


Ilusi model besar akhirnya akan berakhir?
Hari ini, satu catatan di platform media sosial Reddit membangkitkan perbincangan hangat di kalangan netizen. Siaran itu membincangkan kertas kerja "Faktualiti bentuk panjang dalam model bahasa besar" yang diserahkan oleh Google DeepMind semalam. Kaedah dan hasil yang dicadangkan dalam artikel membuat orang membuat kesimpulan bahawa ilusi model bahasa besar tidak lagi menjadi masalah.

Kami tahu bahawa model bahasa yang besar sering menghasilkan kandungan yang mengandungi ralat fakta apabila menjawab soalan mencari fakta mengenai topik terbuka. DeepMind telah menjalankan beberapa penyelidikan penerokaan terhadap fenomena ini.
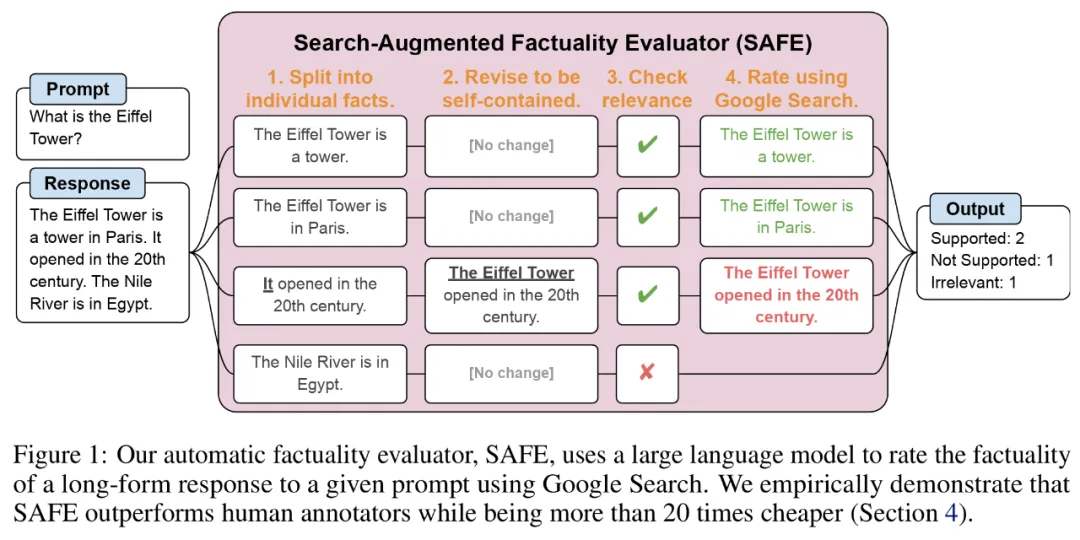
Untuk menanda aras fakta panjang model dalam domain terbuka, penyelidik menggunakan GPT-4 untuk menjana LongFact, set segera yang mengandungi 38 topik dan beribu-ribu soalan. Mereka kemudiannya mencadangkan menggunakan Penilai Fakta Ditambah Carian (SAFE) untuk menggunakan ejen LLM sebagai penilai automatik bagi fakta bentuk panjang. Tujuan SAFE adalah untuk meningkatkan ketepatan penilai kredibiliti fakta.
Berkenaan SELAMAT, menggunakan LLM boleh menerangkan ketepatan setiap kejadian dengan lebih tepat. Proses penaakulan berbilang langkah ini melibatkan penghantaran pertanyaan carian ke Carian Google dan menentukan sama ada hasil carian menyokong contoh tertentu.

Alamat kertas: https://arxiv.org/pdf/2403.18802.pdf
Alamat GitHub: https://github.com/google-deepmind/long-form-factuality Selain itu, penyelidik mencadangkan untuk memanjangkan skor F1 (F1@K) kepada penunjuk agregat praktikal bentuk panjang. Mereka mengimbangi peratusan fakta yang disokong dalam respons (ketepatan) dengan peratusan fakta yang diberikan berbanding hiperparameter yang mewakili panjang respons pilihan pengguna (ingat semula).
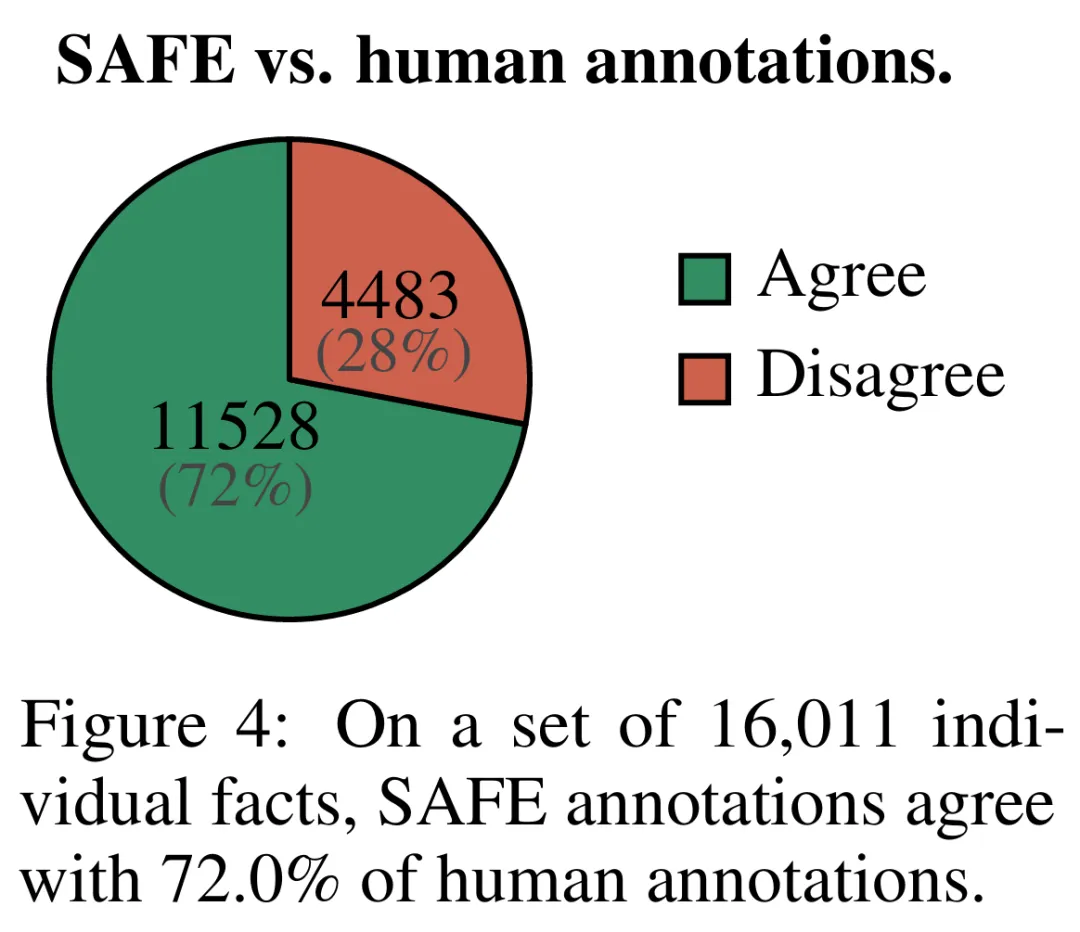
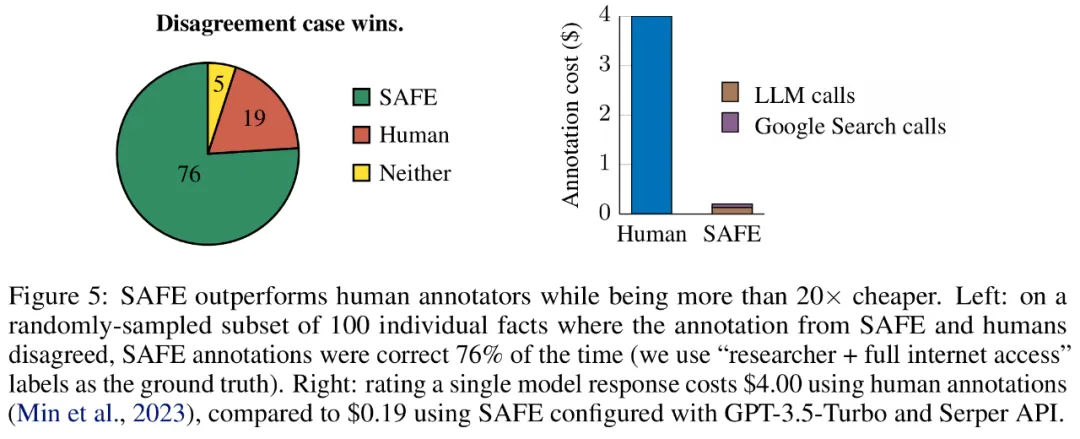
Hasil empirikal menunjukkan ejen LLM boleh mencapai prestasi penarafan yang melebihi manusia. Pada set ~16k fakta individu, SAFE bersetuju dengan anotasi manusia sebanyak 72% dan pada subset rawak 100 kes perselisihan faham, SAFE memenangi 76% pada setiap masa. Pada masa yang sama, SAFE adalah lebih daripada 20 kali lebih murah daripada anotasi manusia.
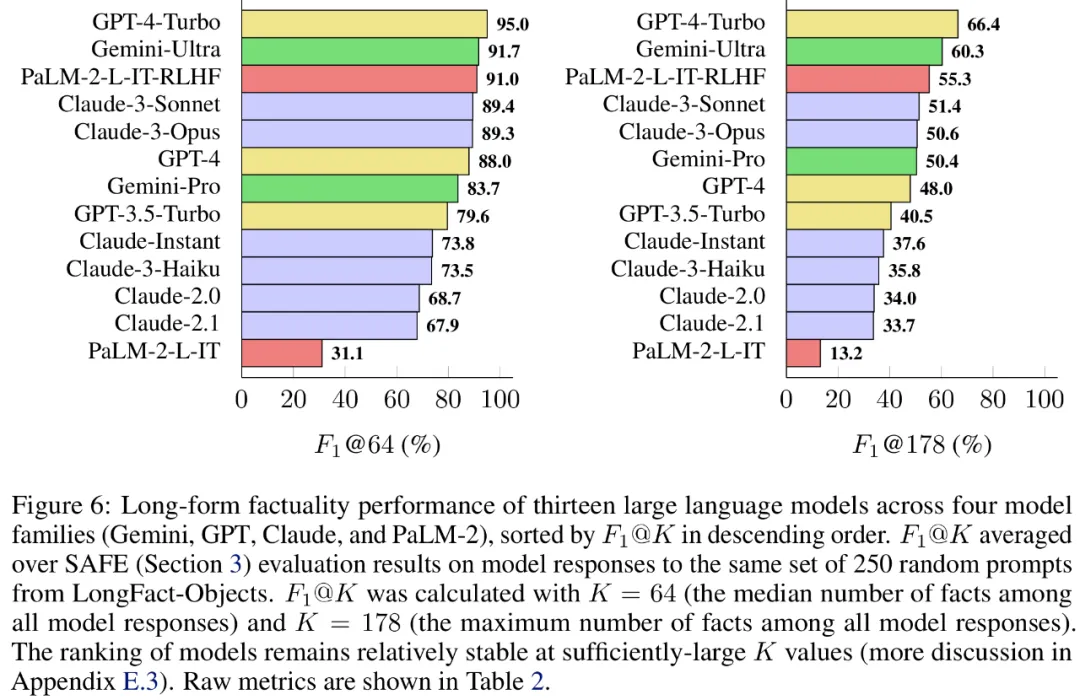
Para penyelidik juga menggunakan LongFact untuk menanda aras 13 model bahasa popular dalam empat siri model besar (Gemini, GPT, Claude dan PaLM-2), dan mendapati bahawa model bahasa yang lebih besar secara amnya boleh mencapai hasil yang lebih baik.
Quoc V. Le, salah seorang pengarang kertas kerja dan saintis penyelidikan di Google, berkata bahawa kerja baharu ini untuk menilai dan menanda aras kefaktaan bentuk panjang mencadangkan set data baharu, kaedah penilaian baharu dan kaedah yang mengimbangi ketepatan dan Metrik agregat ingat kembali. Pada masa yang sama, semua data dan kod akan menjadi sumber terbuka untuk kerja masa hadapan.
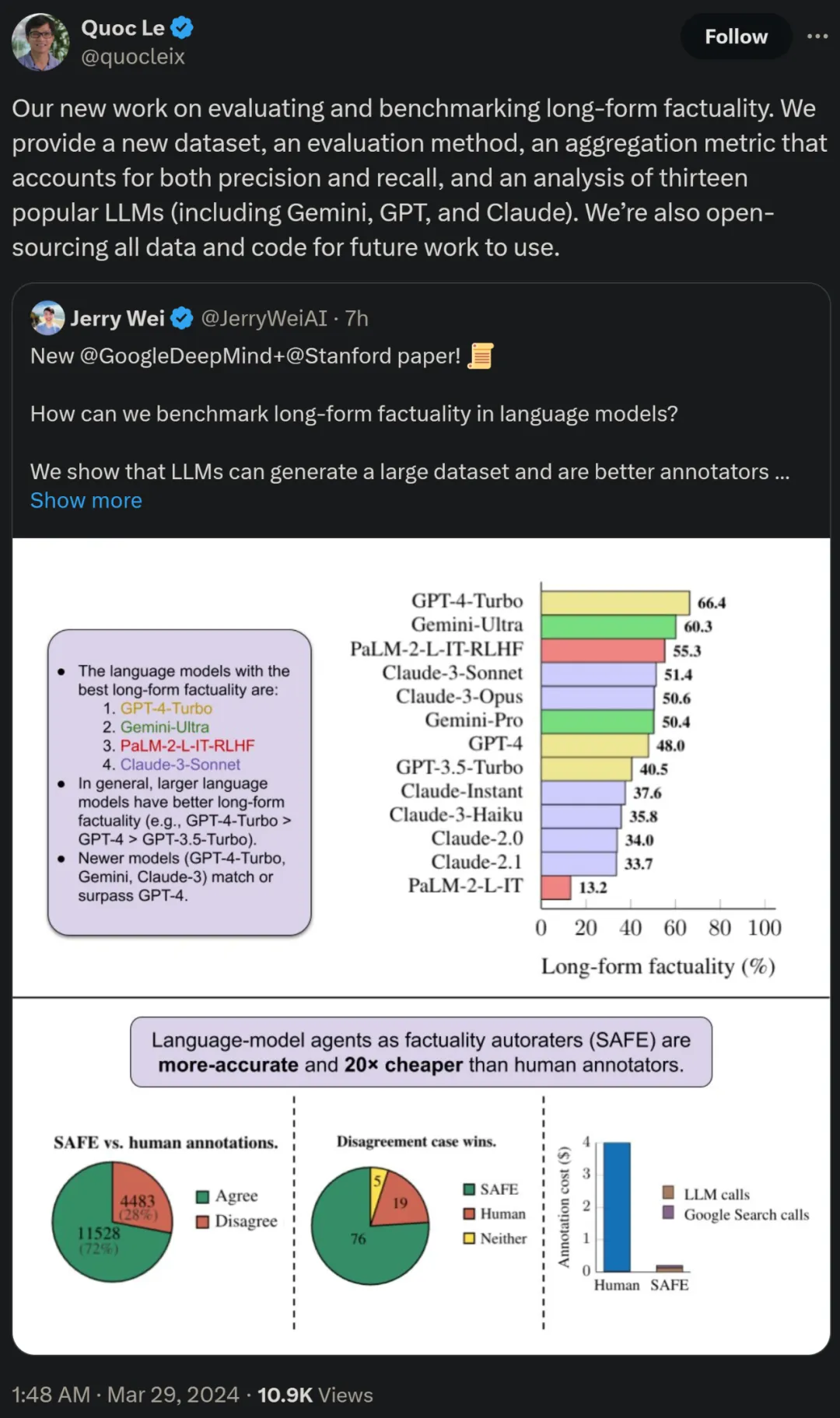 method overview
method overview
LongFact mengandungi dua tugas: LongFact-Concepts dan LongFact-Objects, dibezakan dengan sama ada soalan bertanya tentang konsep atau objek. Para penyelidik menjana 30 isyarat unik untuk setiap subjek, menghasilkan 1140 isyarat untuk setiap tugas.
SELAMAT: Ejen LLM sebagai penilai automatik fakta

Para penyelidik mencadangkan Penilai Fakta Ditambah Carian (SELAMAT), dan prinsip operasinya menyala jawapan panjang ke dalam fakta bebas yang berasingan;
b) Tentukan sama ada setiap fakta individu adalah relevan untuk menjawab gesaan dalam konteksc) Untuk setiap fakta yang berkaitan, keluarkan pertanyaan carian Google secara berulang dalam proses berbilang langkah dan sebabkan sama ada hasil carian menyokong fakta tersebut. Mereka percaya bahawa inovasi utama SAFE ialah menggunakan model bahasa sebagai ejen untuk menjana pertanyaan carian Google berbilang langkah dan membuat alasan dengan teliti sama ada hasil carian menyokong fakta. Rajah 3 di bawah menunjukkan contoh rantaian penaakulan. Untuk membahagikan respons yang panjang kepada fakta bebas yang berasingan, para penyelidik mula-mula menggesa model bahasa untuk membahagikan setiap ayat dalam respons yang panjang kepada fakta yang berasingan, dan kemudian mengarahkan model itu untuk memisahkan rujukan yang tidak jelas seperti kata ganti nama ) dengan entiti yang betul yang mereka rujuk dalam konteks tindak balas, mengubah suai setiap fakta individu menjadi bebas. Untuk menjaringkan setiap fakta bebas, mereka menggunakan model bahasa untuk membuat alasan sama ada fakta itu berkaitan dengan gesaan yang dijawab dalam konteks respons, dan kemudian menggunakan kaedah berbilang langkah untuk menilai setiap fakta relevan yang masih ada sebagai "disokong" atau "tidak disokong". Butirannya ditunjukkan dalam Rajah 1 di bawah. Pada setiap langkah, model menjana pertanyaan carian berdasarkan fakta yang akan dijaringkan dan hasil carian yang diperoleh sebelum ini. Selepas beberapa langkah tertentu, model melakukan inferens untuk menentukan sama ada hasil carian menyokong fakta tersebut, seperti yang ditunjukkan dalam Rajah 3 di atas. Selepas semua fakta dinilai, metrik keluaran SAFE untuk pasangan tindak balas segera adalah bilangan fakta "sokongan", bilangan fakta "tidak berkaitan" dan bilangan fakta "tidak disokong". Ejen LLM menjadi pencatat fakta yang lebih baik daripada manusia Untuk menilai secara kuantitatif kualiti anotasi yang diperoleh menggunakan SELAMAT, para penyelidik menggunakan anotasi manusia. Data tersebut mengandungi 496 pasangan tindak balas segera, yang mana respons dibahagikan secara manual kepada fakta individu (jumlah 16,011 fakta individu), dan setiap fakta individu dilabelkan secara manual sebagai disokong, tidak relevan atau tidak disokong. Mereka membandingkan secara langsung anotasi SELAMAT dan anotasi manusia untuk setiap fakta dan mendapati bahawa SELAMAT bersetuju dengan manusia pada 72.0% fakta individu, seperti ditunjukkan dalam Rajah 4 di bawah. Ini menunjukkan bahawa SAFE mencapai prestasi peringkat manusia pada kebanyakan fakta individu. Subset 100 fakta individu daripada temu bual rawak kemudiannya diperiksa yang mana anotasi SAFE tidak konsisten dengan penilai manusia. Penyelidik menganotasi semula setiap fakta secara manual (membenarkan akses kepada Carian Google, bukan sahaja Wikipedia, untuk penjelasan yang lebih komprehensif) dan menggunakan label ini sebagai kebenaran asas. Mereka mendapati bahawa dalam kes percanggahan pendapat ini, anotasi SAFE adalah betul 76% sepanjang masa, manakala anotasi manusia adalah betul hanya 19% pada masa itu, mewakili kadar kemenangan 4 berbanding 1 untuk SAFE. Butirannya ditunjukkan dalam Rajah 5 di bawah. Di sini, harga dua pelan anotasi patut diberi perhatian. Kos untuk menilai respons model tunggal menggunakan anotasi manusia ialah $4, manakala SAFE menggunakan GPT-3.5-Turbo dan Serper API hanya $0.19. Tanda aras siri Gemini, GPT, Claude dan PaLM-2 Akhirnya, penyelidik menguji empat siri model (Gemini, GPT-12 di bawah Long) dan PaFLM dalam Jadual 2) Menjalankan ujian penanda aras yang meluas pada 13 model bahasa yang besar. Secara khusus, mereka menilai setiap model menggunakan subset rawak yang sama iaitu 250 petunjuk dalam LongFact-Objects, kemudian menggunakan SAFE untuk mendapatkan metrik penilaian mentah bagi setiap tindak balas model, dan menggunakan metrik F1@K. Didapati bahawa, secara amnya, model bahasa yang lebih besar mencapai faktual bentuk panjang yang lebih baik. Seperti yang ditunjukkan dalam Rajah 6 dan Jadual 2 di bawah, GPT-4-Turbo lebih baik daripada GPT-4, GPT-4 lebih baik daripada GPT-3.5-Turbo, Gemini-Ultra lebih baik daripada Gemini-Pro dan PaLM-2-L -IT-RLHF Lebih baik daripada PaLM-2-L-IT. Sila rujuk kertas asal untuk butiran lanjut teknikal dan keputusan percubaan. 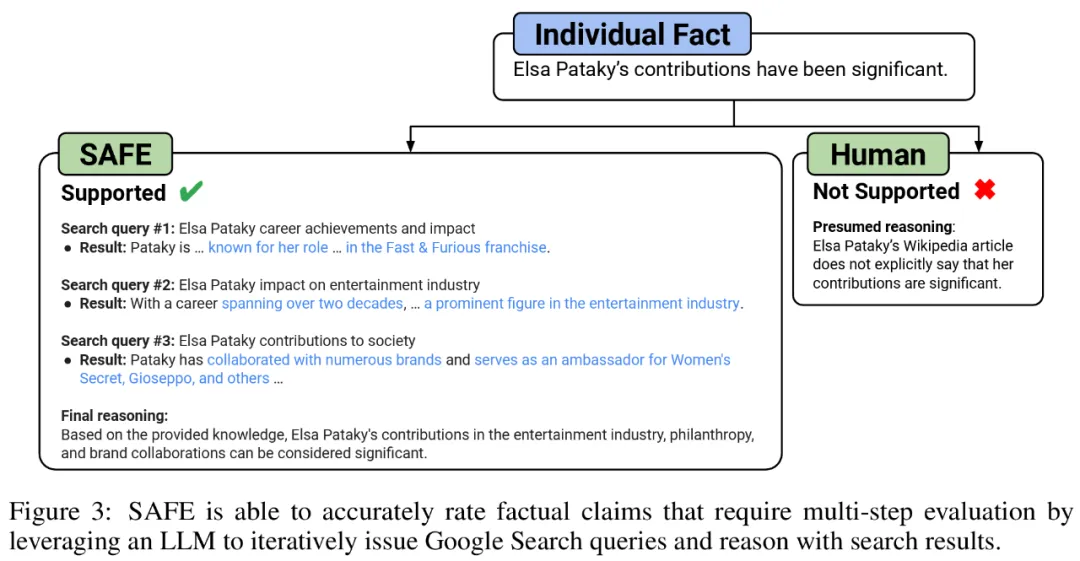
Hasil eksperimen

Atas ialah kandungan terperinci DeepMind menamatkan ilusi model besar? Pelabelan fakta lebih dipercayai daripada manusia, 20 kali lebih murah, dan sumber terbuka sepenuhnya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah perisian anti-virus?
Apakah perisian anti-virus?
 Platform mata wang digital domestik
Platform mata wang digital domestik
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
 Apakah maksud c#?
Apakah maksud c#?
 Bagaimana untuk memulihkan fail yang dipadam secara kekal pada komputer
Bagaimana untuk memulihkan fail yang dipadam secara kekal pada komputer
 Bagaimana untuk membuka fail html pada telefon bimbit
Bagaimana untuk membuka fail html pada telefon bimbit
 Kaedah pemulihan pangkalan data Oracle
Kaedah pemulihan pangkalan data Oracle
 Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej
Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



