Maklum Balas Kepintaran Buatan (AIF) akan menggantikan RLHF?
Dalam bidang model besar, penalaan halus adalah langkah penting untuk meningkatkan prestasi model. Apabila bilangan model besar sumber terbuka secara beransur-ansur meningkat, orang ramai telah meringkaskan banyak kaedah penalaan halus, beberapa daripadanya telah mencapai hasil yang baik. Baru-baru ini, penyelidik dari Meta dan Universiti New York menggunakan "kaedah ganjaran diri" untuk membenarkan model besar menjana data penalaan halus mereka sendiri, yang membawa kejutan baharu kepada orang ramai. Dalam kaedah baharu, pengarang memperhalusi Llama 2 70B dalam tiga lelaran, dan model yang dihasilkan mengatasi beberapa model besar penting sedia ada pada kedudukan AlpacaEval 2.0, termasuk Claude 2, Gemini Pro dan GPT -4 . Jadi kertas itu menarik perhatian orang hanya beberapa jam selepas ia disiarkan di arXiv. Walaupun kaedah tersebut belum lagi menjadi sumber terbuka, dipercayai kaedah yang digunakan dalam makalah tersebut diterangkan dengan jelas dan tidak sepatutnya sukar untuk dihasilkan semula. 
Adalah diketahui bahawa penalaan model bahasa besar (LLM) menggunakan data keutamaan manusia boleh meningkatkan prestasi penjejakan arahan model pra-latihan. Dalam siri GPT, OpenAI mencadangkan kaedah standard pembelajaran peneguhan maklum balas manusia (RLHF), yang membolehkan model besar mempelajari model ganjaran daripada keutamaan manusia, dan kemudian membenarkan model ganjaran dibekukan dan digunakan untuk melatih LLM menggunakan pembelajaran peneguhan Ini kaedah telah mendapat kejayaan besar. Idea baharu yang muncul baru-baru ini adalah untuk mengelakkan sepenuhnya model ganjaran latihan dan secara langsung menggunakan pilihan manusia untuk melatih LLM, seperti pengoptimuman keutamaan langsung (DPO). Dalam kedua-dua kes di atas, penalaan disekat oleh saiz dan kualiti data keutamaan manusia, dan dalam kes RLHF, kualiti penalaan juga disekat oleh kualiti model ganjaran beku yang dilatih daripadanya. Dalam karya baharu dalam Meta, penulis mencadangkan untuk melatih model ganjaran yang mempertingkatkan diri yang, daripada dibekukan, dikemas kini secara berterusan semasa penalaan LLM untuk mengelakkan kesesakan ini. Kunci kepada pendekatan ini adalah untuk membangunkan ejen dengan semua keupayaan yang diperlukan semasa latihan (daripada berpecah kepada model ganjaran dan model bahasa), membenarkan pra-latihan tugas mengikut arahan dan latihan pelbagai tugas untuk membolehkan serentak Latih pelbagai tugas untuk mencapai pemindahan tugas. Jadi pengarang memperkenalkan model bahasa yang memberi ganjaran kepada diri sendiri, yang mana ejennya bertindak sebagai arahan untuk mengikuti model, menjana respons untuk gesaan yang diberikan, dan juga boleh menjana dan menilai arahan baharu berdasarkan contoh untuk menambah latihan mereka sendiri set . Kaedah baharu menggunakan rangka kerja yang serupa dengan DPO lelaran untuk melatih model ini. Bermula dari model benih, seperti yang ditunjukkan dalam Rajah 1, dalam setiap lelaran terdapat proses penciptaan arahan kendiri di mana model menjana respons calon untuk gesaan yang baru dibuat, dan ganjaran kemudiannya diberikan oleh model yang sama. Yang terakhir ini dicapai melalui gesaan daripada LLM-sebagai-Hakim, yang juga boleh dilihat sebagai tugas mengikut arahan. Bina set data keutamaan daripada data yang dijana dan latih lelaran model seterusnya melalui DPO. 
Model bahasa yang memberi ganjaran kepada diri sendiriPendekatan yang dicadangkan oleh pengarang mula-mula mengandaikan: akses kepada model bahasa pra-latihan asas dan sejumlah kecil data benih beranotasi manusia, dan kemudian membina model yang bertujuan untuk memiliki kedua-dua kemahiran : 1. Ikut arahan: Berikan gesaan yang menerangkan permintaan pengguna dan dapat menjana respons yang berkualiti tinggi, membantu (dan tidak berbahaya). 2. Penciptaan arahan kendiri: Keupayaan untuk menjana dan menilai arahan baharu berikutan contoh untuk ditambah pada set latihan anda sendiri. Kemahiran ini digunakan untuk membolehkan model melakukan penjajaran kendiri, iaitu komponen yang digunakan untuk melatih dirinya secara berulang menggunakan Maklum Balas Kepintaran Buatan (AIF). Penciptaan arahan kendiri melibatkan penjanaan respons calon dan kemudian membiarkan model itu sendiri menilai kualitinya, iaitu ia bertindak sebagai model ganjarannya sendiri, dengan itu menggantikan keperluan untuk model luaran. Ini dicapai melalui mekanisme LLM-as-a-Judge [Zheng et al., 2023b], iaitu dengan merumuskan penilaian respons sebagai tugasan berikutan arahan. Data keutamaan AIF yang dicipta sendiri ini digunakan sebagai set latihan. Jadi semasa proses penalaan halus, model yang sama digunakan untuk kedua-dua peranan: sebagai "pembelajar" dan sebagai "hakim". Berdasarkan peranan hakim yang muncul, model itu boleh meningkatkan lagi prestasi melalui penalaan halus kontekstual. Proses penjajaran diri secara keseluruhan ialah proses berulang yang diteruskan dengan membina satu siri model, setiap satu merupakan peningkatan berbanding yang lepas. Apa yang penting di sini ialah memandangkan model boleh meningkatkan keupayaan generatifnya dan menggunakan mekanisme generatif yang sama seperti model ganjarannya sendiri, ini bermakna model ganjaran itu sendiri boleh bertambah baik melalui lelaran ini, yang selaras dengan standard yang wujud dalam model ganjaran. Terdapat perbezaan dalam pendekatan. Penyelidik percaya bahawa pendekatan ini boleh meningkatkan potensi model pembelajaran ini untuk memperbaiki diri pada masa hadapan dan menghapuskan kesesakan yang terhad. Rajah 1 menunjukkan gambaran keseluruhan kaedah. 

Dalam eksperimen, pengkaji menggunakan Llama 2 70B sebagai model asas pra-latihan. Mereka mendapati bahawa penjajaran LLM ganjaran kendiri bukan sahaja meningkatkan arahan berikutan prestasi tetapi juga meningkatkan keupayaan pemodelan ganjaran berbanding model benih garis dasar. Ini bermakna bahawa dalam latihan berulang, model dapat menyediakan dirinya dengan set data keutamaan kualiti yang lebih baik dalam lelaran tertentu berbanding lelaran sebelumnya. Walaupun kesan ini cenderung tepu di dunia nyata, ia menawarkan kemungkinan menarik bahawa model ganjaran yang terhasil (dan dengan itu LLM) adalah lebih baik daripada model yang dilatih semata-mata daripada data benih mentah yang ditulis oleh manusia. Dari segi kebolehan mengikut arahan, keputusan eksperimen ditunjukkan dalam Rajah 3: 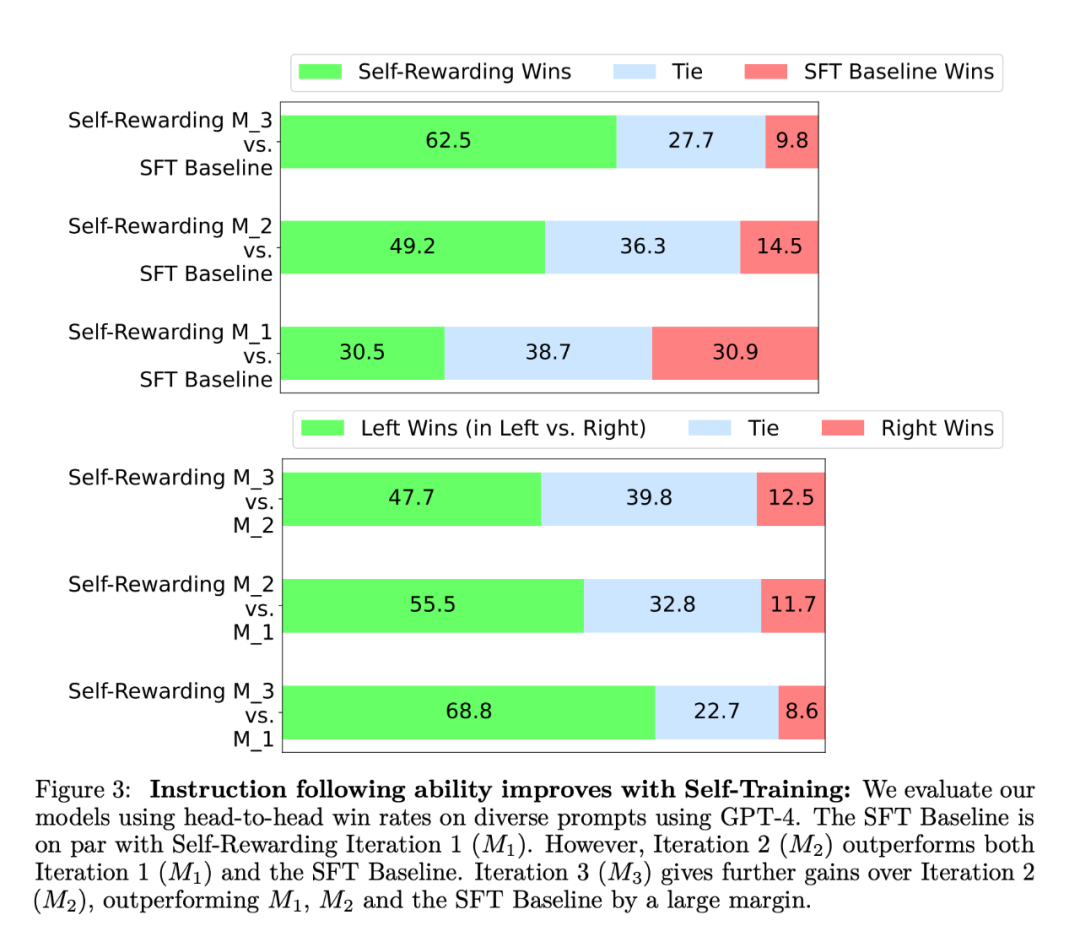 Para penyelidik menilai model ganjaran diri pada senarai kedudukan AlpacaEval 2, dan keputusan ditunjukkan dalam Jadual 1. Mereka memerhati kesimpulan yang sama seperti penilaian head-to-head, iaitu, kadar kemenangan lelaran latihan adalah lebih tinggi daripada GPT4-Turbo, daripada 9.94% dalam lelaran 1, kepada 15.38% dalam lelaran 2, kepada 20.44% dalam lelaran 3. Sementara itu, model Iterasi 3 mengatasi banyak model sedia ada, termasuk Claude 2, Gemini Pro dan GPT4 0613.
Para penyelidik menilai model ganjaran diri pada senarai kedudukan AlpacaEval 2, dan keputusan ditunjukkan dalam Jadual 1. Mereka memerhati kesimpulan yang sama seperti penilaian head-to-head, iaitu, kadar kemenangan lelaran latihan adalah lebih tinggi daripada GPT4-Turbo, daripada 9.94% dalam lelaran 1, kepada 15.38% dalam lelaran 2, kepada 20.44% dalam lelaran 3. Sementara itu, model Iterasi 3 mengatasi banyak model sedia ada, termasuk Claude 2, Gemini Pro dan GPT4 0613.

Hasil penilaian pemodelan ganjaran ditunjukkan dalam Jadual 2. Kesimpulannya termasuk:
EFT telah bertambah baik berbanding garis dasar SFT Berbanding dengan menggunakan IFT sahaja, menggunakan IFT+EFT, kesemua lima penunjuk ukuran telah bertambah baik. Sebagai contoh, perjanjian ketepatan berpasangan dengan manusia meningkat daripada 65.1% kepada 78.7%.
Tingkatkan keupayaan pemodelan ganjaran melalui latihan kendiri. Selepas pusingan latihan ganjaran kendiri, keupayaan model untuk memberikan ganjaran kendiri untuk lelaran seterusnya dipertingkatkan, dan keupayaannya untuk mengikuti arahan juga dipertingkatkan.
Kepentingan Tips LLMas-a-Judge. Para penyelidik menggunakan pelbagai format segera dan mendapati bahawa gesaan LLMas-a-Judge mempunyai ketepatan berpasangan yang lebih tinggi apabila menggunakan garis dasar SFT.
Pengarang percaya bahawa kaedah latihan ganjaran kendiri bukan sahaja meningkatkan keupayaan pengesanan arahan model, tetapi juga meningkatkan keupayaan model ganjaran model dalam lelaran. Walaupun ini hanyalah kajian awal, ia nampaknya merupakan hala tuju penyelidikan yang menarik. Kaedah ini juga membuka kemungkinan tertentu untuk kaedah penghakiman yang lebih kompleks. Sebagai contoh, model besar boleh mengesahkan ketepatan jawapan mereka dengan mencari pangkalan data, menghasilkan output yang lebih tepat dan boleh dipercayai. Kandungan rujukan: https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_language_models_meta_2024/Atas ialah kandungan terperinci Model besar di bawah ganjaran kendiri: Llama2 mengoptimumkan dirinya melalui pembelajaran Meta, mengatasi prestasi GPT-4. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




 Apakah syiling NFT?
Apakah syiling NFT?
 Kaedah pelaksanaan fungsi benteng js
Kaedah pelaksanaan fungsi benteng js
 Bagaimana untuk menutup selepas menjalankan arahan nohup
Bagaimana untuk menutup selepas menjalankan arahan nohup
 Bagaimana untuk menukar antara lebar penuh dan separuh lebar
Bagaimana untuk menukar antara lebar penuh dan separuh lebar
 Kaedah analisis data
Kaedah analisis data
 Apakah perbezaan antara rabbitmq dan kafka
Apakah perbezaan antara rabbitmq dan kafka
 apakah julat python
apakah julat python
 keperluan konfigurasi perkakasan pelayan web
keperluan konfigurasi perkakasan pelayan web








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



