


Versi Microsoft Sora dilahirkan!
Sora adalah sumber popular tetapi tertutup, yang telah membawa cabaran yang agak besar kepada komuniti akademik. Ulama hanya boleh cuba menggunakan kejuruteraan terbalik untuk menghasilkan semula atau melanjutkan Sora.
Walaupun strategi Diffusion Transformer dan tampalan spatial telah dicadangkan, masih sukar untuk mencapai prestasi Sora, apatah lagi kekurangan kuasa pengkomputeran dan set data.
Walau bagaimanapun, gelombang caj baharu yang dilancarkan oleh penyelidik untuk menghasilkan semula Sora akan datang!
Sebentar tadi, Lehigh University bekerjasama dengan pasukan Microsoft untuk membangunkan rangka kerja ejen multi-AI baharu—Mora.

Alamat kertas: https://arxiv.org/abs/2403.13248
Ya, idea Lehigh University dan Microsoft bergantung pada ejen AI.
Mora lebih seperti generasi video generalis Sora. Dengan menyepadukan berbilang ejen AI visual SOTA, keupayaan penjanaan video universal yang ditunjukkan oleh Sora boleh dihasilkan semula.

Secara khusus, Mora dapat memanfaatkan berbilang ejen visual untuk mensimulasikan keupayaan penjanaan video Sora dalam pelbagai tugas, termasuk:
-Teks ke penjanaan video🜎🜎 penjanaan imej ke video
- Panjangkan video yang dijana
- Penyuntingan video ke video
- Menjahit video
- Dunia digital analog
Keputusan menunjukkan , Mora mencapai prestasi rapat dengan Sora dalam tugasan ini.
Perlu dinyatakan bahawa prestasinya dalam tugas penjanaan teks-ke-video mengatasi model sumber terbuka sedia ada dan menduduki tempat kedua dalam kalangan semua model, kedua selepas Sora.
Namun, masih terdapat jurang yang jelas dengan Sora dari segi prestasi keseluruhan.
Mora boleh menjana resolusi tinggi, video koheren masa berdasarkan gesaan teks, dengan resolusi 1024 × 576, tempoh 12 saat dan sejumlah 75 bingkai.

Mora pada asasnya memulihkan semua kebolehan Sora Bagaimana untuk menjelmakannya?
Teks kepada penjanaan video
Petua: Terumbu karang bertenaga penuh dengan kehidupan di bawah lautan biru sejernih kristal, dengan ikan berwarna-warni berenang di antara karang, sinaran cahaya matahari dan arus yang lembut menggerakkan tumbuhan laut.

Petua: Banjaran gunung yang megah dilitupi salji, dengan puncaknya menyentuh awan dan tasik jernih di dasarnya, memantulkan gunung dan langit, mencipta cermin semula jadi yang mempesonakan.

Petua: Di tengah-tengah padang pasir yang luas, sebuah bandar padang pasir keemasan muncul di kaki langit, seni binanya gabungan unsur-unsur Mesir kuno dan futuristik. Bandar ini dikelilingi oleh tenaga yang bersinar penghalang, semasa di udara, tujuh

Penjanaan imej bersyarat berasaskan teks kepada video
Masukkan "imej awan realistik dengan perkataan SORA" klasik ini.

Petua: Imej awan realistik yang mengeja “SORA”.
Kesan yang dihasilkan oleh model Sora adalah seperti ini.

Video yang dihasilkan oleh Mora tidaklah teruk sama sekali.

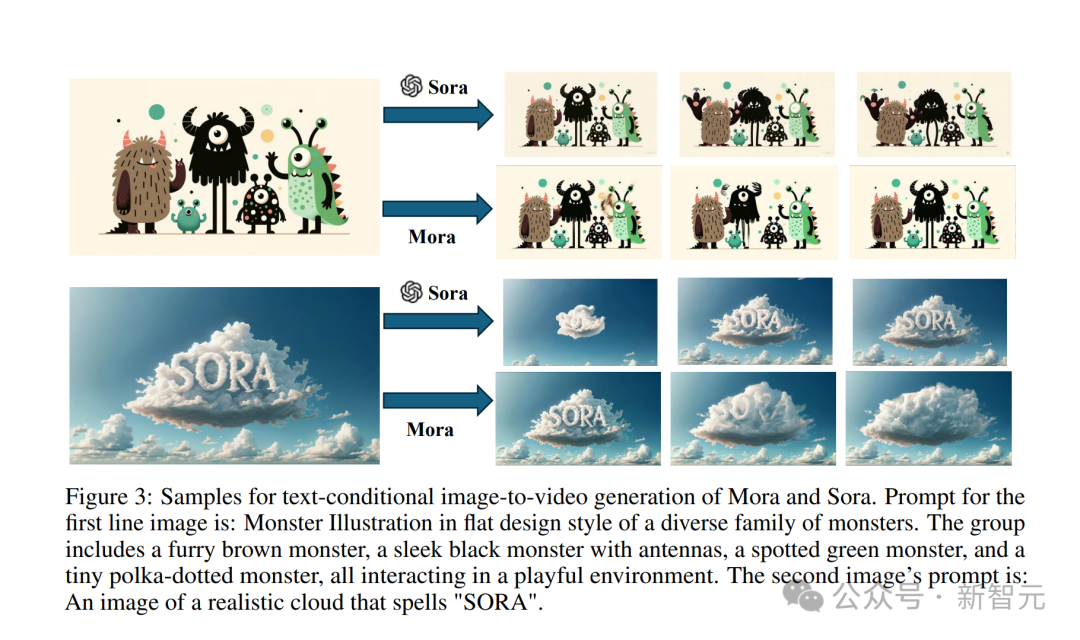
Masukkan juga gambar raksasa kecil. . semua berinteraksi dalam persekitaran yang suka bermain.
 Sora menukarnya kepada kesan video, menjadikan raksasa kecil ini menjadi hidup.
Sora menukarnya kepada kesan video, menjadikan raksasa kecil ini menjadi hidup.
Walaupun Mora juga membuat raksasa kecil itu bergerak, ia jelas sedikit tidak stabil, dan watak kartun dalam gambar tidak kelihatan konsisten. .
Tetapi dalam video yang dijana oleh Mora, penunggang basikal di hadapan berakhir dengan basikalnya hilang dan orang itu cacat, jadi kesannya tidak begitu baik.

Video ke Editor Video
memberikan gesaan "Tukar pemandangan kepada kereta vintaj dari tahun 1920-an" dan masukkan video.

Sora kelihatan sangat sutera selepas perubahan gaya.

Hasil ciptaan Mora sebuah kereta lama agak tidak realistik kerana keadaannya yang usang.

Splice Videos
Masukkan dua video dan kemudian selesaikan penyambungan. 

Video sambung Mora

Analog dunia digital

sedekat itu sejumlah besar demonstrasi, semua orang berpuas hati dengan video Mora Keupayaan untuk menjana Anda mesti faham.
Berbanding dengan OpenAI Sora, prestasi Mora dalam enam tugasan adalah sangat hampir, tetapi terdapat juga kelemahan besar.
Penjanaan teks-ke-video
Khususnya, skor kualiti video Mora 0.792 adalah kedua selepas tempat pertama Sora 0.797, dan melebihi model sumber terbuka terbaik semasa (selepas1).
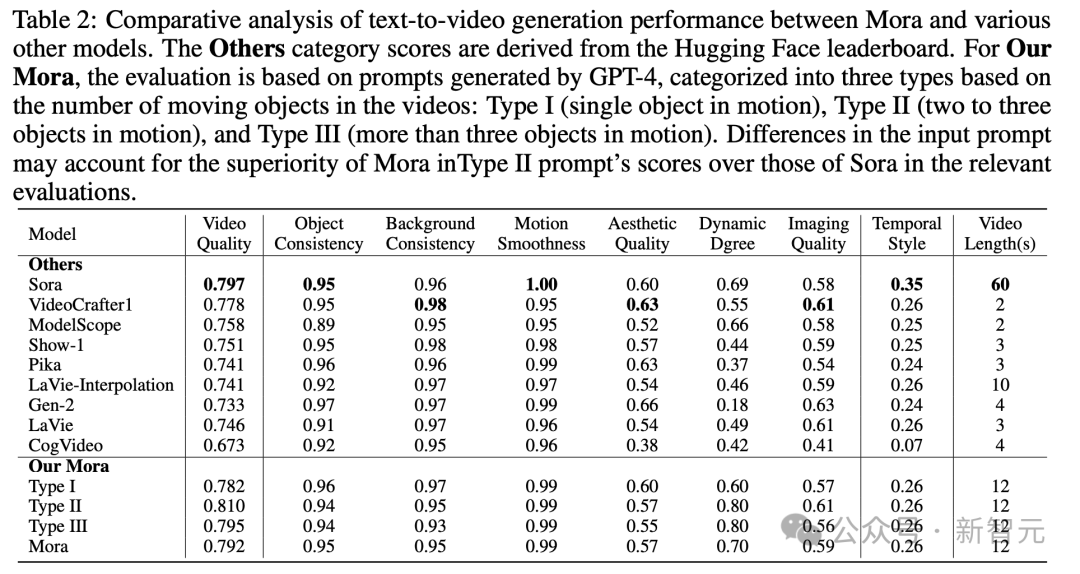 Dari segi konsistensi objek, Mora mendapat markah 0.95, iaitu sama dengan Sora, menunjukkan konsistensi yang sangat baik sepanjang video.
Dari segi konsistensi objek, Mora mendapat markah 0.95, iaitu sama dengan Sora, menunjukkan konsistensi yang sangat baik sepanjang video.
 Dalam imej di bawah, kesetiaan visual penjanaan teks-ke-video Mora sangat menarik, mencerminkan imej beresolusi tinggi dan perhatian yang mendalam terhadap perincian, dan gambaran adegan yang jelas.
Dalam imej di bawah, kesetiaan visual penjanaan teks-ke-video Mora sangat menarik, mencerminkan imej beresolusi tinggi dan perhatian yang mendalam terhadap perincian, dan gambaran adegan yang jelas.
Dalam tugas penjanaan imej berdasarkan keadaan teks, Sora pastinya model paling sempurna dalam keupayaannya untuk menukar gambar dan arahan teks kepada video yang koheren.
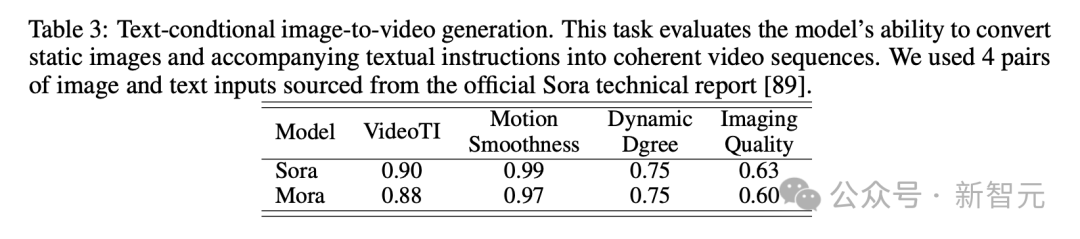 Namun, keputusan Mora sangat berbeza dengan Sora.
Namun, keputusan Mora sangat berbeza dengan Sora.
Video yang dijana sambungan
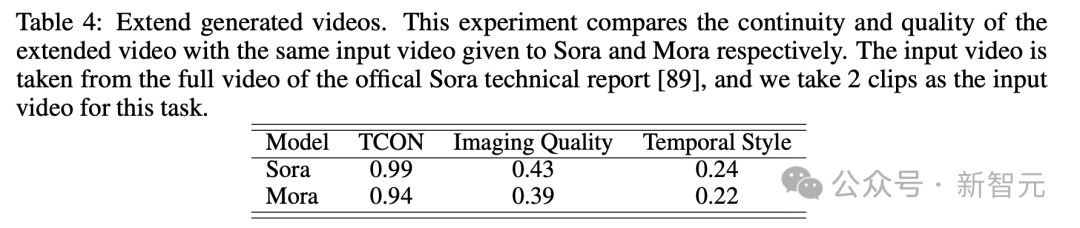 Melihat kepada ujian video yang dijana lanjutan, keputusan dari segi kesinambungan dan kualitinya juga hampir sama dengan Sora.
Melihat kepada ujian video yang dijana lanjutan, keputusan dari segi kesinambungan dan kualitinya juga hampir sama dengan Sora.
 Walaupun Sora mendahului, keupayaan Mora, terutamanya dalam mengikuti gaya masa dan melanjutkan video sedia ada tanpa kehilangan kualiti yang ketara, membuktikan keberkesanannya dalam bidang sambungan video.
Walaupun Sora mendahului, keupayaan Mora, terutamanya dalam mengikuti gaya masa dan melanjutkan video sedia ada tanpa kehilangan kualiti yang ketara, membuktikan keberkesanannya dalam bidang sambungan video.
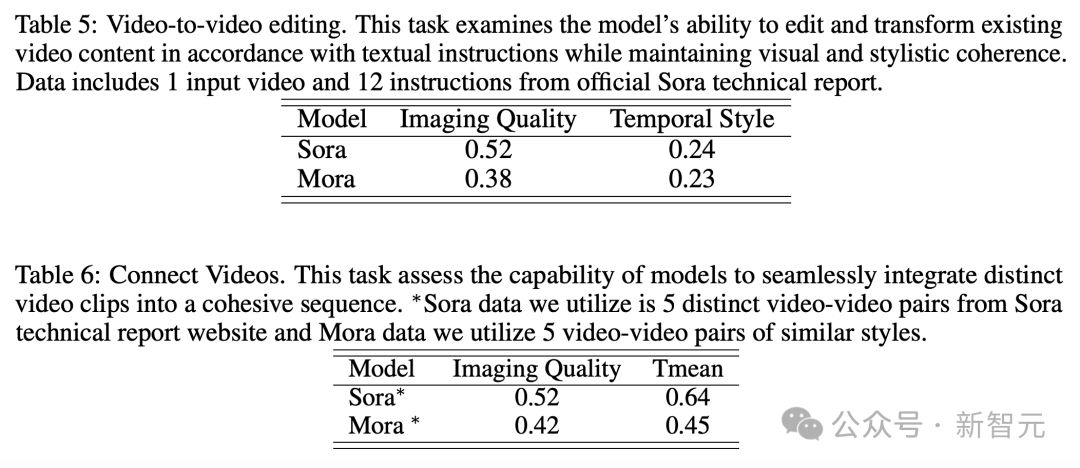
Penyuntingan Video ke Video + Jahitan Video


Mora: Penjanaan video berasaskan ejen
Bagaimana Mora, rangka kerja berbilang ejen, menyelesaikan batasan model penjanaan video semasa?


Dengan cekap menyelaraskan ejen yang mengendalikan tugas penukaran daripada teks kepada imej, imej kepada imej, imej kepada video dan video kepada video, Mora dapat mengendalikan pelbagai tugas penjanaan video yang kompleks, memberikan fleksibiliti penyuntingan yang Cemerlang dan realisme visual.
Ringkasnya, sumbangan utama pasukan adalah seperti berikut:
 - Rangka kerja pelbagai ejen yang inovatif, dan antara muka intuitif untuk memudahkan pengguna mengkonfigurasi komponen berbeza dan mengatur proses tugas.
- Rangka kerja pelbagai ejen yang inovatif, dan antara muka intuitif untuk memudahkan pengguna mengkonfigurasi komponen berbeza dan mengatur proses tugas.
- Penulis mendapati bahawa melalui kerja kolaboratif berbilang ejen (termasuk menukar teks kepada imej, imej kepada video, dll.), kualiti penjanaan video boleh dipertingkatkan dengan ketara. Proses ini bermula dengan teks, yang ditukar kepada imej, kemudian imej dan teks bersama-sama ditukar kepada video, dan akhirnya video dioptimumkan dan diedit.
- Mora menunjukkan prestasi unggul dalam 6 tugasan berkaitan video, mengatasi prestasi model sumber terbuka sedia ada. Ini bukan sahaja membuktikan kecekapan Mora, tetapi juga menunjukkan potensinya sebagai rangka kerja pelbagai guna.
Definisi Ejen
Dalam tugas penjanaan video yang berbeza, berbilang ejen dengan kepakaran berbeza biasanya diperlukan untuk bekerjasama, dengan setiap ejen menyediakan output dalam bidang kepakarannya.
Untuk tujuan ini, penulis mentakrifkan 5 jenis asas ejen: pemilihan dan penjanaan segera, penjanaan teks-ke-imej, penjanaan imej-ke-imej, penjanaan imej-ke-video dan penjanaan video-ke-video .
- Pemilihan Segera dan Ejen Penjanaan:
Sebelum mula menjana imej awal, gesaan teks melalui satu siri langkah pemprosesan dan pengoptimuman yang ketat. Ejen ini boleh memanfaatkan model bahasa yang besar (seperti GPT-4) untuk menganalisis teks dengan tepat, mengekstrak maklumat dan tindakan utama, serta meningkatkan perkaitan dan kualiti imej yang dijana dengan banyak.
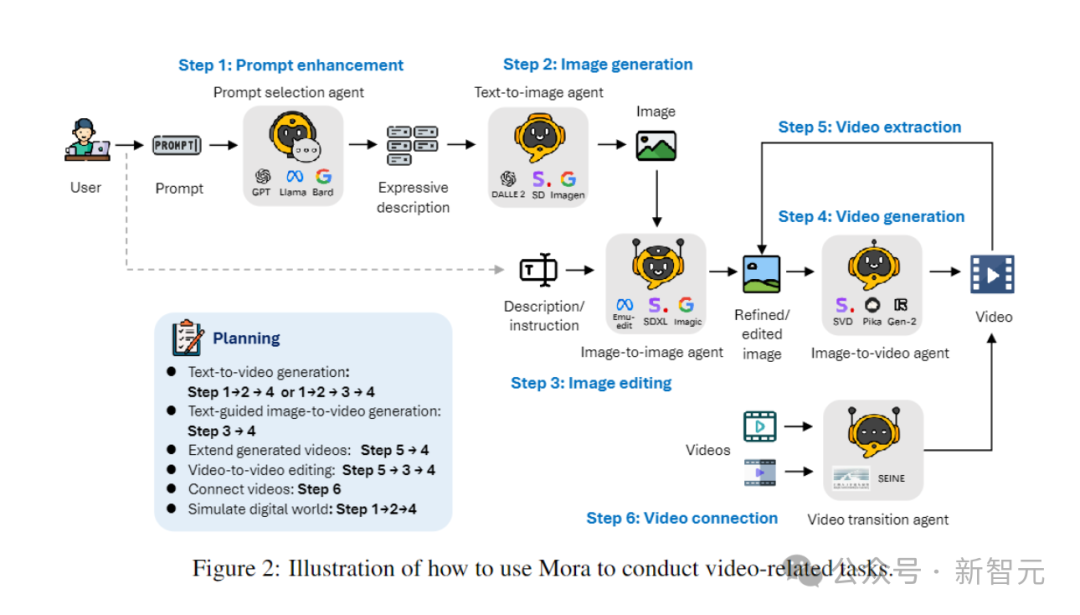 - Ejen Penjanaan Teks kepada Imej:
- Ejen Penjanaan Teks kepada Imej:
Ejen ini bertanggungjawab untuk menukar perihalan teks kaya kepada imej berkualiti tinggi. Fungsi terasnya adalah untuk memahami secara mendalam dan menggambarkan input teks yang kompleks, membolehkan penciptaan imej visual yang terperinci dan tepat berdasarkan huraian teks yang disediakan.
- Ejen penjanaan imej ke imej:
Ubah suai imej sumber sedia ada berdasarkan arahan teks tertentu. Ia mentafsir isyarat teks dengan tepat dan melaraskan imej sumber dengan sewajarnya, daripada pengubahsuaian halus kepada transformasi lengkap. Dengan menggunakan model pra-latihan, ia boleh menggabungkan penerangan teks dan perwakilan visual dengan berkesan, membolehkan penyepaduan elemen baharu, pelarasan kepada gaya visual atau perubahan dalam komposisi imej.
- Ejen penjanaan imej kepada video:
Selepas penjanaan imej awal, ejen ini bertanggungjawab untuk menukar imej statik kepada video dinamik. Ia menganalisis kandungan dan gaya imej awal untuk menjana bingkai seterusnya untuk memastikan keselarasan dan ketekalan visual video, menunjukkan keupayaan model untuk memahami, meniru imej awal, dan meramal serta melaksanakan perkembangan logik adegan.
- Ejen Penyambung Video:
Ejen ini memastikan peralihan yang lancar dan konsisten secara visual antara dua video dengan menggunakan bingkai utamanya secara terpilih. Ia mengenal pasti unsur dan gaya biasa dalam dua video dengan tepat, menghasilkan video yang koheren dan menarik secara visual.
Penjanaan teks-ke-imej
Para penyelidik menggunakan model teks-ke-imej berskala besar terlatih dan wakil untuk menjana imej berkualiti tinggi terlebih dahulu
Pelaksanaan pertama menggunakan Stable Diffusion XL.
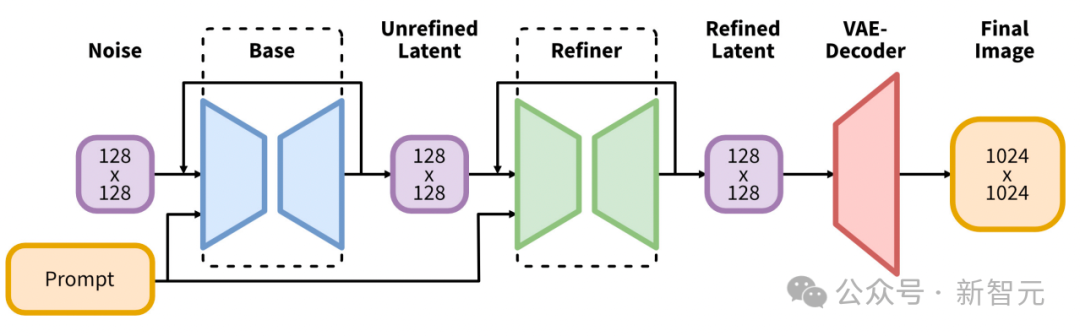
Ia memperkenalkan evolusi ketara dalam seni bina dan kaedah model resapan terpendam untuk sintesis teks-ke-imej, menetapkan penanda aras baharu dalam bidang tersebut.
Teras seni binanya ialah rangkaian tulang belakang UNet yang diperluas, yang tiga kali lebih besar daripada tulang belakang yang digunakan dalam versi Stable Diffusion 2 sebelumnya.
Peluasan ini dicapai terutamanya dengan meningkatkan bilangan blok perhatian dan julat konteks merentas perhatian yang lebih luas, dan dipermudahkan dengan menyepadukan sistem pengekod dwi teks.
Pengekod pertama adalah berdasarkan OpenCLIP ViT-bigG, manakala pengekod kedua memanfaatkan CLIP ViT-L, membolehkan tafsiran input teks yang lebih kaya dan bernuansa dengan menyambungkan output pengekod ini.

Inovasi seni bina ini dilengkapkan dengan pengenalan pelbagai skim pelaziman baru yang tidak memerlukan penyeliaan luaran, sekali gus meningkatkan fleksibiliti dan keupayaan model untuk menjana imej merentas pelbagai nisbah aspek.
Selain itu, SDXL menampilkan model penambahbaikan yang menggunakan transformasi imej-ke-imej post hoc untuk meningkatkan kualiti visual imej yang dijana.
Proses penghalusan ini menggunakan teknologi penyah bunyi untuk memperhalusi imej keluaran tanpa menjejaskan kecekapan atau kelajuan proses penjanaan.
Penjanaan imej-ke-imej
Dalam proses ini, penyelidik menggunakan rangka kerja awal untuk melaksanakan InstructPix2Pix sebagai ejen penjanaan imej-ke-imej.

InstructPix2Pix direka dengan teliti untuk penyuntingan imej yang berkesan berdasarkan arahan bahasa semula jadi.
Teras sistem menyepadukan pengetahuan luas dua model pra-latihan: GPT-3 untuk menjana arahan pengeditan dan tajuk yang disunting berdasarkan perihalan Stable Diffusion untuk menukar input berasaskan teks ini kepada output visual .
Pendekatan cerdik ini terlebih dahulu memperhalusi GPT-3 pada set data susun atur kapsyen imej dan arahan pengeditan yang sepadan, menghasilkan model yang boleh mencadangkan pengeditan yang wajar secara kreatif dan menjana kapsyen yang diubah suai.
Selepas ini, model Stable Diffusion yang dipertingkatkan oleh teknologi Prompt-to-Prompt menjana pasangan imej (sebelum dan selepas mengedit) berdasarkan sari kata yang dijana oleh GPT-3.
Kemudian latih model resapan bersyarat teras InstructPix2Pix pada set data yang dijana.
InstructPix2Pix secara langsung memanfaatkan arahan teks dan imej input untuk melakukan pengeditan dalam satu hantaran hadapan.
Kecekapan ini dipertingkatkan lagi dengan menggunakan panduan bebas pengelas untuk keadaan imej dan arahan, membolehkan model mengimbangi kesetiaan imej mentah dan pematuhan dengan arahan pengeditan.
Penjanaan imej ke video
Dalam ejen penjanaan teks ke video, ejen penjanaan video memainkan peranan penting dalam memastikan kualiti dan konsistensi video.
Pelaksanaan pertama penyelidik adalah menggunakan model penjanaan video SOTA semasa Stable Video Diffusion untuk menjana video.

Senibina SVD memanfaatkan kekuatan Stable Diffusion v2.1, LDM yang asalnya dibangunkan untuk sintesis imej, memperluaskan keupayaannya untuk mengendalikan kerumitan masa yang wujud dalam kandungan video, dengan itu memperkenalkan cara untuk menjana resolusi tinggi video kaedah lanjutan.
Inti model SVD mengikuti sistem latihan tiga peringkat, bermula daripada teks kepada korelasi imej, dan model mempelajari perwakilan visual yang mantap daripada set imej yang berbeza. Asas ini membolehkan model memahami dan menjana corak dan tekstur visual yang kompleks.
Pada peringkat kedua, pra-latihan video, model didedahkan kepada sejumlah besar data video, membolehkannya mempelajari dinamik temporal dan corak gerakan dengan menggabungkan lilitan temporal dan lapisan perhatian dengan rakan spatialnya.
Latihan dilakukan pada set data yang diuruskan sistem, memastikan model belajar daripada kandungan video yang berkualiti tinggi dan berkaitan.
Peringkat terakhir ialah penalaan halus video berkualiti tinggi, yang memfokuskan pada meningkatkan keupayaan model untuk menjana video dengan peleraian dan ketepatan yang lebih tinggi menggunakan set data yang lebih kecil tetapi berkualiti tinggi.
Strategi latihan berlapis ini, ditambah dengan proses pengurusan data yang baru, membolehkan SVD menghasilkan sintesis teks-ke-video dan imej-ke-video dengan perincian dan realisme yang luar biasa dari semasa ke semasa dan dengan cemerlang kesepaduan.
Menyambung video
Untuk tugasan ini, penyelidik menggunakan SEINE untuk menjahit video.
SEINE dibina berdasarkan ejen LaVie model T2V yang telah terlatih.
SEINE berpusat pada model penyebaran video bertopeng stokastik yang menjana peralihan berdasarkan penerangan teks.
Dengan menyepadukan imej adegan berbeza dengan kawalan berasaskan teks, SEINE boleh menjana video peralihan yang mengekalkan keselarasan dan kualiti visual.
Selain itu, model ini boleh diperluaskan kepada tugas seperti animasi imej-ke-video dan ramalan video regresi putih. . .
Ia bukan sahaja memudahkan proses menukar teks kepada video, tetapi juga mensimulasikan dunia digital, menunjukkan fleksibiliti dan kecekapan yang tidak pernah berlaku sebelum ini.Sifat sumber terbuka Mora adalah sumbangan penting kepada komuniti AI, meletakkan asas untuk penyelidikan masa depan dengan menyediakan asas kukuh yang menggalakkan pembangunan dan penambahbaikan selanjutnya.
Ini bukan sahaja menjadikan teknologi penjanaan video canggih lebih popular, tetapi juga menggalakkan kerjasama dan inovasi dalam bidang ini.
Limitation
- Data video adalah penting:
Merakam nuansa pergerakan manusia memerlukan jujukan video yang lancar dan resolusi tinggi. Ini membolehkan semua aspek dinamik ditunjukkan secara terperinci, termasuk keseimbangan, postur dan interaksi dengan persekitaran.
Tetapi set data video berkualiti tinggi kebanyakannya datang daripada sumber profesional seperti filem, rancangan TV dan rakaman permainan proprietari. Ia selalunya mengandungi bahan berhak cipta yang tidak mudah dikumpulkan atau digunakan secara sah.
- Perbezaan antara jisim dan panjang:
Walaupun Mora boleh menyelesaikan tugasan yang serupa dengan Sora, kualiti video yang dihasilkan jelas tidak tinggi dalam adegan yang melibatkan sejumlah besar objek bergerak, dan kualiti berkurangan apabila panjang video meningkat, terutamanya selepas melebihi 12 saat. - Keupayaan mengikut arahan: Walaupun Mora boleh memasukkan semua objek yang ditentukan oleh gesaan dalam video, adalah sukar untuk mentafsir dan memaparkan dinamik gerakan yang diterangkan dalam gesaan dengan tepat, seperti kelajuan pergerakan. Selain itu, Mora tidak boleh mengawal arah pergerakan objek seperti membuat objek bergerak ke kiri atau kanan. Penghadan ini terutamanya kerana penjanaan video Mora adalah berdasarkan kaedah imej ke video, dan bukannya mendapatkan arahan secara langsung daripada gesaan teks. - Penjajaran keutamaan manusia: Disebabkan kekurangan maklumat anotasi manusia dalam medan video, hasil percubaan mungkin tidak sentiasa mematuhi keutamaan visual manusia. Sebagai contoh, salah satu tugas penyambungan video di atas memerlukan penjanaan video peralihan seorang lelaki secara beransur-ansur berubah menjadi seorang wanita, yang kelihatan sangat tidak logik.
Atas ialah kandungan terperinci Sora bukan sumber terbuka, Microsoft akan membuka sumbernya untuk anda! Model video Sora yang paling dekat di dunia dilahirkan, dengan kesan yang realistik dan meletup dalam 12 saat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



