


Pembenaman teks (pembenaman perkataan) ialah teknologi asas dalam bidang pemprosesan bahasa semula jadi (NLP) Ia boleh memetakan teks kepada ruang semantik dan menukarnya kepada perwakilan vektor padat. Kaedah ini telah digunakan secara meluas dalam pelbagai tugas NLP, termasuk mendapatkan maklumat (IR), menjawab soalan, pengiraan persamaan teks dan sistem pengesyoran. Melalui pembenaman teks, kita boleh lebih memahami maksud dan hubungan teks, seterusnya meningkatkan keberkesanan tugas NLP.
Dalam bidang pencarian maklumat (IR), peringkat pertama perolehan biasanya menggunakan pembenaman teks untuk pengiraan persamaan. Ia berfungsi dengan memanggil semula set kecil dokumen calon dalam korpus berskala besar dan kemudian melakukan pengiraan yang terperinci. Pengambilan semula berasaskan benam juga merupakan komponen penting dalam Penjanaan Pengukuhan Pengambilan (RAG). Ia membolehkan model bahasa besar (LLM) mengakses pengetahuan luaran dinamik tanpa mengubah suai parameter model. Dengan cara ini, sistem IR boleh menggunakan pembenaman teks dan pengetahuan luaran dengan lebih baik untuk meningkatkan hasil perolehan semula.
Walaupun kaedah pembelajaran pembenaman teks awal seperti word2vec dan GloVe digunakan secara meluas, ciri statiknya mengehadkan keupayaan untuk menangkap maklumat kontekstual yang kaya dalam bahasa semula jadi. Walau bagaimanapun, dengan peningkatan model bahasa pra-latihan, beberapa kaedah baharu seperti Sentence-BERT dan SimCSE telah mencapai kemajuan ketara pada set data inferens bahasa semula jadi (NLI) dengan memperhalusi BERT untuk mempelajari pembenaman teks. Kaedah-kaedah ini memanfaatkan keupayaan sedar konteks BERT untuk lebih memahami semantik dan konteks teks, sekali gus meningkatkan kualiti dan ekspresif benam teks. Melalui gabungan pra-latihan dan penalaan halus, kaedah ini boleh mempelajari maklumat semantik yang lebih kaya daripada korpora berskala besar untuk pemprosesan bahasa semula jadi
Untuk meningkatkan prestasi dan keteguhan pembenaman teks, kaedah lanjutan seperti E5 dan BGE Berbilang peringkat latihan telah digunakan. Mereka mula-mula dilatih terlebih dahulu mengenai berbilion-bilion pasangan teks yang diselia dengan lemah dan kemudian diperhalusi pada beberapa set data beranotasi. Strategi ini boleh meningkatkan prestasi pembenaman teks dengan berkesan.
Kaedah pelbagai peringkat sedia ada masih mempunyai dua kelemahan:
1. Membina saluran paip latihan pelbagai peringkat yang kompleks memerlukan banyak kerja kejuruteraan untuk menguruskan pasangan korelasi yang banyak.
2. Penalaan halus bergantung pada set data yang dikumpulkan secara manual, yang selalunya dihadkan oleh kepelbagaian tugas dan liputan bahasa.
Kebanyakan kaedah menggunakan pengekod gaya BERT dan mengabaikan kemajuan latihan LLM yang lebih baik dan teknik berkaitan.
Pasukan penyelidik Microsoft baru-baru ini mencadangkan kaedah latihan pembenaman teks yang mudah dan cekap untuk mengatasi beberapa kelemahan kaedah sebelumnya. Pendekatan ini tidak memerlukan reka bentuk saluran paip yang kompleks atau set data yang dibina secara manual, tetapi memanfaatkan LLM untuk mensintesis data teks yang pelbagai. Dengan pendekatan ini, mereka dapat menjana pembenaman teks berkualiti tinggi untuk ratusan ribu tugas pembenaman teks dalam hampir 100 bahasa, manakala keseluruhan proses latihan mengambil masa kurang daripada 1,000 langkah.

Pautan kertas: https://arxiv.org/abs/2401.00368
Secara khusus, penyelidik menggunakan dua langkah menggesa kumpulan tugasan LLM, dan mula-mula menggesa strategi calon menggesa LLM menjana data untuk tugasan yang diberikan daripada kumpulan.
Untuk merangkumi senario aplikasi yang berbeza, para penyelidik mereka bentuk berbilang templat segera untuk setiap jenis tugasan dan menggabungkan data yang dijana oleh templat yang berbeza untuk meningkatkan kepelbagaian.
Hasil eksperimen membuktikan bahawa apabila memperhalusi "hanya data sintetik", Mistral-7B mencapai prestasi yang sangat kompetitif pada penanda aras BEIR dan MTEB apabila memperhalusi kedua-dua data sintetik dan beranotasi ditambah, Mencapai prestasi sota.
Menggunakan model bahasa besar (LLM) terkini seperti GPT-4 untuk mensintesis data semakin mendapat perhatian , yang boleh meningkatkan model dalam kepelbagaian keupayaan berbilang tugas dan berbilang bahasa, yang kemudiannya boleh melatih pembenaman teks yang lebih mantap yang berfungsi dengan baik dalam pelbagai tugas hiliran (seperti perolehan semula semantik, pengiraan persamaan teks, pengelompokan).
Untuk menjana data sintetik yang pelbagai, para penyelidik mencadangkan taksonomi mudah yang mula-mula mengklasifikasikan tugasan benam dan kemudian menggunakan templat segera yang berbeza untuk setiap jenis tugas.
Tugas Asimetri
Termasuk tugas yang pertanyaan dan dokumen berkaitan secara semantik tetapi tidak menghuraikan satu sama lain.
Berdasarkan panjang pertanyaan dan dokumen, penyelidik membahagikan lagi tugas asimetri kepada empat subkategori: padanan pendek-panjang (pertanyaan pendek dan dokumen panjang, senario tipikal dalam enjin carian komersial), padanan panjang-pendek, pendek -Perlawanan pendek dan perlawanan panjang-panjang.
Untuk setiap subkategori, para penyelidik mereka bentuk templat gesaan dua langkah, mula-mula menggesa LLM untuk membuat sumbang saran senarai tugas, dan kemudian menghasilkan contoh khusus bagi syarat yang ditentukan tugasan kebanyakannya adalah koheren; Kualitinya sangat tinggi.

Dalam percubaan awal, para penyelidik juga cuba menggunakan satu gesaan untuk menjana takrifan tugas dan pasangan dokumen pertanyaan, tetapi kepelbagaian data tidak sebaik kaedah dua langkah yang dinyatakan di atas.
Tugas simetri
terutamanya termasuk pertanyaan dan dokumen dengan semantik yang serupa tetapi bentuk permukaan yang berbeza.
Dua senario aplikasi dikaji dalam artikel ini: persamaan teks semantik eka bahasa (STS) dan perolehan dwi-teks, dan dua templat segera yang berbeza direka untuk setiap senario, disesuaikan mengikut matlamat khusus mereka sejak takrifan tugasan adalah agak mudah, langkah sumbang saran boleh ditinggalkan.
Untuk meningkatkan lagi kepelbagaian kata gesaan dan mempertingkatkan kepelbagaian data sintetik, penyelidik menambahkan beberapa ruang letak pada setiap papan gesaan dan mengambil sampel secara rawak pada masa jalanan Contohnya, "{query_length}" mewakili daripada Sampel daripada set "{kurang daripada 5 perkataan, 5-10 perkataan, sekurang-kurangnya 10 perkataan}".
Untuk menjana data berbilang bahasa, penyelidik mengambil sampel nilai "{language}" daripada senarai bahasa XLM-R, memberikan lebih berat kepada bahasa sumber tinggi yang tidak mematuhi yang dipratakrifkan; Format JSON akan Dibuang semasa penghuraian juga dialih keluar berdasarkan padanan rentetan yang tepat.
Memandangkan pasangan dokumen pertanyaan yang berkaitan, gunakan pertanyaan asal q+ untuk menjana arahan baharu q_inst, dengan "{task_definition}" ialah pemegang tempat untuk membenamkan perihalan satu ayat bagi simbol tugas.
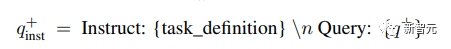
Untuk data sintetik yang dijana, output langkah sumbang saran digunakan untuk set data lain, seperti MS-MARCO, penyelidik mencipta definisi tugas secara manual dan menggunakannya pada semua pertanyaan dalam set data tanpa mengubah suai fail; Sebarang awalan perintah di hujungnya.
Dengan cara ini indeks dokumen diprabina dan tugasan yang perlu dilaksanakan boleh disesuaikan dengan menukar hanya bahagian pertanyaan.
Memandangkan LLM pra-latihan, tambahkan token [EOS] pada penghujung pertanyaan dan dokumen, dan kemudian masukkannya ke dalam LLM untuk mendapatkan pertanyaan dan pembenaman dokumen dengan mendapatkan vektor lapisan terakhir [EOS].
Kemudian gunakan kerugian InfoNCE standard untuk mengira kerugian bagi negatif intra-batch dan negatif keras.
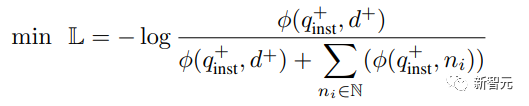
di mana ℕ mewakili set semua negatif,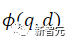 digunakan untuk mengira skor padanan antara pertanyaan dan dokumen, t ialah hiperparameter suhu, ditetapkan pada 0.02 dalam eksperimen
digunakan untuk mengira skor padanan antara pertanyaan dan dokumen, t ialah hiperparameter suhu, ditetapkan pada 0.02 dalam eksperimen
Hasil Eksperimen , yang menggunakan sejumlah 180 juta token.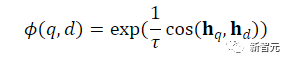
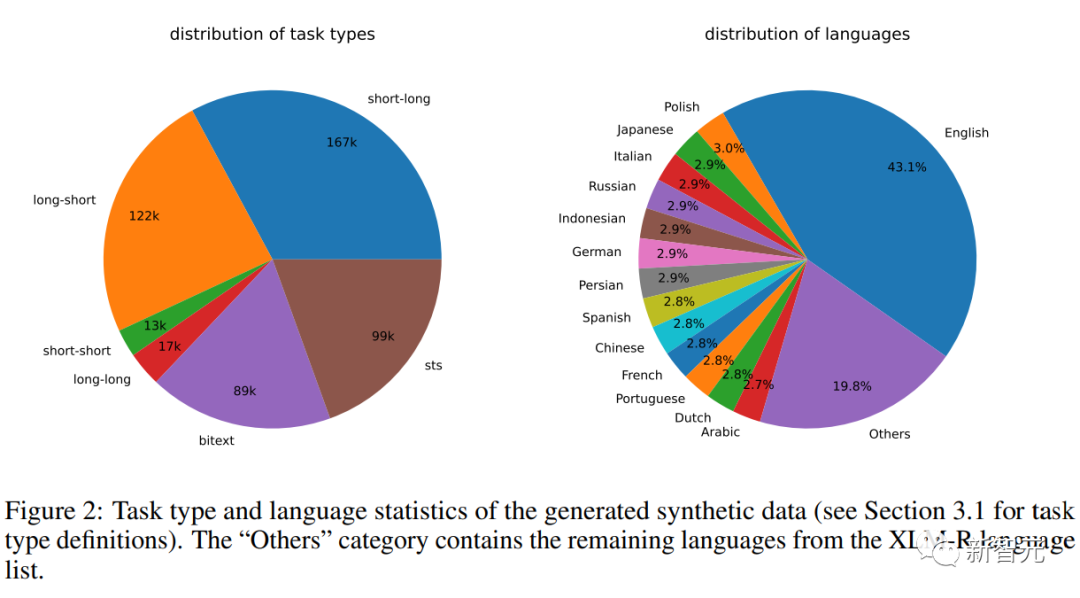
Dari segi kualiti data, penyelidik mendapati bahawa beberapa output GPT-3.5-Turbo tidak mengikut garis panduan yang dinyatakan dalam templat segera, tetapi walaupun demikian, kualiti keseluruhan masih boleh diterima dan awalan. eksperimen juga membuktikan bahawa menggunakan ini Manfaat subset data.
Penalaan halus dan penilaian model
Para penyelidik menggunakan kerugian di atas untuk memperhalusi Mistral-7B yang telah dilatih untuk 1 zaman, mengikuti kaedah latihan RankLLaMA, dan menggunakan LoRA dengan pangkat .
Untuk mengurangkan lagi keperluan memori GPU, teknologi seperti titik semakan kecerunan, latihan ketepatan campuran dan DeepSpeed ZeRO-3 digunakan.
Dari segi data latihan, kedua-dua data sintetik yang dijana dan 13 set data awam telah digunakan, menghasilkan kira-kira 1.8 juta contoh selepas pensampelan.
Untuk perbandingan yang adil dengan beberapa kerja terdahulu, penyelidik juga melaporkan hasil apabila satu-satunya penyeliaan anotasi ialah set data kedudukan bab MS-MARCO, dan juga menilai model pada penanda aras MTEB.
Seperti yang anda lihat dalam jadual di bawah, model "E5mistral-7B + data penuh" yang diperolehi dalam artikel mencapai skor purata tertinggi dalam penanda aras MTEB, iaitu 2.4 lebih tinggi daripada sebelumnya. titik model paling maju.
Dalam tetapan "dengan data sintetik sahaja", tiada data beranotasi digunakan untuk latihan, tetapi prestasinya masih sangat kompetitif.
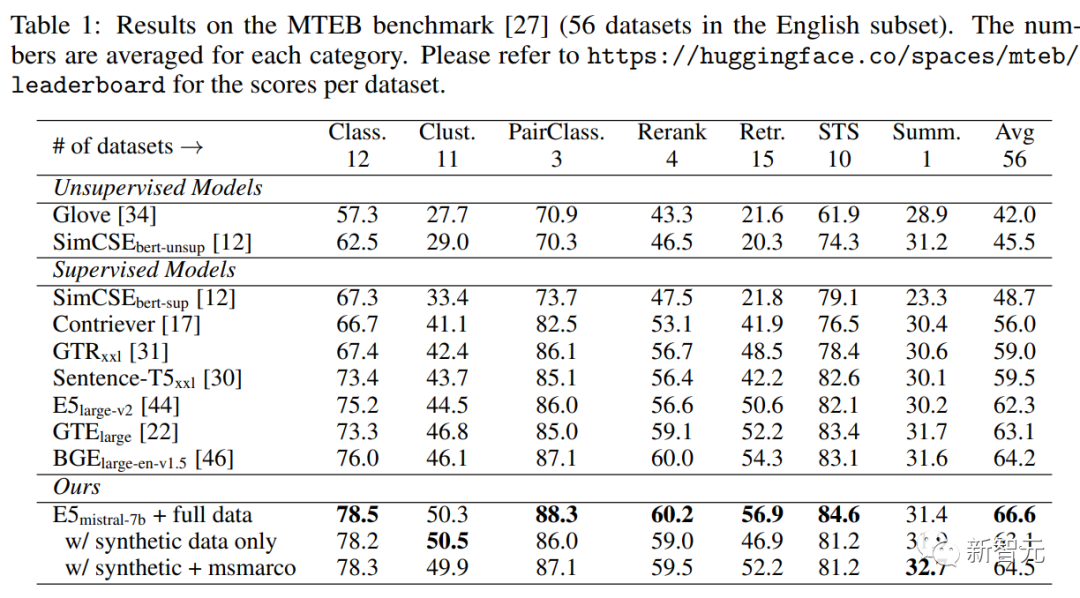
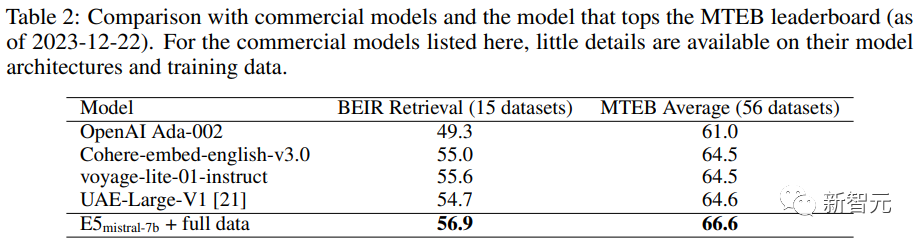
Para penyelidik juga membandingkan beberapa model pembenaman teks komersial, tetapi kekurangan ketelusan dan dokumentasi model ini menghalang perbandingan yang adil.
Walau bagaimanapun, ia dapat dilihat daripada hasil perbandingan prestasi perolehan pada penanda aras BEIR bahawa model terlatih itu adalah lebih baik daripada model komersial semasa secara besar-besaran.
Penemuan semula berbilang bahasa
Untuk menilai keupayaan pelbagai bahasa model, penyelidik menjalankan penilaian ke atas set data MIRACL yang mengandungi pertanyaan dan 18 bahasa penghakiman manusia.
Hasilnya menunjukkan bahawa model itu mengatasi mE5-besar dalam bahasa sumber tinggi, terutamanya dalam bahasa Inggeris, dan prestasinya lebih baik, walau bagaimanapun, untuk bahasa sumber rendah, model itu masih tidak sesuai berbanding dengan asas mE5 .
Para penyelidik mengaitkan ini dengan Mistral-7B yang telah dilatih terutamanya pada data bahasa Inggeris, kaedah yang boleh digunakan oleh model berbilang bahasa ramalan untuk merapatkan jurang ini.
Atas ialah kandungan terperinci Tiada anotasi manual diperlukan! LLM menyokong pembelajaran pembenaman teks: menyokong 100 bahasa dengan mudah dan menyesuaikan diri dengan ratusan ribu tugas hiliran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



