


JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk.

Dan ujian itu tidak dilakukan pada TPU dengan prestasi JAX yang terbaik.

Walaupun Pytorch masih lebih popular daripada Tensorflow di kalangan pembangun sekarang.
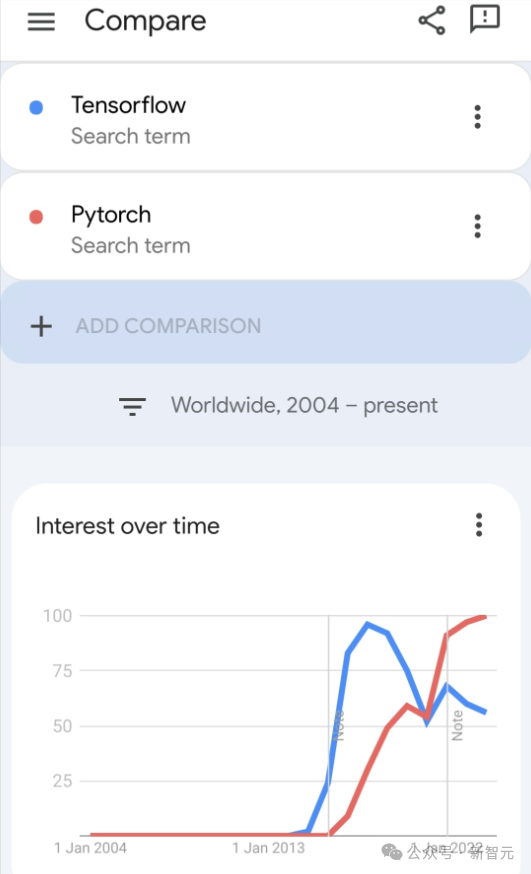
Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX.
Baru-baru ini, pasukan Keras menjalankan penanda aras untuk tiga bahagian belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras 2 dengan TensorFlow.
Pertama, mereka memilih satu set visi komputer arus perdana dan model pemprosesan bahasa semula jadi untuk tugasan kecerdasan buatan generatif dan bukan generatif:

Untuk versi Keras model, ia menggunakan KerasLPCV Build dan menggunakan KerasLPCV. terhadap pelaksanaan yang sedia ada. Untuk versi PyTorch asli, kami memilih pilihan paling popular di Internet:
- BERT, Gemma, Mistral dari HuggingFace Transformers
- StableDiffusion dari
Diffuser HuggingFace- SegmenAnything from Meta
Mereka memanggil set model ini "Native PyTorch" untuk membezakannya daripada versi Keras 3 yang menggunakan bahagian belakang PyTorch.Mereka menggunakan data sintetik untuk semua penanda aras dan menggunakan ketepatan bfloat16 dalam semua latihan dan inferens LLM, sambil menggunakan LoRA (penalaan halus) dalam semua latihan LLM.
Menurut cadangan pasukan PyTorch, mereka menggunakan torch.compile(model, mode="reduce-overhead") dalam pelaksanaan PyTorch asli (kecuali latihan Gemma dan Mistral kerana ketidakserasian).
Untuk mengukur prestasi luar biasa, mereka menggunakan API peringkat tinggi (seperti Jurulatih HuggingFace(), gelung latihan PyTorch standard dan model.fit() Keras) dengan konfigurasi sesedikit mungkin.
Konfigurasi Perkakasan
Semua ujian penanda aras telah dijalankan menggunakan Enjin Pengiraan Awan Google, dikonfigurasikan sebagai: GPU NVIDIA A100 dengan memori video 40GB, 12 CPU maya dan memori hos 85GB.Keputusan Penanda Aras
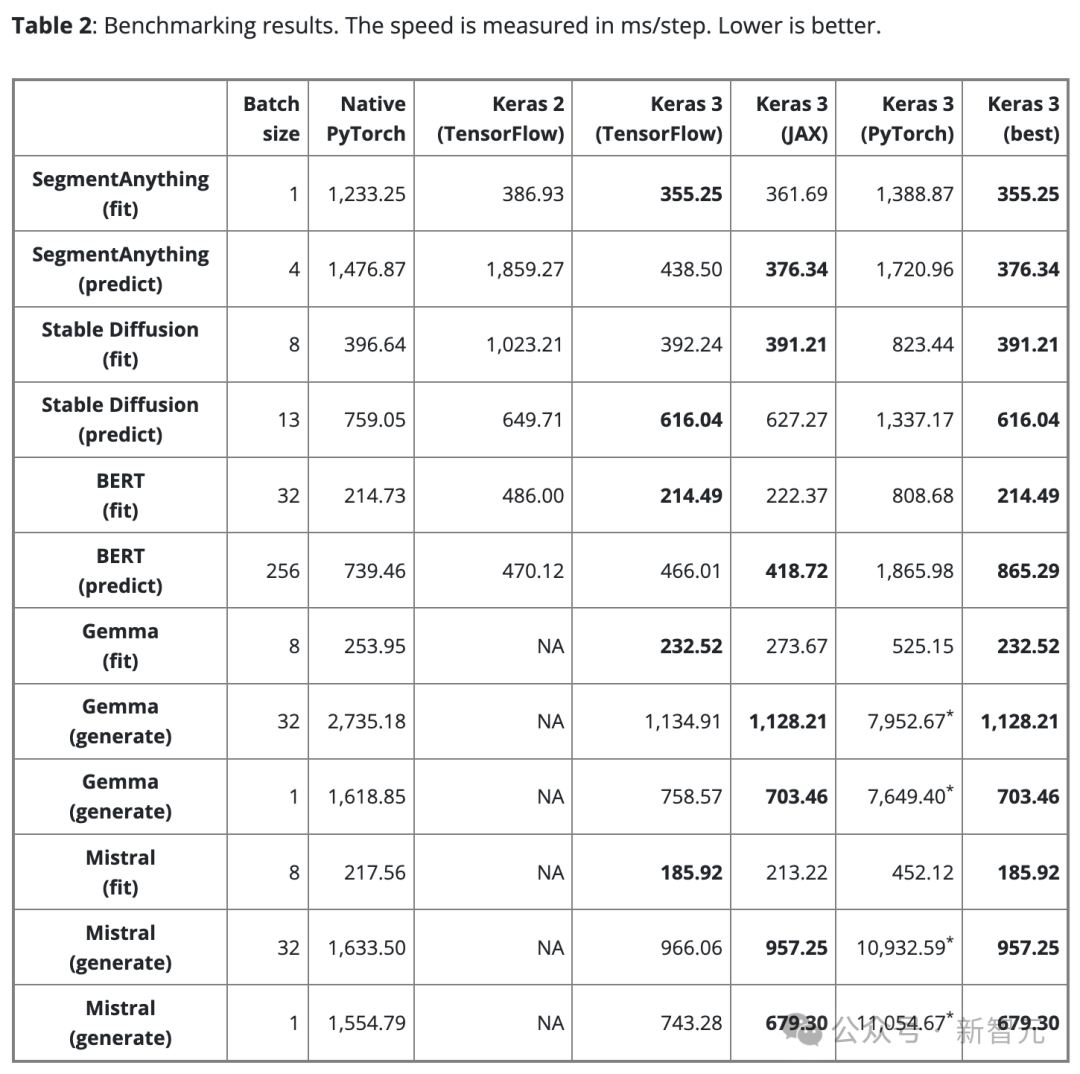
Jadual 2 menunjukkan keputusan penanda aras dalam langkah/ms. Setiap langkah melibatkan latihan atau ramalan pada satu kelompok data.Hasilnya ialah purata 100 langkah, tetapi langkah pertama dikecualikan kerana langkah pertama termasuk penciptaan dan penyusunan model, yang memerlukan masa tambahan.
Untuk memastikan perbandingan yang adil, saiz kelompok yang sama digunakan untuk model dan tugasan yang sama (sama ada latihan atau inferens).
Walau bagaimanapun, untuk model dan tugasan yang berbeza, disebabkan oleh skala dan seni bina yang berbeza, saiz kelompok data boleh dilaraskan mengikut keperluan untuk mengelakkan limpahan memori kerana terlalu besar, atau penggunaan GPU disebabkan kumpulan yang terlalu kecil tidak mencukupi.
Saiz kelompok yang terlalu kecil juga boleh menjadikan PyTorch kelihatan lebih perlahan kerana ia meningkatkan overhead Python.
Untuk model bahasa besar (Gemma dan Mistral), saiz kelompok yang sama juga digunakan semasa ujian kerana ia adalah jenis model yang sama dengan bilangan parameter yang sama (7B).
Memandangkan keperluan pengguna untuk penjanaan teks satu kelompok, kami juga menjalankan ujian penanda aras pada penjanaan teks dengan saiz kelompok 1.
Penemuan 1
Tiada bahagian belakang "optimum". .
Memilih bahagian belakang yang paling pantas selalunya bergantung pada seni bina model.
Perkara ini menyerlahkan kepentingan memilih rangka kerja yang berbeza dalam mengejar prestasi optimum. Keras 3 memudahkan anda menukar hujung belakang untuk mencari yang paling sesuai untuk model anda.
Found 2
Keras 3 secara amnya mengatasi prestasi standard PyTorch.
Berbanding dengan PyTorch asli, Keras 3 mempunyai peningkatan yang ketara dalam daya pemprosesan (langkah/ms).
Khususnya, dalam 5 daripada 10 tugasan ujian, kelajuan meningkat lebih daripada 50%. Antaranya, yang tertinggi mencapai 290%. .
Keras 3 menyediakan persembahan "out of the box" terbaik dalam kelasnya.
Iaitu, semua model Keras yang mengambil bahagian dalam ujian tidak dioptimumkan dalam apa jua cara. Sebaliknya, apabila menggunakan pelaksanaan PyTorch asli, pengguna biasanya perlu melakukan lebih banyak pengoptimuman prestasi sendiri.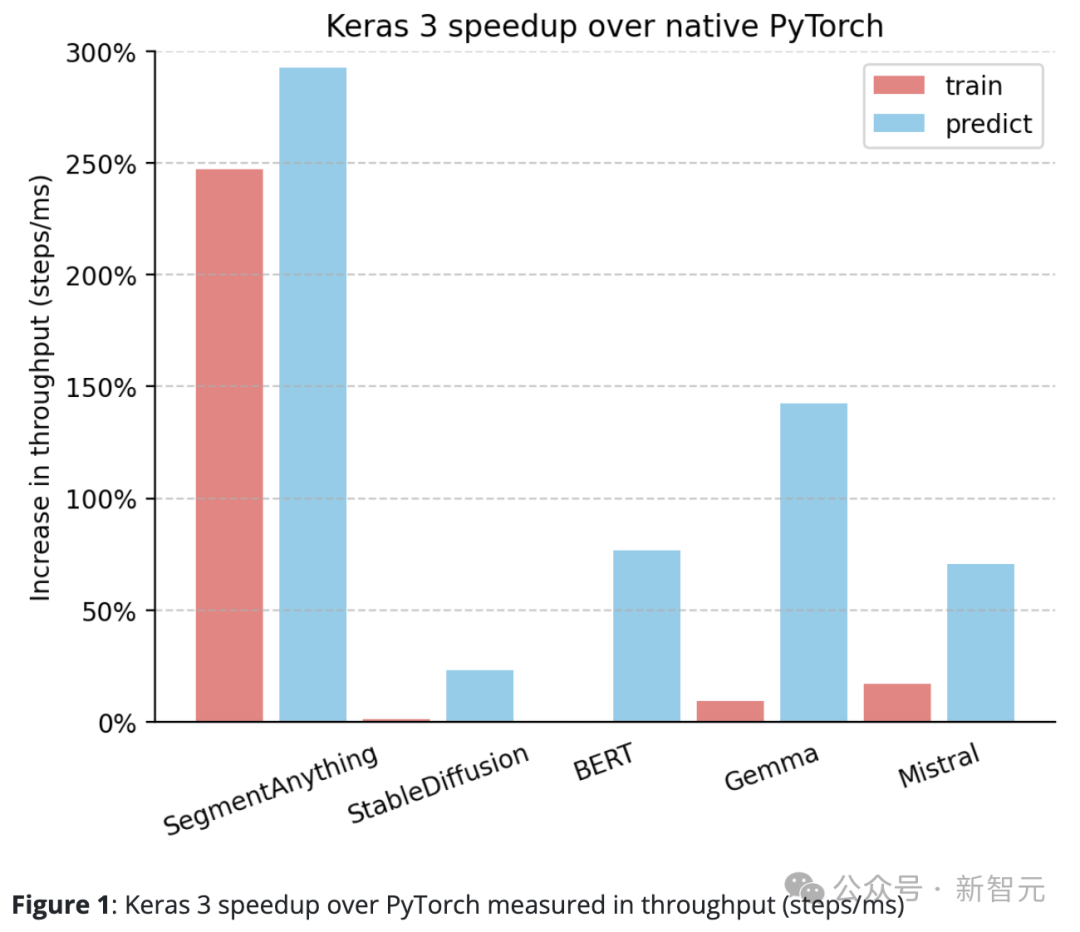
Selain data yang dikongsi di atas, semasa ujian juga telah diperhatikan bahawa prestasi fungsi inferens StableDiffusion bagi Penyebar HuggingFace meningkat lebih daripada 100% apabila menaik taraf daripada versi 0.25.0 kepada 0.3.0.
Begitu juga, dalam HuggingFace Transformers, menaik taraf Gemma daripada versi 4.38.1 kepada 4.38.2 turut meningkatkan prestasi dengan ketara.
Peningkatan prestasi ini menyerlahkan fokus dan usaha HuggingFace dalam pengoptimuman prestasi.Untuk sesetengah model dengan kurang pengoptimuman manual, seperti SegmentAnything, pelaksanaan yang disediakan oleh pengarang kajian digunakan. Dalam kes ini, jurang prestasi berbanding Keras adalah lebih besar daripada kebanyakan model lain.
Ini menunjukkan bahawa Keras mampu memberikan prestasi luar biasa yang sangat baik, dan pengguna boleh menikmati kelajuan larian model yang pantas tanpa perlu mendalami semua teknik pengoptimuman.
Dijumpai 4
Keras 3 secara konsisten mengatasi Keras 2.
Sebagai contoh, kelajuan inferens SegmentAnything telah meningkat sebanyak 380% yang menakjubkan, kelajuan pemprosesan latihan StableDiffusion telah meningkat lebih daripada 150%, dan kelajuan pemprosesan latihan BERT juga telah meningkat lebih daripada 100%.
Ini terutamanya kerana Keras 2 secara langsung menggunakan lebih banyak operasi gabungan TensorFlow dalam beberapa kes, yang mungkin bukan pilihan terbaik untuk kompilasi XLA.
Perlu diingat bahawa walaupun hanya menaik taraf kepada Keras 3 dan terus menggunakan bahagian belakang TensorFlow telah menghasilkan peningkatan prestasi yang ketara.
Kesimpulan
Prestasi rangka kerja sangat bergantung pada model khusus yang digunakan.
Keras 3 boleh membantu memilih rangka kerja terpantas untuk tugas itu, dan pilihan ini hampir sentiasa mengatasi prestasi Keras 2 dan PyTorch.
Lebih penting lagi, model Keras 3 memberikan prestasi luar biasa yang sangat baik tanpa pengoptimuman asas yang kompleks.
Atas ialah kandungan terperinci Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur perintah baris putus cad
perintah baris putus cad Bagaimana untuk menyelesaikan ralat parameter cakera
Bagaimana untuk menyelesaikan ralat parameter cakera Bagaimana untuk menetapkan sempadan bertitik css
Bagaimana untuk menetapkan sempadan bertitik css Senarai lengkap kekunci pintasan idea
Senarai lengkap kekunci pintasan idea Bagaimana untuk menyelesaikan masalah bahawa fail msxml6.dll hilang
Bagaimana untuk menyelesaikan masalah bahawa fail msxml6.dll hilang Cara memuat turun dan menyimpan video tajuk hari ini
Cara memuat turun dan menyimpan video tajuk hari ini Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot
Bagaimana untuk membaiki sistem win7 jika ia rosak dan tidak boleh boot




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



