


"Belajar daripada sejarah boleh membantu kita memahami jatuh bangunnya sejarah kemajuan manusia ialah proses evolusi diri yang sentiasa mengambil pengalaman lalu dan menolak sempadan keupayaan. Kita belajar daripada kegagalan masa lalu dan membetulkan kesilapan; kita belajar daripada pengalaman yang berjaya untuk meningkatkan kecekapan dan keberkesanan. Evolusi diri ini berjalan melalui semua aspek kehidupan: meringkaskan pengalaman untuk menyelesaikan masalah kerja, menggunakan corak untuk meramal cuaca, kami terus belajar dan berkembang dari masa lalu.
Berjaya mengekstrak pengetahuan daripada pengalaman lalu dan mengaplikasikannya pada cabaran masa depan adalah peristiwa penting dalam perjalanan menuju evolusi manusia. Jadi dalam era kecerdasan buatan, bolehkah ejen AI melakukan perkara yang sama?
Dalam beberapa tahun kebelakangan ini, model bahasa seperti GPT dan LLaMA telah menunjukkan keupayaan yang menakjubkan dalam menyelesaikan tugas yang rumit. Walau bagaimanapun, walaupun mereka boleh menggunakan alat untuk menyelesaikan tugasan tertentu, mereka sememangnya kekurangan cerapan dan pembelajaran daripada kejayaan dan kegagalan masa lalu. Ini seperti robot yang hanya boleh menyelesaikan tugasan tertentu Walaupun ia berfungsi dengan baik dalam tugasan semasa, ia tidak boleh meminta pengalaman masa lalunya untuk membantu apabila berhadapan dengan cabaran baharu. Oleh itu, kita perlu mengembangkan lagi model-model ini supaya mereka dapat mengumpul pengetahuan dan pengalaman serta mengaplikasikannya dalam situasi baharu. Dengan memperkenalkan mekanisme ingatan dan pembelajaran, kami boleh menjadikan model ini lebih komprehensif dalam kecerdasan, mampu bertindak balas secara fleksibel dalam tugas dan situasi yang berbeza, dan mendapat inspirasi daripada pengalaman lalu. Ini akan menjadikan model bahasa lebih berkuasa dan boleh dipercayai serta membantu memajukan pembangunan kecerdasan buatan.
Sebagai tindak balas kepada masalah ini, pasukan bersama dari Tsinghua University, Hong Kong University, Renmin University dan Wall-Facing Intelligence baru-baru ini mencadangkan strategi evolusi diri ejen pintar baharu: Investigate-Consolidate-Exploit, ICE). Ia bertujuan untuk meningkatkan kebolehsuaian dan fleksibiliti ejen AI melalui evolusi diri merentas tugas. Ia bukan sahaja dapat meningkatkan kecekapan dan keberkesanan ejen dalam mengendalikan tugas-tugas baharu, tetapi juga mengurangkan permintaan untuk keupayaan model asas ejen dengan ketara.
Kemunculan strategi ini sememangnya telah membuka lembaran baharu dalam evolusi diri ejen pintar, dan juga menandakan satu lagi langkah ke hadapan untuk kami mencapai ejen autonomi sepenuhnya. .

Untuk mempromosikan penggunaan semula pengalaman lepas dengan lebih baik, pengarang mula-mula membahagikan strategi evolusi kepada dua aspek dalam kertas kerja ini. Secara khusus, penulis mengambil struktur perancangan tugas pokok dan pelaksanaan alat rantai ReACT dalam seni bina ejen XAgent sebagai contoh untuk memperkenalkan kaedah pelaksanaan strategi ICE secara terperinci. 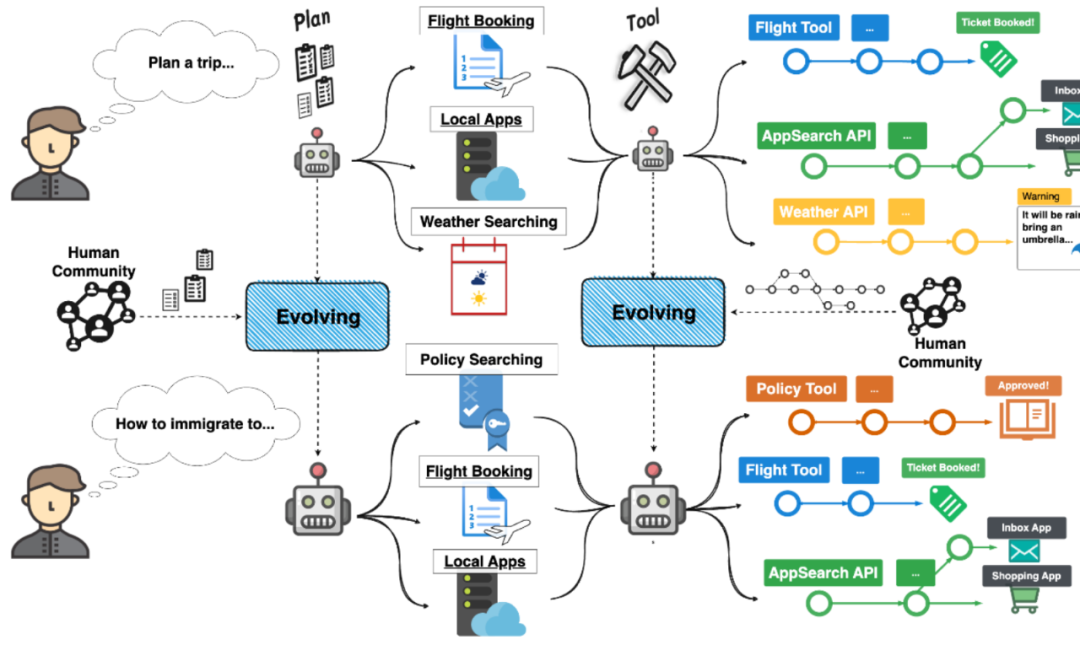
Untuk perancangan misi, evolusi diri dibahagikan kepada tiga peringkat berikut mengikut ICE:
Strategi evolusi kendiri ICE untuk pelaksanaan tugas ejen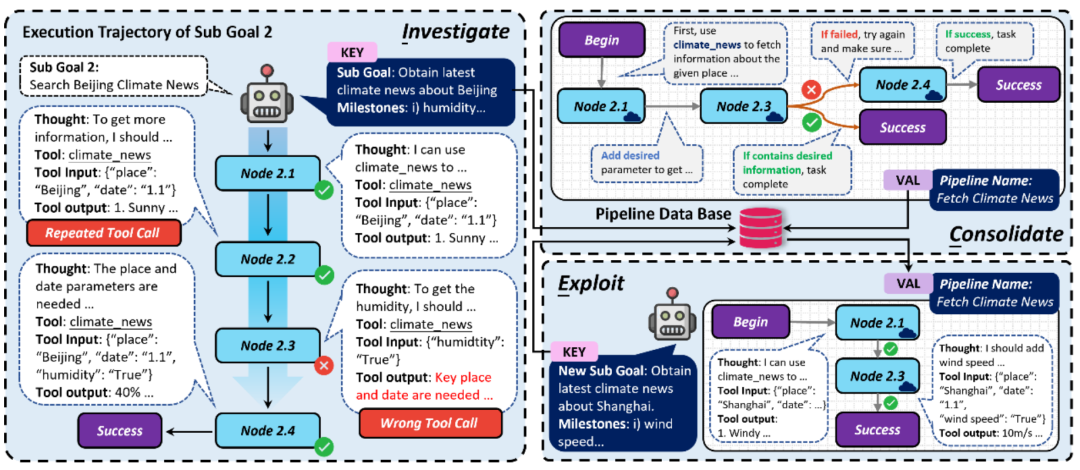
peringkat explorasi
Pengarang menguji strategi evolusi kendiri ICE yang dicadangkan dalam Bilangan panggilan model, dengan itu meningkatkan kecekapan dan mengurangkan overhed.
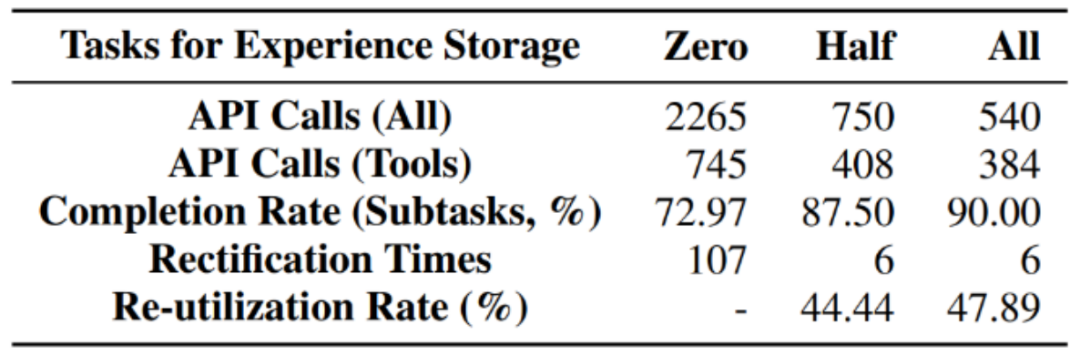
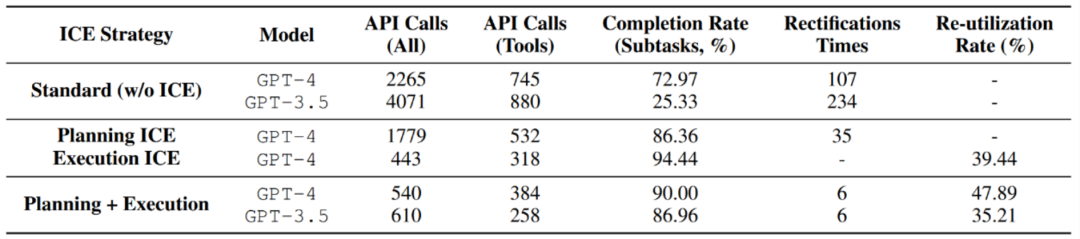 Pada masa yang sama, pengarang juga menjalankan eksperimen ablasi tambahan: apabila pengalaman penyimpanan secara beransur-ansur meningkat , adakah prestasi ejen semakin baik dan baik? Jawapannya ya. Daripada pengalaman sifar, separuh pengalaman, kepada pengalaman penuh, bilangan panggilan ke model asas berkurangan secara beransur-ansur, manakala penyiapan subtugasan meningkat secara beransur-ansur, dan kadar penggunaan semula juga meningkat. Ini menunjukkan bahawa lebih banyak pengalaman lepas boleh menggalakkan pelaksanaan ejen dengan lebih baik dan mencapai kesan skala.
Pada masa yang sama, pengarang juga menjalankan eksperimen ablasi tambahan: apabila pengalaman penyimpanan secara beransur-ansur meningkat , adakah prestasi ejen semakin baik dan baik? Jawapannya ya. Daripada pengalaman sifar, separuh pengalaman, kepada pengalaman penuh, bilangan panggilan ke model asas berkurangan secara beransur-ansur, manakala penyiapan subtugasan meningkat secara beransur-ansur, dan kadar penggunaan semula juga meningkat. Ini menunjukkan bahawa lebih banyak pengalaman lepas boleh menggalakkan pelaksanaan ejen dengan lebih baik dan mencapai kesan skala.
Statistik keputusan eksperimen ablasi prestasi tugasan set ujian di bawah jumlah simpanan pengalaman berbeza
 Kesimpulan
Kesimpulan
Atas ialah kandungan terperinci Mengambil langkah lebih dekat untuk melengkapkan autonomi, Universiti Tsinghua dan strategi evolusi kendiri silang tugas baharu HKU membolehkan ejen belajar untuk 'belajar daripada pengalaman'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



