


Pada tahun 2023, status Transformer, pemain dominan dalam bidang model besar AI, akan mula dicabar. Seni bina baharu yang dipanggil "Mamba" telah muncul Ia adalah model ruang keadaan terpilih yang setanding dengan Transformer dalam pemodelan bahasa, dan mungkin mengatasinya. Pada masa yang sama, Mamba boleh mencapai penskalaan linear apabila panjang konteks meningkat, yang membolehkannya mengendalikan jujukan panjang jutaan perkataan dan meningkatkan daya pemprosesan inferens sebanyak 5 kali apabila memproses data sebenar. Peningkatan prestasi terobosan ini menarik perhatian dan membawa kemungkinan baharu kepada pembangunan bidang AI.
Lebih sebulan selepas dikeluarkan, Mamba mula menunjukkan pengaruhnya secara beransur-ansur dan melahirkan banyak projek seperti MoE-Mamba, Vision Mamba, VMamba, U-Mamba, MambaByte, dll. Mamba telah menunjukkan potensi yang besar dalam mengatasi kelemahan Transformer secara berterusan. Perkembangan ini menunjukkan perkembangan dan kemajuan berterusan Mamba, membawa kemungkinan baharu kepada bidang kecerdasan buatan.
Walau bagaimanapun, "bintang" yang semakin meningkat ini menghadapi kemunduran pada mesyuarat ICLR 2024. Keputusan awam terkini menunjukkan bahawa kertas Mamba masih belum selesai Kami hanya dapat melihat namanya dalam lajur keputusan yang belum selesai, dan kami tidak dapat menentukan sama ada ia ditangguhkan atau ditolak.

Secara keseluruhan, Mamba menerima penilaian daripada empat pengulas, iaitu 8/8/6/3 masing-masing. Sesetengah orang berkata ia benar-benar membingungkan untuk masih ditolak selepas menerima penarafan sedemikian.

Untuk memahami sebabnya, kita perlu melihat apa yang dikatakan oleh pengulas yang memberi markah rendah.
Halaman semakan kertas: https://openreview.net/forum?id=AL1fq05o7H
Dalam maklum balas ulasan, pengulas yang memberi skor "3: tolak, tidak cukup bagus" menjelaskan beberapa pendapat tentang Mamba:
Pemikiran tentang reka bentuk model:
Pemikiran tentang eksperimen:
Di samping itu, pengulas lain juga menunjukkan kelemahan Mamba: model itu masih mempunyai keperluan memori sekunder semasa latihan seperti Transformers.
Selepas merumuskan pendapat semua pengulas, pasukan pengarang juga menyemak dan menambah baik kandungan kertas kerja, dan menambah keputusan dan analisis eksperimen baharu:
Pengarang memuat turun model H3 terlatih dengan saiz parameter 125M-2.7B dan menjalankan beberapa siri penilaian. Mamba adalah jauh lebih baik dalam semua penilaian bahasa Perlu diingat bahawa model H3 ini adalah model hibrid menggunakan perhatian kuadratik, manakala model tulen pengarang hanya menggunakan lapisan Mamba masa linear adalah lebih baik dalam semua penunjuk.
Perbandingan penilaian dengan model H3 pra-terlatih adalah seperti berikut:
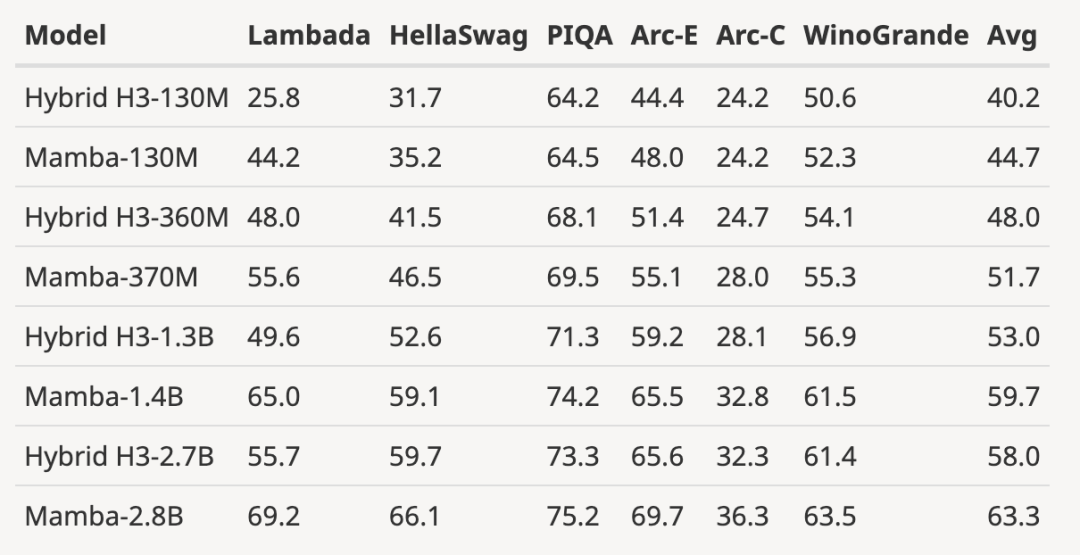
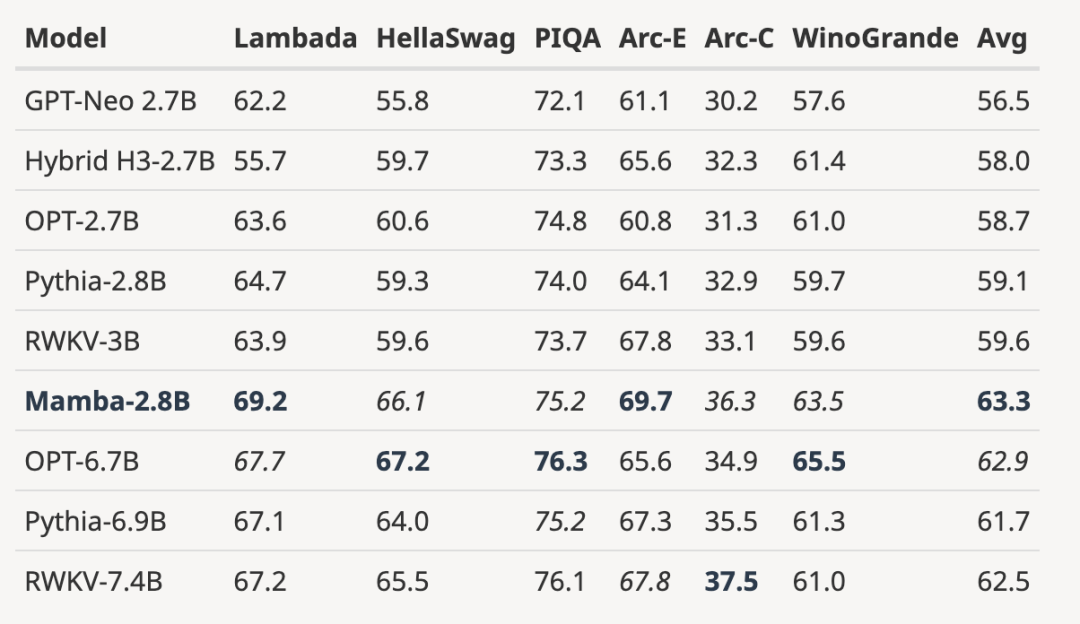
, berbanding dengan Berbanding dengan model sumber terbuka 3B yang dilatih dengan bilangan token yang sama (300B), Mamba lebih unggul dalam setiap keputusan penilaian. Ia juga setanding dengan model skala 7B: apabila membandingkan Mamba (2.8B) dengan OPT, Pythia dan RWKV (7B), Mamba mencapai skor purata terbaik dan terbaik/saat terbaik pada setiap Skor penanda aras.
Penulis telah melampirkan angka yang menilai panjang ekstrapolasi model bahasa parametrik 3B pra-terlatih:
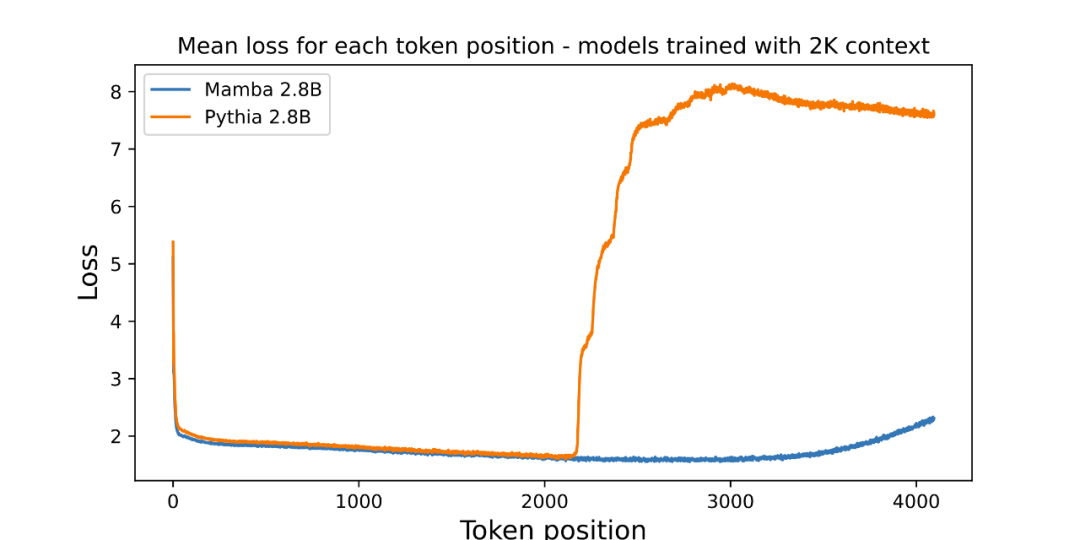
Graf memplot purata kerugian setiap kedudukan (kebolehbacaan log). Kebingungan token pertama adalah tinggi kerana ia tidak mempunyai konteks, manakala kebingungan kedua-dua Mamba dan Transformer garis dasar (Pythia) meningkat sebelum panjang konteks latihan (2048). Menariknya, kebolehlarutan Mamba bertambah baik dengan ketara di luar konteks latihannya, sehingga panjang sekitar 3000.
Pengarang menekankan bahawa ekstrapolasi panjang bukanlah motivasi langsung model dalam artikel ini, tetapi menganggapnya sebagai ciri tambahan:
Walaupun begitu, dua bulan telah berlalu, dan kertas kerja ini masih dalam proses "Decision Pending", tanpa keputusan yang jelas "penerimaan" atau "penolakan".
Dalam persidangan teratas AI utama, "letupan dalam bilangan penyerahan" adalah masalah yang menyusahkan, jadi pengulas yang mempunyai tenaga terhad pasti akan melakukan kesilapan. Ini telah menyebabkan penolakan banyak kertas terkenal dalam sejarah, termasuk YOLO, transformer XL, Dropout, mesin vektor sokongan (SVM), penyulingan pengetahuan, SIFT, dan algoritma ranking halaman web enjin carian Google PageRank (lihat: "YOLO dan PageRank yang terkenal penyelidikan yang berpengaruh telah ditolak oleh persidangan CS teratas").
Malah Yann LeCun, salah satu daripada tiga gergasi pembelajaran mendalam, juga merupakan pembuat kertas utama yang sering ditolak. Baru-baru ini, dia menulis tweet bahawa kertas kerjanya "Deep Convolutional Networks on Graph-Structured Data", yang telah dipetik sebanyak 1887 kali, juga telah ditolak oleh persidangan teratas.
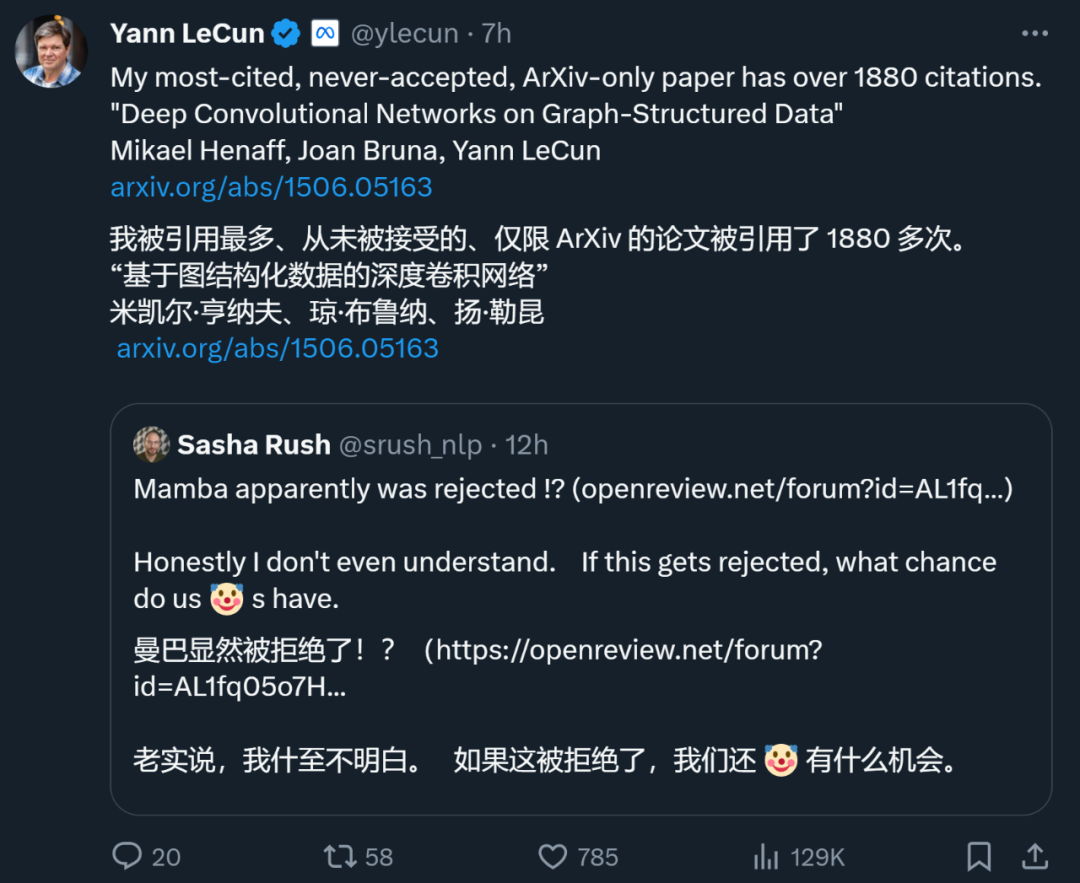
Semasa ICML 2022, dia juga "menyerahkan tiga artikel dan tiga telah ditolak."

Jadi, hanya kerana kertas itu ditolak oleh persidangan tertentu tidak bermakna ia tidak mempunyai nilai. Di antara kertas yang ditolak yang disebutkan di atas, ramai yang memilih untuk berpindah ke persidangan lain dan akhirnya diterima. Oleh itu, netizen mencadangkan agar Mamba bertukar kepada COLM yang ditubuhkan oleh ulama muda seperti Chen Danqi. COLM ialah tempat akademik yang dikhususkan untuk penyelidikan pemodelan bahasa, menumpukan pada pemahaman, penambahbaikan dan mengulas tentang pembangunan teknologi model bahasa, dan mungkin pilihan yang lebih baik untuk kertas kerja seperti Mamba.
Walau bagaimanapun, tidak kira sama ada Mamba akhirnya diterima oleh ICLR, ia telah menjadi karya yang berpengaruh, dan ia juga telah memberi harapan kepada masyarakat untuk menembusi belenggu Transformer, menyuntik harapan kepada penerokaan di luar tradisi tradisional. Model pengubah.
Atas ialah kandungan terperinci Mengapa ICLR tidak menerima kertas Mamba? Komuniti AI telah mencetuskan perbincangan besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk memasang sijil ssl
Bagaimana untuk memasang sijil ssl
 Penggunaan fungsi terima
Penggunaan fungsi terima
 lokasi.tugaskan
lokasi.tugaskan
 Bagaimana untuk membuat fail iso
Bagaimana untuk membuat fail iso
 Bagaimana untuk menyemak alamat pelayan ftp
Bagaimana untuk menyemak alamat pelayan ftp
 Perkara yang perlu dilakukan jika ralat berlaku dalam skrip halaman semasa
Perkara yang perlu dilakukan jika ralat berlaku dalam skrip halaman semasa
 Bagaimana untuk membuka fail php pada telefon bimbit
Bagaimana untuk membuka fail php pada telefon bimbit
 Alih keluar baris pengepala
Alih keluar baris pengepala








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



