


Mengenai Llama 3, terdapat keputusan ujian baharu -
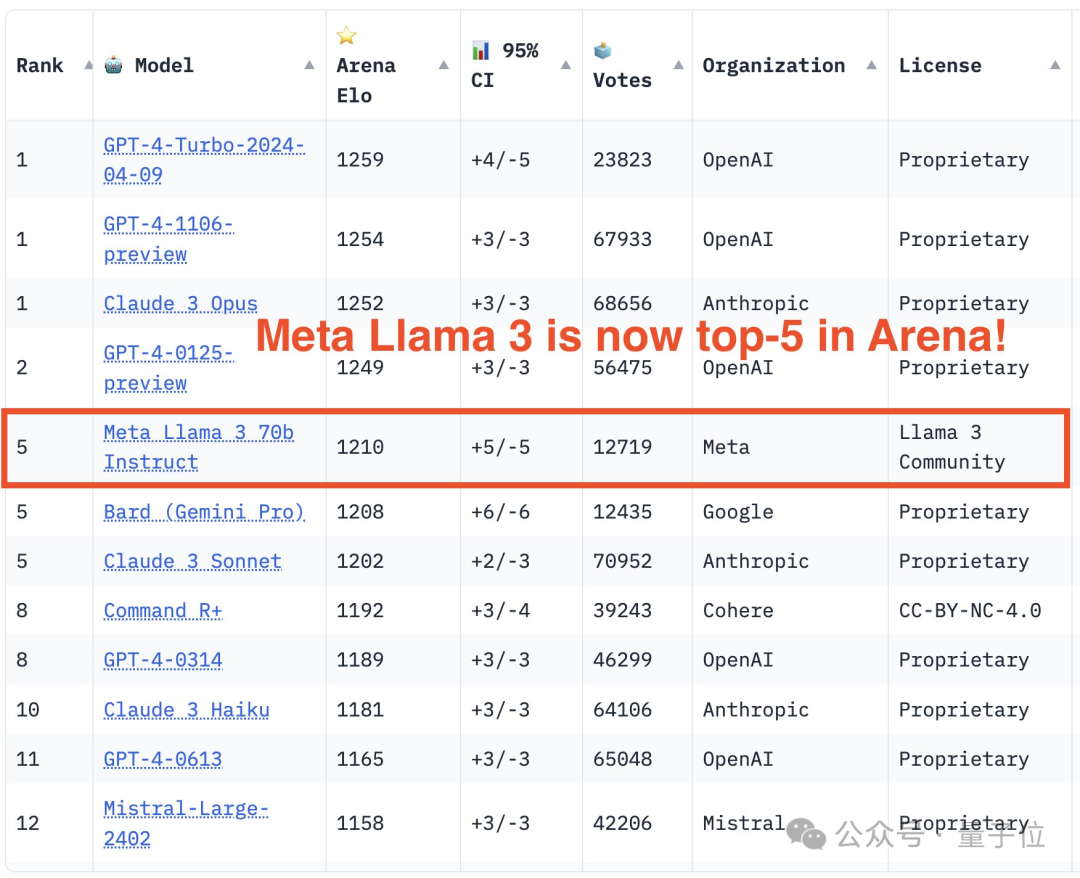
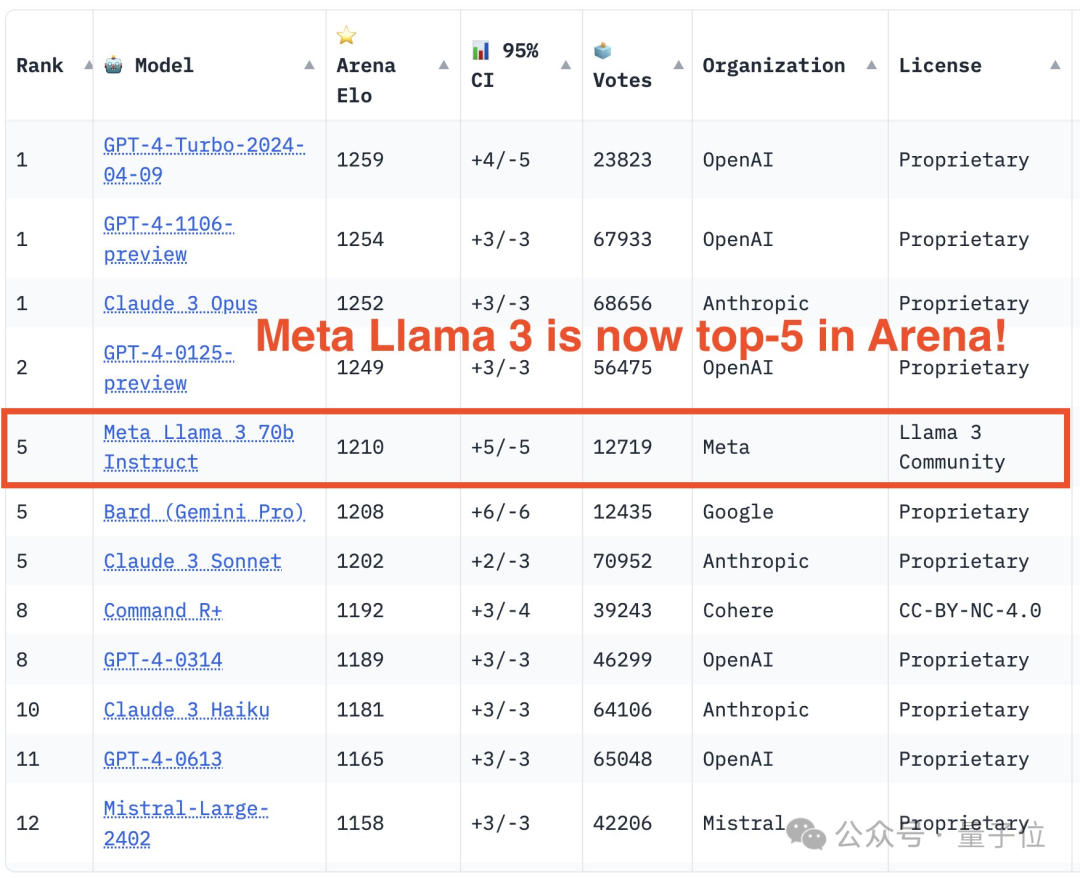
Komuniti penilaian model besar LMSYS mengeluarkan senarai ranking model yang besar, Llama 3 menduduki tempat kelima, dan terikat di tempat pertama dengan GPT-4 dalam kategori Bahasa Inggeris.
 Gambar
Gambar
Berbeza daripada Penanda Aras yang lain, senarai ini berdasarkan model pertempuran satu lawan satu, dan penilai dari seluruh rangkaian membuat cadangan dan skor mereka sendiri.
Akhirnya, Llama 3 menduduki tempat kelima dalam senarai, diikuti oleh tiga versi GPT-4 dan Claude 3 Super Cup Opus yang berbeza.
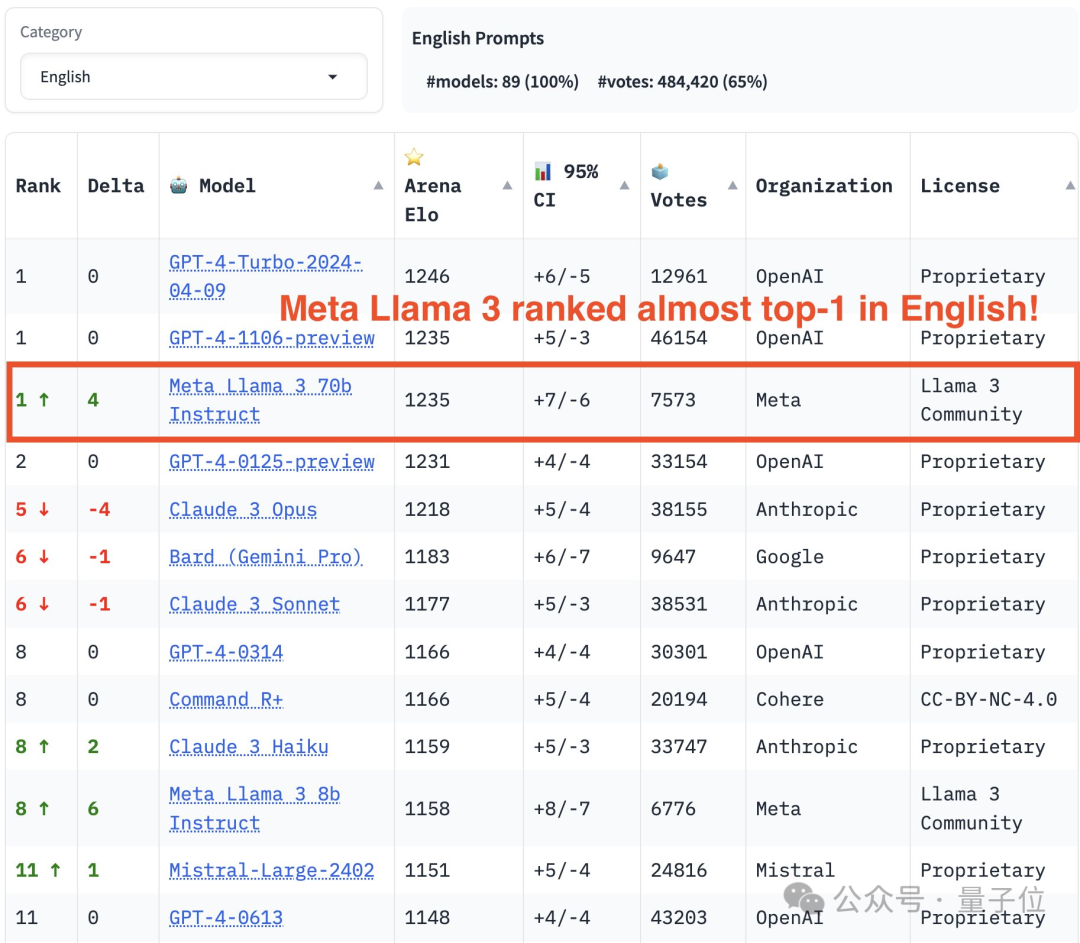
Dalam senarai tunggal Inggeris, Llama 3 memintas Claude dan terikat dengan GPT-4.
LeCun, ketua saintis Meta, sangat gembira dengan keputusan ini dan tweet semula tweet itu dan meninggalkan "Nice".
 Gambar
Gambar
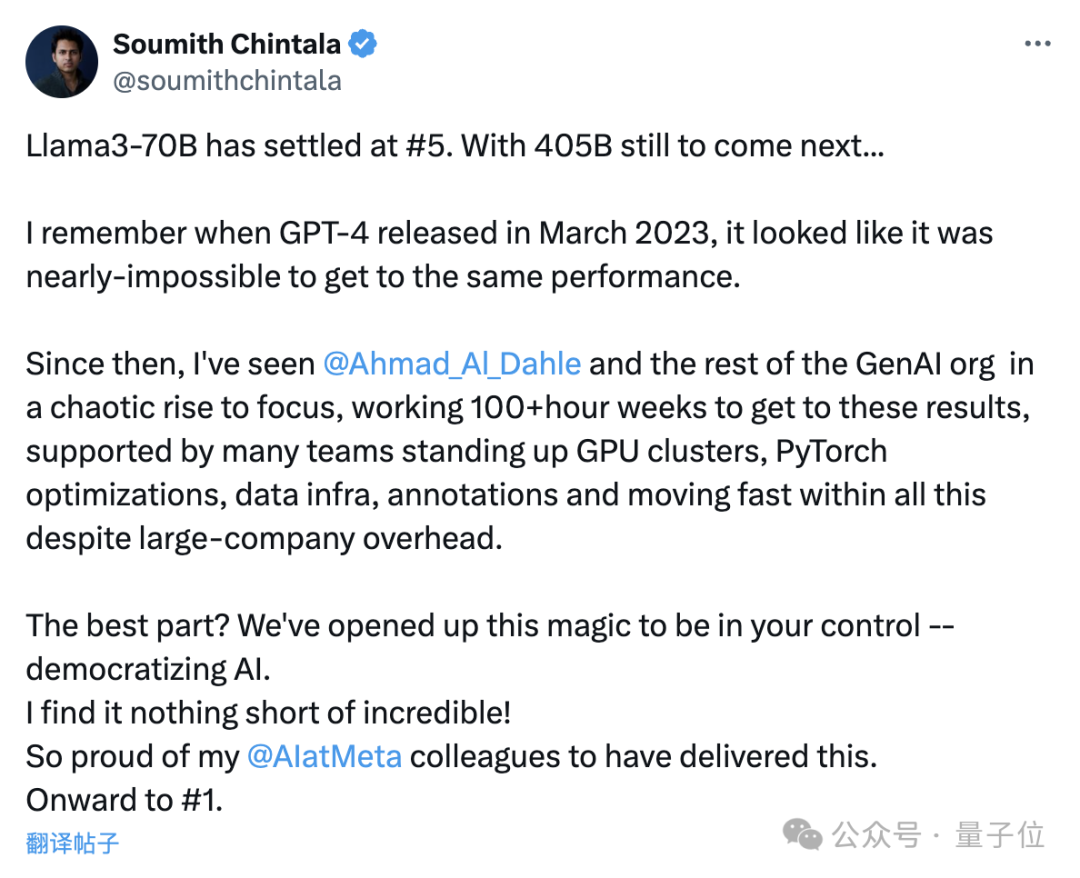
Soumith Chintala, bapa kepada PyTorch, juga teruja menyatakan bahawa keputusan sedemikian adalah luar biasa dan dia berbangga dengan Meta.
Versi 400B Llama 3 masih belum keluar, dan ia memenangi tempat kelima hanya dengan bergantung pada parameter 70B...
Saya masih ingat apabila GPT-4 dikeluarkan pada Mac tahun lepas, hampir mustahil untuk mencapai prestasi yang sama.
…
Pempopularan AI sekarang benar-benar luar biasa, dan saya sangat berbangga dengan rakan sekerja saya di Meta AI kerana mencapai kejayaan sedemikian.
 Gambar
Gambar
Jadi, apakah hasil khusus yang ditunjukkan oleh senarai ini?
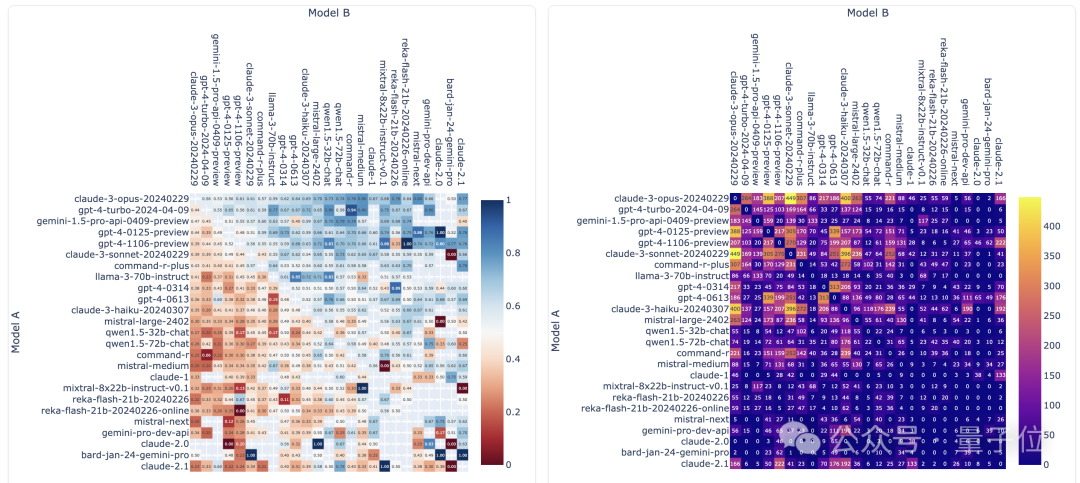
Sehingga senarai terbaharu dikeluarkan, LMSYS telah mengumpul hampir 750,000 keputusan pertempuran solo model besar, melibatkan 89 model.
Antaranya, Llama 3 telah mengambil bahagian sebanyak 12,700 kali, dan GPT-4 mempunyai beberapa versi berbeza, dengan penyertaan paling ramai 68,000 kali.
 Gambar
Gambar
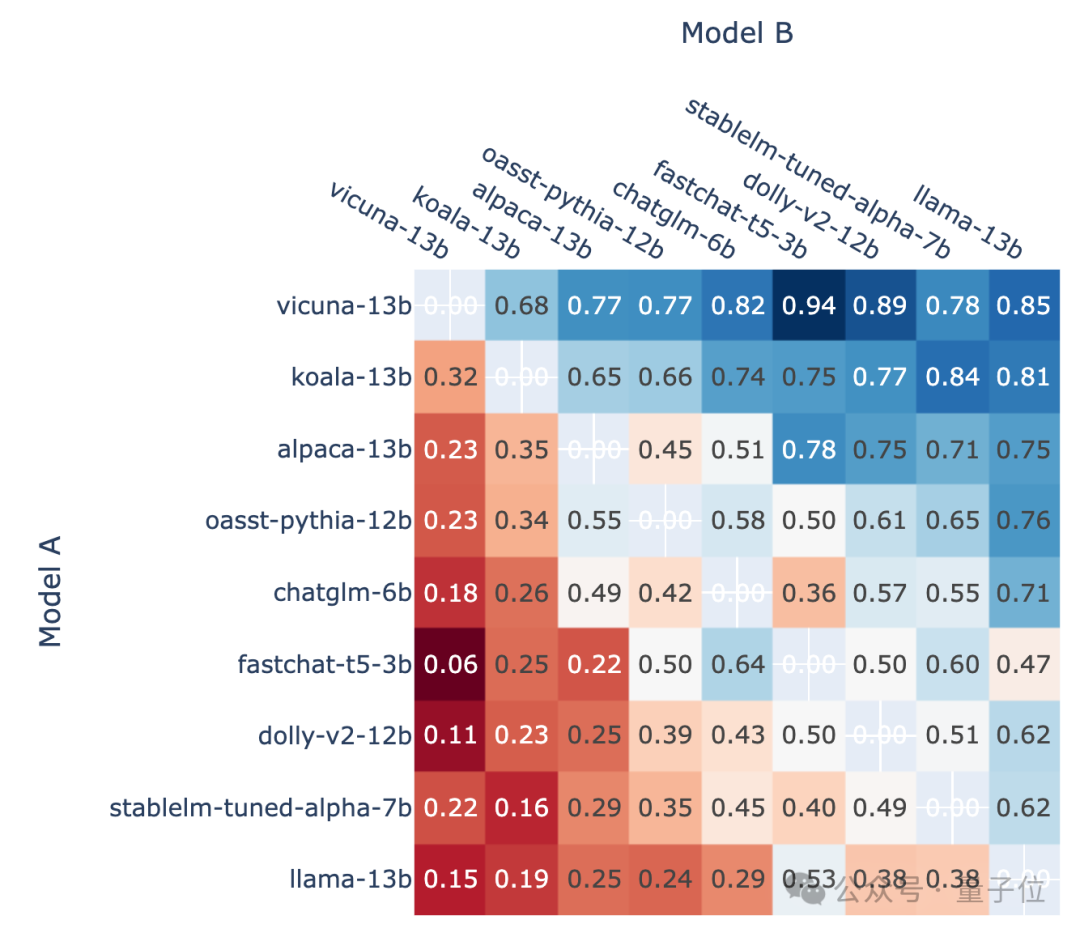
Gambar di bawah menunjukkan bilangan pertandingan dan kadar kemenangan beberapa model popular kedua-dua penunjuk dalam gambar tidak mengira bilangan cabutan.
 Pictures
Pictures
Dari segi senarai, LMSYS dibahagikan kepada senarai umum dan berbilang sub-senarai berada di kedudukan pertama, terikat dengan versi 1106 yang terdahulu, dan Claude 3 Super Large Cup Opus.
Versi lain (0125) GPT-4 menduduki tempat kedua, diikuti rapat oleh Llama 3.
Tetapi apa yang lebih menarik ialah versi 0125 yang lebih baharu tidak berfungsi sebaik versi 1106 yang lebih lama.
 Pictures
Pictures
Dalam senarai tunggal Inggeris, keputusan Llama 3 terikat secara langsung dengan dua GPT-4, malah melepasi versi 0125.
 Pictures
Pictures
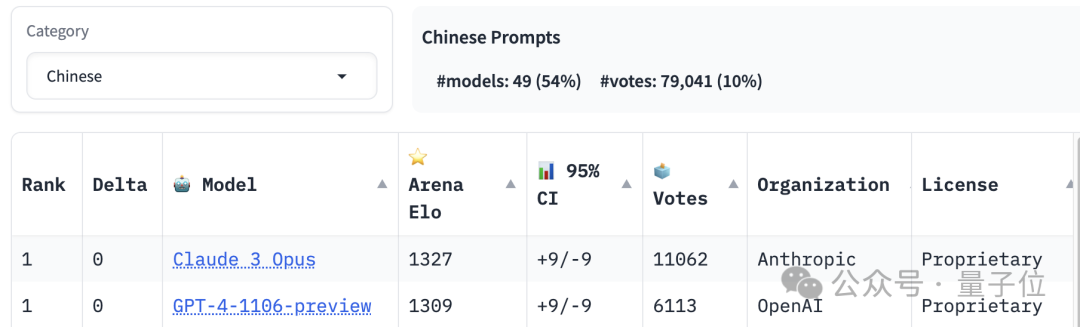
Tempat pertama dalam ranking penguasaan bahasa Cina dikongsi oleh Claude 3 Opus dan GPT-4-1106, manakala Llama 3 telah berada di luar tempat ke-20.
 Pictures
Pictures
Selain kebolehan bahasa, senarai ini juga menetapkan kedudukan untuk teks panjang dan kebolehan pengekodan, dan Llama 3 juga antara yang terbaik.
Namun, apakah "peraturan permainan" khusus LMSYS?
Ini adalah ujian model besar yang semua orang boleh sertai. Soalan dan kriteria penilaian ditentukan oleh peserta sendiri.
Proses "pertandingan" khusus dibahagikan kepada dua mod: pertempuran dan sebelah menyebelah.
 Gambar
Gambar
Dalam mod pertempuran, selepas memasukkan soalan pada antara muka ujian, sistem akan secara rawak memanggil dua model dalam perpustakaan, dan penguji tidak tahu siapa yang dipilih oleh sistem, dan hanya "Model" sahaja dipaparkan dalam antara muka A" dan "Model B".
Selepas model mengeluarkan jawapan, penilai perlu memilih mana yang lebih baik atau seri Sudah tentu, jika prestasi model tidak memenuhi jangkaan, terdapat pilihan yang sepadan.
Hanya selepas pemilihan dibuat, identiti model didedahkan.
Bersebelahan ialah tempat pengguna memilih model yang ditentukan kepada PK Selebihnya proses ujian adalah sama dengan mod pertempuran
Walau bagaimanapun, hanya keputusan undian dalam mod tanpa nama pertempuran akan dikira. dan model mungkin tidak berhati-hati semasa perbualan mendedahkan identiti anda akan membatalkan keputusan. . Data kadar ditukar kepada markah melalui sistem penilaian Elo.
Sistem penilaian Elo ialah kaedah mengira tahap kemahiran relatif pemain, yang direka oleh profesor fizik Amerika Arpad Elo. 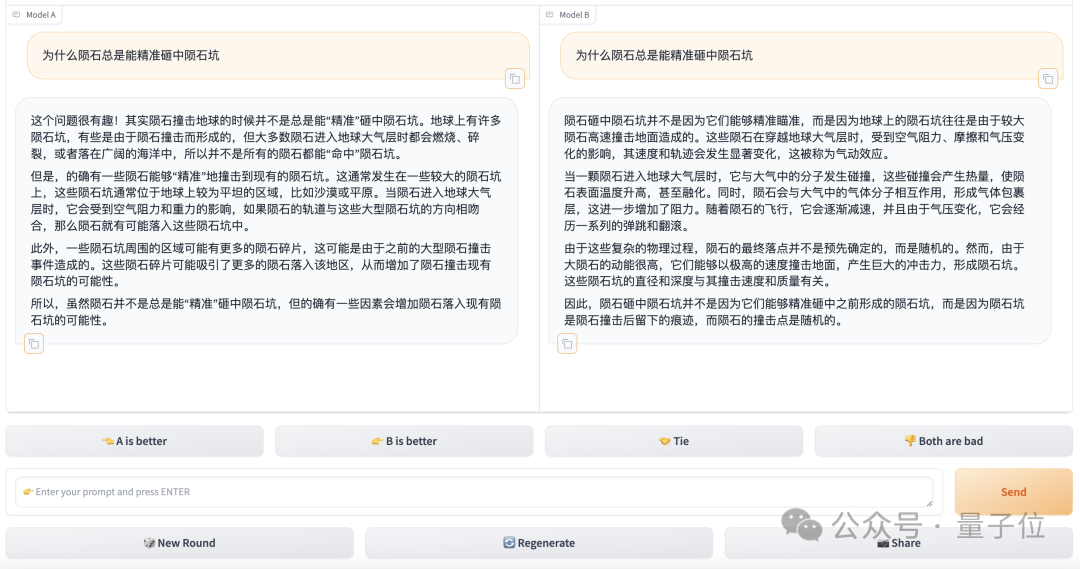 Khusus untuk LMSYS, dalam keadaan awal, rating (R) semua model ditetapkan kepada 1000, dan kemudian jangkaan kadar kemenangan (E) dikira berdasarkan formula sedemikian.
Khusus untuk LMSYS, dalam keadaan awal, rating (R) semua model ditetapkan kepada 1000, dan kemudian jangkaan kadar kemenangan (E) dikira berdasarkan formula sedemikian.
 Semasa ujian diteruskan, markah akan disemak mengikut markah sebenar (S mempunyai tiga nilai1, 0 dan 0.5, sepadan dengan tiga situasi menang, kalah). dan lukisan masing-masing.
Semasa ujian diteruskan, markah akan disemak mengikut markah sebenar (S mempunyai tiga nilai1, 0 dan 0.5, sepadan dengan tiga situasi menang, kalah). dan lukisan masing-masing.
Akhir sekali, selepas semua data yang sah dimasukkan ke dalam pengiraan, skor Elo model diperolehi.
Namun, semasa operasi sebenar, pasukan LMSYS mendapati bahawa kestabilan algoritma ini tidak mencukupi, jadi mereka menggunakan kaedah statistik untuk membetulkannya. 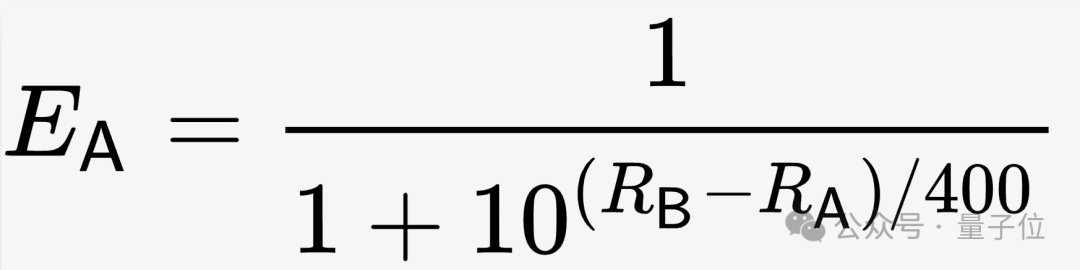 Mereka menggunakan kaedah Bootstrap untuk pensampelan berulang, memperoleh hasil yang lebih stabil dan menganggarkan selang keyakinan.
Mereka menggunakan kaedah Bootstrap untuk pensampelan berulang, memperoleh hasil yang lebih stabil dan menganggarkan selang keyakinan.
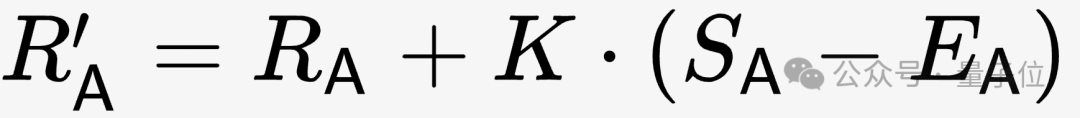 Llama 3 sudah boleh dijalankan pada platform inferens model besar Groq (bukan Musk’s Grok).
Llama 3 sudah boleh dijalankan pada platform inferens model besar Groq (bukan Musk’s Grok).
Sorotan terbesar platform ini ialah "kelajuannya". Sebelum ini, model Mixtral digunakan untuk mencapai kelajuan hampir 500 token sesaat.
Llama 3 juga sangat pantas apabila berjalan Ia sebenarnya diukur bahawa versi 70B boleh menjalankan kira-kira 300 token sesaat, dan versi 8B adalah hampir 800.
Gambar
[2]https://chat.lmsys.org/?leaderboard [3]https://twitter.com/lmsysorg/status/1782483699449332144
Atas ialah kandungan terperinci 750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Formula pilih atur dan gabungan yang biasa digunakan
Formula pilih atur dan gabungan yang biasa digunakan
 Bagaimana untuk membandingkan kandungan fail dua versi dalam git
Bagaimana untuk membandingkan kandungan fail dua versi dalam git
 Bagaimana untuk menyelesaikan ralat "NTLDR tiada" pada komputer anda
Bagaimana untuk menyelesaikan ralat "NTLDR tiada" pada komputer anda
 Windows tidak boleh mengkonfigurasi sambungan wayarles ini
Windows tidak boleh mengkonfigurasi sambungan wayarles ini
 Mengapa Himalaya tidak boleh menyambung ke Internet?
Mengapa Himalaya tidak boleh menyambung ke Internet?
 Bagaimana untuk menyediakan muat semula automatik halaman web
Bagaimana untuk menyediakan muat semula automatik halaman web
 Perintah nama fail ubah suai Linux
Perintah nama fail ubah suai Linux
 pencetus_ralat
pencetus_ralat








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



