


Dalam bidang pemahaman video, walaupun model berbilang modal telah membuat kejayaan dalam analisis video pendek dan menunjukkan keupayaan pemahaman yang kukuh, mereka kelihatan tidak berkuasa apabila berhadapan dengan video panjang peringkat filem. Oleh itu, analisis dan pemahaman video panjang, terutamanya pemahaman kandungan filem berjam-jam, telah menjadi cabaran besar hari ini.
Kesukaran model dalam memahami video panjang terutamanya berpunca daripada kekurangan sumber data video yang panjang, yang mempunyai kecacatan dalam kualiti dan kepelbagaian. Selain itu, mengumpul dan melabelkan data ini memerlukan banyak kerja.
Menghadapi masalah sedemikian, pasukan penyelidik dari Tencent dan Universiti Fudan mencadangkanMovieLLM, rangka kerja penjanaan AI yang inovatif. MovieLLM mengguna pakai kaedah inovatif yang bukan sahaja menjana data video yang berkualiti tinggi dan pelbagai, tetapi juga secara automatik menjana sejumlah besar set data soal jawab yang berkaitan, memperkayakan dimensi dan kedalaman data, dan keseluruhan proses automatik juga sangat Dadi mengurangkan pelaburan manusia.

MovieLLM dengan bijak menggunakan keupayaan penjanaan berkuasa GPT-4 dan model resapan, dan menggunakan strategi penjanaan penerangan bingkai berterusan "mengembangkan cerita". Kaedah "penyongsangan tekstual" digunakan untuk membimbing model resapan untuk menghasilkan imej adegan yang konsisten dengan penerangan teks, dengan itu mencipta bingkai berterusan bagi filem lengkap.
 Gambaran Keseluruhan Kaedah
Gambaran Keseluruhan Kaedah
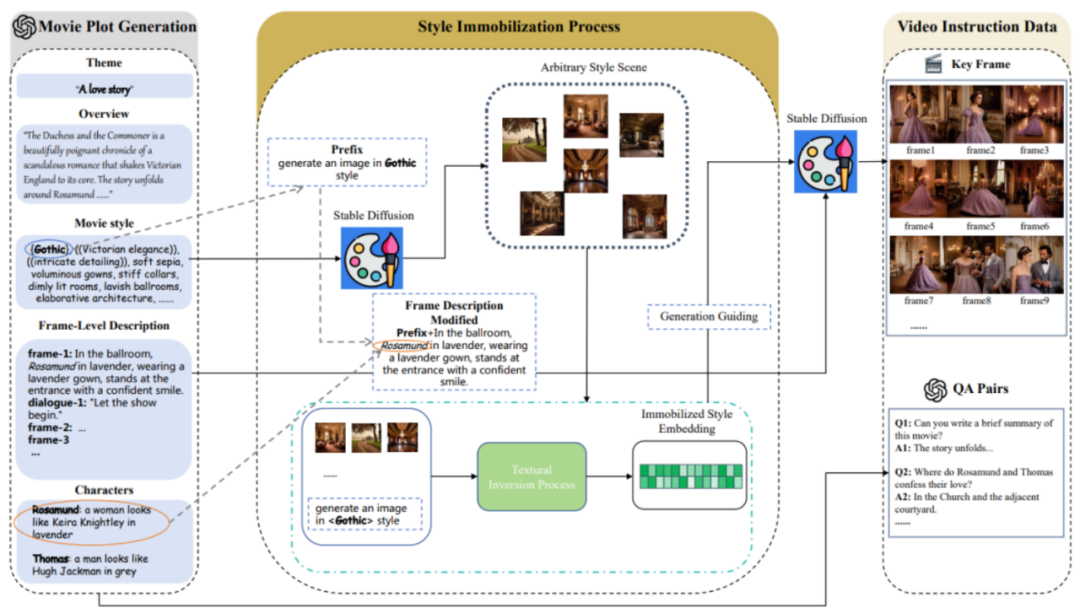 MovieLLM terutamanya merangkumi tiga peringkat:
MovieLLM terutamanya merangkumi tiga peringkat:
1.
MovieLLM tidak bergantung pada web atau set data sedia ada untuk menjana plot, sebaliknya memanfaatkan sepenuhnya kuasa GPT-4 untuk menghasilkan data sintetik. Dengan menyediakan elemen khusus seperti tema, gambaran keseluruhan dan gaya, GPT-4 dibimbing untuk menghasilkan perihalan rangka utama sinematik yang disesuaikan dengan proses penjanaan seterusnya.
2.
MovieLLM bijak menggunakan teknologi "inversi tekstual" untuk membetulkan perihalan gaya yang dijana dalam skrip ke ruang terpendam model resapan. Kaedah ini membimbing model untuk menghasilkan adegan dengan gaya tetap dan mengekalkan kepelbagaian sambil mengekalkan estetika bersatu.
3.
Berdasarkan dua langkah pertama, pembenaman gaya tetap dan penerangan rangka utama telah diperolehi. Berdasarkan ini, MovieLLM menggunakan pembenaman gaya untuk membimbing model resapan untuk menjana bingkai utama yang mematuhi huraian bingkai utama dan secara beransur-ansur menjana pelbagai pasangan soalan dan jawapan pengajaran mengikut plot filem.
 Selepas langkah di atas, MovieLLM mencipta gaya yang berkualiti tinggi, pelbagai, bingkai filem yang koheren dan data pasangan soalan dan jawapan yang sepadan. Pengedaran terperinci jenis data filem adalah seperti berikut:
Selepas langkah di atas, MovieLLM mencipta gaya yang berkualiti tinggi, pelbagai, bingkai filem yang koheren dan data pasangan soalan dan jawapan yang sepadan. Pengedaran terperinci jenis data filem adalah seperti berikut:
Dengan menggunakan data yang dibina berdasarkan MovieLLM untuk penalaan halus pada LLaMA-VID, model besar yang memfokuskan pada pemahaman video yang panjang, kertas kerja ini meningkatkan keupayaan model untuk memahami kandungan video pelbagai panjang dengan ketara. Untuk pemahaman video yang panjang, pada masa ini tiada kerja yang mencadangkan penanda aras ujian, jadi artikel ini juga mencadangkan penanda aras untuk menguji keupayaan pemahaman video yang panjang.
Walaupun MovieLLM tidak secara khusus membina data video pendek untuk latihan, melalui latihan, peningkatan prestasi pada pelbagai penanda aras video pendek masih diperhatikan:
Dalam MSVD-QA dan MSRVTT- Berbanding dengan. model asas, QA telah bertambah baik dengan ketara pada kedua-dua set data ujian ini.

Pada penanda aras prestasi berasaskan penjanaan video, peningkatan prestasi dicapai dalam kelima-lima bidang penilaian.
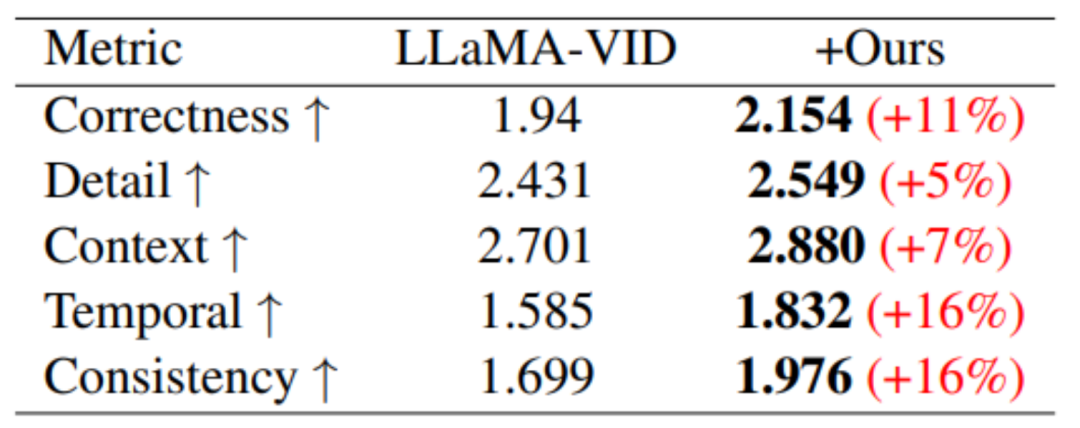
Dari segi pemahaman video yang panjang, melalui latihan MovieLLM, pemahaman model tentang ringkasan, plot dan pemasaan telah dipertingkatkan dengan ketara.

Selain itu, MovieLLM juga mempunyai hasil yang lebih baik dari segi kualiti penjanaan berbanding kaedah penjanaan imej gaya tetap yang serupa.
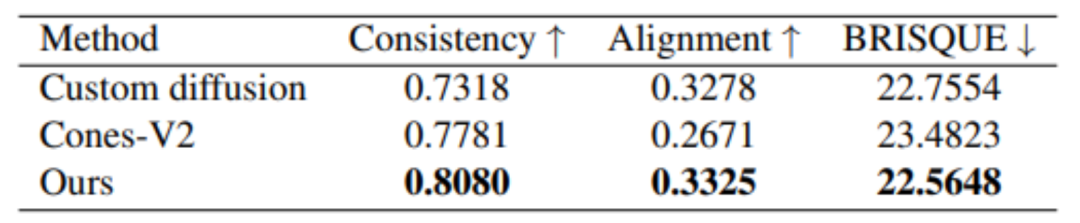
Ringkasnya, aliran kerja penjanaan data yang dicadangkan oleh MovieLLM mengurangkan dengan ketara cabaran untuk menghasilkan data video peringkat filem untuk model dan meningkatkan kawalan dan kepelbagaian kandungan yang dijana. Pada masa yang sama, MovieLLM dengan ketara meningkatkan keupayaan model berbilang modal untuk memahami video panjang peringkat filem, memberikan rujukan berharga untuk bidang lain untuk menggunakan kaedah penjanaan data yang serupa.
Pembaca yang berminat dengan penyelidikan ini boleh membaca teks asal kertas untuk mengetahui lebih lanjut tentang kandungan penyelidikan.
Atas ialah kandungan terperinci Menggunakan video pendek AI untuk 'memberi maklum balas' pemahaman video yang panjang, rangka kerja MovieLLM Tencent menyasarkan penjanaan bingkai berterusan peringkat filem. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur Pengenalan kepada rangka kerja yang digunakan oleh vscode
Pengenalan kepada rangka kerja yang digunakan oleh vscode Perbezaan antara UCOS dan linux
Perbezaan antara UCOS dan linux Apakah pernyataan kemas kini mysql?
Apakah pernyataan kemas kini mysql? Bagaimana untuk mengalih keluar orang daripada senarai hitam di WeChat
Bagaimana untuk mengalih keluar orang daripada senarai hitam di WeChat Bagaimana untuk menetapkan pembalut baris automatik dalam perkataan
Bagaimana untuk menetapkan pembalut baris automatik dalam perkataan Apakah unsur li?
Apakah unsur li? Apakah teknologi utama firewall?
Apakah teknologi utama firewall?



















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



