


Beberapa masa lalu, kursus AI dalam talian master Karpathy AI telah menerima 150,000 tontonan merentas seluruh rangkaian.
Ketika itu, ada netizen yang mengatakan bahawa nilai kursus 2 jam ini bersamaan dengan 4 tahun kolej.
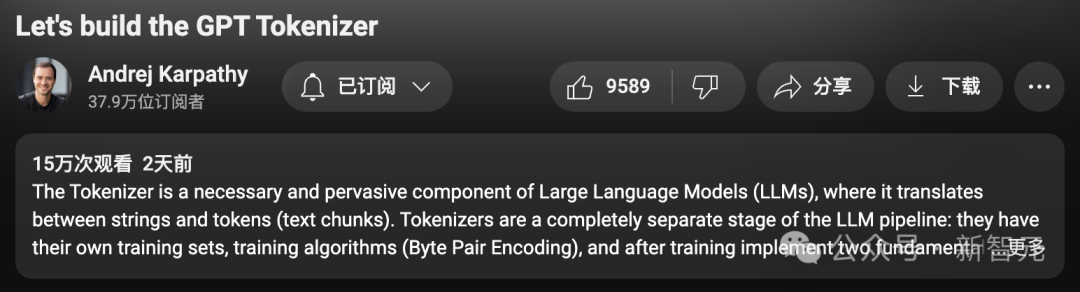
Hanya dalam beberapa hari yang lalu, Karpathy mendapat idea baharu:
Tukar 2 jam 13 minit kandungan video "Membina Tokenizer GPT dari Scratch" menjadi bab buku atau kandungan blog Bentuk artikel memfokuskan kepada topik "pembahagian perkataan".
Langkah khusus adalah seperti berikut:
- Tambahkan sari kata atau teks narasi pada video.
- Potong video kepada beberapa perenggan dengan gambar dan teks yang sepadan.
- Gunakan teknologi kejuruteraan pantas model bahasa besar untuk menterjemah perenggan demi perenggan.
- Keluarkan hasil sebagai halaman web dengan pautan ke bahagian video asal.
Secara lebih meluas, aliran kerja sedemikian boleh digunakan pada mana-mana input video, secara automatik menjana "panduan sokongan" untuk pelbagai tutorial dalam format yang lebih mudah dibaca, disemak dan dicari.
Kedengarannya boleh dilakukan, tetapi juga agak mencabar.
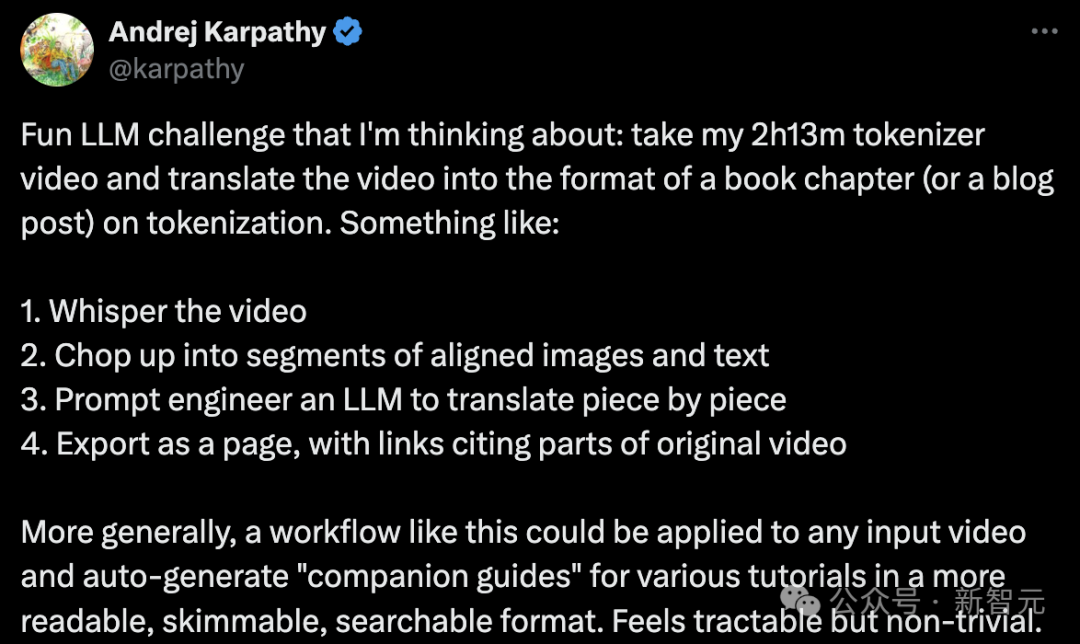
Dia menulis contoh untuk menggambarkan imaginasinya di bawah projek GitHub minbpe.
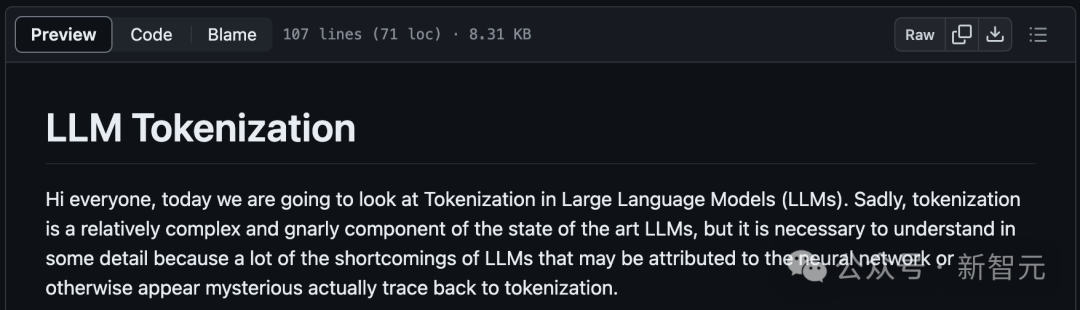
Alamat: https://github.com/karpathy/minbpe/blob/master/lecture.md
Karpathy berkata bahawa ini adalah tugas manual, iaitu menonton video dan menterjemahkannya Artikel dalam format markdown.
"Saya hanya menonton kira-kira 4 minit video (iaitu 3% selesai), dan ini telah mengambil masa saya kira-kira 30 minit untuk menulis, jadi alangkah baiknya jika sesuatu seperti ini dapat dilakukan secara automatik."
Seterusnya, masa kelas!
Salam semua, hari ini kita akan membincangkan isu "segmentasi perkataan" dalam LLM.
Malangnya, "segmentasi perkataan" adalah komponen yang agak kompleks dan rumit bagi model besar yang paling maju, tetapi kita perlu memahaminya secara terperinci.
Oleh kerana banyak kecacatan LLM mungkin dikaitkan dengan rangkaian saraf atau faktor lain yang kelihatan misteri, tetapi kecacatan ini sebenarnya boleh dikesan kembali kepada "pembahagian perkataan".
Pembahagian perkataan peringkat aksara
Jadi, apakah itu pembahagian perkataan?
Malah, dalam video sebelumnya "Mari bina GPT dari awal", saya telah pun memperkenalkan tokenisasi, tetapi itu hanyalah versi peringkat watak yang sangat mudah.
Jika anda pergi ke Google colab dan lihat video itu, anda akan melihat bahawa kami bermula dengan data latihan (Shakespeare), yang merupakan rentetan besar dalam Python:
First Citizen: Before we proceed any further, hear me speak.All: Speak, speak.First Citizen: You are all resolved rather to die than to famish?All: Resolved. resolved.First Citizen: First, you know Caius Marcius is chief enemy to the people.All: We know't, we know't.
Tetapi, bagaimana adakah kita menyuap rentetan ke dalam Bagaimana dengan LLM?
Kita dapat lihat bahawa kita perlu membina perbendaharaan kata untuk semua watak yang mungkin dalam keseluruhan set latihan:
# here are all the unique characters that occur in this textchars = sorted(list(set(text)))vocab_size = len(chars)print(''.join(chars))print(vocab_size)# !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz# 65Kemudian berdasarkan perbendaharaan kata di atas, cipta perbendaharaan kata antara Carian tunggal dan jadual integer untuk penukaran. Jadual carian ini hanyalah kamus Python:
stoi = { ch:i for i,ch in enumerate(chars) }itos = { i:ch for i,ch in enumerate(chars) }# encoder: take a string, output a list of integersencode = lambda s: [stoi[c] for c in s]# decoder: take a list of integers, output a stringdecode = lambda l: ''.join([itos[i] for i in l])print(encode("hii there"))print(decode(encode("hii there")))# [46, 47, 47, 1, 58, 46, 43, 56, 43]# hii thereSetelah kami menukar rentetan kepada jujukan integer, kami melihat bahawa setiap integer digunakan sebagai indeks ke dalam pembenaman 2D parameter boleh dilatih.
Memandangkan saiz perbendaharaan kata kami ialah vocab_size=65 , jadual benam ini juga akan mempunyai 65 baris:
class BigramLanguageModel(nn.Module):def __init__(self, vocab_size):super().__init__()self.token_embedding_table = nn.Embedding(vocab_size, n_embd)def forward(self, idx, targets=None):tok_emb = self.token_embedding_table(idx) # (B,T,C)
Di sini, integer "mengekstrak" baris daripada jadual benam, dan baris ini ialah vektor yang mewakili pembahagian perkataan. Vektor ini kemudiannya akan dimasukkan ke dalam Transformer sebagai input untuk langkah masa yang sepadan.
Menggunakan algoritma BPE untuk pembahagian "ketulan aksara"
Ini semuanya baik dan bagus untuk persediaan naif model bahasa "peringkat aksara".
Tetapi dalam praktiknya, dalam model bahasa yang canggih, orang ramai menggunakan skema yang lebih kompleks untuk membina perbendaharaan kata perwakilan ini.
Secara khusus, penyelesaian ini tidak berfungsi pada tahap watak, tetapi pada tahap "blok watak". Cara perbendaharaan kata bongkah ini dibina menggunakan algoritma seperti Pengekodan Pasangan Byte (BPE), yang kami terangkan secara terperinci di bawah.
Mari kita semak secara ringkas perkembangan sejarah kaedah ini. Makalah yang menggunakan algoritma BPE peringkat byte untuk segmentasi kata model bahasa ialah Model Bahasa Kertas GPT-2 adalah Pelajar Berbilang Tugas Tanpa Seliaan yang diterbitkan oleh OpenAI pada 2019.

Paper Alamat: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
scroll ke bahagian 2.2 . Pada penghujung bahagian ini, anda akan melihat mereka berkata:
Perbendaharaan kata dikembangkan kepada 50,257 patah perkataan. Kami juga meningkatkan saiz konteks daripada 512 kepada 1024 token dan menggunakan saiz kelompok yang lebih besar iaitu 512.
Ingat bahawa dalam lapisan perhatian Transformer, setiap token dikaitkan dengan senarai terhad token sebelumnya dalam jujukan.
Artikel ini menunjukkan bahawa panjang konteks model GPT-2 telah meningkat daripada 512 token dalam GPT-1 kepada 1024 token.
Dalam erti kata lain, token ialah "atom" asas pada input LLM.
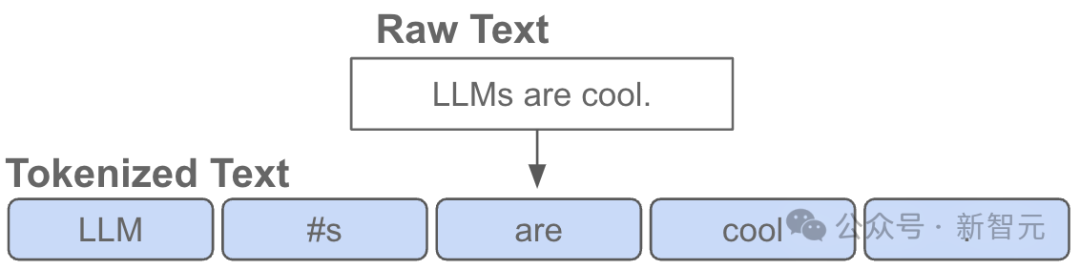
"Tokenisasi" ialah proses menukar rentetan asal dalam Python kepada senarai token, dan sebaliknya.
Ada satu lagi contoh popular yang membuktikan kesejagatan abstraksi ini Jika anda juga mencari "token" dalam kertas Llama 2, anda akan mendapat 63 hasil yang sepadan.
Sebagai contoh, akhbar itu mendakwa bahawa mereka berlatih menggunakan 2 trilion token, dsb.

Alamat kertas: https://arxiv.org/pdf/2307.09288.pdf
Sebuah ceramah ringkas tentang kerumitan pembahagian perkataan
untuk butiran terperinci pelaksanaan, marilah kita Untuk menerangkan secara ringkas, adalah perlu untuk memahami proses "pembahagian perkataan" secara terperinci.
Tokenisasi adalah di tengah-tengah banyak, banyak masalah pelik dalam LLM, dan saya mengesyorkan anda untuk tidak mengabaikannya.
Banyak masalah dengan seni bina rangkaian neural sebenarnya berkaitan dengan pembahagian perkataan. Berikut ialah beberapa contoh:
- Mengapa LLM tidak boleh mengeja perkataan? ——Pembahagian perkataan
- Mengapa LLM tidak boleh melaksanakan tugas pemprosesan rentetan yang sangat mudah, seperti membalikkan rentetan? ——Pembahagian perkataan
- Mengapa LLM lebih teruk dalam tugasan bukan bahasa Inggeris (seperti Jepun)? ——Participle
- Mengapa LLM tidak pandai dalam aritmetik mudah? ——Pembahagian perkataan
- Mengapakah GPT-2 menghadapi lebih banyak masalah semasa pengekodan dalam Python? ——Pembahagian perkataan
- Mengapa LLM saya tiba-tiba berhenti apabila ia melihat rentetan ? ——Participle
- Apakah amaran aneh yang saya terima ini tentang "ruang kosong mengekori"? ——Participle
- Jika saya bertanya kepada LLM tentang "SolidGoldMagikarp", mengapa ia ranap? ——Pembahagian perkataan
- Mengapa saya harus menggunakan YAML dengan LLM dan bukannya JSON? ——Pembahagian perkataan
- Mengapakah LLM bukan pemodelan bahasa hujung ke hujung yang benar? ——Participle

Kami akan kembali kepada soalan-soalan ini pada penghujung video.
Pratonton visual pembahagian perkataan
Seterusnya, mari kami memuatkan WebApp pembahagian perkataan ini.
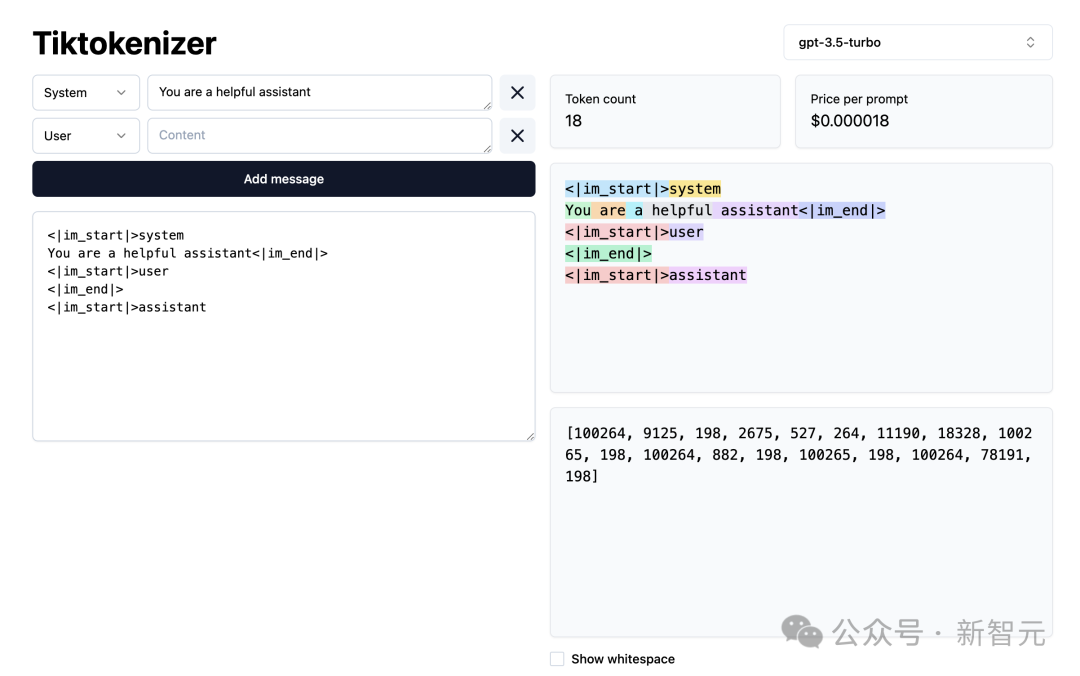
Alamat: https://tiktokenizer.vercel.app/
Kelebihan aplikasi web ini ialah tokenisasi berjalan dalam masa nyata dalam pelayar web, membolehkan anda memasukkan beberapa teks dengan mudah pada rentetan sisi input, dan lihat hasil pembahagian perkataan di sebelah kanan.
Di bahagian atas, anda dapat melihat bahawa kami sedang menggunakan tokenizer gpt2, dan anda dapat melihat bahawa rentetan yang ditampal dalam contoh ini sedang ditokenkan kepada 300 token.
Di sini, ia ditunjukkan dengan jelas dalam warna:
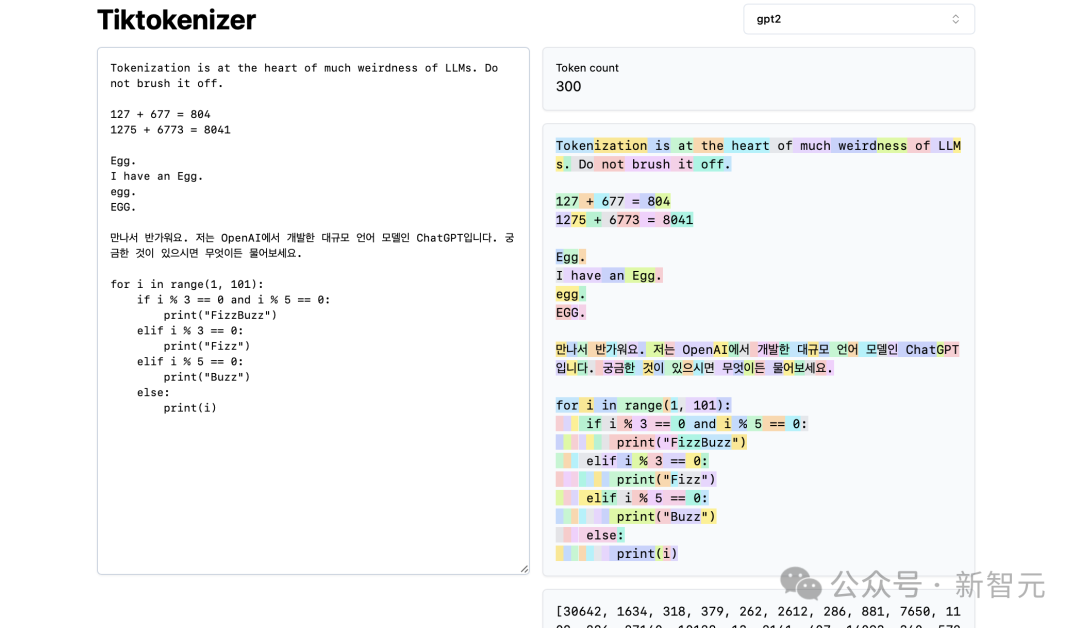
Sebagai contoh, rentetan "Tokenization" dikodkan ke dalam token30642, diikuti dengan token 1634.
token "adalah" (perhatikan bahawa ini ialah tiga aksara, termasuk ruang sebelumnya, ini penting!) ialah 318.
Beri perhatian kepada penggunaan ruang, kerana ia benar-benar terdapat dalam rentetan dan mesti ditulis bersama-sama dengan semua aksara lain. Walau bagaimanapun, ia biasanya ditinggalkan semasa visualisasi demi kejelasan.
Anda boleh menghidupkan dan mematikan ciri visualisasinya di bahagian bawah apl. Begitu juga, token "at" ialah 379, "the" ialah 262, dan seterusnya.
Seterusnya, kita ada contoh aritmetik mudah.
Di sini kita melihat bahawa tokenizer boleh menjadi tidak konsisten dalam penguraian nombornya. Sebagai contoh, nombor 127 ialah token 3 aksara, tetapi nombor 677 adalah kerana terdapat 2 token: 6 (sekali lagi, perhatikan ruang sebelumnya) dan 77.
Kami bergantung kepada LLM untuk menjelaskan kesahihan ini.
Ia mesti belajar tentang dua token ini (6 dan 77 sebenarnya bergabung untuk membentuk nombor 677) dalam parameternya dan semasa latihan.
Begitu juga, kita dapat melihat bahawa jika LLM ingin meramalkan bahawa hasil jumlah ini ialah nombor 804, ia mesti mengeluarkannya dalam dua langkah masa:
Pertama, ia mesti mengeluarkan token "8" , dan kemudian Ia adalah token "04".
Sila ambil perhatian bahawa semua belahan ini kelihatan sewenang-wenangnya. Dalam contoh di bawah, kita dapat melihat bahawa 1275 ialah "12", kemudian "75", 6773 sebenarnya adalah tiga token "6", "77", dan "3", dan 8041 ialah "8" dan "041" .
(Bersambung...)
(TODO: Jika anda mahu meneruskan versi teks, melainkan kami memikirkan cara untuk menjananya secara automatik daripada video)

Netizen berkata, hebat, saya sebenarnya lebih suka membaca siaran ini daripada menonton video, lebih mudah untuk mengawal rentak saya sendiri.

Sesetengah netizen memberi nasihat Karpathy:
"Rasanya rumit, tetapi mungkin menggunakan LangChain. Saya tertanya-tanya sama ada saya boleh menggunakan transkripsi bisikan untuk menghasilkan garis besar peringkat tinggi dengan bab yang jelas, dan kemudian memproses bahagian bab tersebut secara selari, memfokuskan pada setiap satu dalam konteks daripada keseluruhan garis besar. Kandungan khusus blok bab (gambar juga dihasilkan untuk setiap bab yang diproses secara selari).

Seseorang telah menulis saluran paip untuk ini, dan ia akan menjadi sumber terbuka tidak lama lagi.
Atas ialah kandungan terperinci Penuh dengan maklumat berguna! Versi teks pertama kursus AI Master Karpathy selama dua jam, aliran kerja baharu secara automatik menukar video kepada artikel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



