Baru-baru ini, algoritma berasaskan Transformer telah digunakan secara meluas dalam pelbagai tugas penglihatan komputer, tetapi jenis algoritma ini terdedah kepada masalah pemasangan berlebihan apabila jumlah data latihan adalah kecil. Transformers Penglihatan Sedia Ada biasanya secara langsung memperkenalkan algoritma keciciran yang biasa digunakan dalam CNN sebagai penyelaras, yang melakukan penurunan rawak pada peta berat perhatian dan menetapkan kebarangkalian jatuh bersatu untuk lapisan perhatian pada kedalaman yang berbeza. Walaupun Dropout sangat mudah, terdapat tiga masalah utama dengan kaedah drop ini. Pertama, melakukan Penurunan rawak selepas normalisasi softmax akan memecahkan taburan kebarangkalian pemberat perhatian dan gagal untuk menghukum puncak berat, menyebabkan model masih terlalu sesuai dengan maklumat khusus setempat (Rajah 1). Kedua, kebarangkalian kejatuhan yang lebih besar dalam lapisan yang lebih dalam rangkaian akan membawa kepada kekurangan maklumat semantik peringkat tinggi, manakala kebarangkalian penurunan yang lebih kecil dalam lapisan yang lebih cetek akan membawa kepada pemasangan yang berlebihan kepada ciri terperinci asas, jadi kebarangkalian penurunan yang berterusan akan membawa kepada ketidakstabilan dalam proses latihan. Akhir sekali, keberkesanan kaedah drop berstruktur yang biasa digunakan dalam CNN on Vision Transformer tidak jelas. . DropKey penyelaras novel dan plug-and-play dicadangkan, yang boleh mengurangkan masalah overfitting dalam Vision Transformer dengan berkesan. 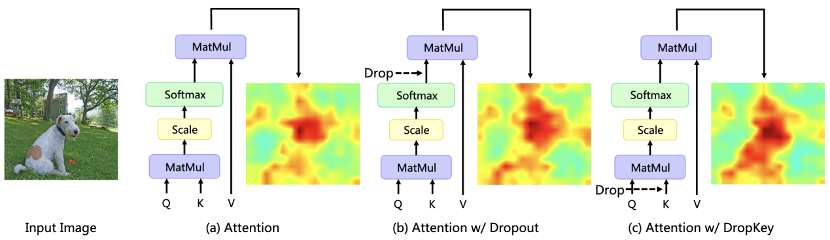
Pautan kertas: https://arxiv.org/abs/2208.02646Tiga isu teras berikut dikaji dalam artikel: perhatian yang perlu diutamakan untuk melakukan operasi Drop? Berbeza dengan penurunan terus berat perhatian, kaedah ini melakukan operasi Drop sebelum mengira matriks perhatian dan menggunakan Kunci sebagai unit Drop asas. Kaedah ini secara teorinya mengesahkan bahawa DropKey penyelaras boleh menghukum kawasan tumpuan tinggi dan memperuntukkan wajaran perhatian kepada bidang minat lain, dengan itu meningkatkan keupayaan model untuk menangkap maklumat global.
Kedua, bagaimana untuk menetapkan kebarangkalian Drop? Berbanding dengan semua lapisan yang berkongsi kebarangkalian Jatuh yang sama, makalah ini mencadangkan kaedah tetapan kebarangkalian Jatuh yang baru, yang secara beransur-ansur melemahkan nilai kebarangkalian Jatuh apabila lapisan perhatian diri semakin mendalam.
Ketiga, adakah perlu melakukan operasi Drop berstruktur seperti CNN? Kaedah ini mencuba pendekatan drop berstruktur berdasarkan tingkap blok dan tingkap silang, dan mendapati bahawa teknik ini tidak penting untuk Pengubah Penglihatan.
Pengubah Penglihatan (ViT) ialah paradigma baharu dalam model penglihatan komputer terkini Ia digunakan secara meluas dalam tugas seperti pengecaman imej, pengesanan imej, dan pengesanan titik kunci manusia. orang tengah. Secara khusus, ViT membahagikan gambar kepada bilangan blok imej yang tetap, menganggap setiap blok imej sebagai unit asas dan memperkenalkan mekanisme perhatian diri berbilang kepala untuk mengekstrak maklumat ciri yang mengandungi perhubungan bersama. Walau bagaimanapun, kaedah seperti ViT sedia ada sering mengalami masalah overfitting pada set data kecil, iaitu, mereka hanya menggunakan ciri tempatan sasaran untuk menyelesaikan tugas yang ditentukan.
Untuk mengatasi masalah di atas, kertas kerja ini mencadangkan DropKey regularizer plug-and-play yang boleh dilaksanakan hanya dalam dua baris kod untuk mengurangkan masalah overfitting kaedah kelas ViT. Berbeza daripada Dropout sedia ada, DropKey menetapkan Kunci kepada objek drop dan telah mengesahkan secara teori dan eksperimen bahawa perubahan ini boleh menghukum bahagian dengan nilai perhatian yang tinggi sambil menggalakkan model untuk memberi lebih perhatian kepada tampalan imej lain yang berkaitan dengan sasaran, yang berguna untuk menangkap ciri teguh global. Di samping itu, kertas itu juga mencadangkan untuk menetapkan kebarangkalian penurunan yang semakin berkurangan untuk lapisan perhatian yang sentiasa mendalam, yang boleh mengelakkan model daripada memasang ciri tahap rendah secara berlebihan sambil memastikan ciri tahap tinggi yang mencukupi untuk latihan yang stabil. Di samping itu, kertas itu secara eksperimen membuktikan bahawa kaedah penurunan berstruktur tidak diperlukan untuk ViT.
Untuk meneroka sebab-sebab penting yang menyebabkan masalah overfitting, penyelidikan ini mula-mula memformalkan mekanisme perhatian menjadi objektif pengoptimuman mudah dan menganalisis bentuk pengembangan Lagrangian. Didapati bahawa apabila model dioptimumkan secara berterusan, tampalan imej dengan bahagian perhatian yang lebih besar dalam lelaran semasa akan cenderung untuk diberikan berat perhatian yang lebih besar dalam lelaran seterusnya. Untuk mengurangkan masalah ini, DropKey secara tersirat menugaskan pengendali penyesuaian kepada setiap blok perhatian dengan menjatuhkan sebahagian Kunci secara rawak untuk mengekang pengagihan perhatian dan menjadikannya lebih lancar. Perlu diingat bahawa berbanding dengan regularizer lain yang direka untuk tugas tertentu, DropKey tidak memerlukan sebarang reka bentuk manual. Memandangkan penurunan rawak dilakukan pada Key semasa fasa latihan, yang akan membawa kepada jangkaan output yang tidak konsisten dalam fasa latihan dan ujian, kaedah ini juga mencadangkan untuk menggunakan kaedah Monte Carlo atau teknik penalaan halus untuk menyelaraskan jangkaan output. Tambahan pula, pelaksanaan kaedah ini hanya memerlukan dua baris kod, seperti yang ditunjukkan dalam Rajah 2.

🎜
Rajah 2 Kaedah pelaksanaan DropKeySecara umumnya, ViT menindih pelbagai lapisan perhatian untuk mempelajari ciri dimensi tinggi secara beransur-ansur. Lazimnya, lapisan cetek mengekstrak ciri visual berdimensi rendah, manakala lapisan dalam bertujuan untuk mengekstrak maklumat kasar tetapi kompleks pada ruang pemodelan. Oleh itu, kajian ini cuba menetapkan kebarangkalian penurunan yang lebih kecil untuk lapisan dalam untuk mengelakkan kehilangan maklumat penting objek sasaran. Khususnya, DropKey tidak melakukan titisan rawak dengan kebarangkalian tetap pada setiap lapisan, tetapi secara beransur-ansur mengurangkan kebarangkalian jatuh apabila bilangan lapisan meningkat. Selain itu, kajian mendapati pendekatan ini bukan sahaja berfungsi dengan DropKey tetapi juga meningkatkan prestasi Tercicir dengan ketara. Walaupun kaedah drop berstruktur telah dikaji secara terperinci dalam CNN, kesan prestasi kaedah drop ini pada ViT belum dikaji. Untuk meneroka sama ada strategi ini akan meningkatkan lagi prestasi, kertas kerja ini melaksanakan dua bentuk berstruktur DropKey, iaitu DropKey-Block dan DropKey-Cross. Antaranya, DropKey-Block menjatuhkan kawasan berterusan dalam tetingkap segi empat sama berpusat pada titik benih, dan DropKey-Cross menjatuhkan kawasan berterusan berbentuk salib berpusat pada titik benih, seperti yang ditunjukkan dalam Rajah 3. Walau bagaimanapun, kajian mendapati bahawa pendekatan penurunan berstruktur tidak membawa kepada peningkatan prestasi. 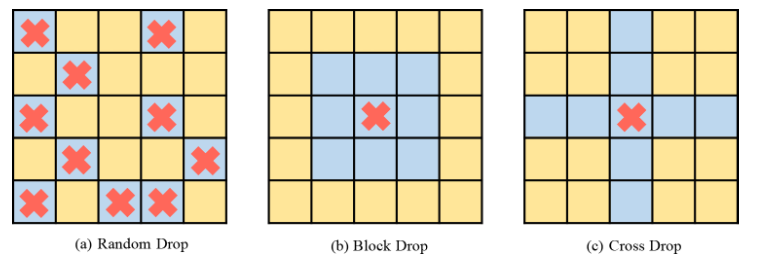
Rajah 3 Kaedah pelaksanaan berstruktur DropKey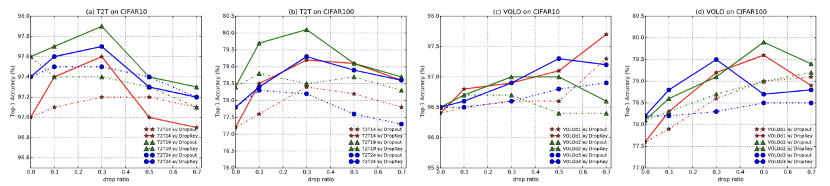
Rajah 4 Perbandingan prestasi DropKey dan Drop out pada CIFAR10/100

Rajah 5 Perbandingan kesan visualisasi peta perhatian bagi DropKey dan Dropout pada CIFAR100
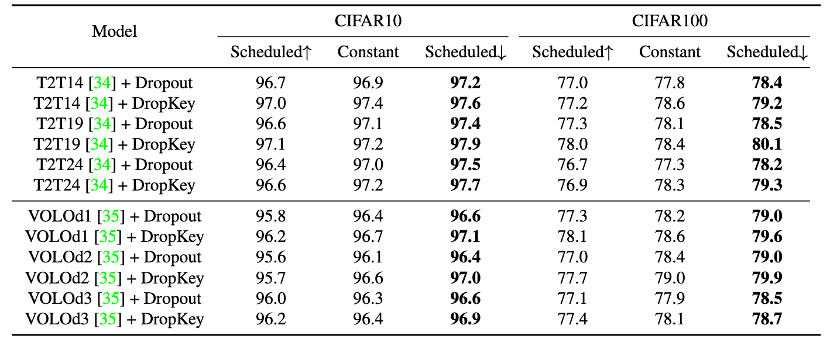
Tetapan perbandingan strategi kebarangkalian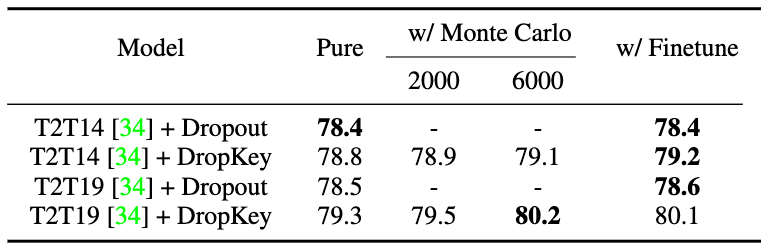
Rajah 7 Perbandingan prestasi strategi penjajaran jangkaan keluaran yang berbeza
Gambar 9 Perbandingan prestasi DropKey dan Dropout pada ImageNet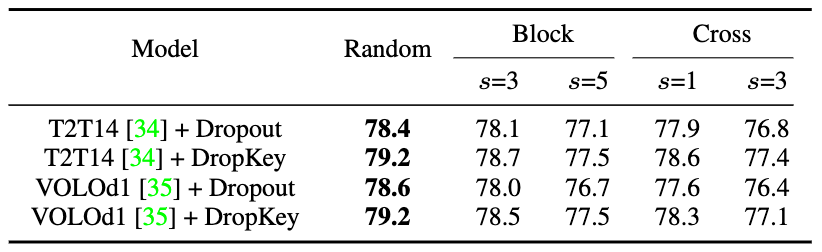
Perbandingan Prestasi COCO dan Key 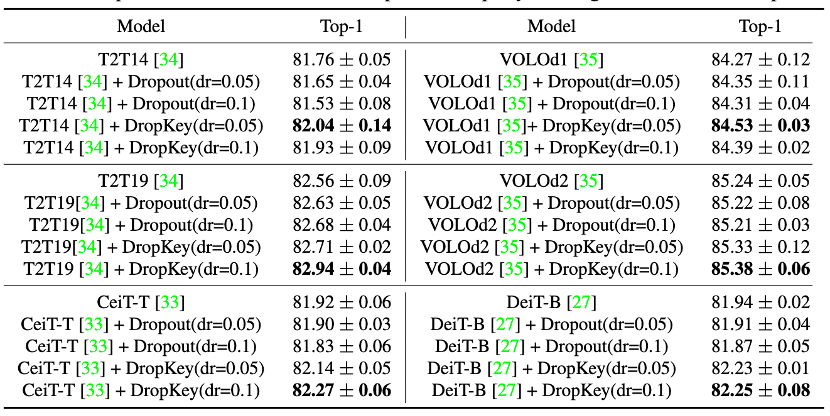
Gambar 11 Perbandingan prestasi DropKey dan Dropout pada HICO-DET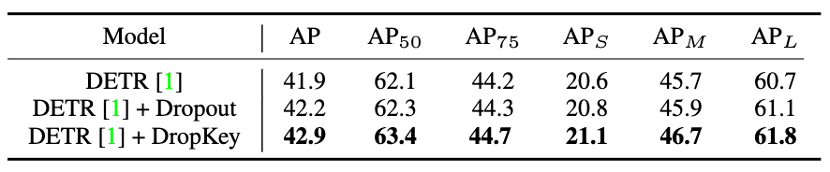

12 Perbandingan prestasi DropKey dan Dropout pada HICO-DETFigure 13 perbandingan visual peta perhatian antara dropkey dan dropout pada hico-det kertas ini secara inovatif mencadangkan regularizer untuk vit, digunakan untuk meringankan yang lebih sesuai masalah ViT. Berbanding dengan penyelaras sedia ada, kaedah ini boleh memberikan pengagihan perhatian yang lancar untuk lapisan perhatian dengan hanya menetapkan Kekunci sebagai objek jatuh. Di samping itu, kertas kerja itu juga mencadangkan strategi penetapan kebarangkalian penurunan yang baru, yang berjaya menstabilkan proses latihan sambil berkesan mengurangkan overfitting. Akhir sekali, kertas kerja ini juga meneroka kesan kaedah penurunan berstruktur pada prestasi model. Atas ialah kandungan terperinci CVPR 2023|Meitu & Universiti Sains dan Teknologi Kebangsaan bersama-sama mencadangkan kaedah penyelarasan DropKey: menggunakan dua baris kod untuk mengelakkan masalah overfitting Transformer visual dengan berkesan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Tidak dapat menyambung ke internet
Tidak dapat menyambung ke internet
 apa yang boleh dilakukan oleh nod
apa yang boleh dilakukan oleh nod
 javac tidak diiktiraf sebagai arahan dalaman atau luaran atau program yang boleh dikendalikan Bagaimana untuk menyelesaikan masalah?
javac tidak diiktiraf sebagai arahan dalaman atau luaran atau program yang boleh dikendalikan Bagaimana untuk menyelesaikan masalah?
 mata wang digital maya
mata wang digital maya
 Apakah teknologi teras yang diperlukan untuk pembangunan Java?
Apakah teknologi teras yang diperlukan untuk pembangunan Java?
 Bagaimana untuk menyelesaikan ranap ribut web
Bagaimana untuk menyelesaikan ranap ribut web
 Apakah perbezaan antara legasi dan uefi?
Apakah perbezaan antara legasi dan uefi?
 Folder menjadi exe
Folder menjadi exe








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



