Pengeluaran OpenAI Sora pada 16 Februari sudah pasti menandakan kejayaan besar dalam bidang penjanaan video. Sora adalah berdasarkan seni bina Diffusion Transformer, yang berbeza daripada kebanyakan kaedah arus perdana di pasaran (dilanjutkan oleh 2D Stable Diffusion). Mengapa Sora berkeras untuk menggunakan Diffusion Transformer, sebabnya boleh dilihat daripada kertas kerja yang diterbitkan di ICLR 2024 (VDT: General-purpose Video Diffusion Transformers melalui Mask Modeling) pada masa yang sama. Kerja ini diketuai oleh pasukan penyelidik Universiti Renmin China dan bekerjasama dengan Universiti California, Berkeley, Universiti Hong Kong, dsb., dan pertama kali diterbitkan di tapak web arXiv pada Mei 2023. Pasukan penyelidik mencadangkan rangka kerja penjanaan video bersatu berdasarkan Transformer - Video Diffusion Transformer (VDT), dan memberikan penjelasan terperinci tentang sebab untuk mengguna pakai seni bina Transformer. 
- Tajuk kertas: VDT: Transformers Resapan Video Tujuan Umum melalui Pemodelan Topeng
- Alamat artikel: Openreview: https://openreview.net/pdf?id=Un0rgm9f04 https://arxiv.org/abs/2305.13311
- Alamat projek: VDT: Transformers Resapan Video Tujuan Umum melalui Pemodelan Topeng
- Alamat kod: https://github.com/RERV/VDT
-
1. Keunggulan dan inovasi VDT
Pengkaji berkata bahawa keunggulan model VDT menggunakan seni bina Transformer dalam bidang penjanaan video dicerminkan dalam: yang terutamanya direka bentuk dan U- untuk imej. Net, Transformer boleh menangkap kebergantungan masa jangka panjang atau tidak teratur dengan tokenisasi yang berkuasa dan mekanisme perhatian, dengan itu mengendalikan dimensi masa dengan lebih baik. Hanya apabila model mempelajari (atau menghafal) pengetahuan dunia (seperti perhubungan ruang-masa dan undang-undang fizikal), ia boleh menjana video yang konsisten dengan dunia sebenar. Oleh itu, kapasiti model menjadi komponen utama penyebaran video. Transformer telah terbukti sangat berskala Sebagai contoh, model PaLM mempunyai sehingga 540B parameter, manakala saiz model 2D U-Net terbesar pada masa itu hanya 2.6B parameter (SDXL), yang menjadikan Transformer lebih sesuai daripada 3D U. -Cabaran penjanaan video.
-
Bidang penjanaan video merangkumi pelbagai tugas termasuk penjanaan tanpa syarat, ramalan video, interpolasi dan penjanaan teks ke imej. Penyelidikan sebelum ini sering menumpukan pada satu tugasan, selalunya memerlukan pengenalan modul khusus untuk memperhalusi tugas hiliran. Tambahan pula, tugasan ini melibatkan pelbagai jenis maklumat bersyarat yang mungkin berbeza merentas bingkai dan modaliti, memerlukan seni bina berkuasa yang boleh mengendalikan panjang dan modaliti input yang berbeza. Pengenalan Transformer boleh menyatukan tugas-tugas ini.
- Inovasi VDT terutamanya merangkumi aspek-aspek berikut:
Menggunakan teknologi Transformer untuk penjanaan video berasaskan resapan
menunjukkan potensi penjanaan video Transforma
. Kelebihan VDT ialah keupayaan penangkapan bergantung masa yang sangat baik, membolehkan penjanaan bingkai video koheren sementara, termasuk mensimulasikan dinamik fizikal objek tiga dimensi dari semasa ke semasa.
- Cadangkan mesin pemodelan topeng spatio-temporal bersatu, yang membolehkan VDT mengendalikan pelbagai tugas penjanaan video dan mencapai aplikasi teknologi yang meluas. Kaedah pemprosesan maklumat bersyarat fleksibel VDT, seperti penyambungan ruang token yang mudah, menyatukan maklumat dengan panjang dan modaliti yang berbeza dengan berkesan. Pada masa yang sama, dengan menggabungkan dengan mekanisme pemodelan topeng spatiotemporal yang dicadangkan dalam kerja ini, VDT telah menjadi alat penyebaran video universal, yang boleh digunakan untuk penjanaan tanpa syarat, ramalan bingkai video berikutnya, interpolasi bingkai, dan penjanaan imej tanpa mengubah suai model. struktur. Pelbagai tugas penjanaan video seperti video dan penyiapan skrin video.
- 2. Tafsiran terperinci seni bina rangkaian VDT
Rangka kerja VDT sangat serupa dengan rangka kerja Sora dan terdiri daripada bahagian berikut: Ciri Input/Output. Matlamat VDT adalah untuk menjana segmen video F×H×W×3 yang terdiri daripada bingkai F video bersaiz H×W. Walau bagaimanapun, jika piksel mentah digunakan sebagai input kepada VDT, terutamanya apabila F adalah besar, ia akan membawa kepada kerumitan pengiraan yang sangat tinggi. Untuk menyelesaikan masalah ini, diilhamkan oleh model penyebaran terpendam (LDM), VDT menggunakan tokenizer VAE yang telah terlatih untuk menayangkan video ke dalam ruang terpendam. Mengurangkan dimensi vektor input dan output kepada F×H/8×W/8×C ciri terpendam/bunyi mempercepatkan latihan dan kelajuan inferens VDT, dengan saiz ciri terpendam bingkai F ialah H/8×W /8 . Di sini 8 ialah kadar pensampelan menurun bagi tokenizer VAE, dan C mewakili dimensi ciri terpendam. Pembenaman linear. Mengikuti pendekatan Vision Transformer, VDT membahagikan perwakilan ciri video terpendam ke dalam tompok tidak bertindih bersaiz N×N. Blok Transformer Masa Angkasa. Diilhamkan oleh kejayaan perhatian kendiri spatiotemporal dalam pemodelan video, VDT memasukkan lapisan perhatian temporal ke dalam Blok Transformer untuk mendapatkan keupayaan pemodelan dimensi temporal. Khususnya, setiap Blok Transformer terdiri daripada perhatian temporal berbilang kepala, perhatian spatial berbilang kepala dan rangkaian suapan hadapan bersambung sepenuhnya, seperti yang ditunjukkan dalam rajah di atas. Membandingkan laporan teknikal terkini Sora, kita dapat melihat bahawa hanya terdapat beberapa perbezaan halus dalam butiran pelaksanaan antara VDT dan Sora . Pertama sekali, VDT menggunakan kaedah memproses mekanisme perhatian secara berasingan dalam dimensi spatio-temporal, manakala Sora menggabungkan dimensi masa dan ruang dan memprosesnya melalui mekanisme perhatian tunggal. Pendekatan pengasingan perhatian ini telah menjadi perkara biasa dalam medan video dan sering dilihat sebagai pilihan kompromi di bawah kekangan memori video. VDT memilih untuk menggunakan perhatian berpecah kerana sumber pengkomputeran yang terhad. Keupayaan dinamik video Sora yang berkuasa mungkin datang daripada mekanisme perhatian keseluruhan ruang dan masa. Kedua, tidak seperti VDT, Sora juga menganggap gabungan keadaan teks. Terdapat kajian terdahulu mengenai gabungan bersyarat teks berdasarkan Transformer (seperti DiT Diperkirakan bahawa Sora boleh menambahkan lagi mekanisme perhatian silang kepada modulnya, penyambungan teks dan bunyi secara langsung sebagai input bersyarat juga berpotensi kemungkinan. Semasa proses penyelidikan VDT, penyelidik menggantikan U-Net, rangkaian tulang belakang asas yang biasa digunakan, dengan Transformer. Ini bukan sahaja mengesahkan keberkesanan Transformer dalam tugasan penyebaran video, menunjukkan kelebihan pengembangan yang mudah dan kesinambungan yang dipertingkatkan, tetapi juga mencetuskan pemikiran lanjut mereka tentang nilai potensinya. Dengan kejayaan model GPT dan populariti model autoregresif (AR), penyelidik telah mula meneroka aplikasi Transformer yang lebih mendalam dalam bidang penjanaan video, dan mempertimbangkan sama ada ia boleh menyediakan cara baharu untuk mencapai kecerdasan visual. Bidang penjanaan video mempunyai tugas yang berkait rapat - ramalan video. Idea untuk meramalkan bingkai video seterusnya sebagai laluan kepada kecerdasan visual mungkin kelihatan mudah, tetapi ia sebenarnya menjadi kebimbangan umum di kalangan ramai penyelidik. Berdasarkan pertimbangan ini, penyelidik berharap dapat menyesuaikan dan mengoptimumkan model mereka pada tugas ramalan video. Tugas ramalan video juga boleh dianggap sebagai penjanaan bersyarat, di mana bingkai bersyarat yang diberikan ialah beberapa bingkai pertama video. VDT terutamanya mempertimbangkan tiga kaedah penjanaan keadaan berikut: 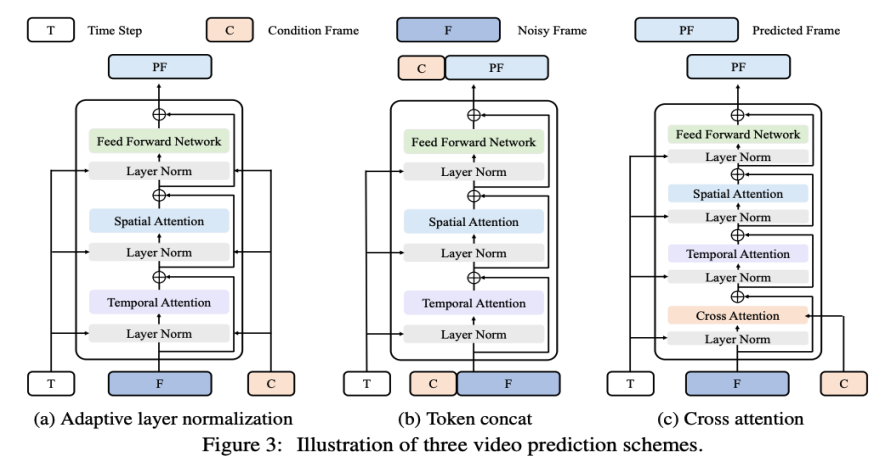
Penormalan lapisan penyesuaian. Cara mudah untuk mencapai ramalan video adalah dengan menyepadukan ciri bingkai bersyarat ke dalam normalisasi lapisan Blok VDT, sama seperti cara kami menyepadukan maklumat temporal ke dalam proses penyebaran. Silang Perhatian. Penyelidik juga telah meneroka menggunakan perhatian silang sebagai skema ramalan video, di mana bingkai bersyarat digunakan sebagai kunci dan nilai, dan bingkai hingar digunakan sebagai pertanyaan. Ini membenarkan gabungan maklumat bersyarat dengan bingkai hingar. Sebelum memasuki lapisan perhatian silang, gunakan tokenizer VAE untuk mengekstrak ciri bingkai bersyarat dan menampalnya. Sementara itu, benam kedudukan spatial dan temporal juga ditambah untuk membantu VDT kami mempelajari maklumat yang sepadan dalam bingkai bersyarat. Penyambungan token. Model VDT menggunakan seni bina Transformer tulen, jadi secara langsung menggunakan bingkai bersyarat sebagai token input ialah kaedah yang lebih intuitif untuk VDT. Kami mencapai ini dengan menggabungkan bingkai terkondisi (ciri terpendam) dan bingkai hingar pada tahap token, yang kemudiannya dimasukkan ke dalam VDT. Seterusnya, mereka membahagikan jujukan bingkai output VDT dan menggunakan bingkai yang diramalkan untuk proses resapan, seperti yang ditunjukkan dalam Rajah 3 (b). Para penyelidik mendapati bahawa penyelesaian ini menunjukkan kelajuan penumpuan terpantas dan memberikan prestasi yang lebih baik dalam keputusan akhir berbanding dengan dua kaedah pertama. Di samping itu, penyelidik mendapati bahawa walaupun bingkai bersyarat panjang tetap digunakan semasa latihan, VDT masih boleh menerima bingkai bersyarat pada sebarang panjang sebagai ciri ramalan konsisten input dan output. Di bawah rangka kerja VDT, untuk mencapai tugas ramalan video, tidak perlu membuat sebarang pengubahsuaian pada struktur rangkaian, hanya input model yang perlu diubah. Penemuan ini membawa kepada soalan intuitif: Bolehkah kita mengeksploitasi lagi skalabiliti ini untuk melanjutkan VDT kepada tugas penjanaan video yang lebih pelbagai - seperti video penjanaan imej - tanpa memperkenalkan sebarang modul atau parameter tambahan . Dengan menyemak keupayaan VDT dalam penjanaan tanpa syarat dan ramalan video, satu-satunya perbezaan ialah jenis ciri input. Khususnya, input boleh menjadi ciri terpendam bising semata-mata, atau gabungan ciri terpendam bersyarat dan bising. Kemudian, penyelidik memperkenalkan Pemodelan Topeng Spatial-Temporal Bersepadu untuk menyatukan input bersyarat, seperti yang ditunjukkan dalam Rajah 4 di bawah: 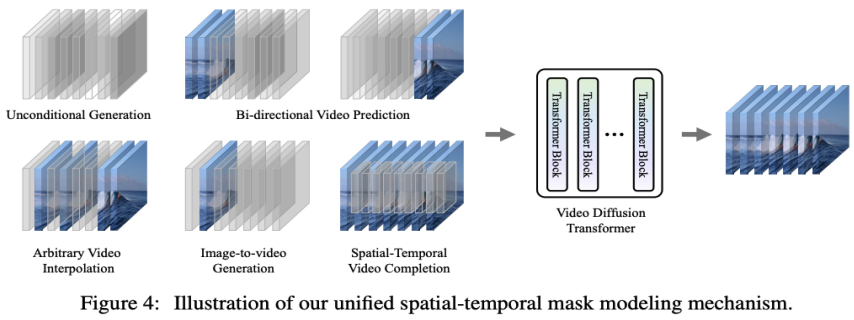
3. Penilaian prestasi VDTMelalui kaedah di atas, model VDT bukan sahaja boleh mengendalikan penjanaan video tanpa syarat dan tugas ramalan video dengan lancar, tetapi juga boleh diperluaskan kepada pelbagai medan penjanaan video yang lebih luas seperti video dengan hanya melaraskan ciri input. Penjelmaan fleksibiliti dan skalabiliti ini menunjukkan potensi kuat rangka kerja VDT dan menyediakan hala tuju dan kemungkinan baharu untuk teknologi penjanaan video masa hadapan. 
Menariknya, sebagai tambahan kepada teks-ke-video, OpenAI juga menunjukkan tugas hebat Sora yang lain, termasuk penjanaan berasaskan imej, ramalan video depan dan belakang serta contoh gabungan klip video yang berbeza, dsb., dan penyelidik mencadangkan Tugas hiliran yang disokong oleh Pemodelan Topeng Ruang-Temporal Bersepadu adalah sangat serupa MAE Kaiming juga disebut dalam rujukan. Oleh itu, spekulasi bahawa lapisan bawah Sora juga menggunakan kaedah latihan seperti MAE. Penyelidik juga meneroka simulasi undang-undang fizikal mudah oleh model generatif VDT. Mereka menjalankan eksperimen pada set data Physion, di mana VDT menggunakan 8 bingkai pertama sebagai bingkai bersyarat dan meramalkan 8 bingkai seterusnya. Dalam contoh pertama (dua baris atas) dan contoh ketiga (dua baris bawah), VDT berjaya mensimulasikan proses fizikal yang melibatkan bola bergerak sepanjang trajektori parabola dan bola bergolek di atas satah dan berlanggar dengan silinder . Dalam contoh kedua (dua baris tengah), VDT menangkap kelajuan/momentum bola apabila ia berhenti sebelum memukul silinder. Ini membuktikan bahawa seni bina Transformer boleh mempelajari undang-undang fizikal tertentu. 
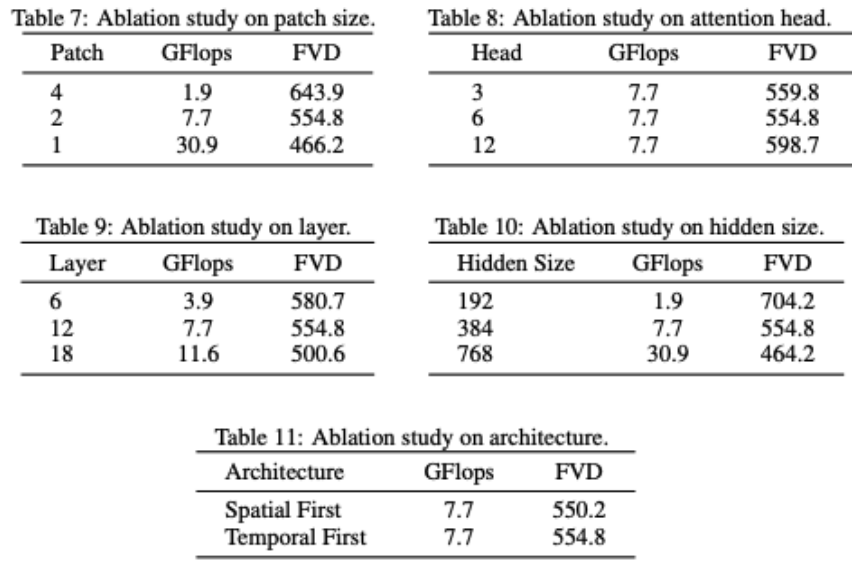
VDT mengurangkan sebahagian struktur rangkaian. Ia boleh didapati bahawa prestasi model sangat berkaitan dengan GFlops, dan beberapa butiran struktur model itu sendiri tidak mempunyai kesan yang besar. Ini juga konsisten dengan penemuan DiT. Para penyelidik juga menjalankan beberapa kajian ablasi struktur pada model VDT. Keputusan menunjukkan bahawa mengurangkan Saiz Tampalan, meningkatkan bilangan Lapisan dan meningkatkan Saiz Tersembunyi boleh meningkatkan lagi prestasi model. Kedudukan perhatian Temporal dan Spatial dan bilangan ketua perhatian mempunyai sedikit kesan ke atas keputusan model. Terdapat beberapa pertukaran reka bentuk yang diperlukan, tetapi secara keseluruhan tidak terdapat perbezaan yang ketara dalam prestasi model sambil mengekalkan GFlop yang sama. Walau bagaimanapun, peningkatan dalam GFlops membawa kepada hasil yang lebih baik, menunjukkan kebolehskalaan seni bina VDT atau Transformer. Keputusan ujian VDT menunjukkan keberkesanan dan fleksibiliti seni bina Transformer dalam memproses penjanaan data video. Disebabkan oleh had sumber pengkomputeran, eksperimen VDT hanya dijalankan pada beberapa set data akademik yang kecil. Kami menantikan penyelidikan masa depan untuk meneroka lebih lanjut hala tuju baharu dan aplikasi teknologi penjanaan video berdasarkan VDT, dan kami juga mengharapkan syarikat China melancarkan model Sora domestik secepat mungkin. Atas ialah kandungan terperinci Universiti domestik membina VDT model seperti Sora, dan Transformer penyebaran video universal telah diterima oleh ICLR 2024. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Apakah kaedah penghasilan penghasilan animasi html5?
Apakah kaedah penghasilan penghasilan animasi html5?
 Tiga ciri utama java
Tiga ciri utama java
 konfigurasi pembolehubah persekitaran jdk
konfigurasi pembolehubah persekitaran jdk
 sambungan jauh mstsc gagal
sambungan jauh mstsc gagal
 Apakah sistem pengurusan biasa?
Apakah sistem pengurusan biasa?
 Penyelesaian kepada tandatangan tidak sah
Penyelesaian kepada tandatangan tidak sah
 Apakah definisi tatasusunan?
Apakah definisi tatasusunan?
 Bagaimana untuk memasukkan keistimewaan root dalam linux
Bagaimana untuk memasukkan keistimewaan root dalam linux








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



