



Lajur AIxiv ialah lajur di mana kandungan akademik dan teknikal diterbitkan di laman web ini. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Dari GPT-4 128K dan Claude 200K terkemuka antarabangsa kepada Sembang Kimi "Red Fried Chicken" domestik yang menyokong lebih daripada 2 juta perkataan teks, model bahasa besar (LLM) sentiasa digulung dalam konteks yang panjang teknologi. Apabila minda paling bijak di dunia sedang mengusahakan sesuatu, kepentingan dan kesukaran perkara itu jelas dengan sendirinya.
Konteks yang sangat panjang boleh mengembangkan nilai produktiviti model besar. Dengan populariti AI, pengguna tidak lagi berpuas hati dengan bermain dengan model besar dan melakukan beberapa permainan asah otak Pengguna mula ingin menggunakan model besar untuk benar-benar meningkatkan produktiviti. Lagipun, PPT yang dahulunya mengambil masa seminggu untuk dibuat kini boleh dijana dalam beberapa minit dengan hanya memberi model besar rentetan kata-kata pantas dan beberapa dokumen rujukan Siapa yang tidak menyukainya sebagai orang yang bekerja?
Beberapa kaedah pemodelan jujukan cekap baharu telah muncul baru-baru ini, seperti Lightning Attention (TransNormerLLM), State Space Modeling (Mamba), Linear RNN (RWKV, HGRN, Griffin), dll., yang telah menjadi hala tuju penyelidikan yang hangat. Penyelidik tidak sabar-sabar untuk mengubah seni bina Transformer berusia 7 tahun yang sudah matang untuk mendapatkan seni bina baharu dengan prestasi yang setanding tetapi hanya kerumitan linear. Pendekatan jenis ini memfokuskan pada reka bentuk seni bina model dan menyediakan pelaksanaan mesra perkakasan berdasarkan CUDA atau Triton, membolehkan ia dikira dengan cekap dalam GPU kad tunggal seperti FlashAttention.
Pada masa yang sama, seorang lagi pengawal latihan urutan panjang juga telah menggunakan strategi berbeza: selari jujukan semakin mendapat perhatian. Dengan membahagikan jujukan panjang kepada berbilang jujukan pendek yang dibahagikan sama rata dalam dimensi jujukan, dan mengedarkan jujukan pendek kepada kad GPU yang berbeza untuk latihan selari, dan ditambah dengan komunikasi antara kad, kesan latihan selari jujukan dicapai. Daripada keselarian jujukan Colossal-AI yang terawal, kepada keselarian jujukan Megatron, kepada DeepSpeed Ulysses, dan baru-baru ini Ring Attention, para penyelidik terus mereka bentuk mekanisme komunikasi yang lebih elegan dan cekap untuk meningkatkan kecekapan latihan keselarian jujukan. Sudah tentu, kaedah yang diketahui ini semuanya direka untuk mekanisme perhatian tradisional, yang kami panggil Softmax Attention dalam artikel ini. Kaedah ini telah dianalisis oleh pelbagai pakar, jadi artikel ini tidak akan membincangkannya secara terperinci.

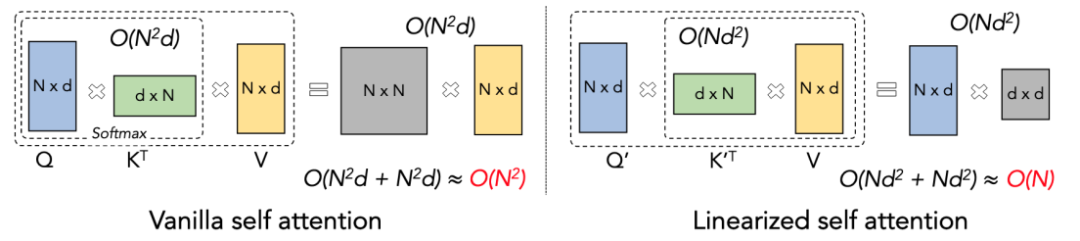
Untuk lebih memahami idea LASP, mari kita semak semula formula pengiraan tradisional Perhatian Softmax: O=softmax((QK^T)⊙M)V, di mana Q, K, V, M, dan O ialah matriks Pertanyaan, Kunci, Nilai, Topeng dan Output, M di sini ialah matriks tiga segi tiga semua-1 yang lebih rendah dalam tugasan sehala (seperti GPT), dan boleh diabaikan dalam tugasan dua hala (seperti BERT), iaitu , tiada matriks Topeng untuk tugasan dua hala. Kami akan membahagikan LASP kepada empat perkara untuk penjelasan di bawah:
Prinsip Perhatian Linear
Perhatian Linear boleh dianggap sebagai varian Softmax Attention. Perhatian Linear mengalih keluar pengendali Softmax yang mahal secara pengiraan, dan formula pengiraan Perhatian boleh ditulis sebagai bentuk ringkas O=((QK^T)⊙M) V. Walau bagaimanapun, disebabkan kewujudan matriks Mask M dalam tugasan sehala, borang ini masih hanya boleh melakukan pengiraan pendaraban kiri (iaitu mengira QK^T dahulu), jadi kerumitan linear O (N) tidak boleh diperolehi. . Tetapi untuk tugas dua hala, kerana tiada matriks Topeng, formula pengiraan boleh dipermudahkan lagi kepada O=(QK^T) V. Perkara yang bijak tentang Perhatian Linear ialah dengan hanya menggunakan hukum bersekutu bagi pendaraban matriks, formula pengiraannya boleh diubah lagi menjadi: O=Q (K^T V) Bentuk pengiraan ini dipanggil pendaraban betul Perhatian Menggoda Kerumitan O (N) boleh dicapai dalam tugas dua hala ini!
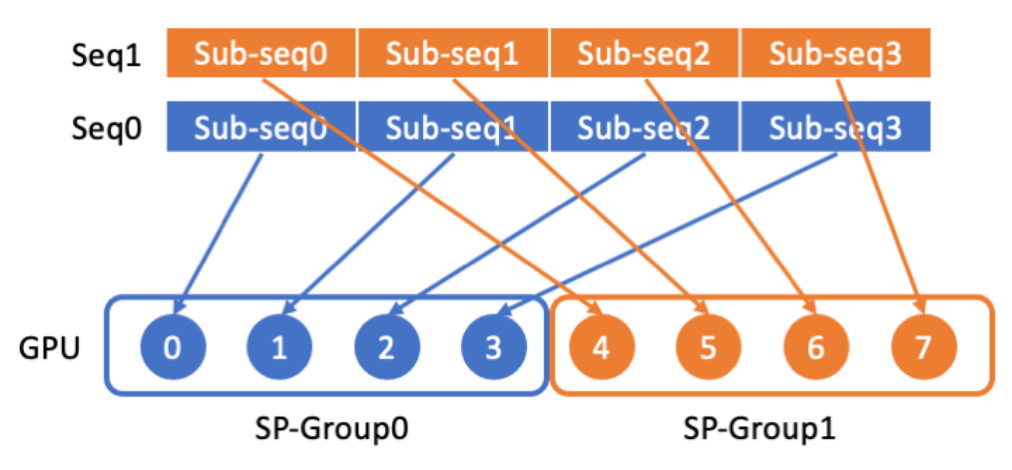
LASP pengedaran data
LASP mula-mula membahagikan data jujukan panjang kepada berbilang jujukan yang dibahagikan sama rata daripada dimensi jujukan, dan kemudian mengedarkan jujukan kepada semua GPU dalam jujukan kumpulan komunikasi selari mempunyai, supaya setiap kumpulan komunikasi selari mempunyai, supaya setiap kumpulan komunikasi selari urutan untuk pengiraan selari bagi jujukan berikutnya. . Dikira daripada jujukan Xi adalah Qi, Ki dan Vi yang dibahagikan mengikut dimensi jujukan Setiap indeks i sepadan dengan Bongkah dan Peranti (iaitu, GPU). Disebabkan kewujudan matriks Mask, penulis LASP bijak membezakan Qi, Ki, dan Vi yang sepadan dengan setiap Chunk kepada dua jenis, iaitu: Intra-Chunk dan Inter-Chunk. Antaranya, Intra-Chunk ialah Chunk pada pepenjuru selepas matriks Topeng dibahagikan kepada blok Ia boleh dianggap bahawa matriks Topeng masih wujud, dan pendaraban kiri masih perlu digunakan; garis luar pepenjuru matriks Topeng, yang boleh dianggap tidak Dengan kewujudan matriks Topeng, pendaraban betul boleh digunakan dengan jelas, apabila lebih banyak Potongan dibahagikan, bahagian Ketulan pada pepenjuru akan menjadi lebih kecil, dan bahagian Ketulan di luar pepenjuru akan menjadi lebih besar. Antaranya, untuk pengiraan Inter-Chunk darab betul, semasa pengiraan hadapan, setiap peranti perlu menggunakan komunikasi titik ke titik untuk Menerima KV peranti sebelumnya dan menghantar KV dikemas kini sendiri ke peranti seterusnya. Apabila mengira secara terbalik, ia adalah sebaliknya, kecuali objek Hantar dan Terima menjadi dKV kecerunan KV. Proses pengiraan ke hadapan ditunjukkan dalam rajah di bawah:
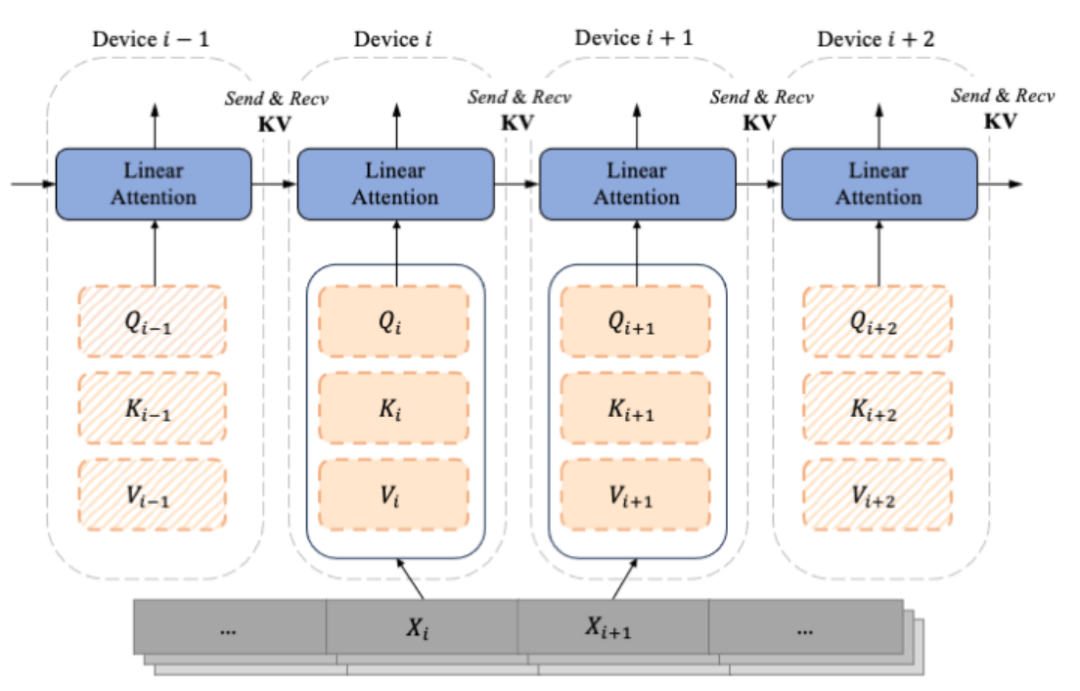
Pelaksanaan kod LASP
Untuk meningkatkan kecekapan pengiraan LASP pada GPU, penulis melakukan Pelaburan Kernel pada pengiraan Intra-Chunk dan Inter -Chunk masing-masing, dan Pengiraan kemas kini KV dan dKV juga disepadukan ke dalam pengiraan Intra-Chunk dan Inter-Chunk. Selain itu, untuk mengelakkan pengiraan semula KV pengaktifan semasa perambatan belakang, pengarang memilih untuk menyimpannya dalam HBM GPU sejurus selepas pengiraan perambatan hadapan. Semasa perambatan balik berikutnya, LASP mengakses KV secara langsung untuk digunakan. Perlu diingatkan bahawa saiz KV yang disimpan dalam HBM ialah d x d dan sama sekali tidak dipengaruhi oleh panjang jujukan N. Apabila panjang jujukan input N adalah besar, jejak memori KV menjadi tidak ketara. Di dalam satu GPU, pengarang melaksanakan Lightning Attention yang dilaksanakan oleh Triton untuk mengurangkan overhed IO antara HBM dan SRAM, dengan itu mempercepatkan pengiraan Linear Attention satu kad.
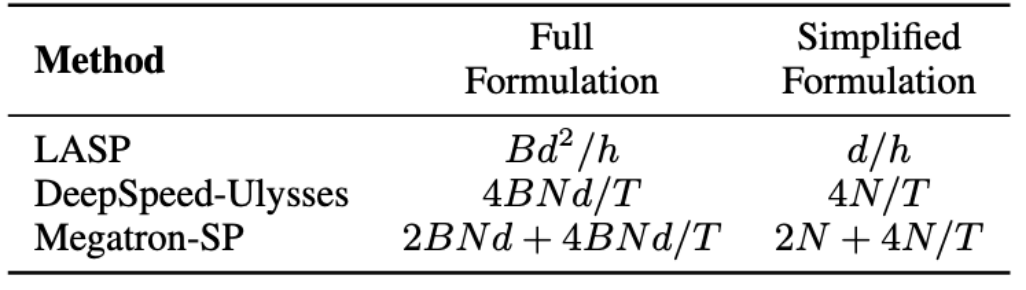
Analisis lalu lintas
Dalam algoritma LASP, perlu diperhatikan bahawa perambatan ke hadapan memerlukan komunikasi pengaktifan KV pada setiap lapisan modul Perhatian Linear. Trafik ialah Bd^2/j, dengan B ialah saiz kelompok dan h ialah bilangan kepala. Sebaliknya, Megatron-SP menggunakan operasi All-Gather selepas dua lapisan Norma Lapisan dalam setiap lapisan Transformer, dan operasi Reduce-Scatter selepas lapisan Attention dan FFN, yang menyebabkan komunikasinya Kuantiti ialah 2BNd + 4BNd/T, di mana T ialah dimensi selari jujukan. DeepSpeed-Ulysses menggunakan operasi komunikasi set All-to-All untuk memproses input Q, K, V dan output O setiap lapisan modul Attention, menghasilkan volum komunikasi 4BNd/T. Perbandingan volum komunikasi antara ketiga-tiga ditunjukkan dalam jadual di bawah. dengan d/j ialah dimensi kepala, biasanya ditetapkan kepada 128. Dalam aplikasi praktikal, LASP boleh mencapai volum komunikasi teori yang paling rendah apabila N/T>=32. Tambahan pula, volum komunikasi LASP tidak dipengaruhi oleh panjang jujukan N atau panjang jujukan C, yang merupakan kelebihan besar untuk pengkomputeran selari jujukan yang sangat panjang merentas kelompok GPU yang besar.
Data-Sequence Hybrid Parallel
Data parallelism (iaitu pembahagian data peringkat kelompok) telah menjadi operasi rutin untuk latihan teragih Ia telah berkembang berdasarkan susunan data yang asal kepada DDP (P). mencapai lebih banyak keselarian data yang dihiris penjimatan memori, daripada siri DeepSpeed ZeRO yang asal kepada FSDP yang disokong secara rasmi oleh PyTorch, keselarian data yang dihiris telah menjadi cukup matang dan digunakan oleh semakin ramai pengguna. Sebagai kaedah pembahagian data peringkat jujukan, LASP serasi dengan pelbagai kaedah selari data termasuk PyTorch DDP, Zero-1/2/3 dan FSDP. Ini sudah pasti berita baik untuk pengguna LASP.
Eksperimen Ketepatan
Hasil eksperimen pada TransNormerLLM (TNL) dan Linear Transformer menunjukkan bahawa LASP, sebagai kaedah pengoptimuman sistem, boleh digabungkan dengan pelbagai bahagian belakang DDP dan mencapai prestasi setanding dengan Baseline.
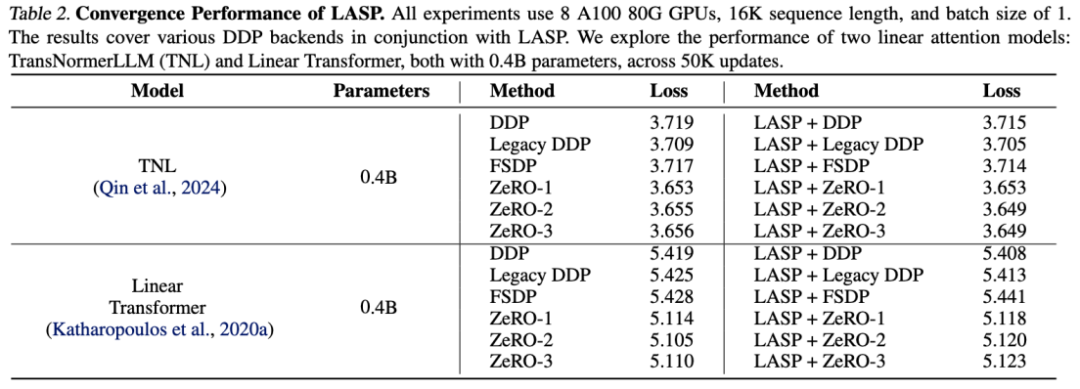
Eksperimen Kebolehskalaan
Terima kasih kepada reka bentuk mekanisme komunikasi yang cekap, LASP boleh dikembangkan dengan mudah kepada ratusan kad GPU dan mengekalkan kebolehskalaan yang baik.
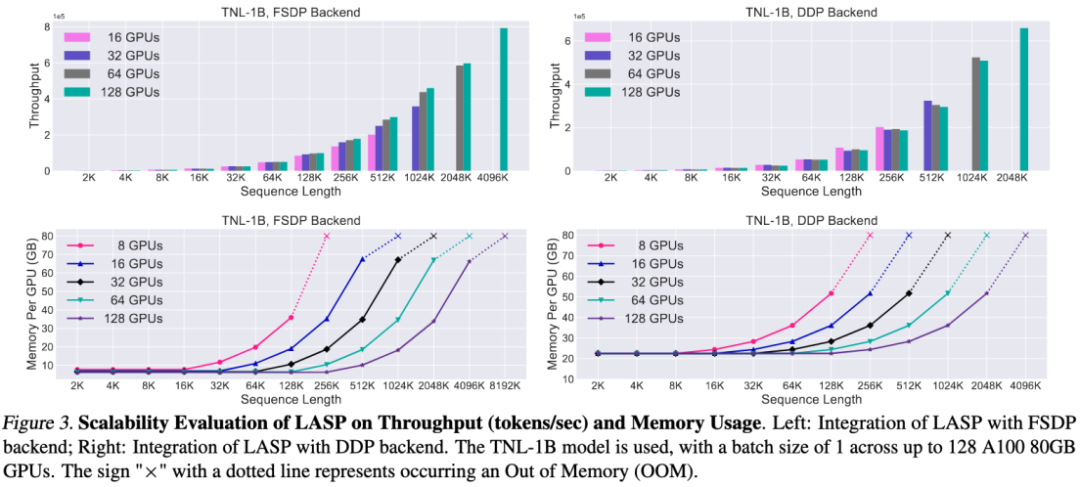
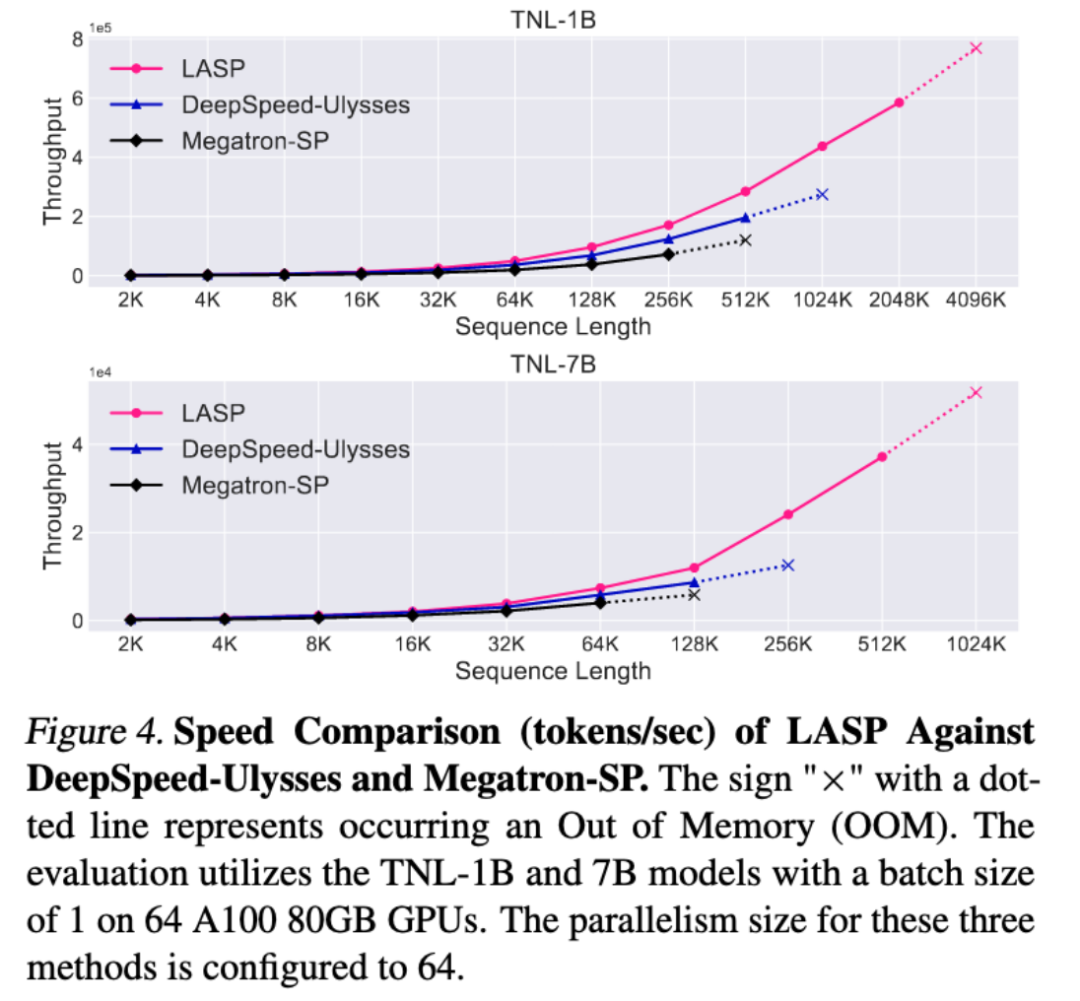
Eksperimen perbandingan kelajuan
Berbanding dengan kaedah selari jujukan matang Megatron-SP dan DeepSpeed-Ulysses, panjang jujukan terpanjang LASP yang boleh dilatih ialah 8 kali ganda Megatron-SP dan 4 kali ganda daripada DeepSpeed Ulysses masing-masing 136% dan 38% lebih laju.
Kesimpulan
Untuk memudahkan percubaan semua orang, penulis telah menyediakan pelaksanaan kod LASP yang sedia untuk digunakan Tidak perlu memuat turun set data dan model Anda hanya memerlukan PyTorch untuk mengalami LASP yang sangat panjang dan keselarian urutan yang sangat pantas dalam beberapa minit.
Portal kod: https://github.com/OpenNLPLab/LASP
Atas ialah kandungan terperinci Jujukan yang sangat panjang, sangat pantas: Keselarian jujukan LASP untuk generasi baharu model bahasa besar yang cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bina pelayan git anda sendiri
Bina pelayan git anda sendiri
 Perbezaan antara git dan svn
Perbezaan antara git dan svn
 git undo menyerahkan komit
git undo menyerahkan komit
 Bagaimana untuk membatalkan ralat komit git
Bagaimana untuk membatalkan ralat komit git
 Bagaimana untuk membandingkan kandungan fail dua versi dalam git
Bagaimana untuk membandingkan kandungan fail dua versi dalam git
 permainan ipad tiada bunyi
permainan ipad tiada bunyi
 Pengenalan kepada carriage return dan aksara suapan baris dalam java
Pengenalan kepada carriage return dan aksara suapan baris dalam java
 apa itu xfce
apa itu xfce








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



