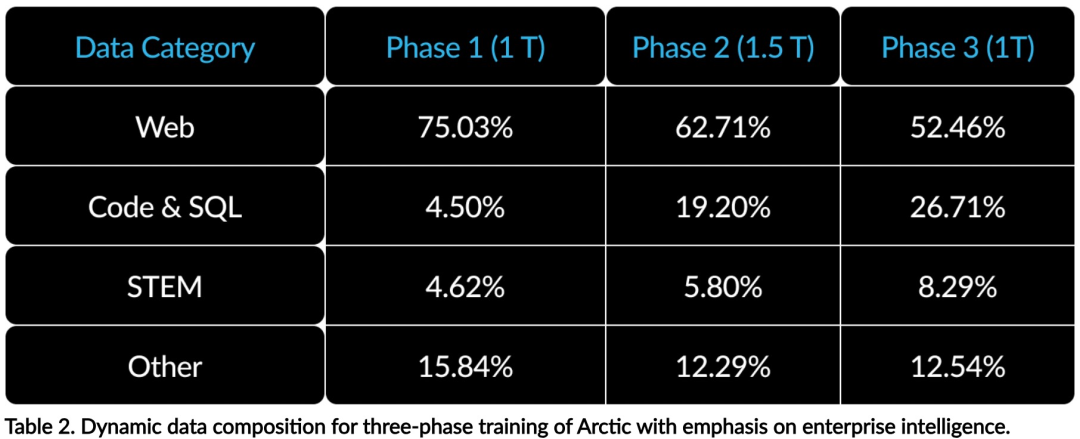
Prestasi cemerlang dalam metrik peringkat perusahaan seperti penjanaan kod dan SQL memerlukan pembelajaran kurikulum data (Pembelajaran Kurikulum) yang sama sekali berbeza daripada metrik umum Melalui ratusan eksperimen ablasi berskala kecil, pasukan mengetahui bahawa kemahiran umum, seperti penaakulan akal, boleh dipelajari pada peringkat awal manakala metrik yang lebih kompleks, seperti pengekodan, matematik dan SQL, boleh dipelajari dengan berkesan kemudian; latihan. Ini boleh dibandingkan dengan pendidikan kehidupan manusia, secara beransur-ansur memperoleh kebolehan daripada mudah kepada sukar. Oleh itu, Artik menggunakan kurikulum tiga peringkat, dengan setiap peringkat mempunyai komposisi data yang berbeza, dengan peringkat pertama memfokuskan pada kemahiran umum (token 1T) dan dua peringkat terakhir memfokuskan pada kemahiran perusahaan (token 1.5T dan 1T). Kecekapan inferens
Kecekapan inferens juga merupakan aspek penting dalam kecekapan model, yang mempengaruhi sama ada model boleh digunakan pada kos yang rendah. Artik mewakili lonjakan dalam saiz model MoE, menggunakan lebih ramai pakar dan jumlah parameter daripada mana-mana model MoE regresi sumber terbuka lain. Oleh itu, Snowflake memerlukan beberapa idea inovatif untuk memastikan Artik boleh membuat kesimpulan dengan cekap: 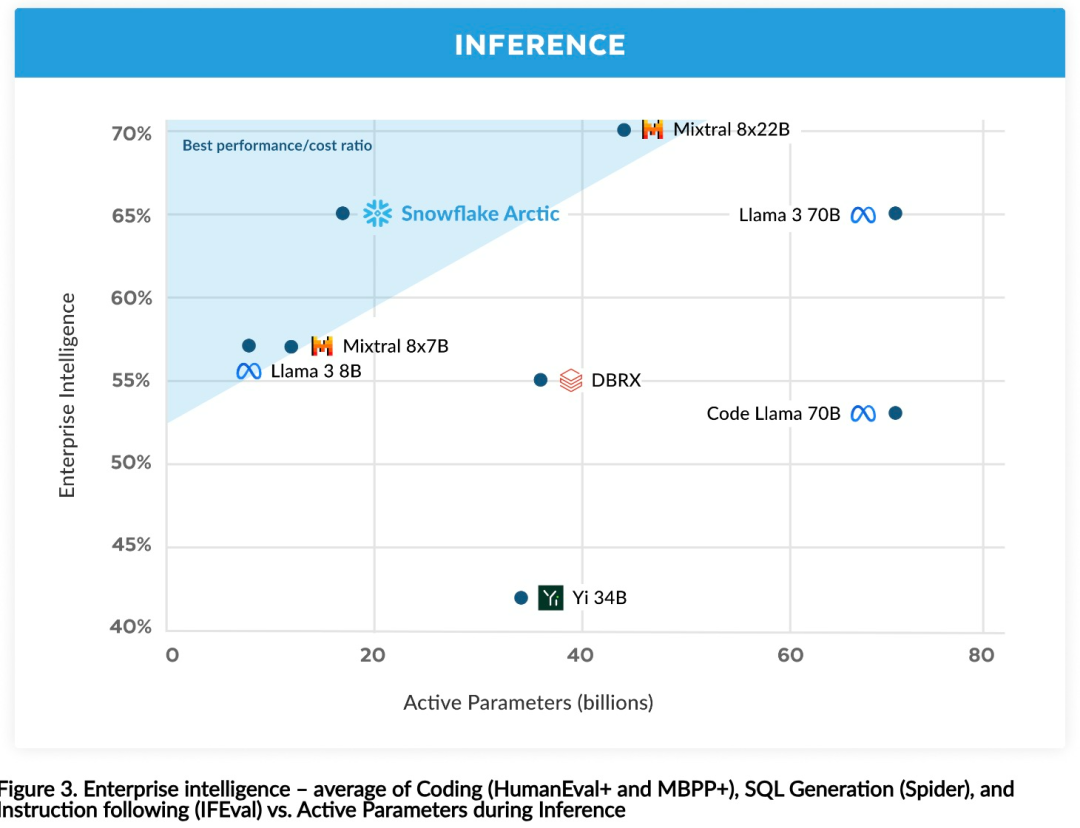 a) Dalam inferens interaktif dengan saiz kelompok kecil, seperti saiz kelompok 1, kependaman inferens model MoE dihadkan dengan membaca semua parameter aktif Masa, inferens dihadkan oleh lebar jalur memori. Pada saiz kelompok ini, volum bacaan memori Artik (parameter aktif 17B) hanyalah 1/4 daripada Kod-Llama 70B dan 2/5 daripada Mixtral 8x22B (parameter aktif 44B), menghasilkan kadar inferens yang lebih pantas.
a) Dalam inferens interaktif dengan saiz kelompok kecil, seperti saiz kelompok 1, kependaman inferens model MoE dihadkan dengan membaca semua parameter aktif Masa, inferens dihadkan oleh lebar jalur memori. Pada saiz kelompok ini, volum bacaan memori Artik (parameter aktif 17B) hanyalah 1/4 daripada Kod-Llama 70B dan 2/5 daripada Mixtral 8x22B (parameter aktif 44B), menghasilkan kadar inferens yang lebih pantas.
b) Apabila saiz kelompok meningkat dengan ketara, seperti beribu-ribu token setiap hantaran hadapan, Artik bergerak daripada lebar jalur memori terhad kepada terhad secara pengiraan, dengan inferens dihadkan oleh parameter aktif setiap token. Dalam hal ini, Artik ialah 1/4 usaha pengiraan CodeLlama 70B dan Llama 3 70B.
Untuk mencapai inferens terikat pengiraan dan daya pemprosesan tinggi yang sepadan dengan bilangan kecil parameter aktif di Artik, saiz kelompok yang lebih besar diperlukan. Untuk mencapai ini memerlukan cache KV yang mencukupi untuk menyokongnya, serta memori yang mencukupi untuk menyimpan hampir 500B parameter model.
Walaupun mencabar, Snowflake mencapai ini dengan menggunakan dua nod untuk inferens dan menggabungkan pengoptimuman sistem seperti pemberat FP8, fius berpecah dan batching berterusan, selari tensor intra-nod dan selari saluran paip antara nod.
Pasukan penyelidik telah bekerjasama rapat dengan NVIDIA untuk mengoptimumkan inferens untuk perkhidmatan mikro NVIDIA NIM yang dipacu oleh TensorRT-LLM. Pada masa yang sama, pasukan penyelidik juga bekerjasama dengan komuniti vLLM, dan pasukan pembangunan dalaman juga akan melaksanakan inferens cekap Artik untuk kes penggunaan perusahaan dalam beberapa minggu akan datang. Pautan rujukan: https://www.snowflake.com/blog/arctic-open-efficient-foundation-language-models-snowflake/Atas ialah kandungan terperinci Dengan hanya 1/17 kos latihan Llama3, model MoE sumber terbuka Snowflake 128x3B. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Apakah maksud apache?
Apakah maksud apache?
 permulaan apache gagal
permulaan apache gagal
 arahan fail cari linux
arahan fail cari linux
 kekunci pintasan baldi cat ps
kekunci pintasan baldi cat ps
 Perkara yang perlu dilakukan jika desktop jauh tidak dapat disambungkan
Perkara yang perlu dilakukan jika desktop jauh tidak dapat disambungkan
 Hubungan antara lebar jalur dan kelajuan rangkaian
Hubungan antara lebar jalur dan kelajuan rangkaian
 Windows 10 menjalankan pengenalan lokasi pembukaan
Windows 10 menjalankan pengenalan lokasi pembukaan
 Bagaimana untuk menukar perisian bahasa c ke bahasa Cina
Bagaimana untuk menukar perisian bahasa c ke bahasa Cina








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



