


Yuanxiang mengeluarkan model besar XVERSE-MoE-A4.2B, yang mengguna pakai seni bina model Campuran Pakar yang paling canggih dalam industri (Campuran Pakar), mengaktifkan parameter 4.2B, dan kesannya setanding dengan model 13B. Model ini adalah sumber terbuka sepenuhnya dan percuma tanpa syarat untuk kegunaan komersil, membenarkan sebilangan besar perusahaan kecil dan sederhana, penyelidik dan pembangun menggunakannya atas permintaan dalam "baldi keluarga" berprestasi tinggi Yuanxiang, mempromosikan penggunaan kos rendah .

Pembangunan model besar arus perdana seperti GPT3, Llama dan XVERSE mengikut Undang-undang Penskalaan Semasa proses latihan model dan inferens, semua parameter diaktifkan semasa pengiraan ke hadapan dan belakang tunggal pengaktifan (padat diaktifkan). Apabila skala model meningkat, kos kuasa pengkomputeran akan meningkat dengan mendadak.
Memandangkan semakin ramai penyelidik percaya bahawa model KPM yang jarang diaktifkan boleh menjadi kaedah yang lebih berkesan tanpa meningkatkan kos latihan dan inferens pengiraan dengan ketara apabila meningkatkan saiz model. Oleh kerana teknologi ini agak baru, kebanyakan model sumber terbuka atau penyelidikan akademik di China masih belum popular. Dalam penyelidikan kendiri elemen, menggunakan korpus yang sama untuk melatih 2.7 kuadrilion token, XVERSE-MoE-A4.2B mempunyai jumlah parameter pengaktifan sebenar 4.2B, dan prestasi "melompat" melebihi XVERSE-13B-2, hanya jumlah pengiraan dikurangkan sebanyak 50% masa latihan. Berbanding dengan pelbagai penanda aras sumber terbuka Llama, model ini dengan ketara mengatasi Llama2-13B dan hampir dengan Llama1-65B (gambar di bawah).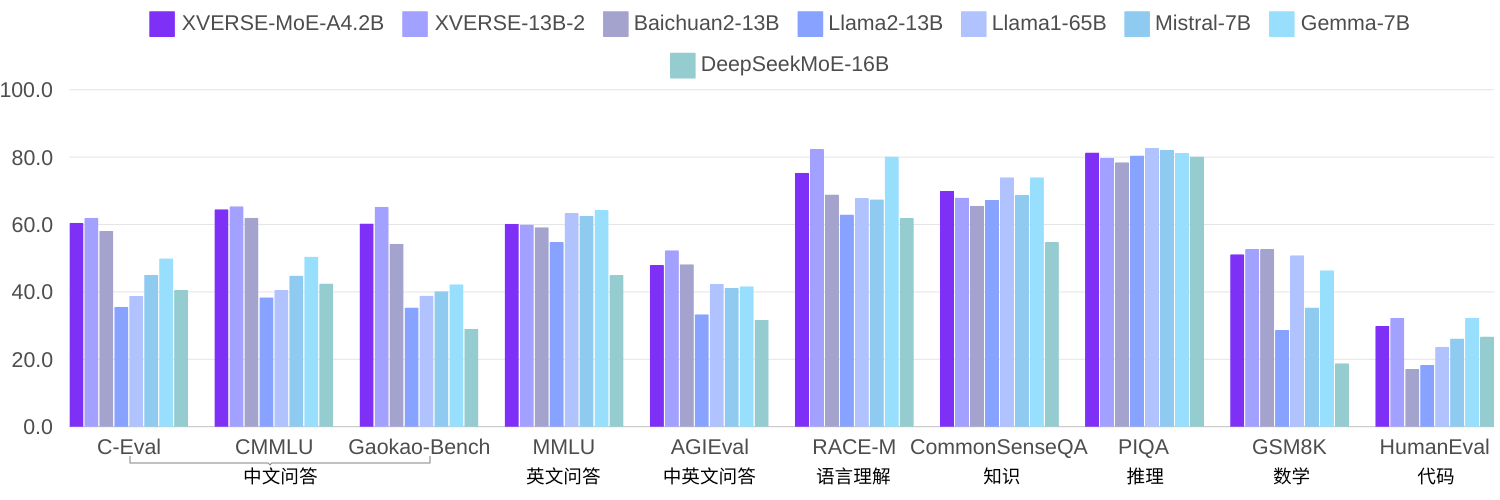
KPMPenyelidikan kendiri dan inovasi teknologi
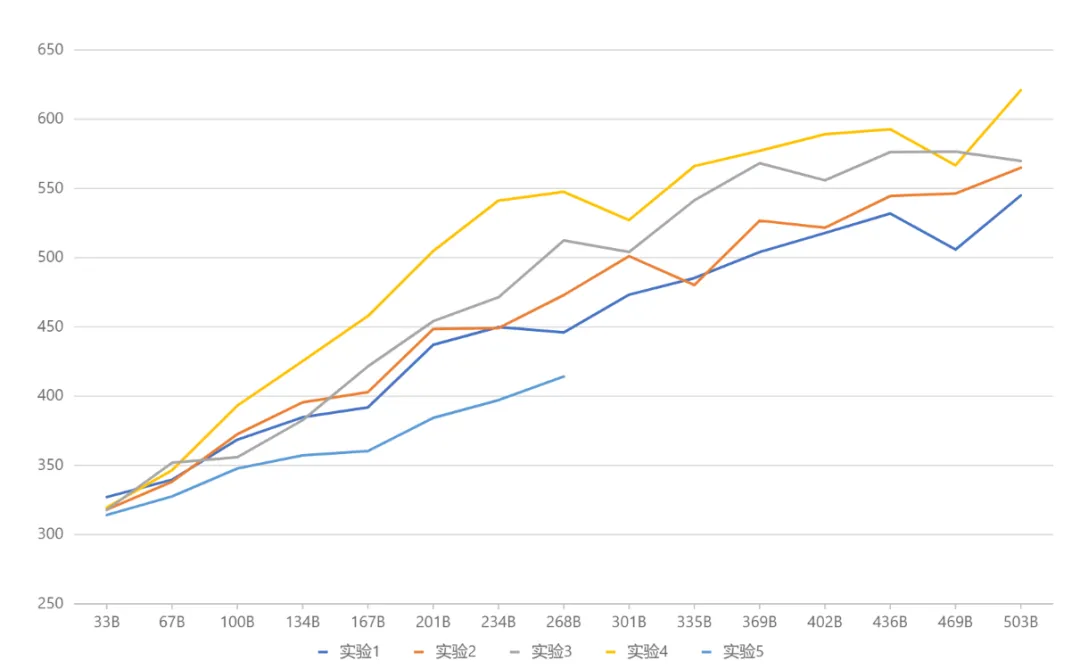
Kementerian Pendidikan (KPM) pada masa ini merupakan rangka kerja model yang paling canggih dalam industri Disebabkan teknologi yang lebih baharu, model sumber terbuka domestik atau penyelidikan akademik tidak namun menjadi popular. MetaObject membangunkan secara bebas rangka kerja latihan dan inferens KPM yang cekap, dan berinovasi dalam tiga arah: Dari segi prestasi, satu set operator gabungan yang cekap telah dibangunkan berdasarkan penghalaan pakar yang unik dan logik pengiraan berat dalam seni bina KPM, yang meningkatkan pengkomputeran dengan ketara. Kecekapan; Mensasarkan cabaran penggunaan memori yang tinggi dan volum komunikasi yang besar dalam model KPM, operasi pengiraan yang bertindih, komunikasi dan pemunggahan memori direka untuk meningkatkan daya pemprosesan keseluruhan secara berkesan. Dari segi seni bina, tidak seperti MoE tradisional (seperti Mixtral 8x7B), yang menyamakan saiz setiap pakar dengan FFN standard, Yuanxiang menggunakan reka bentuk pakar yang lebih halus, dan saiz setiap pakar hanyalah satu perempat daripada FFN standard, yang meningkatkan fleksibiliti dan prestasi Model pakar juga dibahagikan kepada dua kategori: Pakar Kongsi dan Pakar Bukan Kongsi. Pakar kongsi kekal aktif semasa pengiraan, manakala pakar bukan kongsi diaktifkan secara terpilih mengikut keperluan. Reka bentuk ini kondusif untuk memampatkan pengetahuan am ke dalam parameter pakar yang dikongsi dan mengurangkan lebihan pengetahuan dalam kalangan parameter pakar yang tidak dikongsi. Dari segi latihan, diilhamkan oleh Switch Transformers, ST-MoE dan DeepSeekMoE, Yuanxiang memperkenalkan istilah kehilangan pengimbangan beban untuk mengimbangi beban dengan lebih baik dalam kalangan pakar istilah z-loss penghala digunakan untuk memastikan latihan yang cekap dan stabil. Pemilihan seni bina diperoleh melalui satu siri eksperimen perbandingan (gambar di bawah Dalam Eksperimen 3 dan Eksperimen 2, jumlah parameter dan amaun parameter pengaktifan adalah sama, tetapi reka bentuk pakar berbutir halus yang terdahulu membawa prestasi yang lebih tinggi). . Atas dasar ini, Eksperimen 4 membahagikan lagi pakar kepada dua jenis: dikongsi dan tidak dikongsi, yang meningkatkan kesannya dengan ketara. Eksperimen 5 meneroka kaedah memperkenalkan pakar kongsi apabila saiz pakar adalah sama dengan FFN standard, tetapi kesannya tidak sesuai.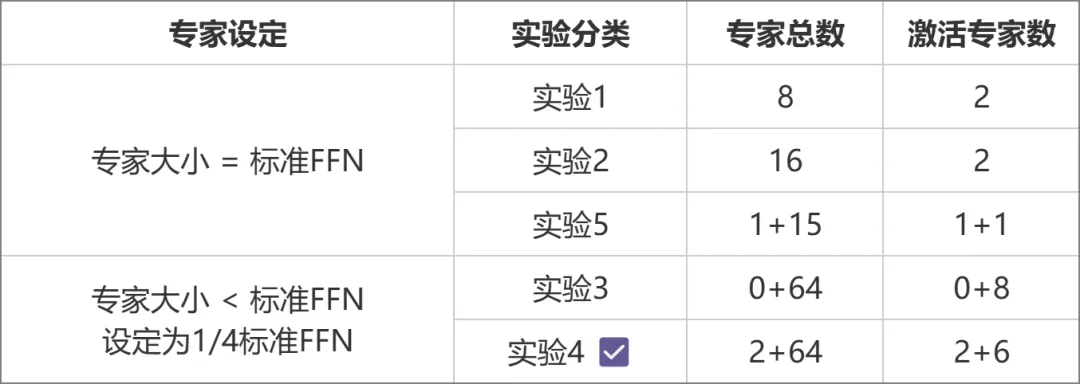
Atas ialah kandungan terperinci Model besar MoE pertama Yuanxiang ialah sumber terbuka: parameter pengaktifan 4.2B, kesannya setanding dengan model 13B. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menukar devc++ kepada bahasa Cina
Bagaimana untuk menukar devc++ kepada bahasa Cina
 Penggunaan lain dalam struktur gelung Python
Penggunaan lain dalam struktur gelung Python
 Perbezaan antara berlabuh dan bertujuan
Perbezaan antara berlabuh dan bertujuan
 penggunaan fungsi isnumber
penggunaan fungsi isnumber
 Apakah kelemahan tomcat biasa?
Apakah kelemahan tomcat biasa?
 penyelesaian di luar julat
penyelesaian di luar julat
 Cara memadankan nombor dalam ungkapan biasa
Cara memadankan nombor dalam ungkapan biasa
 Apakah perdagangan mata wang digital
Apakah perdagangan mata wang digital








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



