


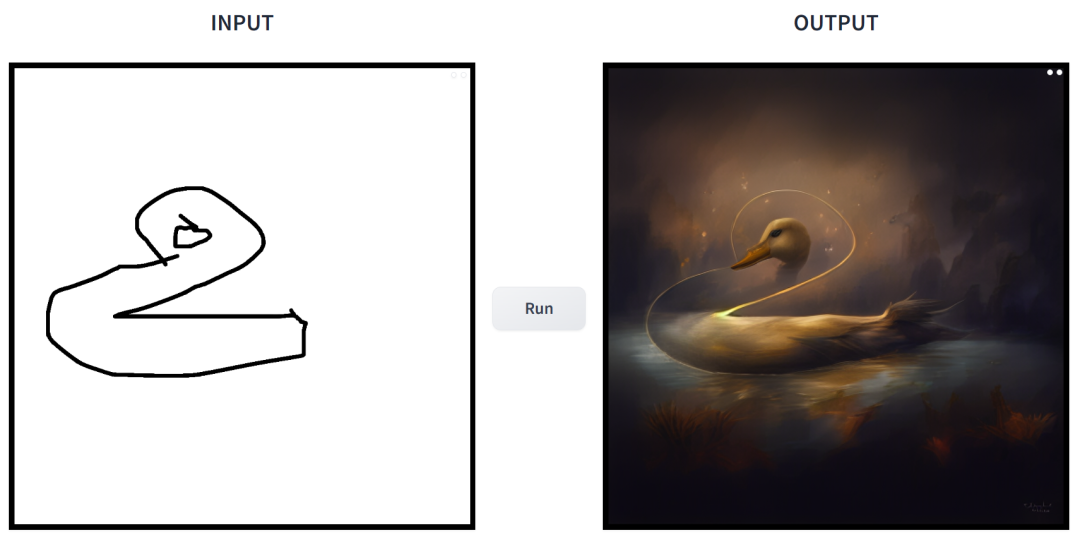
Lakaran ringkas boleh diubah menjadi lukisan pelbagai gaya dengan satu klik, dan penerangan tambahan boleh ditambah Ini dicapai dalam kajian yang dilancarkan bersama oleh CMU dan Adobe.
Penolong Profesor CMU Junyan Zhu ialah pengarang kajian itu dan pasukannya menerbitkan kajian berkaitan di persidangan ICCV 2021. Kajian ini menunjukkan bagaimana model GAN sedia ada boleh disesuaikan dengan satu atau beberapa lakaran lukisan tangan untuk menghasilkan imej yang sepadan dengan lakaran. .
 Alamat percubaan: https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
Alamat percubaan: https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
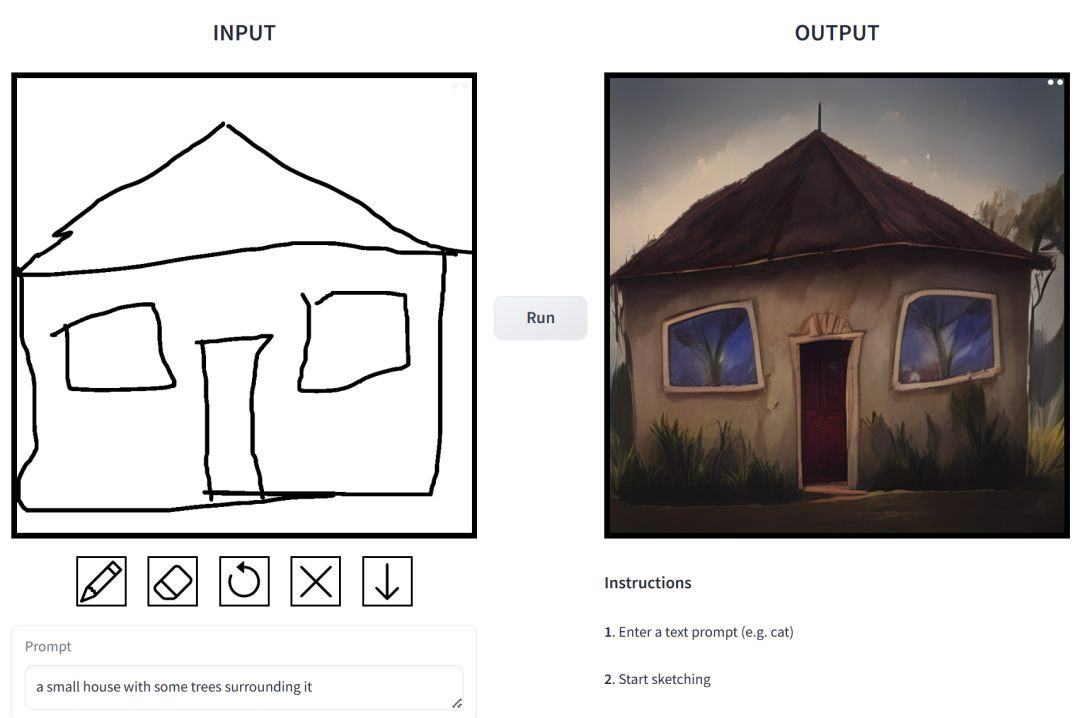
prompt ialah "sebuah rumah kecil yang dikelilingi oleh tumbuh-tumbuhan".
prompt ialah "budak-budak Cina bermain bola keranjang".
prompt ialah "Muscle Man Arnab". Dalam kerja ini, penyelidik membuat penambahbaikan yang disasarkan kepada masalah yang wujud dalam model resapan bersyarat dalam aplikasi sintesis imej. Model sedemikian membolehkan pengguna menjana imej berdasarkan keadaan spatial dan gesaan teks, dan mempunyai kawalan yang tepat ke atas reka letak pemandangan, lakaran pengguna dan pose manusia.
Tetapi masalahnya ialah lelaran model resapan menyebabkan kelajuan inferens menjadi perlahan, mengehadkan aplikasi masa nyata, seperti Sketch2Photo interaktif. Selain itu, latihan model biasanya memerlukan set data berpasangan berskala besar, yang membawa kos yang besar kepada banyak aplikasi dan tidak boleh dilaksanakan untuk beberapa aplikasi lain. 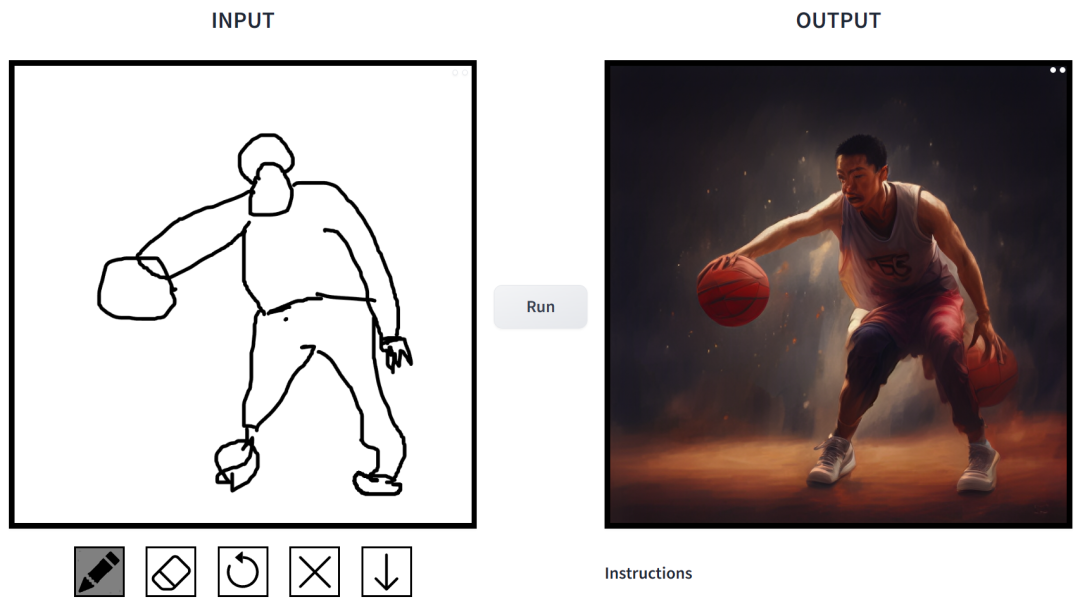
Untuk menyelesaikan masalah model resapan bersyarat, penyelidik telah memperkenalkan kaedah umum yang menggunakan objektif pembelajaran adversarial untuk menyesuaikan model resapan satu langkah kepada tugasan baharu dan bidang baharu. Khususnya, mereka menyepadukan modul individu model resapan terpendam vanila ke dalam rangkaian penjana hujung ke hujung tunggal dengan pemberat kecil yang boleh dilatih, dengan itu meningkatkan keupayaan model untuk mengekalkan struktur imej input sambil mengurangkan pemasangan berlebihan.
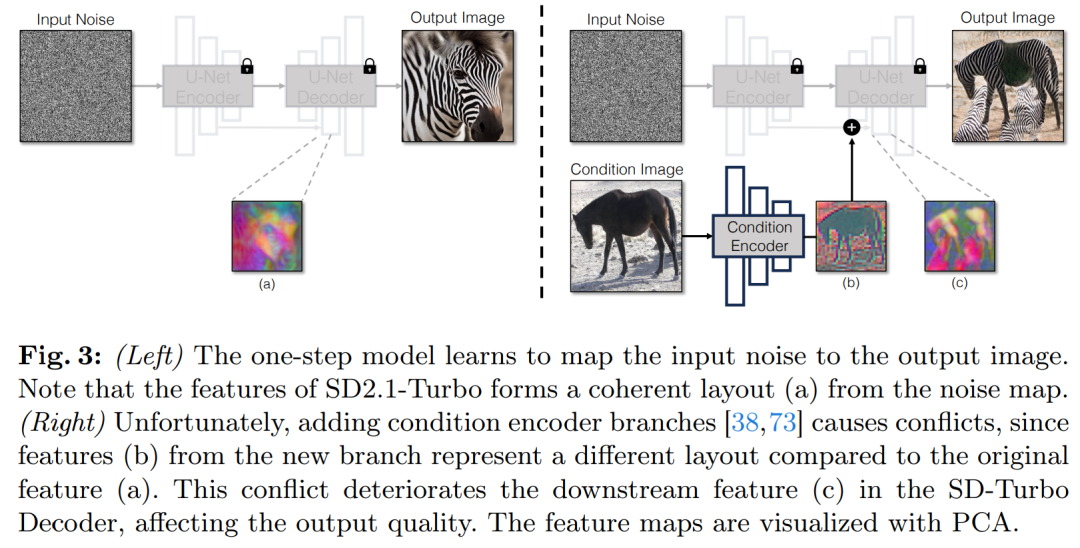
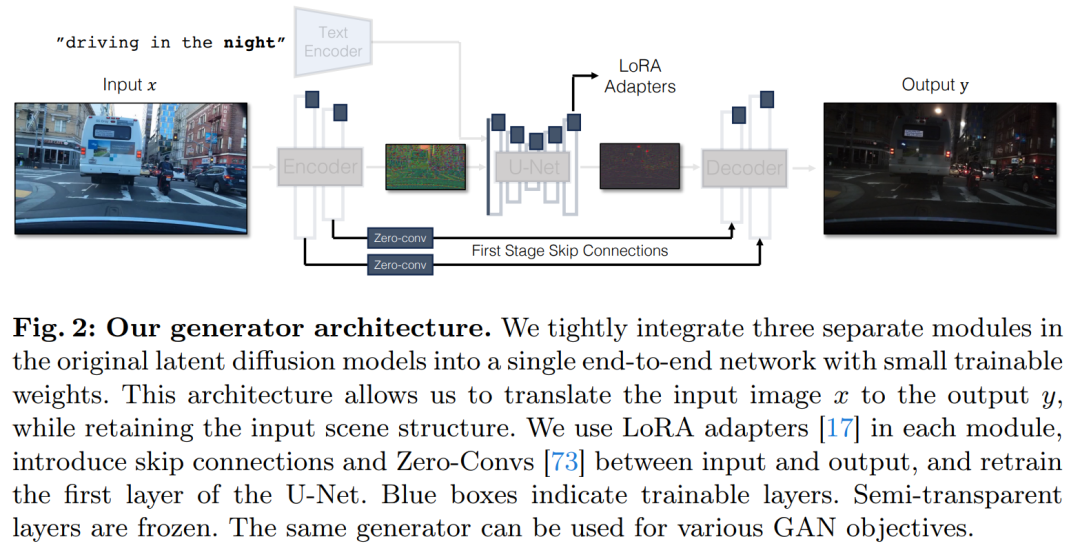
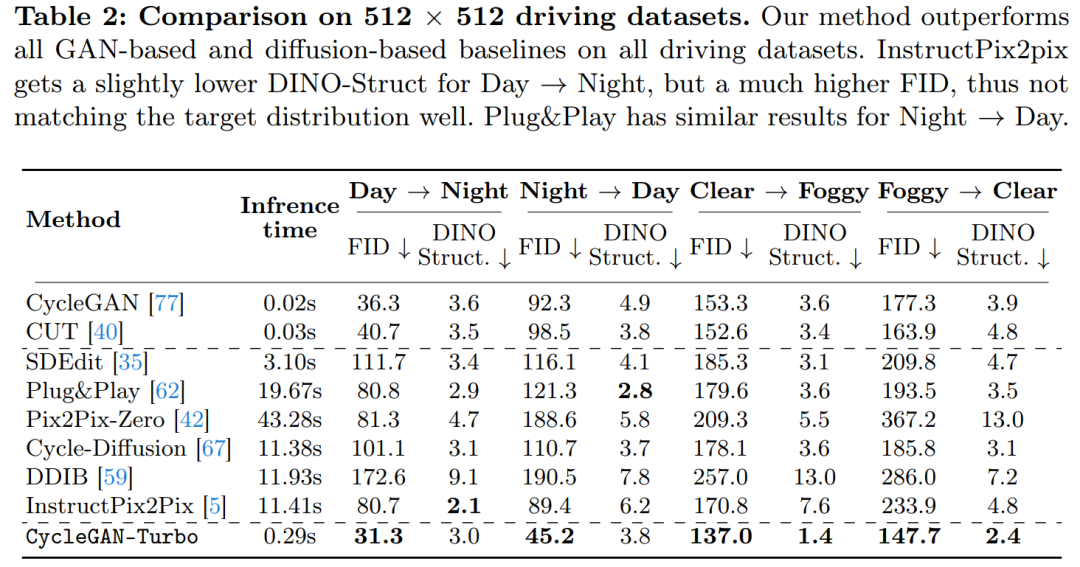
Penyelidik telah melancarkan model CycleGAN-Turbo, yang dalam tetapan tidak berpasangan boleh mengatasi GAN sedia ada dan kaedah berasaskan resapan dalam pelbagai tugas penukaran pemandangan, seperti penukaran siang dan malam, menambah atau mengalih keluar kabus dan salji Hujan dan cuaca lain kesan. Pada masa yang sama, untuk mengesahkan fleksibiliti seni bina mereka sendiri, para penyelidik menjalankan eksperimen pada tetapan berpasangan. Keputusan menunjukkan bahawa model pix2pix-Turbo mereka mencapai kesan visual yang setanding dengan Edge2Image dan Sketch2Photo, dan mengurangkan langkah inferens kepada 1 langkah. Ringkasnya, kerja ini menunjukkan bahawa model teks-ke-imej terlatih satu langkah boleh berfungsi sebagai tulang belakang yang berkuasa dan serba boleh untuk banyak tugas penjanaan imej hiliran. Kajian ini mencadangkan kaedah umum untuk menyesuaikan model penyebaran satu langkah (seperti SD-Turbo) kepada tugas dan domain baharu melalui pembelajaran lawan. Ini memanfaatkan pengetahuan dalaman model resapan terlatih sambil mendayakan inferens yang cekap (cth., 0.29 saat pada A6000 dan 0.11 saat pada A100 untuk imej 512x512). Selain itu, model bersyarat satu langkah CycleGAN-Turbo dan pix2pix-Turbo boleh melaksanakan pelbagai tugas terjemahan imej-ke-imej, sesuai untuk tetapan berpasangan dan bukan berpasangan. CycleGAN-Turbo mengatasi kaedah berasaskan GAN dan berasaskan penyebaran sedia ada, manakala pix2pix-Turbo adalah setanding dengan kerja terkini seperti ControlNet untuk Sketch2Photo dan Edge2Image, tetapi dengan kelebihan inferens satu langkah. Tambah input bersyarat Untuk menukar model teks kepada imej kepada model imej kepada imej, perkara pertama yang perlu dilakukan ialah mencari cara yang cekap untuk menggabungkan imej input x ke dalam model. Strategi biasa untuk memasukkan input bersyarat ke dalam model Difusi ialah memperkenalkan cawangan penyesuai tambahan, seperti yang ditunjukkan dalam Rajah 3. Secara khusus, kajian ini memulakan pengekod kedua dan melabelkannya sebagai Pengekod Keadaan. Pengekod Kawalan menerima imej input x dan mengeluarkan peta ciri berbilang resolusi kepada model Resapan Stabil yang telah terlatih melalui sambungan baki. Kaedah ini mencapai hasil yang luar biasa dalam mengawal model resapan. Seperti yang ditunjukkan dalam Rajah 3, kajian ini menggunakan dua pengekod (pengekod U-Net dan pengekod bersyarat) dalam model satu langkah untuk menangani cabaran yang dihadapi oleh imej bising dan imej input. Tidak seperti model resapan berbilang langkah, peta hingar dalam model satu langkah secara langsung mengawal susun atur dan pose imej yang dijana, yang sering bercanggah dengan struktur imej input. Oleh itu, penyahkod menerima dua set ciri baki yang mewakili struktur berbeza, yang menjadikan proses latihan lebih mencabar. Input bersyarat langsung. Rajah 3 juga menggambarkan bahawa struktur imej yang dijana oleh model pra-latihan dipengaruhi dengan ketara oleh peta hingar z. Berdasarkan cerapan ini, kajian mengesyorkan memasukkan input bersyarat terus ke rangkaian. Untuk menyesuaikan model tulang belakang kepada keadaan baharu, kajian itu menambah beberapa pemberat LoRA kepada pelbagai lapisan U-Net (lihat Rajah 2). Kekalkan butiran input Pengekod imej untuk Model Resapan Terpendam (LDM) mempercepatkan latihan model resapan dengan memampatkan resolusi spatial imej input daripada meningkatkan bilangan saluran dengan faktor 8 3 hingga 4. proses penaakulan. Walaupun reka bentuk ini boleh mempercepatkan latihan dan inferens, ia mungkin tidak sesuai untuk tugas penukaran imej yang memerlukan pemuliharaan butiran imej input. Rajah 4 menggambarkan masalah ini, di mana kami mengambil imej input pemanduan siang hari (kiri) dan menukarnya kepada imej yang sepadan memandu waktu malam, menggunakan seni bina yang tidak menggunakan sambungan langkau (tengah). Dapat diperhatikan bahawa butiran terperinci seperti teks, papan tanda jalan dan kereta yang jauh tidak disimpan. Sebaliknya, imej diubah yang terhasil menggunakan seni bina yang termasuk sambungan langkau (kanan) melakukan tugas yang lebih baik untuk mengekalkan butiran kompleks ini. Untuk menangkap butiran visual yang terperinci bagi imej input, kajian itu menambah sambungan langkau antara rangkaian pengekod dan penyahkod (lihat Rajah 2). Khususnya, kajian mengekstrak empat pengaktifan perantaraan selepas setiap blok pensampelan bawah dalam pengekod dan memprosesnya melalui lapisan konvolusi sifar 1 × 1, kemudian memasukkannya ke dalam blok pensampelan yang sepadan dalam penyahkod . Pendekatan ini memastikan bahawa butiran rumit dipelihara semasa penukaran imej. Kajian ini membandingkan CycleGAN-Turbo dengan kaedah transformasi imej bukan berpasangan berasaskan GAN sebelumnya. Daripada analisis kualitatif, Rajah 5 dan Rajah 6 menunjukkan bahawa kaedah berasaskan GAN mahupun kaedah berasaskan resapan tidak boleh mencapai keseimbangan antara realisme imej keluaran dan mengekalkan struktur. Kajian itu juga membandingkan CycleGAN-Turbo dengan CycleGAN dan CUT. Jadual 1 dan 2 membentangkan hasil perbandingan kuantitatif ke atas lapan tugas penukaran yang tidak berpasangan. . Kaedah kami sedikit mengatasi kaedah ini dalam metrik jarak FID dan DINO-Struktur. Pada set data pemacu, kaedah pengeditan ini menunjukkan prestasi yang lebih teruk kerana tiga sebab: (1) model mengalami kesukaran menjana pemandangan kompleks yang mengandungi berbilang objek, (2) kaedah ini (kecuali Arahan-pix2pix) perlu terlebih dahulu Imej itu diterbalikkan ke dalam peta hingar, memperkenalkan kemungkinan ralat manusia, dan (3) model pra-latihan tidak boleh mensintesis imej paparan jalan yang serupa dengan yang ditangkap oleh set data pemanduan. Jadual 2 dan Rajah 16 menunjukkan bahawa pada keempat-empat tugas peralihan memandu, kaedah ini mengeluarkan imej yang tidak berkualiti dan tidak mengikut struktur imej input. 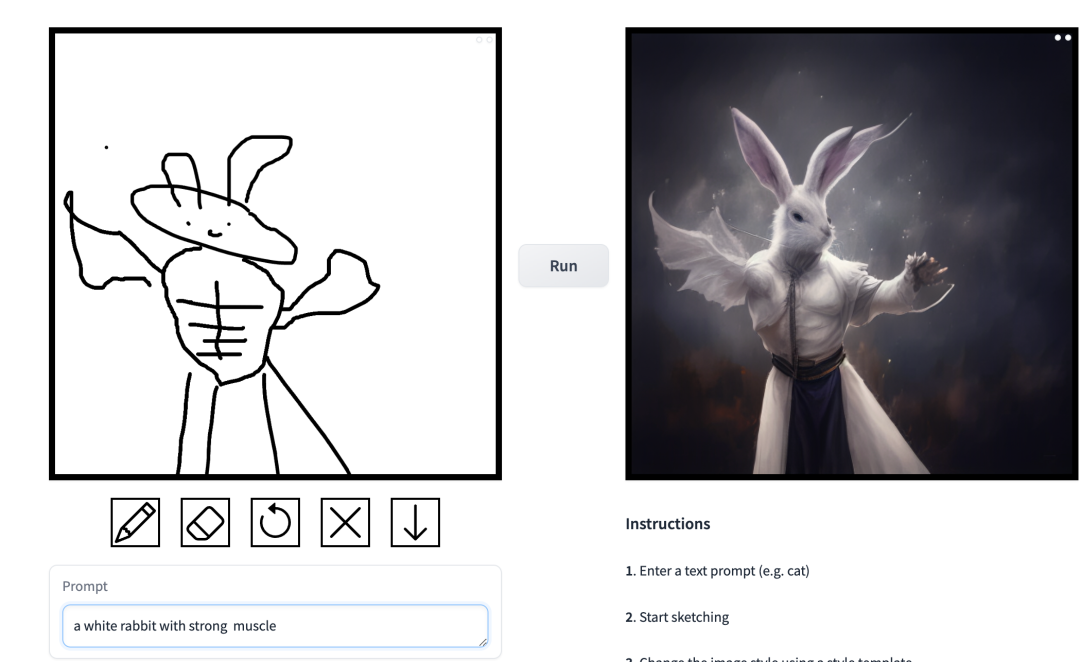
Pengenalan kaedah

Eksperimen


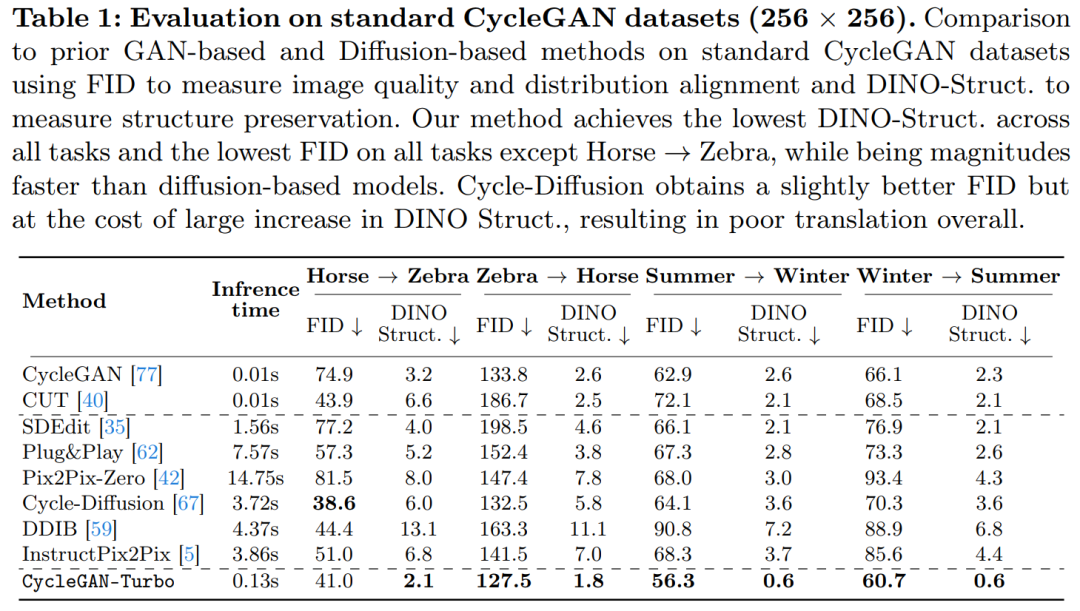
 Seperti yang ditunjukkan dalam Jadual 1 dan Rajah 14, pada set data berpusatkan objek (seperti kuda → zebra), kaedah ini boleh menjana zebra yang realistik, tetapi mengalami kesukaran padanan tepat.
Seperti yang ditunjukkan dalam Jadual 1 dan Rajah 14, pada set data berpusatkan objek (seperti kuda → zebra), kaedah ini boleh menjana zebra yang realistik, tetapi mengalami kesukaran padanan tepat. 
Atas ialah kandungan terperinci CMU Zhu Junyan dan kerja baharu Adobe: inferens imej 512x512, A100 hanya mengambil masa 0.11 saat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Urutan keutamaan pengendali dalam bahasa c
Urutan keutamaan pengendali dalam bahasa c
 Bagaimana untuk mematikan pusat keselamatan windows
Bagaimana untuk mematikan pusat keselamatan windows
 Bagaimana untuk mewakili nombor negatif dalam binari
Bagaimana untuk mewakili nombor negatif dalam binari
 Di manakah bilangan penonton dalam talian di stesen b?
Di manakah bilangan penonton dalam talian di stesen b?
 bios tidak dapat mengesan pemacu keadaan pepejal
bios tidak dapat mengesan pemacu keadaan pepejal
 bootmgr tiada dan tidak boleh boot
bootmgr tiada dan tidak boleh boot
 Bagaimana untuk menukar susun atur cad daripada putih kepada hitam
Bagaimana untuk menukar susun atur cad daripada putih kepada hitam
 arahan telnet
arahan telnet








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



