Google telah mengeluarkan rangka kerja video baharu:
Anda hanya memerlukangambar anda dan rakaman ucapan anda, dan anda boleh mendapatkanvideo seperti hidup ucapan anda.
Tempoh video berubah-ubah, dan contoh semasa yang dilihat adalah sehingga 10s.
Anda boleh lihat sama adabentuk mulut atau mimik muka, ia adalah sangat semula jadi.
Jika imej input meliputi seluruh bahagian atas badan, ia juga boleh digunakan dengan kayaisyarat:

Selepas membacanya, netizen berkata:
Dengannya, kita tidak perlu lagi menahannya. persidangan video dalam talian pada masa hadapan Selesaikan rambut anda dan berpakaian sebelum pergi.
Nah, ambil potret dan rakam audio pertuturan(kepala anjing manual)
Gunakan suara anda untuk mengawal potret untuk menjana video
Rangka kerja ini dipanggilVLOGGER
Ia terutamanya berdasarkan model resapan dan mengandungi dua bahagian:
Satu ialah model resapan manusia-ke-3d
(manusia-ke-3d-gerakan).
Yang lain ialah seni bina resapan baharu untuk mempertingkatkan model teks-ke-imej.
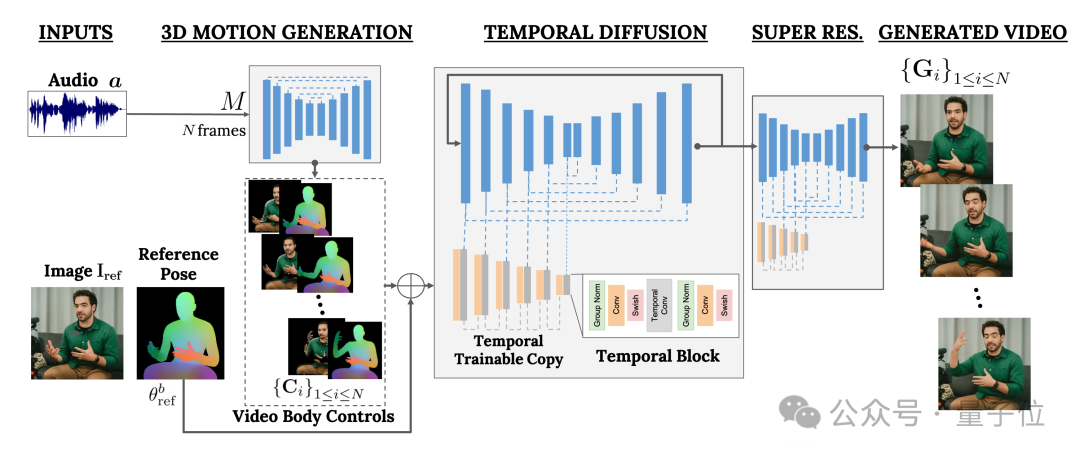
Antaranya, bekas bertanggungjawab menggunakan bentuk gelombang audio sebagai input untuk menjana tindakan kawalan badan watak, termasuk mata, ekspresi dan gerak isyarat, postur badan keseluruhan, dll.
Yang terakhir ialah model imej-ke-imej dimensi temporal yang digunakan untuk memanjangkan model resapan imej berskala besar dan menggunakan tindakan yang baru diramalkan untuk menjana bingkai yang sepadan.
Untuk menjadikan keputusan menepati imej watak tertentu, VLOGGER juga mengambil gambar rajah pose imej parameter sebagai input.
Latihan VLOGGER selesai pada set data yang sangat besar
(bernama MENTOR).
Berapa besarnya?
Ia berdurasi 2200 jam dan mengandungi 800,000 video aksara.
Antaranya, tempoh video set ujian juga adalah 120 jam, dengan jumlah 4,000 aksara.
Google memperkenalkan bahawa prestasi VLOGGER yang paling cemerlang ialah kepelbagaiannya:
Seperti yang ditunjukkan dalam gambar di bawah, semakin gelap
(merah)bahagian imej piksel akhir, semakin kaya tindakan.

Berbanding dengan kaedah sebelumnya yang serupa dalam industri, kelebihan terbesar VLOGGER ialah ia tidak perlu melatih semua orang, tidak bergantung pada pengesanan muka dan pemangkasan, dan video yang dihasilkan sangat lengkap
(termasuk muka dan bibir, termasuk pergerakan badan)dan sebagainya.

Khususnya, seperti yang ditunjukkan dalam jadual berikut:
Kaedah Pelakon Semula Wajah tidak boleh mengawal penjanaan video sedemikian dengan audio dan teks.
Audio-ke-gerakan boleh menjana audio dengan mengekod audio ke dalam pergerakan muka 3D, tetapi kesan yang dihasilkannya tidak cukup realistik.
Penyegerakan bibir boleh mengendalikan video dengan tema yang berbeza, tetapi ia hanya boleh mensimulasikan pergerakan mulut.
Sebagai perbandingan, dua kaedah terakhir, SadTaker dan Styletalk, berprestasi paling hampir dengan Google VLOGGER, tetapi mereka juga dikalahkan oleh ketidakupayaan untuk mengawal badan dan mengedit video lagi.

Bercakap tentang suntingan video, seperti dalam gambar di bawah, salah satu aplikasi model VLOGGER ialah ini boleh membuatkan watak diam, tutup mata, tutup mata kiri sahaja, atau buka seluruh mata dengan satu klik:

Aplikasi lain ialah terjemahan video:
Sebagai contoh, menukar pertuturan bahasa Inggeris dalam video asal kepada bahasa Sepanyol dengan bentuk mulut yang sama.
Netizen mengeluh
Akhirnya, mengikut "peraturan lama", Google tidak mengeluarkan model itu Sekarang yang kita boleh lihat adalah lebih banyak kesan dan kertas.
Nah, terdapat banyak aduan:
Kualiti imej model, penyegerakan bibir tidak sepadan, ia masih kelihatan sangat robotik, dll.
Oleh itu, sesetengah orang tidak teragak-agak untuk meninggalkan ulasan negatif:
Adakah ini tahap Google?

Saya agak kesal dengan nama "VLOGGER".

——Berbanding dengan Sora OpenAI, kenyataan netizen itu sememangnya tidak munasabah. .
Apa pendapat anda?
Lagi kesan:https://enriccorona.github.io/vlogger/
Kertas penuh:https://enriccorona.github.io/vlogger/paper.pdf
Atas ialah kandungan terperinci Google mengeluarkan model 'Vlogger': satu gambar menghasilkan video 10 saat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
































![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



