


Dalam sistem Linux, pengurusan memori adalah salah satu bahagian terpenting dalam sistem pengendalian. Ia bertanggungjawab untuk memperuntukkan memori fizikal terhad kepada pelbagai proses dan menyediakan abstraksi memori maya supaya setiap proses mempunyai ruang alamat sendiri dan boleh melindungi dan berkongsi memori. Artikel ini akan memperkenalkan prinsip dan kaedah pengurusan memori Linux, termasuk konsep seperti memori maya, memori fizikal, memori logik dan memori linear, serta model asas, panggilan sistem dan kaedah pelaksanaan pengurusan memori Linux.
Artikel ini berdasarkan mesin 32-bit dan bercakap tentang beberapa titik pengetahuan pengurusan memori.
Alamat maya juga dipanggil alamat linear. Linux tidak menggunakan mekanisme segmentasi, jadi alamat logik dan alamat maya (alamat linear) (Dalam mod pengguna, alamat logik mod kernel secara khusus merujuk kepada alamat sebelum offset linear yang dinyatakan di bawah) adalah konsep yang sama. Tidak perlu menyebut alamat fizikal. Kebanyakan alamat maya kernel dan alamat fizikal hanya berbeza dengan offset linear. Alamat maya dan alamat fizikal dalam ruang pengguna dipetakan menggunakan jadual halaman berbilang peringkat, tetapi ia masih dipanggil alamat linear.
Dalam struktur x86, ruang alamat Linux kernel virtualdibahagikan kepada 0~3G sebagai ruang pengguna dan 3~4G sebagai ruang kernel (perhatikan bahawa alamat linear yang boleh digunakan oleh kernel hanyalah 1G). Ruang maya kernel (3G~4G) dibahagikan kepada tiga jenis kawasan:
ZONE_DMA bermula dari 16MB selepas 3G
ZON_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~1G
Memandangkan alamat maya dan fizikal kernel hanya berbeza dengan satu offset: alamat fizikal = alamat logik – 0xC0000000. Oleh itu, jika ruang kernel 1G digunakan sepenuhnya untuk pemetaan linear, jelas memori fizikal hanya boleh mengakses julat 1G, yang jelas tidak munasabah. HIGHMEM adalah untuk menyelesaikan masalah ini secara khusus membuka kawasan yang tidak memerlukan pemetaan linear dan boleh disesuaikan secara fleksibel untuk mengakses kawasan memori fizikal di atas 1G. Saya mengambil gambar dari Internet,
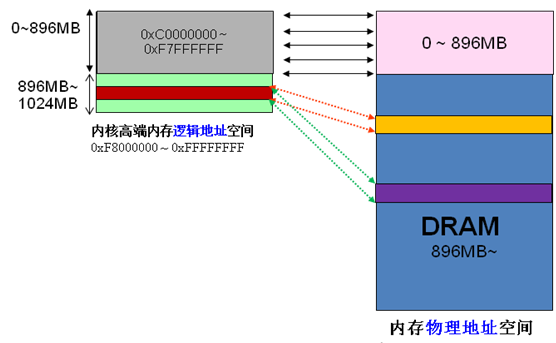
Pembahagian memori mewah adalah seperti yang ditunjukkan di bawah,
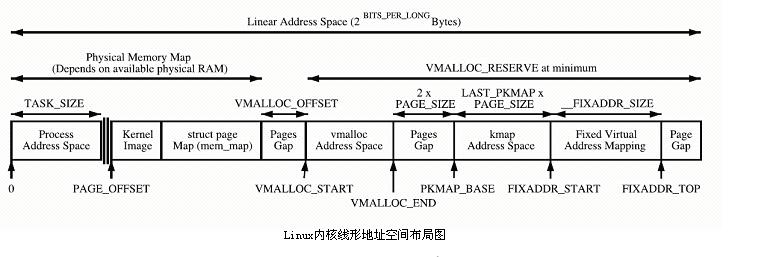
Inti terus memetakan ruang PAGE_OFFSET~VMALLOC_START, kmalloc dan __get_free_page() memperuntukkan halaman di sini. Kedua-duanya menggunakan pengalokasi papak untuk memperuntukkan halaman fizikal secara langsung dan kemudian menukarnya kepada alamat logik (alamat fizikal adalah berterusan). Sesuai untuk memperuntukkan segmen kecil memori. Kawasan ini mengandungi sumber seperti imej kernel dan jadual bingkai halaman fizikal mem_map.
Ruang pemetaan dinamik kernel VMALLOC_START~VMALLOC_END, yang digunakan oleh vmalloc, mempunyai ruang yang boleh diwakili yang besar.
Ruang pemetaan kekal kernel PKMAP_BASE ~ FIXADDR_START, kmap
Ruang pemetaan sementara kernel FIXADDR_START~FIXADDR_TOP, kmap_atomic
Algoritma Buddy menyelesaikan masalah pemecahan luaran Kernel mengurus halaman yang tersedia dalam setiap zon, menyusunnya ke dalam baris gilir senarai terpaut mengikut kuasa saiz 2 (pesanan), dan menyimpannya dalam tatasusunan kawasan_bebas.
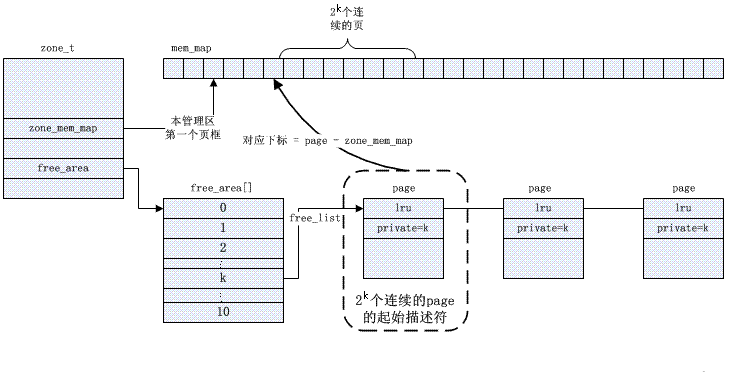
Pengurusan rakan khusus adalah berdasarkan peta bit, dan algoritmanya untuk memperuntukkan dan mengitar semula halaman diterangkan di bawah,
penerangan contoh algoritma rakan:
Andaikan memori sistem kita hanya mempunyai ***16****** muka surat*****RAM*. Oleh kerana RAM hanya mempunyai 16 halaman, kita hanya perlu menggunakan empat peringkat (urutan) bitmap rakan kongsi (kerana saiz memori bersebelahan maksimum ialah ******16****** halaman***), As ditunjukkan di bawah.
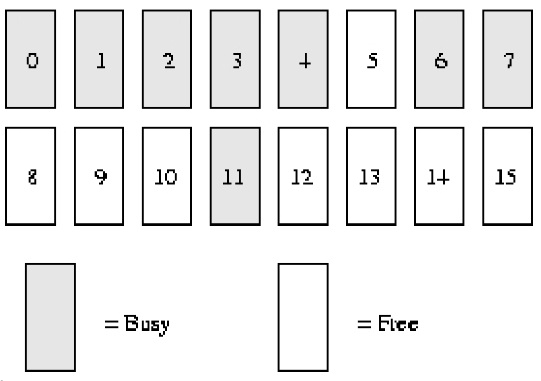

order(0) bimap mempunyai 8 bit (*** halaman boleh mempunyai sehingga ******16****** halaman, jadi ******16/2***)
order(1) bimap mempunyai 4 bit (***order******(******0******)******bimap****** Terdapat ******8************bit******digit***, jadi 8/2);
Iaitu, blok pertama pesanan (1) terdiri daripada *** dua bingkai halaman ****halaman1* *** dan ******halaman2***** dan terdiri daripada * pesanan (1 ) Blok 2 terdiri daripada dua bingkai halaman ****halaman3* *** dan ******halaman4******, terdapat **** antara kedua-dua ini blok **bit****bit*
order(2) bimap mempunyai 2 bit (***order******(******1******)******bimap****** Terdapat ******4************bit******digit***, jadi 4/2)
order(3) bimap ada 1 bit (***order******(******2******)******bimap****** Terdapat ******4************bit******digit***, jadi 2/2)
Dalam urutan(0), bit pertama mewakili ****2****** halaman*** pertama, dan bit kedua mewakili 2 halaman seterusnya. Kerana halaman 4 telah diperuntukkan dan halaman 5 adalah percuma, bit ketiga ialah 1.
Begitu juga dalam urutan(1), sebab bit3 ialah 1 ialah satu rakan kongsi adalah bebas sepenuhnya (halaman 8 dan 9), tetapi rakan kongsi yang sepadan (halaman 10 dan 11) tidak, jadi apabila halaman itu dikitar semula pada masa hadapan, mereka boleh digabungkan.
Proses peruntukan
***Apabila kita memerlukan blok halaman percuma ******pesanan****** (******1******), *** kemudian lakukan langkah berikut:
1. Senarai pautan percuma awal ialah:
pesanan(0): 5, 10
pesanan(1): 8 [8,9]
pesanan(2): 12 [12,13,14,15]
pesanan(3):
2. Daripada senarai terpaut percuma di atas, kita dapat melihat bahawa terdapat * blok halaman percuma pada senarai terpaut pesanan (1) Peruntukkan kepada pengguna dan padamkannya daripada senarai terpaut. *
3 Apabila kami memerlukan blok pesanan(1), kami juga mula mengimbas daripada senarai percuma pesanan.
4 Jika tiada sekatan halaman percuma*** pada ***pesanan****** (******1******), maka kami akan pergi ke peringkat yang lebih tinggi (pesanan. ) Cari di atas, perintah(2).
5 Pada masa ini (tiada blok halaman percuma pada ***pesanan****** (******1*****)*) terdapat blok halaman percuma, yang adalah hamba halaman 12 bermula. Blok halaman dibahagikan kepada dua blok halaman tertib (1) yang lebih kecil, [12, 13] dan [14, 15]. [14, 15] Blok halaman ditambahkan pada pesanan****** (******1*****) senarai percuma*, dan pada masa yang sama [12 ****** ,******13]****Blok halaman dikembalikan kepada pengguna. *
6 Senarai pautan percuma terakhir ialah:
pesanan(0): 5, 10
pesanan(1): 14 [14,15]
pesanan(2):
pesanan(3):
Proses kitar semula
***Apabila kita mengitar semula halaman ******11****** (******pesanan 0****), langkah berikut dilakukan: *
***1******, ****** menjumpai rakan kongsi di ******pesanan****** (******0******) Gambar mewakili bit **** halaman ******11****** *
index =**page_idx >> (pesanan + 1)* *
= 11 >> (0 + 1)**
= 5*2. Semak langkah di atas untuk mengira nilai bit yang sepadan dalam peta bit. Jika nilai bit ialah 1, terdapat rakan kongsi terbiar yang rapat dengan kita. Nilai Bit5 ialah 1 (perhatikan bahawa ia bermula dari bit0, Bit5 ialah bit ke-6) kerana halaman 10 rakan kongsinya adalah percuma.
3 Sekarang kami menetapkan semula nilai bit ini kepada 0, kerana kedua-dua rakan kongsi (halaman 10 dan halaman 11) terbiar sepenuhnya pada masa ini.
4 Kami mengalih keluar halaman 10 daripada senarai percuma pesanan.
5 Pada masa ini, kami melakukan operasi selanjutnya pada 2 halaman percuma (halaman 10 dan 11, pesanan (1)).
6 Halaman percuma baharu bermula dari halaman 10, jadi kami mencari indeksnya dalam peta bit rakan kongsi pesanan(1) untuk melihat sama ada terdapat rakan kongsi terbiar untuk operasi penggabungan selanjutnya. Menggunakan syarikat yang dikira dari langkah satu, kita mendapat bit 2 (kedudukan 3).
7 Bit 2 (pesanan(1) bitmap) juga adalah 1 kerana blok halaman rakan kongsinya (halaman 8 dan 9) adalah percuma.
8. Tetapkan semula nilai bit2 (pesanan(1) bitmap), dan kemudian padamkan blok halaman percuma dalam senarai terpaut pesanan(1).
9 Kini kami bergabung menjadi blok percuma 4 saiz halaman (bermula dari halaman 8), dengan itu memasuki tahap yang lain. Cari nilai bit yang sepadan dengan bitmap rakan kongsi dalam susunan (2), iaitu bit1, dan nilainya ialah 1. Ia perlu dicantumkan lagi (sebabnya adalah sama seperti di atas).
10 Alih keluar blok halaman percuma (bermula dari halaman 12) daripada senarai terpaut oder(2), dan kemudian gabungkan lagi blok halaman ini dengan blok halaman yang diperolehi oleh penggabungan sebelumnya. Kini kami mendapat blok halaman percuma bermula dari halaman 8 dan bersaiz 8 halaman.
11 Kita masuk level lain, order (3). Indeks bitnya ialah 0, dan nilainya juga 0. Ini bermakna bahawa rakan kongsi yang sepadan tidak semuanya bebas, jadi tidak ada kemungkinan untuk bergabung lagi. Kami hanya menetapkan bit ini kepada 1, dan kemudian meletakkan blok halaman percuma yang digabungkan ke dalam senarai terpaut percuma pesanan(3).
12 Akhirnya kami dapat blok percuma 8 muka surat,

usaha rakan untuk mengelakkan serpihan dalaman
Fragmentasi memori fizikal sentiasa menjadi salah satu kelemahan sistem pengendalian Linux Walaupun banyak penyelesaian telah dicadangkan, tiada kaedah yang dapat menyelesaikannya dengan sepenuhnya peruntukan rakan memori adalah salah satu penyelesaian. Kami tahu bahawa fail cakera juga mempunyai masalah pemecahan, tetapi pemecahan fail cakera hanya akan memperlahankan kelajuan membaca dan menulis sistem dan tidak akan menyebabkan ralat fungsi Selain itu, kami juga boleh memecah cakera tanpa menjejaskan fungsi cakera. kemas. Pemecahan memori fizikal adalah berbeza sama sekali Memori fizikal dan sistem pengendalian sangat rapat sehingga sukar bagi kita untuk memindahkan memori fizikal semasa masa jalan (pada ketika ini, pemecahan cakera adalah lebih mudah; sebenarnya, mel gorman mempunyai Tampalan pemadatan memori. telah diserahkan, tetapi masih belum diterima oleh kernel talian utama). Oleh itu, arah penyelesaian terutamanya tertumpu pada mencegah serpihan. Semasa pembangunan kernel 2.6.24, fungsi kernel untuk mengelakkan pemecahan telah ditambahkan pada kernel talian utama. Sebelum memahami prinsip asas anti-pemecahan, mula-mula kelaskan halaman memori:
1. Halaman tidak boleh dialih: Lokasi dalam memori mesti ditetapkan dan tidak boleh dialihkan ke tempat lain Kebanyakan halaman yang diperuntukkan oleh inti teras termasuk dalam kategori ini.
2. Halaman boleh dituntut semula: Ia tidak boleh dialihkan secara langsung, tetapi ia boleh dikitar semula, kerana halaman tersebut juga boleh dibina semula daripada sumber tertentu Contohnya, data fail pemetaan tergolong dalam kategori ini secara berkala mengikut peraturan tertentu.
3. Halaman boleh alih boleh alih: boleh dialih sesuka hati. Halaman milik aplikasi ruang pengguna tergolong dalam jenis halaman ini Mereka dipetakan melalui jadual halaman, jadi kami hanya perlu mengemas kini entri jadual halaman dan menyalin data ke lokasi baharu boleh digunakan oleh berbilang Perkongsian Proses sepadan dengan berbilang entri jadual halaman.
Cara untuk mengelakkan pemecahan adalah dengan meletakkan ketiga-tiga jenis halaman ini pada senarai pautan yang berbeza untuk mengelakkan pelbagai jenis halaman daripada mengganggu antara satu sama lain. Pertimbangkan keadaan di mana halaman tak alih terletak di tengah halaman boleh alih Selepas kami mengalihkan atau mengitar semula halaman ini, halaman tak alih ini menghalang kami daripada mendapatkan ruang bebas fizikal yang lebih besar.
Selain itu, Setiap zon mempunyai baris gilir halaman bersihnya sendiri yang dinyahaktifkan, yang sepadan dengan dua baris gilir global merentas zon, baris gilir halaman kotor yang dinyahaktifkan dan baris gilir aktif. Barisan gilir ini dipautkan melalui penunjuk lru struktur halaman.
Berfikir: Apakah maksud baris gilir penyahaktifan (lihat
pengalokasi papak: selesaikan masalah pemecahan dalaman
Inti selalunya bergantung pada peruntukan objek kecil, yang diperuntukkan berkali-kali sepanjang hayat sistem. Pengalokasi cache papak menyediakan kefungsian ini dengan menyimpan objek yang sama saiz (lebih kecil daripada 1halaman), dengan itu mengelakkan masalah pemecahan dalaman biasa. Berikut adalah gambar buat masa ini mengenai prinsipnya, sila rujuk rujukan biasa 3. Jelas sekali, mekanisme papak adalah berdasarkan algoritma buddy, dan yang pertama adalah penghalusan yang terakhir.
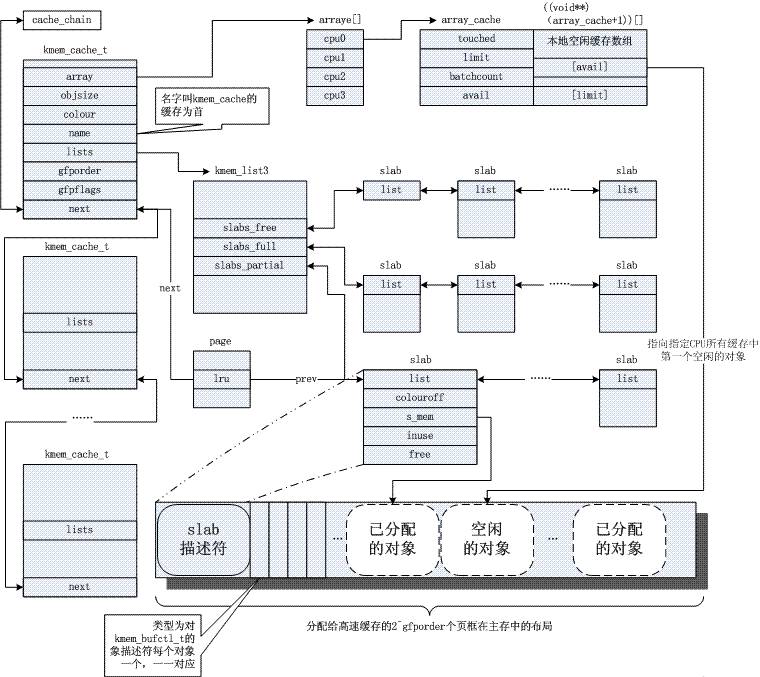
4. Mekanisme kitar semula/memfokuskan halaman
Menggunakan halaman Perihal
Dalam beberapa artikel sebelumnya, kami mengetahui bahawa kernel Linux memperuntukkan halaman dalam banyak situasi.
1. Kod kernel boleh memanggil fungsi seperti alloc_pages untuk memperuntukkan terus halaman daripada sistem rakan kongsi yang menguruskan halaman fizikal (senarai percuma kawasan_bebas pada zon pengurusan) (lihat "Analisis Ringkas Pengurusan Memori Kernel Linux"). Sebagai contoh: pemacu boleh memperuntukkan cache dengan cara ini apabila membuat proses, kernel juga memperuntukkan dua halaman berturut-turut dengan cara ini sebagai struktur thread_info dan susunan inti proses dan seterusnya. Memperuntukkan halaman daripada sistem rakan kongsi ialah kaedah peruntukan halaman yang paling asas, dan peruntukan memori lain adalah berdasarkan kaedah ini
2. Banyak objek dalam kernel diuruskan menggunakan mekanisme papak (lihat "Analisis Ringkas Linux Slub Allocator"). Papak adalah bersamaan dengan kumpulan objek, yang "memformat" halaman menjadi "objek" dan menyimpannya dalam kolam untuk kegunaan manusia. Apabila objek tidak mencukupi dalam papak, mekanisme papak akan memperuntukkan halaman secara automatik daripada sistem rakan kongsi dan "memformat"nya menjadi objek baharu
3. Cache cakera (lihat "Analisis Ringkas Membaca dan Menulis Fail Kernel Linux"). Apabila membaca dan menulis fail, halaman diperuntukkan daripada sistem rakan kongsi dan digunakan untuk cache cakera, dan kemudian data fail pada cakera dimuatkan ke halaman cache cakera yang sepadan
4. Pemetaan ingatan. Apa yang dipanggil pemetaan memori di sini sebenarnya merujuk kepada pemetaan halaman memori kepada ruang pengguna untuk digunakan oleh proses pengguna. Setiap vma dalam struktur task_struct->mm proses mewakili pemetaan, dan pelaksanaan sebenar pemetaan ialah selepas program pengguna mengakses alamat memori yang sepadan, halaman yang disebabkan oleh pengecualian kesalahan halaman diperuntukkan dan jadual halaman adalah dikemas kini. (Lihat "Analisis Ringkas Pengurusan Memori Kernel Linux");
Pengenalan ringkas kepada kitar semula halaman
Apabila terdapat peruntukan halaman, akan ada kitar semula halaman. Kaedah kitar semula halaman secara kasar boleh dibahagikan kepada dua jenis:
Satu ialah keluaran aktif. Sama seperti program pengguna melepaskan memori setelah diperuntukkan melalui fungsi malloc melalui fungsi percuma, pengguna halaman dengan jelas mengetahui bila halaman akan digunakan dan bila ia tidak diperlukan lagi.
Dua kaedah peruntukan pertama yang dinyatakan di atas secara amnya dikeluarkan secara aktif oleh program kernel. Untuk halaman yang diperuntukkan terus daripada sistem rakan kongsi, ia dikeluarkan secara aktif oleh pengguna menggunakan fungsi seperti free_pages Selepas halaman dikeluarkan, ia dikeluarkan terus ke sistem rakan kongsi (menggunakan fungsi kmem_cache_alloc) juga dikeluarkan oleh pengguna Secara aktif dikeluarkan (menggunakan fungsi kmem_cache_free).
Ringkasnya, apa yang PFRA perlu lakukan ialah mengitar semula halaman ini yang boleh dikitar semula. Untuk mengelakkan sistem daripada mengalami kekurangan halaman, PFRA akan dipanggil secara berkala dalam utas kernel. Atau kerana sistem sudah kebuluran halaman, proses pelaksanaan kernel yang cuba memperuntukkan halaman tidak boleh mendapatkan halaman yang diperlukan dan memanggil PFRA secara serentak.
Dua kaedah peruntukan terakhir yang dinyatakan di atas biasanya dikitar semula oleh PFRA (atau dikitar semula secara serentak oleh proses seperti memadam fail dan proses keluar).
halaman umum kitar semula PFRA
Untuk kaedah peruntukan dua halaman pertama yang dinyatakan di atas (peruntukan halaman langsung dan peruntukan objek melalui papak), mungkin juga perlu untuk mengitar semula melalui PFRA.
Pengguna halaman boleh mendaftarkan fungsi panggil balik dengan PFRA (menggunakan fungsi register_shrink). Fungsi panggil balik ini kemudiannya dipanggil oleh PFRA pada masa yang sesuai untuk mencetuskan kitar semula halaman atau objek yang sepadan.
Salah satu yang lebih tipikal ialah kitar semula gigi. Pergigian ialah objek yang diperuntukkan oleh papak dan digunakan untuk mewakili struktur direktori sistem fail maya. Apabila kiraan rujukan gigi dikurangkan kepada 0, gigi tidak dilepaskan secara langsung, tetapi dicache dalam senarai terpaut LRU untuk kegunaan seterusnya. (Lihat "Analisis Ringkas Sistem Fail Maya Kernel Linux".)
Dentry dalam senarai terpaut LRU ini akhirnya perlu dikitar semula, jadi apabila sistem fail maya dimulakan, register_shrinker dipanggil untuk mendaftarkan fungsi kitar semula shrink_dcache_memory.
Objek superblock semua sistem fail dalam sistem disimpan dalam senarai terpaut Fungsi shrink_dcache_memory mengimbas senarai terpaut ini, mendapatkan LRU bagi gigi yang tidak digunakan setiap superblock, dan kemudian menuntut semula beberapa gigi tertua daripadanya. Apabila gigi dilepaskan, inod yang sepadan akan dinyahrujuk, yang mungkin juga menyebabkan inod dilepaskan.
Selepas inod dikeluarkan, ia juga diletakkan dalam senarai terpaut yang tidak digunakan Semasa pemulaan, sistem fail maya juga memanggil register_shrinker untuk mendaftarkan fungsi panggil balik shrink_icache_memory untuk mengitar semula inod yang tidak digunakan ini, supaya cache cakera yang dikaitkan dengan inod juga akan. dilepaskan.
Selain itu, semasa sistem berjalan, mungkin terdapat banyak objek terbiar dalam papak (contohnya, selepas penggunaan puncak objek tertentu berlalu). Fungsi cache_reap dalam PFRA digunakan untuk mengitar semula objek terbiar yang berlebihan ini Jika sesetengah objek terbiar boleh dipulihkan ke halaman, halaman itu boleh dilepaskan semula ke sistem rakan kongsi
Perkara yang dilakukan oleh fungsi cache_reap adalah mudah untuk dikatakan. Semua struktur kmem_cache yang menyimpan kumpulan objek dalam sistem disambungkan ke dalam senarai terpaut Fungsi cache_reap mengimbas setiap kumpulan objek, kemudian mencari halaman yang boleh dikitar semula dan mengitar semulanya. (Sudah tentu, proses sebenar adalah sedikit lebih rumit.)
Mengenai pemetaan memori
Seperti yang dinyatakan sebelum ini, cache cakera dan pemetaan memori biasanya dikitar semula oleh PFRA. Kitar semula PFRA bagi kedua-duanya adalah sangat serupa Malah, cache cakera mungkin dipetakan ke ruang pengguna. Berikut adalah pengenalan ringkas kepada pemetaan ingatan:
Pemetaan fail bermakna vma yang mewakili pemetaan ini sepadan dengan kawasan tertentu dalam fail. Kaedah pemetaan ini agak jarang digunakan secara eksplisit oleh program mod pengguna secara amnya biasa membuka fail dan kemudian membaca/menulis fail.
Malah, program pengguna juga boleh menggunakan panggilan sistem mmap untuk memetakan bahagian tertentu fail ke ingatan (sepadan dengan vma), dan kemudian membaca dan menulis fail dengan mengakses memori. Walaupun program pengguna jarang menggunakan kaedah ini, proses pengguna penuh dengan pemetaan sedemikian: kod boleh laku (termasuk fail boleh laku dan fail perpustakaan lib) yang dilaksanakan oleh proses dipetakan dengan cara ini.
Dalam artikel "Analisis Ringkas Pembacaan dan Penulisan Fail Kernel Linux", kami tidak membincangkan pelaksanaan pemetaan fail. Malah, pemetaan fail memetakan terus halaman dalam cache cakera fail ke ruang pengguna (boleh dilihat bahawa halaman yang dipetakan oleh fail adalah subset halaman cache cakera), dan pengguna boleh membaca dan menulisnya dengan 0 salinan. Apabila menggunakan baca/tulis, salinan akan berlaku antara memori ruang pengguna dan cache cakera.
Pemetaan tanpa nama adalah relatif kepada pemetaan fail, yang bermaksud bahawa vma pemetaan ini tidak sepadan dengan fail. Untuk peruntukan memori biasa dalam ruang pengguna (ruang timbunan, ruang tindanan), semuanya tergolong dalam pemetaan tanpa nama.
Jelas sekali, pelbagai proses boleh memetakan ke fail yang sama melalui pemetaan fail mereka sendiri (contohnya, kebanyakan proses memetakan fail pustaka libc), bagaimana pula dengan pemetaan tanpa nama? Malah, berbilang proses boleh memetakan memori fizikal yang sama melalui pemetaan tanpa nama mereka sendiri Keadaan ini disebabkan oleh proses ibu bapa-anak berkongsi memori fizikal asal (salinan-tulis) selepas garpu.
Halaman mana yang patut dikitar semula
Bagi kitar semula, halaman cache cakera (termasuk halaman yang dipetakan fail) boleh dibuang dan dikitar semula. Tetapi jika halaman itu kotor, ia mesti ditulis semula ke cakera sebelum dibuang.
Halaman yang dipetakan tanpa nama tidak boleh dibuang, kerana halaman tersebut mengandungi data yang sedang digunakan oleh program pengguna dan data tidak boleh dipulihkan selepas dibuang. Sebaliknya, data dalam halaman cache cakera itu sendiri disimpan pada cakera dan boleh diterbitkan semula.
Oleh itu, jika anda ingin mengitar semula halaman yang dipetakan tanpa nama, anda perlu membuang data pada halaman ke cakera terlebih dahulu. Ini adalah pertukaran halaman (swap). Jelas sekali, kos pertukaran halaman secara relatifnya lebih tinggi.
Halaman yang dipetakan tanpa nama boleh ditukar kepada fail swap atau swap partition pada cakera (partition ialah peranti dan peranti juga fail. Jadi ia secara kolektif dirujuk sebagai fail swap di bawah).
Walaupun terdapat banyak halaman yang boleh dikitar semula, jelas sekali PFRA harus mengitar semula/menukar sesedikit mungkin (kerana halaman ini perlu dipulihkan dari cakera, yang memerlukan kos yang tinggi). Oleh itu, PFRA hanya menuntut semula/menukar sebahagian daripada halaman yang jarang digunakan apabila perlu, dan bilangan halaman yang dituntut semula setiap kali adalah nilai empirikal: 32.
Jadi, semua halaman cache cakera dan halaman yang dipetakan tanpa nama ini diletakkan dalam satu set LRU. (Sebenarnya, setiap zon mempunyai satu set LRU sedemikian, dan halaman diletakkan dalam LRU zon yang sepadan.)
Sekumpulan LRU terdiri daripada beberapa pasang senarai terpaut, termasuk senarai terpaut halaman cache cakera (termasuk halaman pemetaan fail), senarai terpaut halaman pemetaan tanpa nama, dsb. Sepasang senarai terpaut sebenarnya adalah dua senarai terpaut: aktif dan tidak aktif Yang pertama ialah halaman yang baru digunakan dan yang kedua ialah halaman yang tidak digunakan baru-baru ini.
Semasa mengitar semula halaman, PFRA perlu melakukan dua perkara Satu ialah mengalihkan halaman yang paling kurang digunakan dalam senarai terpaut aktif ke senarai terpaut yang tidak aktif.
Tentukan yang paling kurang digunakan baru-baru ini
Sekarang timbul persoalan, bagaimana untuk menentukan halaman mana dalam senarai aktif/tidak aktif yang paling kurang digunakan baru-baru ini?
Satu pendekatan ialah mengisih, dan apabila halaman diakses, alihkannya ke bahagian belakang senarai terpaut (dengan mengandaikan kitar semula bermula di kepala). Tetapi ini bermakna bahawa kedudukan halaman dalam senarai terpaut mungkin dialihkan dengan kerap, dan ia mesti dikunci sebelum dialihkan (mungkin terdapat berbilang CPU mengaksesnya pada masa yang sama), yang mempunyai kesan yang besar terhadap kecekapan.
Inti Linux mengamalkan kaedah penandaan dan pesanan. Apabila halaman bergerak antara senarai terpaut yang aktif dan tidak aktif, ia sentiasa diletakkan di hujung senarai terpaut (sama seperti di atas, dengan mengandaikan kitar semula bermula dari kepala).
Apabila halaman tidak dialihkan antara senarai terpaut, susunannya tidak diselaraskan. Sebaliknya, teg akses digunakan untuk menunjukkan sama ada halaman tersebut baru sahaja diakses. Jika halaman dengan teg akses yang ditetapkan dalam senarai terpaut tidak aktif diakses semula, ia akan dialihkan ke senarai terpaut aktif dan teg akses akan dikosongkan. (Malah, untuk mengelakkan konflik akses, halaman tidak bergerak terus dari senarai terpaut tidak aktif ke senarai terpaut aktif, tetapi terdapat struktur perantaraan pagevec yang digunakan sebagai penimbal untuk mengelak daripada mengunci senarai terpaut.)
Terdapat dua jenis teg akses pada halaman Satu ialah teg PG_referenced yang diletakkan dalam page->flags ini ditetapkan apabila halaman itu diakses. Untuk halaman dalam cache cakera (tidak dipetakan), proses pengguna mengaksesnya melalui panggilan sistem seperti baca dan tulis Kod panggilan sistem akan menetapkan bendera PG_referenced halaman yang sepadan.
Untuk halaman yang dipetakan memori, proses pengguna boleh mengaksesnya secara langsung (tanpa melalui kernel), jadi bendera akses dalam kes ini tidak ditetapkan oleh kernel, tetapi oleh mmu. Selepas memetakan alamat maya ke alamat fizikal, mmu akan menetapkan bendera yang diakses pada entri jadual halaman yang sepadan untuk menunjukkan bahawa halaman itu telah diakses. (Dengan cara yang sama, mmu akan meletakkan bendera kotor pada entri jadual halaman yang sepadan dengan halaman yang sedang ditulis, menunjukkan bahawa halaman itu adalah halaman yang kotor.)
Teg akses halaman (termasuk dua teg di atas) akan dikosongkan semasa proses kitar semula halaman oleh PFRA, kerana teg akses jelas sepatutnya mempunyai tempoh sah dan kitaran berjalan PFRA mewakili tempoh sah ini. Tanda PG_referenced dalam page->flags boleh dikosongkan terus, manakala bit yang diakses dalam entri jadual halaman hanya boleh dikosongkan selepas mencari entri jadual halaman yang sepadan melalui halaman (lihat "Pemetaan Terbalik" di bawah).
Jadi, bagaimanakah proses kitar semula mengimbas senarai pautan LRU?
Memandangkan terdapat berbilang kumpulan LRU (terdapat berbilang zon dalam sistem dan setiap zon mempunyai berbilang kumpulan LRU), jika PFRA mengimbas semua LRU untuk setiap kitar semula untuk mencari halaman yang paling layak untuk dikitar semula, kecekapan kitar semula algoritma akan menjadi jelas.
Kaedah pengimbasan yang digunakan oleh kernel Linux PFRA adalah untuk menentukan keutamaan pengimbasan, dan menggunakan keutamaan ini untuk mengira bilangan halaman yang harus diimbas pada setiap LRU. Keseluruhan algoritma kitar semula bermula dengan keutamaan paling rendah, mengimbas halaman yang paling kurang digunakan baru-baru ini dalam setiap LRU, dan kemudian cuba untuk menuntut semula halaman tersebut. Jika bilangan halaman yang mencukupi telah dikitar semula selepas satu imbasan, proses kitar semula akan tamat. Jika tidak, tingkatkan keutamaan dan imbas semula sehingga bilangan halaman yang mencukupi telah dituntut semula. Dan jika bilangan halaman yang mencukupi tidak boleh dikitar semula, keutamaan akan ditingkatkan kepada maksimum, iaitu, semua halaman akan diimbas. Pada masa ini, walaupun bilangan halaman kitar semula masih tidak mencukupi, proses kitar semula akan berakhir.
Setiap kali LRU diimbas, bilangan halaman yang sepadan dengan keutamaan semasa diperoleh daripada senarai pautan aktif dan senarai pautan tidak aktif, dan kemudian halaman ini diproses: jika halaman tidak boleh dikitar semula (seperti disimpan atau dikunci ), ia diletakkan semula Sepadan dengan kepala senarai yang dipautkan (sama seperti di atas, dengan mengandaikan kitar semula bermula dari kepala jika tidak, jika bendera akses halaman ditetapkan, kosongkan bendera dan letakkan halaman kembali ke penghujungnya); senarai terpaut yang sepadan (sama seperti di atas, dengan mengandaikan kitar semula bermula dari kepala jika tidak halaman Ia akan dialihkan daripada senarai terpaut aktif ke senarai terpaut tidak aktif atau dikitar semula daripada senarai terpaut tidak aktif.
Halaman yang diimbas ditentukan berdasarkan sama ada bendera akses ditetapkan atau tidak. Jadi bagaimanakah teg akses ini ditetapkan? Terdapat dua cara ialah apabila pengguna mengakses fail melalui panggilan sistem seperti baca/tulis, kernel mengendalikan halaman dalam cache cakera dan menetapkan bendera akses halaman ini (ditetapkan dalam struktur halaman yang lain); ialah proses mengakses fail secara terus Apabila halaman telah dipetakan, mmu akan secara automatik menambah tag akses (ditetapkan dalam pte jadual halaman) ke entri jadual halaman yang sepadan. Pertimbangan tentang teg akses adalah berdasarkan dua maklumat ini. (Memandangkan halaman, mungkin terdapat beberapa PTE yang merujuknya. Bagaimana untuk mengetahui sama ada PTE ini mempunyai teg akses yang ditetapkan? Kemudian anda perlu mencari PTE ini melalui pemetaan terbalik. Kami akan membincangkannya di bawah.)
PFRA tidak cenderung untuk mengitar semula halaman yang dipetakan tanpa nama daripada senarai terpaut aktif, kerana memori yang digunakan oleh proses pengguna secara amnya agak kecil, dan kitar semula memerlukan pertukaran, yang memerlukan kos yang tinggi. Oleh itu, apabila terdapat banyak baki memori dan sebahagian kecil pemetaan tanpa nama, halaman dalam senarai terpaut aktif yang sepadan dengan pemetaan tanpa nama tidak akan dikitar semula. (Dan jika halaman itu telah diletakkan dalam senarai tidak aktif, anda tidak perlu risau tentangnya lagi.)
Pemetaan terbalik
Seperti ini, semasa proses kitar semula halaman yang dikendalikan oleh PFRA, beberapa halaman dalam senarai tidak aktif LRU mungkin akan dikitar semula.
Jika halaman tidak dipetakan, ia boleh dikitar semula terus ke sistem rakan kongsi (untuk halaman yang kotor, tulis semula dahulu dan kemudian kitar semula). Jika tidak, masih ada satu perkara yang menyusahkan untuk ditangani. Oleh kerana entri jadual halaman tertentu proses pengguna merujuk halaman ini, sebelum mengitar semula halaman tersebut, entri jadual halaman yang merujuk kepadanya mesti diberi penjelasan.
Jadi, persoalan timbul, bagaimana kernel mengetahui entri jadual halaman mana yang dirujuk oleh halaman ini? Untuk melakukan ini, kernel menetapkan pemetaan terbalik dari halaman ke entri jadual halaman.
Vma yang sepadan dengan halaman yang dipetakan boleh didapati melalui pemetaan terbalik, dan jadual halaman yang sepadan boleh didapati melalui vma->vm_mm->pgd. Kemudian dapatkan alamat maya halaman melalui page->index. Kemudian cari entri jadual halaman yang sepadan dari jadual halaman melalui alamat maya. (Teg yang diakses dalam entri jadual halaman yang dinyatakan sebelum ini dicapai melalui pemetaan terbalik.)
Dalam struktur halaman yang sepadan dengan halaman, jika bit terendah halaman->pemetaan ditetapkan, ia adalah halaman pemetaan tanpa nama, dan halaman->pemetaan menunjuk ke struktur anon_vma, sebaliknya, ia adalah halaman pemetaan fail, dan page->pemetaan ialah struktur address_space yang sepadan dengan fail. (Jelas sekali, apabila struktur anon_vma dan struktur ruang_alamat diperuntukkan, alamat mesti diselaraskan, sekurang-kurangnya bit terendah mestilah 0.)
Untuk halaman yang dipetakan tanpa nama, struktur anon_vma berfungsi sebagai pengepala senarai terpaut, menghubungkan semua vmas yang memetakan halaman ini melalui penuding senarai terpaut vma->anon_vma_node. Setiap kali halaman (tanpa nama) dipetakan ke ruang pengguna, vma yang sepadan ditambahkan pada senarai terpaut ini.
Untuk halaman yang dipetakan fail, struktur address_space bukan sahaja mengekalkan pepohon radix untuk menyimpan halaman cache cakera, tetapi juga mengekalkan pepohon carian keutamaan untuk semua vmas yang dipetakan pada fail. Oleh kerana VMA yang dipetakan oleh fail ini tidak semestinya memetakan keseluruhan fail, kemungkinan hanya sebahagian daripada fail dipetakan. Oleh itu, selain mengindeks semua vmas yang dipetakan, pepohon carian keutamaan ini juga perlu mengetahui kawasan mana fail dipetakan ke vmas yang mana. Setiap kali halaman (fail) dipetakan ke ruang pengguna, vma yang sepadan ditambah pada pepohon carian keutamaan ini. Oleh itu, memandangkan halaman pada cache cakera, kedudukan halaman dalam fail boleh diperolehi melalui page->index, dan semua vmas yang dipetakan ke halaman ini boleh didapati melalui pepohon carian keutamaan.
Dalam dua langkah di atas, halaman ajaib->indeks melakukan dua perkara, mendapatkan alamat maya halaman dan mendapatkan lokasi halaman dalam cache cakera fail.
vma->vm_start merekodkan alamat maya pertama vma, vma->vm_pgoff merekodkan offset vma dalam fail pemetaan yang sepadan (atau memori kongsi), dan page->indeks merekodkan halaman dalam fail (atau memori kongsi) mengimbangi dalam.
Offset halaman dalam vma boleh diperolehi melalui vma->vm_pgoff dan page->index, dan alamat maya halaman boleh diperolehi dengan menambah vma->vm_start dan halaman dalam cache cakera fail boleh diperolehi melalui; halaman->indeks.
Halaman bertukar masuk dan keluar
Selepas mencari entri jadual halaman yang merujuk halaman untuk dikitar semula, untuk pemetaan fail, entri jadual halaman yang merujuk halaman boleh dikosongkan terus. Apabila pengguna mengakses alamat ini sekali lagi, pengecualian kesalahan halaman dicetuskan Kod pengendalian pengecualian kemudiannya mengalokasikan semula halaman dan membaca data yang sepadan daripada cakera (mungkin, halaman itu sudah berada dalam cache cakera yang sepadan. Kerana proses lain telah mengaksesnya. pertama). Ini adalah sama seperti kali pertama halaman diakses selepas pemetaan;
Untuk pemetaan tanpa nama, halaman pertama ditulis kembali ke fail swap, dan kemudian indeks halaman dalam fail swap mesti direkodkan dalam entri jadual halaman.
Terdapat bit hadir dalam entri jadual halaman Jika bit ini dikosongkan, mmu menganggap entri jadual halaman tidak sah. Apabila entri jadual halaman tidak sah, bit lain tidak dipedulikan oleh mmu dan boleh digunakan untuk menyimpan maklumat lain. Ia digunakan di sini untuk menyimpan indeks halaman dalam fail swap (sebenarnya nombor fail swap + nombor indeks dalam fail swap).
Proses menukar halaman yang dipetakan tanpa nama kepada fail swap (proses swap-out) sangat serupa dengan proses menulis halaman kotor dalam cache cakera kembali ke fail.
Fail swap juga mempunyai struktur address_space yang sepadan Apabila menukar keluar, halaman yang dipetakan tanpa nama pertama kali diletakkan dalam cache cakera yang sepadan dengan address_space ini, dan kemudian ditulis kembali ke fail swap seperti halaman kotor ditulis semula. Selepas menulis balik selesai, halaman dikeluarkan (ingat, tujuan kami adalah untuk melepaskan halaman).
Jadi mengapa tidak hanya menulis halaman kembali ke fail swap dan bukannya melalui cache cakera? Oleh kerana halaman ini mungkin telah dipetakan beberapa kali, adalah mustahil untuk mengubah suai entri jadual halaman yang sepadan dalam jadual halaman semua proses pengguna sekaligus (ubah suainya kepada indeks halaman dalam fail swap), jadi semasa proses halaman yang dikeluarkan , halaman itu diletakkan buat sementara waktu pada cache cakera.
Tidak semua pengubahsuaian pada entri jadual halaman berjaya (contohnya, halaman telah diakses semula sebelum pengubahsuaian, jadi tidak perlu mengitar semula halaman sekarang), jadi masa yang diperlukan untuk halaman diletakkan dalam cache cakera mungkin juga menjadi sangat panjang.
Begitu juga, proses membaca halaman yang dipetakan tanpa nama daripada fail swap (proses swap-in) juga hampir sama dengan proses membaca data fail.
Mula-mula pergi ke cache cakera yang sepadan untuk melihat sama ada halaman itu ada di sana, kemudian baca dalam fail swap. Data dalam fail juga dibaca ke dalam cache cakera, dan kemudian entri jadual halaman yang sepadan dalam jadual halaman proses pengguna akan ditulis semula untuk menghala terus ke halaman ini.
Halaman ini mungkin tidak dapat diambil daripada cache cakera serta-merta, kerana jika terdapat proses pengguna lain yang turut dipetakan ke halaman ini (entri jadual halaman yang sepadan telah diubah suai untuk diindeks ke dalam fail swap), mereka juga boleh merujuknya di sini. . Halaman tidak boleh diambil daripada cache cakera sehingga tiada entri jadual halaman lain merujuk kepada indeks fail swap.
Pembunuhan pasti yang terakhir
Seperti yang dinyatakan sebelum ini, PFRA mungkin telah mengimbas semua LRU dan masih tidak dapat menuntut semula halaman yang diperlukan. Begitu juga, halaman tidak boleh dikitar semula dalam papak, cache gigi, cache inod, dsb.
Pada masa ini, bagaimana jika sekeping kod kernel tertentu mesti mendapatkan halaman (tanpa halaman, sistem mungkin ranap)? PFRA tidak mempunyai pilihan selain menggunakan pilihan terakhir - OOM (kehabisan ingatan). Apa yang dipanggil OOM adalah untuk mencari proses yang paling tidak penting dan kemudian membunuhnya. Melegakan tekanan sistem dengan melepaskan halaman memori yang diduduki oleh proses ini.
5. Seni bina pengurusan memori
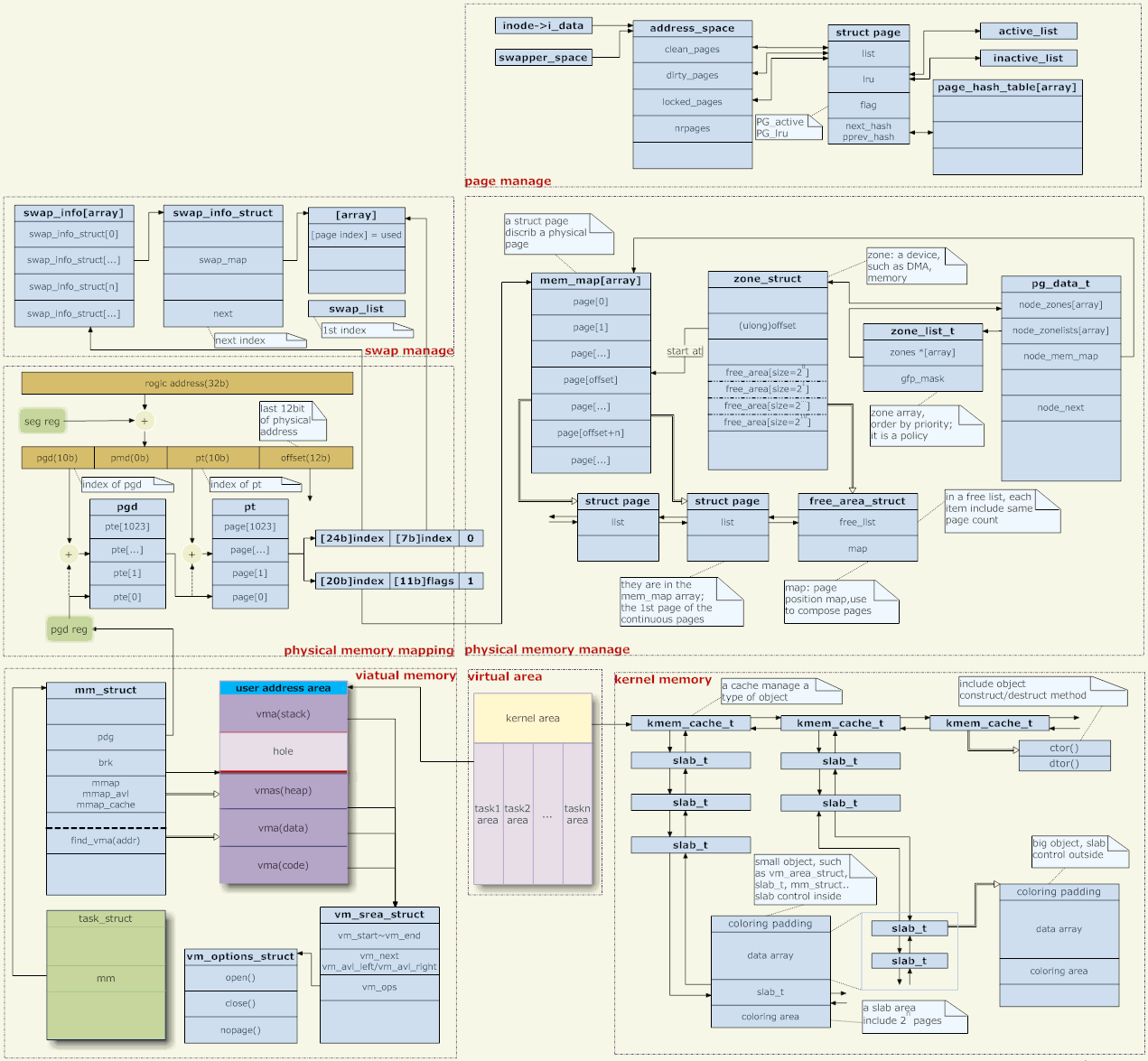
Sedikit perkataan tentang gambar di atas,
Pemetaan alamat
Inti Linux menggunakan pengurusan memori halaman Alamat memori yang diberikan oleh aplikasi adalah alamat maya, yang perlu diubah tahap demi tahap melalui beberapa peringkat jadual halaman sebelum ia menjadi alamat fizikal sebenar.
Fikirkanlah, pemetaan alamat masih menjadi perkara yang menakutkan. Apabila mengakses ruang memori yang diwakili oleh alamat maya, beberapa capaian memori diperlukan untuk mendapatkan entri jadual halaman yang digunakan untuk penukaran dalam setiap peringkat jadual halaman (jadual halaman disimpan dalam memori) sebelum pemetaan boleh diselesaikan. Maksudnya, untuk mencapai capaian memori, memori sebenarnya diakses N+1 kali (N=paras jadual halaman), dan operasi penambahan N perlu dilakukan.
Oleh itu, pemetaan alamat mesti disokong oleh perkakasan, dan mmu (unit pengurusan memori) adalah perkakasan ini. Dan cache diperlukan untuk menyimpan jadual halaman Cache ini ialah TLB (Penimbal lookaside terjemahan).
Walaupun begitu, pemetaan alamat masih mempunyai overhed yang besar. Dengan mengandaikan bahawa kelajuan capaian cache adalah 10 kali ganda daripada memori, kadar hit ialah 40%, dan jadual halaman mempunyai tiga peringkat, maka secara purata satu akses alamat maya menggunakan kira-kira dua masa capaian memori fizikal.
Oleh itu, sesetengah perkakasan terbenam mungkin meninggalkan penggunaan mmu Perkakasan sedemikian boleh menjalankan VxWorks (sistem pengendalian masa nyata terbenam yang sangat cekap), Linux (Linux juga mempunyai pilihan kompilasi untuk melumpuhkan mmu), dan sistem lain.
Tetapi kelebihan menggunakan mmu juga hebat, yang paling penting ialah pertimbangan keselamatan. Setiap proses mempunyai ruang alamat maya bebas dan tidak mengganggu antara satu sama lain. Selepas menyerahkan pemetaan alamat, semua program akan dijalankan dalam ruang alamat yang sama. Oleh itu, pada mesin tanpa mmu, capaian memori di luar sempadan proses boleh menyebabkan ralat yang tidak dapat dijelaskan dalam proses lain, atau malah menyebabkan kernel ranap.
Mengenai isu pemetaan alamat, kernel hanya menyediakan jadual halaman, dan penukaran sebenar diselesaikan oleh perkakasan. Jadi bagaimanakah kernel menjana jadual halaman ini? Ini mempunyai dua aspek, pengurusan ruang alamat maya dan pengurusan ingatan fizikal. (Malah, hanya pemetaan alamat mod pengguna perlu diuruskan dan pemetaan alamat mod kernel dikodkan dengan keras.)
Pengurusan alamat maya
Setiap proses sepadan dengan struktur tugas, yang menunjuk kepada struktur mm, yang merupakan pengurus memori proses. (Untuk utas, setiap utas juga mempunyai struktur tugas, tetapi semuanya menghala ke mm yang sama, jadi ruang alamat dikongsi.)
mm->pgd menunjuk ke memori yang mengandungi jadual halaman Setiap proses mempunyai mm sendiri, dan setiap mm mempunyai jadual halaman sendiri. Oleh itu, apabila proses dijadualkan, jadual halaman ditukar (biasanya terdapat daftar CPU untuk menyimpan alamat jadual halaman, seperti CR3 di bawah X86, dan penukaran jadual halaman adalah untuk menukar nilai daftar). Oleh itu, ruang alamat setiap proses tidak mempengaruhi satu sama lain (kerana jadual halaman berbeza, sudah tentu anda tidak boleh mengakses ruang alamat orang lain. Kecuali untuk memori yang dikongsi, ini sengaja supaya jadual halaman yang berbeza boleh mengakses alamat fizikal yang sama .
Operasi program pengguna pada memori (peruntukan, kitar semula, pemetaan, dll.) adalah semua operasi pada mm, khususnya operasi pada vma (ruang memori maya) pada mm. Vma ini mewakili pelbagai kawasan ruang proses, seperti timbunan, timbunan, kawasan kod, kawasan data, pelbagai kawasan pemetaan, dll.
Operasi program pengguna pada memori tidak akan menjejaskan jadual halaman secara langsung, apatah lagi peruntukan memori fizikal. Sebagai contoh, jika malloc berjaya, ia hanya mengubah vma tertentu Jadual halaman tidak akan berubah, dan peruntukan memori fizikal tidak akan berubah.
Katakan pengguna memperuntukkan memori dan kemudian mengakses memori ini. Oleh kerana pemetaan yang berkaitan tidak direkodkan dalam jadual halaman, CPU menjana pengecualian kesalahan halaman. Kernel menangkap pengecualian dan menyemak sama ada alamat tempat pengecualian berlaku wujud dalam vma undang-undang. Jika tidak, berikan proses "kesalahan pembahagian" dan biarkan ia ranap; jika ya, peruntukkan halaman fizikal dan buat pemetaan untuknya.
Pengurusan ingatan fizikal
Jadi bagaimanakah memori fizikal diperuntukkan?
Pertama sekali, Linux menyokong NUMA (seni bina storan tidak homogen), dan peringkat pertama pengurusan memori fizikal ialah pengurusan media. Struktur pg_data_t menerangkan medium. Secara umumnya, medium pengurusan memori kami hanyalah memori, dan ia adalah seragam, jadi ia boleh dianggap hanya terdapat satu objek pg_data_t dalam sistem.
Terdapat beberapa zon di bawah setiap medium. Umumnya terdapat tiga, DMA, NORMAL dan TINGGI.
DMA: Oleh kerana bas DMA bagi sesetengah sistem perkakasan adalah lebih sempit daripada bas sistem, hanya sebahagian daripada ruang alamat boleh digunakan untuk DMA ini diuruskan dalam kawasan DMA (ini adalah produk mewah). ;
TINGGI: Memori mewah. Dalam sistem 32-bit, ruang alamat ialah 4G Kernel menetapkan bahawa julat 3~4G ialah ruang kernel, dan 0~3G ialah ruang pengguna (setiap proses pengguna mempunyai ruang maya yang begitu besar) (Rajah: tengah bawah). Seperti yang dinyatakan sebelum ini, pemetaan alamat kernel adalah berkod keras, yang bermaksud bahawa jadual halaman yang sepadan 3~4G adalah berkod keras, dan ia dipetakan ke alamat fizikal 0~1G. (Malah, 1G tidak dipetakan, hanya 896M. Baki ruang ditinggalkan untuk memetakan alamat fizikal yang lebih besar daripada 1G, dan bahagian ini jelas tidak berkod keras). Oleh itu, alamat fizikal yang lebih besar daripada 896M tidak mempunyai jadual halaman berkod keras untuk sepadan dengannya. adalah kurang daripada 896M, tiada memori high-end Jika ia adalah mesin 64-bit, tiada memori high-end, kerana ruang alamat sangat besar, dan ruang kepunyaan kernel adalah lebih daripada 1G) ;
BIASA: Ingatan yang bukan milik DMA atau TINGGI dipanggil NORMAL.
Zon_list di atas zon mewakili strategi peruntukan, iaitu keutamaan zon apabila memperuntukkan memori. Sejenis peruntukan memori selalunya bukan sahaja diperuntukkan dalam satu zon Contohnya, apabila memperuntukkan halaman untuk digunakan kernel, keutamaan tertinggi adalah untuk memperuntukkannya daripada NORMAL tidak berfungsi kerana belum diperuntukkan lagi). Wujudkan pemetaan), iaitu strategi peruntukan.
Setiap medium memori mengekalkan mem_map, dan struktur halaman yang sepadan ditubuhkan untuk setiap halaman fizikal dalam medium untuk mengurus memori fizikal.
Setiap zon merekodkan kedudukan permulaannya pada mem_map. Dan halaman percuma dalam zon ini disambungkan melalui kawasan_bebas. Peruntukan memori fizikal datang dari sini Jika anda mengalih keluar halaman dari kawasan_bebas, ia diperuntukkan. (Peruntukan memori kernel adalah berbeza daripada proses pengguna. Penggunaan memori pengguna akan diawasi oleh kernel, dan penggunaan yang tidak betul akan menyebabkan "kesalahan segmentasi"; manakala kernel tidak diawasi dan hanya boleh bergantung pada kesedaran . Jangan gunakan halaman yang anda belum pilih dari free_area )
[Buat pemetaan alamat]
Apabila kernel memerlukan memori fizikal, dalam banyak kes, keseluruhan halaman diperuntukkan Untuk melakukan ini, pilih sahaja halaman dari mem_map di atas. Sebagai contoh, kernel yang disebutkan sebelum ini menangkap pengecualian kesalahan halaman, dan kemudian perlu memperuntukkan halaman untuk mewujudkan pemetaan.
Bercakap tentang ini, akan ada soalan Apabila kernel memperuntukkan halaman dan menetapkan pemetaan alamat, adakah kernel menggunakan alamat maya atau alamat fizikal? Pertama sekali, alamat yang diakses oleh kod kernel adalah alamat maya, kerana arahan CPU menerima alamat maya (pemetaan alamat adalah telus kepada arahan CPU). Walau bagaimanapun, apabila mewujudkan pemetaan alamat, kandungan yang diisi oleh kernel dalam jadual halaman adalah alamat fizikal, kerana matlamat pemetaan alamat adalah untuk mendapatkan alamat fizikal.
Jadi, bagaimanakah kernel mendapat alamat fizikal ini? Malah, seperti yang dinyatakan di atas, halaman dalam mem_map ditubuhkan berdasarkan memori fizikal, dan setiap halaman sepadan dengan halaman fizikal.
Jadi kita boleh katakan bahawa pemetaan alamat maya dilengkapkan oleh struktur halaman di sini, dan mereka memberikan alamat fizikal terakhir. Walau bagaimanapun, struktur halaman jelas diuruskan melalui alamat maya (seperti yang dinyatakan sebelum ini, arahan CPU menerima alamat maya). Jadi, struktur halaman melaksanakan pemetaan alamat maya orang lain, siapa yang akan melaksanakan pemetaan alamat maya struktur halaman itu sendiri? Tiada siapa yang boleh mencapainya.
Ini membawa kepada masalah yang dinyatakan sebelum ini Entri jadual halaman dalam ruang kernel adalah berkod keras. Apabila kernel dimulakan, pemetaan alamat telah dikod keras dalam ruang alamat kernel. Struktur halaman jelas wujud dalam ruang kernel, jadi masalah pemetaan alamatnya telah diselesaikan dengan "hard-coding".
Memandangkan entri jadual halaman dalam ruang kernel berkod keras, masalah lain timbul Memori dalam kawasan NORMAL (atau DMA) mungkin dipetakan ke ruang kernel dan ruang pengguna. Pemetaan ke ruang kernel adalah jelas kerana pemetaan ini berkod keras. Halaman ini juga boleh dipetakan ke ruang pengguna, yang mungkin dalam senario pengecualian yang tiada halaman yang dinyatakan sebelum ini. Halaman yang dipetakan ke ruang pengguna harus diperoleh terlebih dahulu dari kawasan HIGH, kerana kenangan ini menyusahkan kernel untuk diakses, jadi sebaiknya berikannya kepada ruang pengguna. Walau bagaimanapun, kawasan HIGH mungkin kehabisan, atau mungkin tiada kawasan HIGH dalam sistem kerana memori fizikal yang tidak mencukupi pada peranti Oleh itu, pemetaan kawasan NORMAL ke ruang pengguna tidak dapat dielakkan.
Walau bagaimanapun, tiada masalah bahawa memori dalam kawasan NORMAL dipetakan ke ruang kernel dan ruang pengguna, kerana jika halaman sedang digunakan oleh kernel, halaman yang sepadan sepatutnya telah dialih keluar dari kawasan_bebas, jadi pengecualian kesalahan halaman kod pengendalian tidak akan lagi Halaman ini dipetakan ke ruang pengguna. Perkara yang sama berlaku secara terbalik Halaman yang dipetakan ke ruang pengguna secara semula jadi telah dialih keluar dari free_area, dan kernel tidak akan menggunakan halaman ini lagi.
Pengurusan ruang kernel
Selain menggunakan keseluruhan halaman memori, kadangkala kernel juga perlu memperuntukkan ruang dalam sebarang saiz seperti program pengguna menggunakan malloc. Fungsi ini dilaksanakan oleh sistem papak.
Papak adalah bersamaan dengan menubuhkan kumpulan objek untuk beberapa objek struktur yang biasa digunakan dalam kernel, seperti kumpulan yang sepadan dengan struktur tugas, kumpulan yang sepadan dengan struktur mm, dan sebagainya.
Slab juga mengekalkan kumpulan objek umum, seperti kumpulan objek "saiz 32 bait", kumpulan objek "saiz 64 bait", dsb. Fungsi kmalloc yang biasa digunakan dalam kernel (serupa dengan malloc dalam mod pengguna) diperuntukkan dalam kumpulan objek umum ini.
Sebagai tambahan kepada ruang memori yang sebenarnya digunakan oleh objek, papak juga mempunyai struktur kawalan yang sepadan. Terdapat dua cara untuk mengaturnya. Jika objek lebih besar, struktur kawalan menggunakan halaman khas untuk menyimpannya; jika objek lebih kecil, struktur kawalan menggunakan halaman yang sama dengan ruang objek.
Selain slab, Linux 2.6 turut memperkenalkan mempool (memory pool). Tujuannya ialah: kami tidak mahu objek tertentu gagal diperuntukkan kerana memori tidak mencukupi, jadi kami memperuntukkan beberapa lebih awal dan menyimpannya dalam mempool. Dalam keadaan biasa, sumber dalam mempool tidak akan disentuh apabila memperuntukkan objek, dan akan diperuntukkan melalui papak seperti biasa. Apabila memori sistem kekurangan bekalan dan memori tidak boleh diperuntukkan melalui papak, kandungan mempool akan digunakan.
Halaman bertukar masuk dan keluar(Gambar: atas kanan)
Pertukaran halaman masuk dan keluar adalah satu lagi sistem yang sangat kompleks. Menukar keluar halaman memori ke cakera dan memetakan fail cakera ke memori adalah dua proses yang hampir sama (motivasi di sebalik menukar halaman memori ke cakera adalah untuk memuatkannya semula ke dalam memori dari cakera pada masa hadapan). Jadi swap menggunakan semula beberapa mekanisme subsistem fail.
Menukar halaman masuk dan keluar adalah perkara yang sangat intensif CPU dan IO, tetapi disebabkan oleh sebab sejarah bahawa memori mahal, kita perlu menggunakan cakera untuk mengembangkan memori. Tetapi sekarang memori semakin murah, kita boleh memasang beberapa gigabait memori dengan mudah dan kemudian mematikan sistem swap. Oleh itu, pelaksanaan swap adalah sangat sukar untuk diterokai, jadi saya tidak akan menerangkan butiran di sini. (Lihat juga: "Analisis Ringkas Kitar Semula Halaman Kernel Linux")
[Pengurusan Memori Ruang Pengguna]
Malloc ialah fungsi perpustakaan libc, dan program pengguna biasanya menggunakannya (atau fungsi serupa) untuk memperuntukkan ruang memori.
Terdapat dua cara untuk libc memperuntukkan memori Satu ialah melaraskan saiz timbunan, dan satu lagi adalah untuk mmap kawasan memori maya baharu (timbunan itu juga merupakan vma).
Dalam kernel, timbunan ialah vma dengan hujung tetap dan hujung boleh ditarik balik (gambar: kiri tengah). Hujung boleh skala dilaraskan melalui panggilan sistem brk. Libc menguruskan ruang timbunan Apabila pengguna memanggil malloc untuk memperuntukkan memori, libc cuba memperuntukkannya daripada timbunan sedia ada. Jika ruang timbunan tidak mencukupi, tambahkan ruang timbunan melalui brk.
Apabila pengguna membebaskan ruang yang diperuntukkan, libc boleh mengurangkan ruang timbunan melalui brk. Walau bagaimanapun, adalah mudah untuk meningkatkan ruang timbunan tetapi sukar untuk mengurangkannya. Pertimbangkan situasi di mana ruang pengguna telah memperuntukkan 10 blok memori secara berterusan, dan 9 blok pertama telah dibebaskan. Pada masa ini, walaupun blok ke-10 yang tidak percuma hanya bersaiz 1 bait, libc tidak dapat mengurangkan saiz timbunan. Kerana hanya satu hujung cerucuk boleh dibesarkan dan dikecutkan, dan bahagian tengahnya tidak boleh dilubangkan. Blok ingatan ke-10 menduduki hujung timbunan yang boleh skala Saiz timbunan tidak boleh dikurangkan, dan sumber yang berkaitan tidak boleh dikembalikan kepada kernel.
Apabila pengguna mallocs memori yang besar, libc akan memetakan vma baharu melalui panggilan sistem mmap. Oleh kerana pelarasan saiz timbunan dan pengurusan ruang masih menyusahkan, ia akan menjadi lebih mudah untuk membina semula vma (masalah percuma yang dinyatakan di atas juga merupakan salah satu sebabnya).
Jadi mengapa tidak sentiasa mmap vma baharu semasa malloc? Pertama, untuk peruntukan dan kitar semula ruang kecil, ruang timbunan yang diuruskan oleh libc sudah boleh memenuhi keperluan, dan tidak perlu membuat panggilan sistem setiap kali. Dan vma adalah berdasarkan halaman, dan minimum adalah untuk memperuntukkan satu halaman kedua, terlalu banyak vma akan mengurangkan prestasi sistem. Pengecualian kesalahan halaman, penciptaan dan pemusnahan vma, saiz semula ruang timbunan, dll. semuanya memerlukan operasi pada vma Anda perlu mencari vma (atau yang) yang perlu dikendalikan di antara semua vma dalam proses semasa. Terlalu banyak vmas pasti akan membawa kepada kemerosotan prestasi. (Apabila proses mempunyai lebih sedikit VMA, kernel menggunakan senarai terpaut untuk mengurus VMA; apabila terdapat lebih banyak VMA, pokok merah-hitam digunakan sebaliknya.)
[Timbunan pengguna]
Seperti timbunan, timbunan juga adalah vma (gambar: kiri tengah) vma ini ditetapkan pada satu hujung dan boleh dilanjutkan di hujung yang lain (perhatian, ia tidak boleh dikontrak). Istimewanya vma ini tiada sistem call seperti brk untuk meregangkan vma ini secara automatik.
Apabila alamat maya yang diakses oleh pengguna melebihi vma ini, kernel secara automatik akan meningkatkan vma apabila mengendalikan pengecualian kesalahan halaman. Kernel akan menyemak daftar tindanan semasa (seperti ESP), dan alamat maya yang diakses tidak boleh melebihi ESP tambah n (n ialah bilangan bait maksimum yang boleh ditolak oleh arahan tolak CPU ke dalam tindanan pada satu masa). Dalam erti kata lain, kernel menggunakan ESP sebagai penanda aras untuk menyemak sama ada capaian di luar sempadan.
Walau bagaimanapun, nilai ESP boleh dibaca dan ditulis secara bebas oleh program mod pengguna Bagaimana jika program pengguna melaraskan ESP dan menjadikan timbunan sangat besar? Terdapat satu set konfigurasi tentang sekatan proses dalam kernel, termasuk konfigurasi saiz tindanan hanya boleh menjadi begitu besar, dan jika ia lebih besar, ralat akan berlaku.
Untuk sesuatu proses, tindanan secara amnya boleh diregangkan agak besar (cth: 8MB). Tetapi bagaimana dengan benang?
Pertama sekali, apa yang berlaku dengan timbunan benang? Seperti yang dinyatakan sebelum ini, mm benang berkongsi proses induknya. Walaupun tindanan ialah vma dalam mm, benang tidak boleh berkongsi vma ini dengan proses induknya (dua entiti yang sedang berjalan jelas tidak perlu berkongsi tindanan). Oleh itu, apabila benang dicipta, perpustakaan benang mencipta vma baharu melalui mmap, yang digunakan sebagai tindanan benang (biasanya lebih besar daripada: 2M).
Ia boleh dilihat bahawa timbunan benang bukanlah timbunan sebenar dalam erti kata Ia adalah kawasan tetap dan mempunyai kapasiti yang sangat terhad.
Melalui artikel ini, anda harus mempunyai pemahaman asas tentang pengurusan memori Linux Ia merupakan cara yang berkesan untuk menukar dan memperuntukkan memori maya dan memori fizikal, dan boleh menyesuaikan diri dengan pelbagai keperluan sistem Linux. Sudah tentu, pengurusan memori tidak statik Ia perlu disesuaikan dan diubah suai mengikut platform perkakasan dan versi kernel tertentu. Ringkasnya, pengurusan memori adalah komponen yang sangat diperlukan dalam sistem Linux dan layak untuk kajian dan penguasaan mendalam anda.
Atas ialah kandungan terperinci Pengurusan memori Linux: bagaimana untuk menukar dan memperuntukkan memori maya dan memori fizikal. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



