


Pembelajaran mendalam ialah satu cabang pembelajaran mesin yang direka bentuk untuk mensimulasikan keupayaan otak dalam pemprosesan data. Ia menyelesaikan masalah dengan membina model rangkaian saraf tiruan yang membolehkan mesin belajar tanpa pengawasan. Pendekatan ini membolehkan mesin mengekstrak dan memahami corak dan ciri yang kompleks secara automatik. Melalui pembelajaran mendalam, mesin boleh belajar daripada sejumlah besar data dan memberikan ramalan dan keputusan yang sangat tepat. Ini telah membolehkan pembelajaran mendalam mencapai kejayaan besar dalam bidang seperti penglihatan komputer, pemprosesan bahasa semula jadi dan pengecaman pertuturan.
Untuk memahami fungsi rangkaian saraf, pertimbangkan penghantaran impuls dalam neuron. Selepas data diterima daripada terminal dendrit, ia ditimbang (didarab dengan w) dalam nukleus dan kemudian dihantar sepanjang akson dan disambungkan ke sel saraf yang lain. Akson (x) ialah keluaran daripada satu neuron dan menjadi input kepada neuron lain, sekali gus memastikan pemindahan maklumat antara saraf.
Untuk membuat model dan melatih pada komputer, kita perlu memahami algoritma operasi dan mendapatkan output dengan memasukkan arahan.
Di sini kami menyatakannya melalui matematik, seperti berikut:
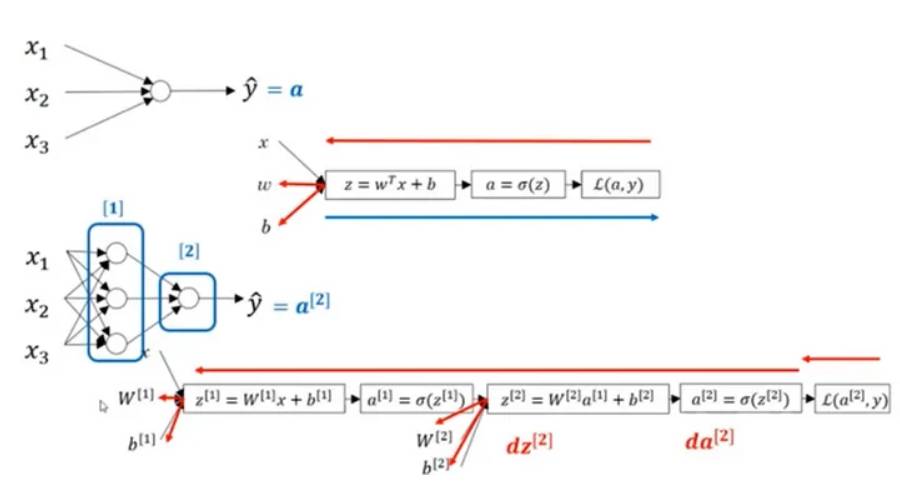
Dalam rajah di atas, rangkaian neural 2 lapisan ditunjukkan, yang mengandungi lapisan tersembunyi 4 neuron dan lapisan keluaran yang mengandungi satu neuron. Perlu diingatkan bahawa bilangan lapisan input tidak menjejaskan operasi rangkaian saraf. Bilangan neuron dalam lapisan ini dan bilangan nilai input diwakili oleh parameter w dan b. Secara khusus, input kepada lapisan tersembunyi ialah x, dan input kepada lapisan keluaran ialah nilai a.
Tangen hiperbolik, ReLU, ReLU Bocor dan fungsi lain boleh menggantikan sigmoid sebagai fungsi pengaktifan yang boleh dibezakan dan digunakan dalam lapisan, dan pemberat dikemas kini melalui operasi terbitan dalam perambatan belakang.
Fungsi pengaktifan ReLU digunakan secara meluas dalam pembelajaran mendalam. Oleh kerana bahagian fungsi ReLU yang kurang daripada 0 tidak boleh dibezakan, mereka tidak belajar semasa latihan. Fungsi pengaktifan ReLU Bocor menyelesaikan masalah ini Ia boleh dibezakan dalam bahagian kurang daripada 0 dan akan belajar dalam apa jua keadaan. Ini menjadikan Leaky ReLU lebih berkesan daripada ReLU dalam beberapa senario.
Atas ialah kandungan terperinci Analisis kaedah pembelajaran rangkaian saraf tiruan dalam pembelajaran mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penyelesaian ralat HTTP 503
Penyelesaian ralat HTTP 503
 Apakah maksud nohup?
Apakah maksud nohup?
 Apa itu Metaverse
Apa itu Metaverse
 Bagaimana untuk merujuk css dalam html
Bagaimana untuk merujuk css dalam html
 Telefon bimbit OnePlus milik jenama manakah?
Telefon bimbit OnePlus milik jenama manakah?
 Cara menggunakan return dalam bahasa C
Cara menggunakan return dalam bahasa C
 Apakah fungsi pembinaan laman web?
Apakah fungsi pembinaan laman web?
 vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan
vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



