


Selepas bos pergi, model pertama dah ada!
Baru hari ini, Stability AI secara rasmi mengumumkan model kod baharu, Stable Code Instruct 3B.
 Gambar
Gambar
Kestabilan adalah sangat penting. Pemergian CEO telah menyebabkan beberapa masalah kepada Stable Diffusion, dan mungkin ada masalah dengan gaji anda sendiri.
Walau bagaimanapun, angin dan hujan sedang melanda di luar bangunan, tetapi makmal tetap tidak bergerak Penyelidikan harus dilakukan, perbincangan harus dibuat, dan model harus disesuaikan Perang model besar-besaran dalam pelbagai bidang .
Bukan sahaja ia menyebarkan gerainya untuk terlibat dalam peperangan habis-habisan, tetapi setiap penyelidikan juga membuat kemajuan yang berterusan. . Stable_C ode_TechReport_release.pdf
 Dengan gesaan bahasa semula jadi, Stable Code Instruct 3B boleh Mengendalikan pelbagai tugas seperti penjanaan kod, matematik dan pertanyaan berkaitan pembangunan perisian lain. . adalah lebih daripada dua kali ganda saiznya 7B Instruct dan model lain, dan prestasinya dalam tugas berkaitan kejuruteraan perisian adalah setanding dengan StarChat 15B. .
Dengan gesaan bahasa semula jadi, Stable Code Instruct 3B boleh Mengendalikan pelbagai tugas seperti penjanaan kod, matematik dan pertanyaan berkaitan pembangunan perisian lain. . adalah lebih daripada dua kali ganda saiznya 7B Instruct dan model lain, dan prestasinya dalam tugas berkaitan kejuruteraan perisian adalah setanding dengan StarChat 15B. .
Pengujian menunjukkan bahawa Stable Code Instruct 3B mampu memadankan atau melebihi pesaing dalam ketepatan penyelesaian kod, pemahaman arahan bahasa semula jadi dan serba boleh merentas bahasa pengaturcaraan yang berbeza.
Pictures
 Stable Code Instruct 3B adalah berdasarkan hasil tinjauan pemaju Stack Overflow 2023 dan memfokuskan latihan pada bahasa pengaturcaraan seperti Python, Javascript, Java, C, C++ dan Pergi.
Stable Code Instruct 3B adalah berdasarkan hasil tinjauan pemaju Stack Overflow 2023 dan memfokuskan latihan pada bahasa pengaturcaraan seperti Python, Javascript, Java, C, C++ dan Pergi.
Selain daripada bahasa pengaturcaraan popular yang disebutkan di atas, Stable Code Instruct 3B juga termasuk latihan untuk bahasa lain (seperti SQL, PHP dan Rust), dan boleh memberikan latihan yang berkuasa walaupun dalam bahasa tanpa latihan (seperti Lua) prestasi ujian.
Stable Code Instruct 3B bukan sahaja mahir dalam penjanaan kod, tetapi juga tugasan FIM (isi di tengah), pertanyaan pangkalan data, terjemahan kod, tafsiran dan penciptaan. 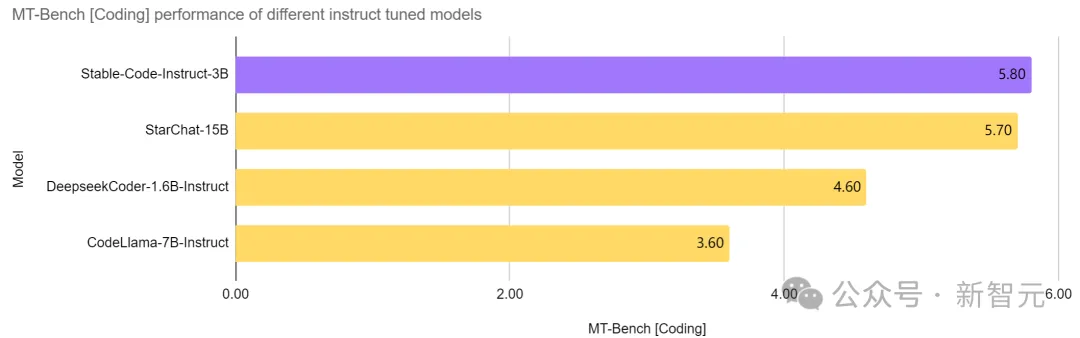
Gambar
Muat Turun Model: https://huggingface.co/stabilityai/stable-code-instruct-3b
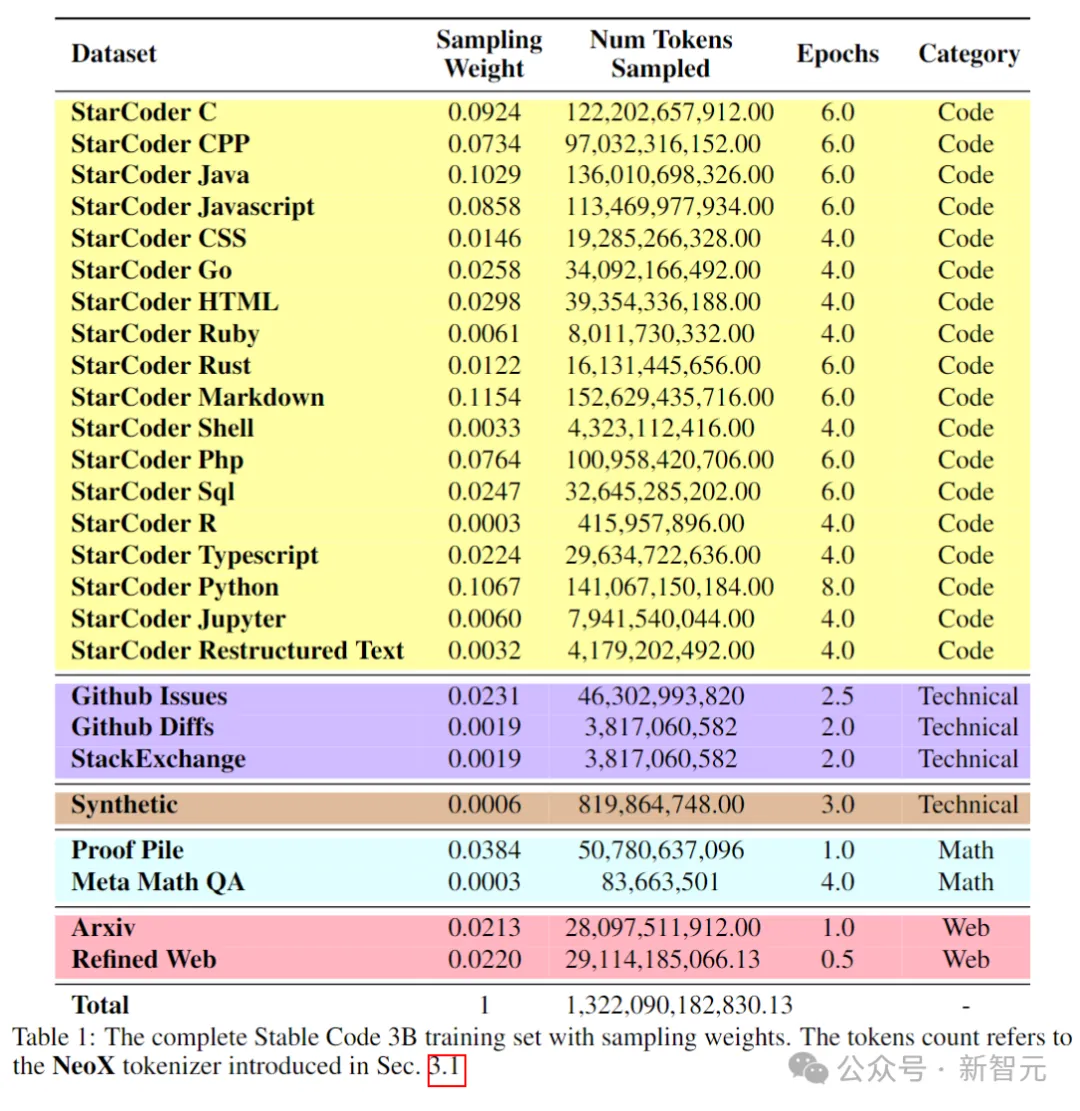
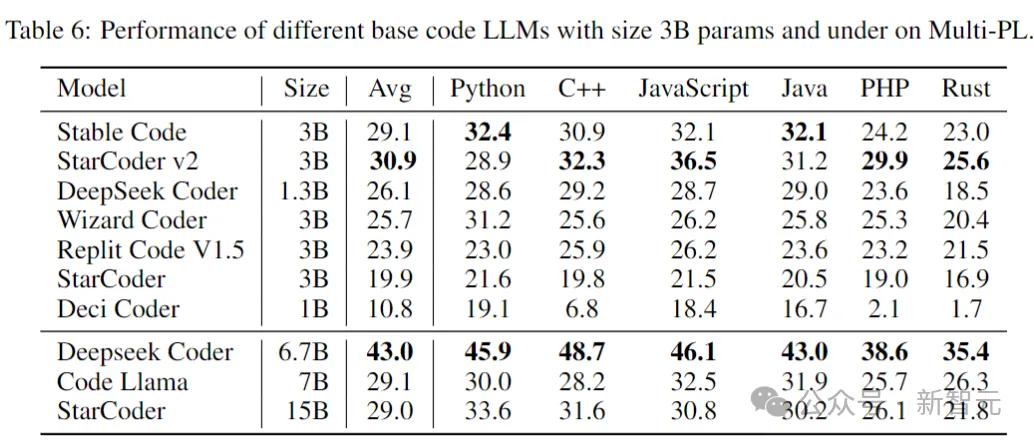
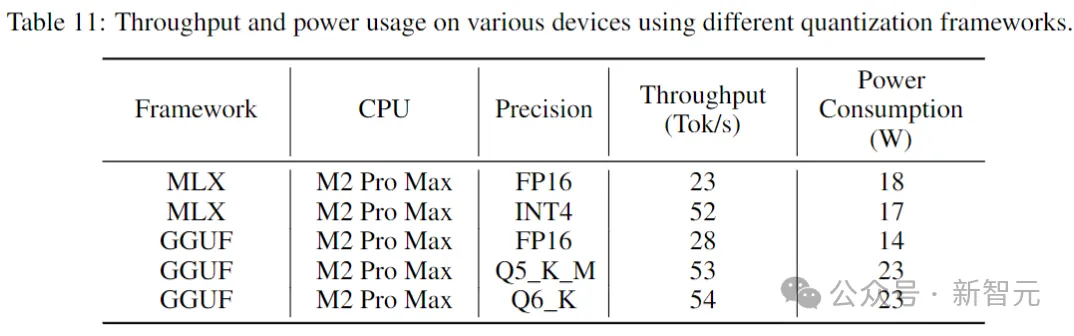
Kod Stabil dibina pada Stable LM 3B dan merupakan reka bentuk penyahkod sahaja yang serupa dengan Transformer Jadual berikut ialah beberapa maklumat struktur utama: Perbezaan utama dengan LLaMA termasuk: Pembenaman kedudukan yang lebih baik: Gunakan pembenaman subkue pertama yang diputar 25% daya pengeluaran. Regulasi: Gunakan LayerNorm dengan istilah bias pembelajaran dan bukannya RMSNorm. Syarat bias: Semua istilah berat sebelah dalam rangkaian suapan hadapan dan lapisan perhatian diri berbilang kepala dipadamkan, kecuali untuk KQV. Menggunakan tokenizer (BPE) yang sama seperti model LM 3B Stable, dengan saiz 50,257 sebagai tambahan, tag khas StarCoder juga dirujuk, termasuk bilangan bintang yang digunakan untuk menunjukkan nama fail, repositori, dan menunggu pengisian pertengahan (FIM). Untuk latihan konteks yang panjang, gunakan penanda khas untuk menunjukkan apabila dua fail yang digabungkan tergolong dalam repositori yang sama. Data latihan Data data pra-latihan mengumpul pelbagai sumber data berskala besar yang boleh diakses secara umum, termasuk repositori bacaan kod (seperti, dokumentasi teknikal) Fokus pada teks dan set data web yang besar. Matlamat utama fasa pra-latihan awal adalah untuk mempelajari perwakilan dalaman yang kaya untuk meningkatkan keupayaan model dengan ketara dalam pemahaman matematik, penaakulan logik dan memproses teks teknikal yang kompleks yang berkaitan dengan pembangunan perisian. Di samping itu, data latihan juga mengandungi set data teks biasa untuk menyediakan model dengan pengetahuan dan konteks bahasa yang lebih luas, akhirnya membolehkan model mengendalikan pelbagai pertanyaan dan tugasan yang lebih luas dalam cara perbualan. Jadual berikut menunjukkan sumber data, kategori dan berat pensampelan korpus pra-latihan, dengan nisbah kod dan data bahasa semula jadi ialah 80:20. Selain itu, penyelidik juga memperkenalkan set data sintetik kecil, data itu telah disintesis daripada petua benih set data CodeAlpaca, yang mengandungi 174,000 petua. Dan mengikuti kaedah WizardLM, secara beransur-ansur meningkatkan kerumitan gesaan benih yang diberikan, dan memperoleh 100,000 gesaan tambahan. Pengarang percaya bahawa memperkenalkan data sintetik ini pada awal peringkat pra-latihan membantu model bertindak balas dengan lebih baik kepada teks bahasa semula jadi. Dataset data konteks panjang Memandangkan berbilang fail dalam repositori sering bergantung antara satu sama lain, panjang konteks adalah penting untuk model pengekodan. Para penyelidik menganggarkan bilangan median dan purata token dalam repositori perisian masing-masing ialah 12k dan 18k, jadi 16,384 telah dipilih sebagai panjang konteks. Langkah seterusnya adalah untuk membuat dataset konteks yang panjang aliran kandungan. Untuk mengelakkan sebarang potensi berat sebelah yang mungkin timbul daripada susunan fail yang tetap, penulis menggunakan strategi rawak. Untuk setiap repositori, dua urutan fail sambungan yang berbeza dijana. Gambar Kod Stabil dilatih menggunakan 32 contoh Amazon P4d, yang mengandungi 254 penggunaan NVIDIA A100256GB dan optimasi NVIDIA. Kaedah latihan berperingkat digunakan di sini, seperti yang ditunjukkan dalam gambar di atas. Latihan mengikut pemodelan jujukan autoregresif standard untuk meramalkan token seterusnya. Model ini dimulakan menggunakan pusat pemeriksaan Stabil LM 3B Panjang konteks bagi peringkat pertama latihan ialah 4096, dan kemudian pra-latihan berterusan dilakukan. Latihan dilakukan dengan ketepatan campuran BFloat16, dan FP32 digunakan untuk all-reduce. Tetapan pengoptimum AdamW ialah: β1=0.9, β2=0.95, ε=1e−6, λ (pereputan berat)=0.1. Mulakan dengan kadar pembelajaran = 3.2e-4, tetapkan kadar pembelajaran minimum kepada 3.2e-5, dan gunakan pereputan kosinus. One of the Core Assumsions of Natural Language Model Latihan adalah urutan kausa kiri-ke-kanan. pengisytiharan Boleh dalam sebarang susunan untuk banyak fungsi). Untuk menyelesaikan masalah ini, penyelidik menggunakan FIM (Isi Tengah). Bahagikan dokumen kepada tiga segmen secara rawak: awalan, tengah dan akhiran, kemudian alihkan segmen tengah ke penghujung dokumen. Selepas penyusunan semula, proses latihan autoregresif yang sama diikuti. . Selepas melakukan penyahduaan padanan tepat, tiga set data menyediakan sejumlah kira-kira 500,000 sampel latihan. Gunakan penjadual kadar pembelajaran kosinus untuk mengawal proses latihan dan tetapkan saiz kelompok global kepada 512 untuk membungkus input ke dalam urutan panjang tidak lebih daripada 4096. Selepas SFT, mulakan fasa DPO, menggunakan data daripada UltraFeedback untuk memilih set data yang mengandungi kira-kira 7,000 sampel. Di samping itu, untuk meningkatkan keselamatan model, penulis juga memasukkan dataset RLFH yang Bermanfaat dan Tidak Memudaratkan. Para penyelidik menggunakan RMSProp sebagai algoritma pengoptimuman dan meningkatkan kadar pembelajaran ke puncak 5e-7 dalam peringkat awal latihan DPO. Ujian Prestasi Berikut membandingkan prestasi model pada tugas penyiapan kod, menggunakan penanda aras Multi-PL untuk menilai model. Jadual berikut menunjukkan prestasi model kod berbeza dengan parameter saiz 3B dan ke bawah pada Multi-PL. Gambar Walaupun bilangan parameter Kod Stabil masing-masing kurang daripada 40% dan 20% Kod Llama dan StarCoder 15B, prestasi purata model dalam pelbagai bahasa pengaturcaraan adalah setanding dengan mereka. Jadual berikut menilai arahan versi yang diperhalusi beberapa model dalam penanda aras Multi-PL. Pictures SQL Performance Gambar Prestasi Inferens Keputusan menunjukkan bahawa daya pengeluaran meningkat hampir dua kali ganda apabila menggunakan ketepatan yang lebih rendah. Walau bagaimanapun, adalah penting untuk ambil perhatian bahawa melaksanakan pengkuantitian ketepatan yang lebih rendah boleh mengakibatkan beberapa kemerosotan (berpotensi besar) dalam prestasi model. Rujukan: //m.sbmmt.com/link/8cb3522da182ff9ea5925bbd8975b203
Butiran teknikal
 Gambar
GambarSeni bina model
 Gambar
Gambar
Proses latihan
 Pictures
Pictures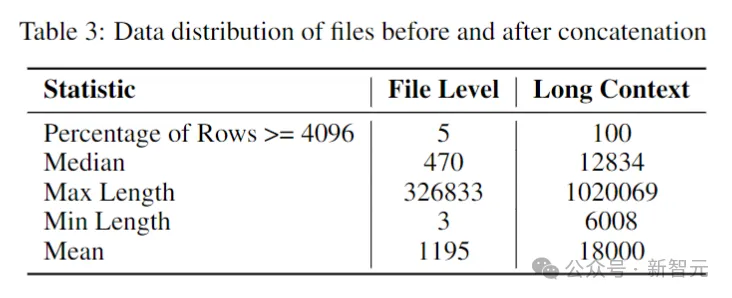 Latihan berperingkat
Latihan berperingkat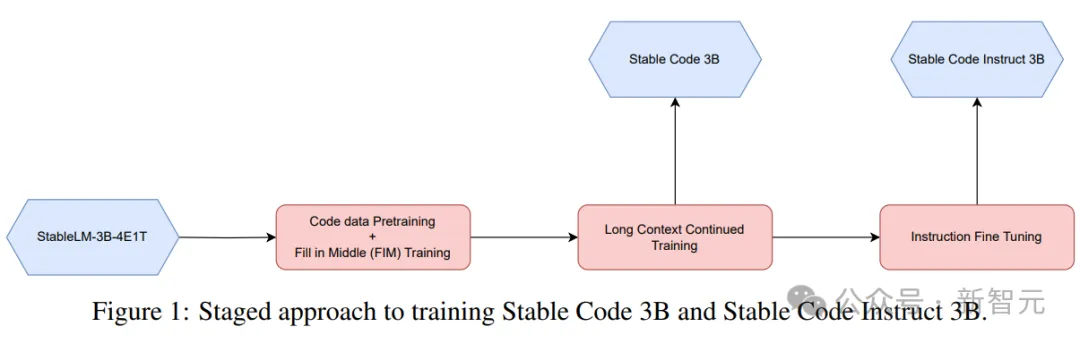 Gambar
Gambar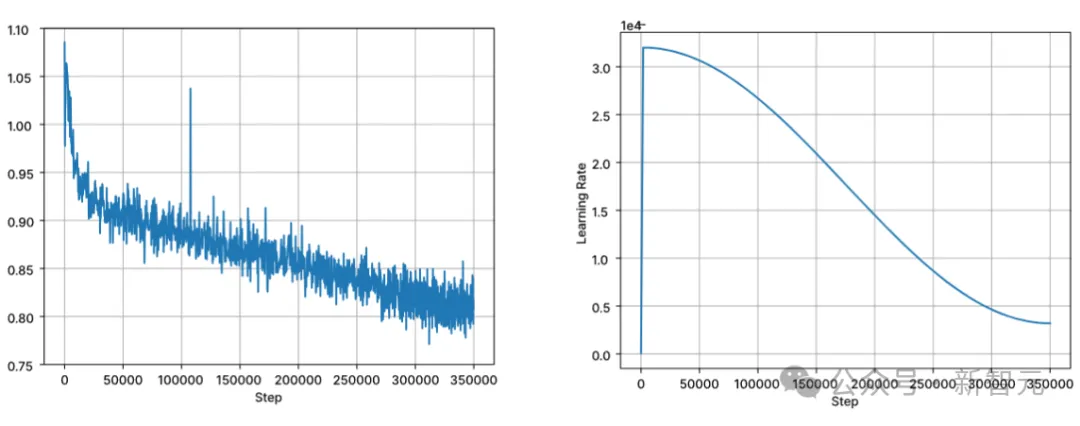 Pictures
PicturesMula-mula lakukan penalaan halus SFT menggunakan set data yang tersedia secara umum pada Wajah Memeluk: termasuk OpenHermes, Maklum Balas Kod, CodeAlpaca.
Pangkalan Kod Stabil
 Arahan Kod Stabil
Arahan Kod Stabil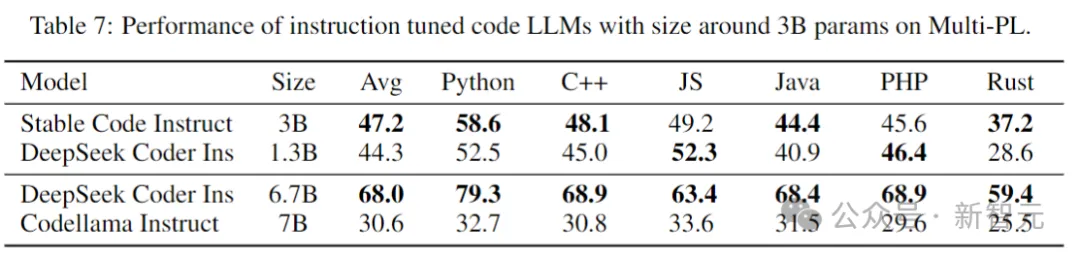

 Gambar
Gambar
Atas ialah kandungan terperinci Jawatan pertama sejak bos pergi! Model kod rasmi kestabilan Kod Stabil Arahan 3B. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Formula pilih atur dan gabungan yang biasa digunakan
Formula pilih atur dan gabungan yang biasa digunakan
 Pengenalan kepada penggunaan kod keseluruhan vbs
Pengenalan kepada penggunaan kod keseluruhan vbs
 Adakah perdagangan Bitcoin dibenarkan di China?
Adakah perdagangan Bitcoin dibenarkan di China?
 Apakah jenis data asas dalam php
Apakah jenis data asas dalam php
 Apakah pertukaran Sols Inscription Coin?
Apakah pertukaran Sols Inscription Coin?
 Pengenalan pelayan PHP
Pengenalan pelayan PHP
 Apakah maksud rangkaian gprs?
Apakah maksud rangkaian gprs?
 Bagaimana untuk mengaktifkan perkhidmatan storan awan
Bagaimana untuk mengaktifkan perkhidmatan storan awan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



