Dalam perkembangan semasa model dialog pintar, model asas yang berkuasa memainkan peranan yang penting. Pra-latihan model termaju ini sering bergantung pada korpora yang berkualiti tinggi dan pelbagai, dan cara membina korpus sedemikian telah menjadi cabaran utama dalam industri. Dalam bidang berprofil tinggi AI untuk Matematik, kekurangan relatif korpus matematik berkualiti tinggi mengehadkan potensi kecerdasan buatan generatif dalam aplikasi matematik. Untuk menangani cabaran ini, Makmal Kepintaran Buatan Generatif Universiti Jiao Tong Shanghai melancarkan "MathPile". Ini ialah korpus pra-latihan berkualiti tinggi dan pelbagai yang disasarkan khusus pada bidang matematik, yang mengandungi kira-kira 9.5 bilion token dan direka bentuk untuk meningkatkan keupayaan model besar dalam penaakulan matematik. Selain itu, makmal juga melancarkan versi komersial MathPile - "MathPile_Commercial" untuk meluaskan lagi skop aplikasi dan potensi komersialnya. 
Penggunaan penyelidikan: https://huggingface.co/datasets- GAIR versi: https://huggingface.co/datasets/GAIR/MathPile_Commercial
mempunyai ciri-ciri berikut:
MathPile 1.
: Tidak seperti korpora yang memfokuskan pada bidang umum pada masa lalu, seperti Pile, RedPajama, atau korpus berbilang bahasa ROOTS, dsb., MathPile memfokuskan pada bidang matematik. Walaupun sudah ada beberapa korpora matematik khusus, ia sama ada bukan sumber terbuka (seperti korpus yang digunakan oleh Google untuk melatih Minerva, MathMix OpenAI), atau tidak cukup kaya dan pelbagai (seperti ProofPile dan OpenWebMath baru-baru ini).
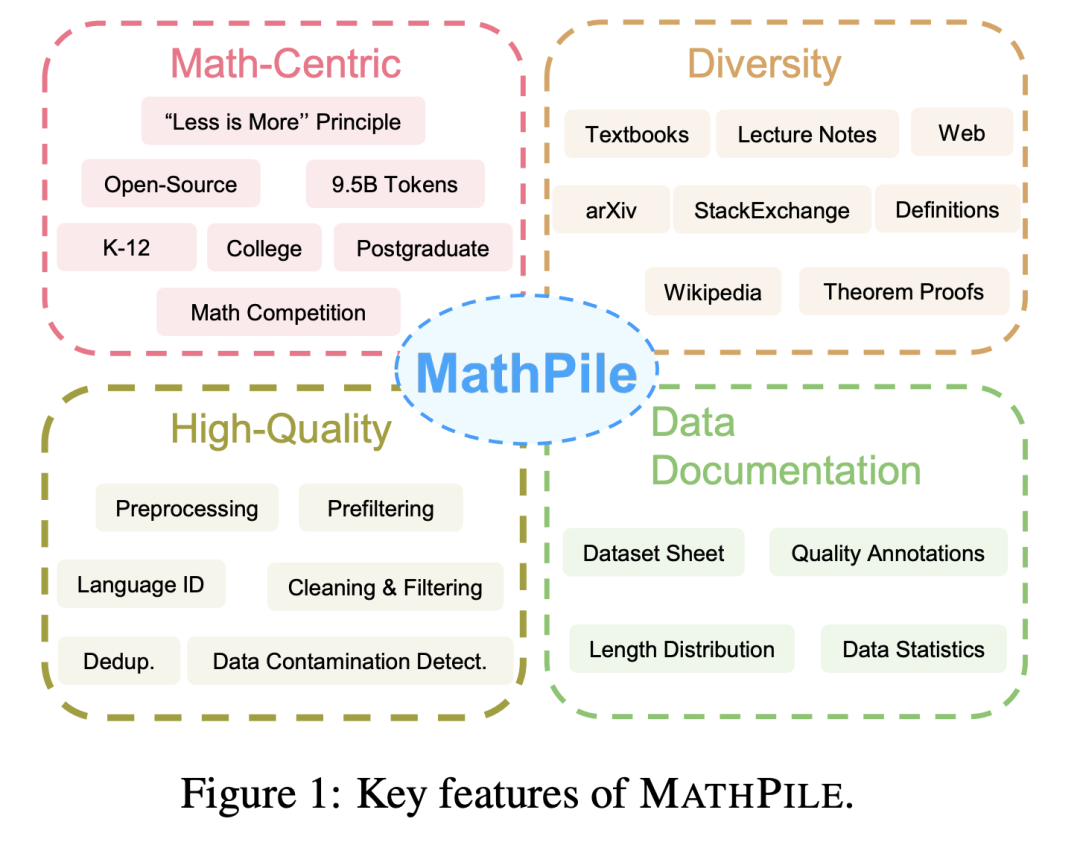
: MathPile mempunyai pelbagai sumber data, seperti buku teks matematik sumber terbuka, nota kelas, buku teks sintetik, kertas berkaitan matematik di arXiv, entri berkaitan matematik di Wikipedia, dan ProofWiki. bukti dan definisi untuk , soalan dan jawapan matematik berkualiti tinggi di StackExchange, tapak Soal Jawab komuniti dan halaman web matematik daripada Common Crawl. Kandungan di atas meliputi kandungan yang sesuai untuk sekolah rendah dan menengah, universiti, pelajar siswazah, dan pertandingan matematik. MathPile merangkumi 0.19B token buku teks matematik berkualiti tinggi buat kali pertama.
: Pasukan penyelidik mengikut konsep "kurang adalah lebih" semasa proses pengumpulan dan yakin bahawa kualiti data adalah lebih baik daripada kuantiti, walaupun dalam peringkat pra-latihan. Daripada sumber data ~520B token (kira-kira 2.2TB), mereka melalui set pra-pemprosesan, pra-penapisan, pengenalan bahasa, pembersihan, penapisan dan deduplikasi yang ketat dan kompleks untuk memastikan kualiti tinggi korpus. Perlu dinyatakan bahawa MathMix yang digunakan oleh OpenAI hanya mempunyai 1.5B token.
: Untuk meningkatkan ketelusan, pasukan penyelidik mendokumentasikan MathPile dan menyediakan helaian set data. Semasa proses pemprosesan data, pasukan penyelidik juga melakukan "anotasi kualiti" pada dokumen dari Web. Sebagai contoh, skor pengecaman bahasa dan nisbah simbol kepada perkataan dalam dokumen membolehkan penyelidik menapis lagi dokumen mengikut keperluan mereka sendiri. Mereka juga melakukan pengesanan pencemaran set ujian hiliran pada korpus untuk menghapuskan sampel daripada set ujian penanda aras seperti MATH dan MMLU-STEM. Pada masa yang sama, pasukan penyelidik juga mendapati bahawa terdapat juga sejumlah besar sampel ujian hiliran dalam OpenWebMath, yang menunjukkan bahawa penjagaan tambahan harus diambil apabila menghasilkan korpus pra-latihan untuk mengelakkan penilaian hiliran yang tidak sah.
proses pengumpulan dan pemprosesan data MathPile.
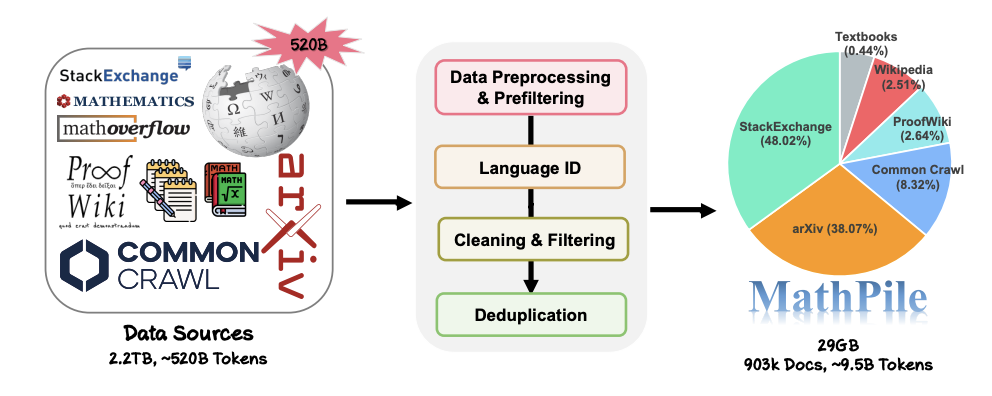
Hari ini, apabila persaingan dalam bidang model besar semakin sengit, banyak syarikat teknologi tidak lagi mendedahkan data mereka, serta sumber dan nisbah data mereka, apatah lagi butiran pra-pemprosesan yang terperinci. Sebaliknya, MathPile meringkaskan satu set kaedah pemprosesan data yang sesuai untuk medan Matematik berdasarkan penerokaan sebelumnya. Dalam bahagian pembersihan dan penapisan data, langkah khusus yang diguna pakai oleh pasukan penyelidik ialah:
- Kesan baris yang mengandungi "lorem ipsum" jika "lorem ipsum" digantikan dengan kurang baris daripada 5 aksara, baris akan dialih keluar;
- mengesan baris yang mengandungi "javescript" dan juga mengandungi "dayakan", "lumpuhkan" atau "pelayar", dan bilangan aksara dalam baris itu kurang daripada 200 aksara, kemudian tapis baris Baris;
- Tapis keluar baris dengan kurang daripada 10 perkataan dan mengandungi "Log masuk", "log masuk", "baca lagi..." atau "item dalam troli"; keluar perkataan huruf besar Dokumen yang merangkumi lebih daripada 40%; lebih daripada 80%; menjadi, kepada, daripada, dan, itu, mempunyai, dsb. );
- Tapis dokumen yang nisbah elips kepada perkataan melebihi 50%
- Tapis dokumen di mana garisan bermula dengan peluru melebihi 50%; 90%;
- Tapis dan alih keluar ruang dan Dokumen dengan kurang daripada 200 aksara selepas tanda baca
boleh didapati dalam butiran kertas
- Selain itu, pasukan penyelidik juga menyediakan banyak sampel data semasa proses pembersihan. Gambar di bawah menunjukkan dokumen hampir pendua dalam Common Crawl yang dikesan oleh algoritma MinHash LSH (ditunjukkan dalam sorotan merah jambu).
- Seperti yang ditunjukkan dalam rajah di bawah, pasukan penyelidik menemui masalah daripada set ujian MATH (seperti yang diserlahkan dalam warna kuning) semasa proses pengesanan kebocoran data.
Perangkaan dan Contoh Set Data
Jadual berikut menunjukkan maklumat statistik bagi setiap komponen MathPile Anda boleh mendapati bahawa kertas arXiv dan buku teks biasanya mempunyai panjang dokumen yang agak pendek, manakala dokumen wiki yang agak pendek. .
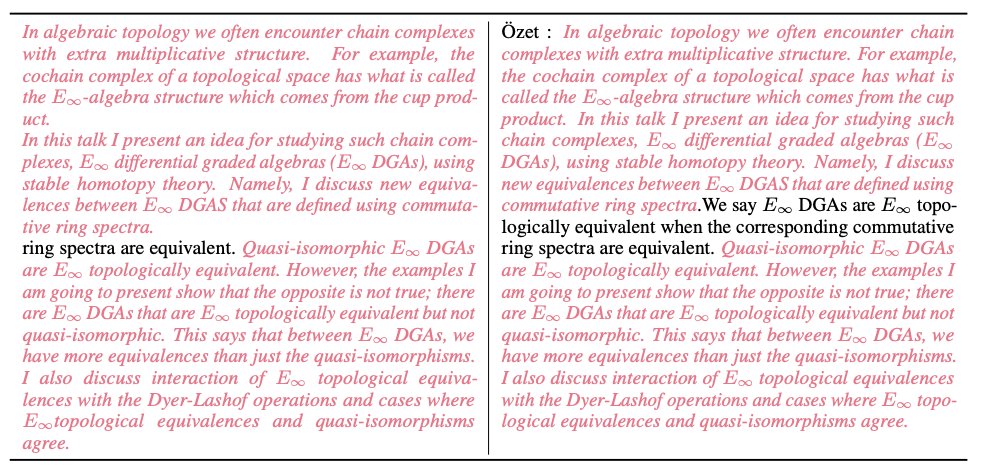 Gambar di bawah adalah contoh dokumen buku teks dalam korpus MathPile Dapat dilihat struktur dokumennya agak jelas dan kualitinya tinggi.
Gambar di bawah adalah contoh dokumen buku teks dalam korpus MathPile Dapat dilihat struktur dokumennya agak jelas dan kualitinya tinggi.

Hasil eksperimen
Pasukan penyelidik juga mendedahkan beberapa keputusan percubaan awal. Mereka melakukan latihan pra lanjut berdasarkan model Mistral-7B yang popular pada masa ini. Kemudian, ia dinilai pada beberapa set data tanda aras penaakulan matematik biasa melalui kaedah gesaan beberapa pukulan. Data percubaan awal yang telah diperolehi setakat ini adalah seperti berikut: Tanda aras ujian ini merangkumi semua peringkat pengetahuan matematik, termasuk matematik sekolah rendah (seperti GSM8K, TAL-SCQ5K-EN dan MMLU-Math), tinggi matematik sekolah (seperti MATH, SAT -Math, MMLU-Math, AQuA, dan MathQA), dan matematik kolej (cth., MMLU-Math). Keputusan percubaan awal yang diumumkan oleh pasukan penyelidik menunjukkan bahawa dengan meneruskan pra-latihan tentang buku teks dan subset Wikipedia dalam MathPile, model bahasa telah mencapai peningkatan yang ketara dalam keupayaan penaakulan matematik pada tahap kesukaran yang berbeza. Pasukan penyelidik juga menekankan bahawa eksperimen yang berkaitan masih diteruskan. 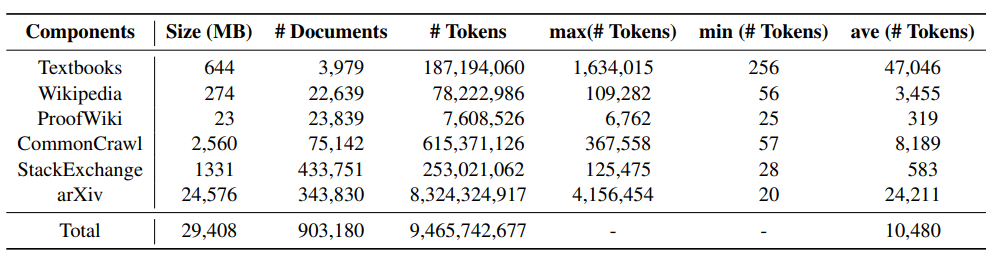
KesimpulanMathPile telah mendapat perhatian meluas sejak dikeluarkan dan telah dicetak semula oleh banyak pihak pada masa ini dalam senarai trend Set Data Huggingface. Pasukan penyelidik menyatakan bahawa mereka akan terus mengoptimumkan dan menaik taraf set data untuk meningkatkan lagi kualiti data. 
MathPile berada dalam senarai sohor kini Set Data Huggingface.  MathPile dimajukan oleh blogger AI terkenal AK, sumber: https://twitter.com/_akhaliq/status/1740571256234057798.
MathPile dimajukan oleh blogger AI terkenal AK, sumber: https://twitter.com/_akhaliq/status/1740571256234057798.
Pada masa ini, MathPile telah dikemas kini kepada versi kedua, bertujuan untuk menyumbang kepada penyelidikan dan pembangunan komuniti sumber terbuka. Pada masa yang sama, versi komersial set datanya juga telah dibuka kepada orang ramai. Atas ialah kandungan terperinci Untuk menambah matematik bagi model besar, serahkan korpus MathPile sumber terbuka dengan 9.5 bilion token, yang juga boleh digunakan secara komersial. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Pertanyaan masa Internet
Pertanyaan masa Internet
 Bagaimana untuk membaca data dalam fail excel dalam python
Bagaimana untuk membaca data dalam fail excel dalam python
 Bagaimana untuk menyelesaikan masalah bahawa folder tidak mempunyai pilihan keselamatan
Bagaimana untuk menyelesaikan masalah bahawa folder tidak mempunyai pilihan keselamatan
 pengendalian pengecualian java
pengendalian pengecualian java
 Bagaimana untuk memadam alamat WeChat saya
Bagaimana untuk memadam alamat WeChat saya
 Berapakah kos untuk menggantikan bateri telefon bimbit Apple?
Berapakah kos untuk menggantikan bateri telefon bimbit Apple?
 Bagaimana untuk menetapkan vlanid
Bagaimana untuk menetapkan vlanid
 Mengapa Windows tidak boleh mengakses laluan peranti atau fail yang ditentukan
Mengapa Windows tidak boleh mengakses laluan peranti atau fail yang ditentukan





















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



