


Memperoleh data berkualiti tinggi telah menjadi halangan utama dalam latihan model besar semasa.
Beberapa hari lalu, OpenAI telah disaman oleh New York Times dan menuntut pampasan berbilion dolar. Aduan itu menyenaraikan pelbagai bukti plagiarisme oleh GPT-4.
Malah New York Times menggesa pemusnahan hampir semua model besar seperti GPT.

Ramai nama besar dalam industri AI telah lama percaya bahawa "data sintetik" mungkin merupakan penyelesaian terbaik untuk masalah ini.

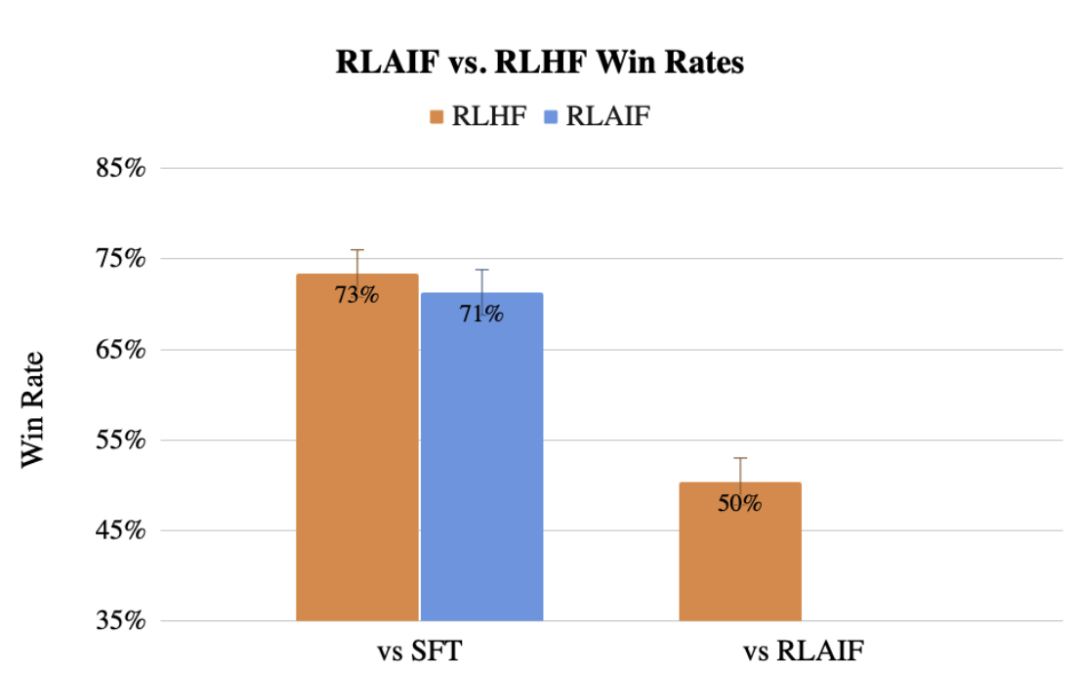
Sebelum ini, pasukan Google juga mencadangkan kaedah menggunakan LLM untuk menggantikan keutamaan pelabelan manusia RLAIF, dan kesannya tidak kalah dengan manusia.
Kini, penyelidik di Google dan MIT telah mendapati bahawa pembelajaran daripada model besar boleh membawa kepada perwakilan model terbaik yang dilatih menggunakan data sebenar.
Kaedah terbaharu ini dipanggil SynCLR, kaedah mempelajari perwakilan maya sepenuhnya daripada imej sintetik dan penerangan sintetik, tanpa sebarang data sebenar. . .

Belajar daripada Model Generatif
Kaedah pembelajaran “perwakilan visual” berprestasi terbaik pada masa ini bergantung pada set data dunia sebenar berskala besar. Walau bagaimanapun, terdapat banyak kesukaran untuk mengumpul data sebenar.Untuk mengurangkan kos mengumpul data, para penyelidik dalam kertas kerja ini bertanya soalan:
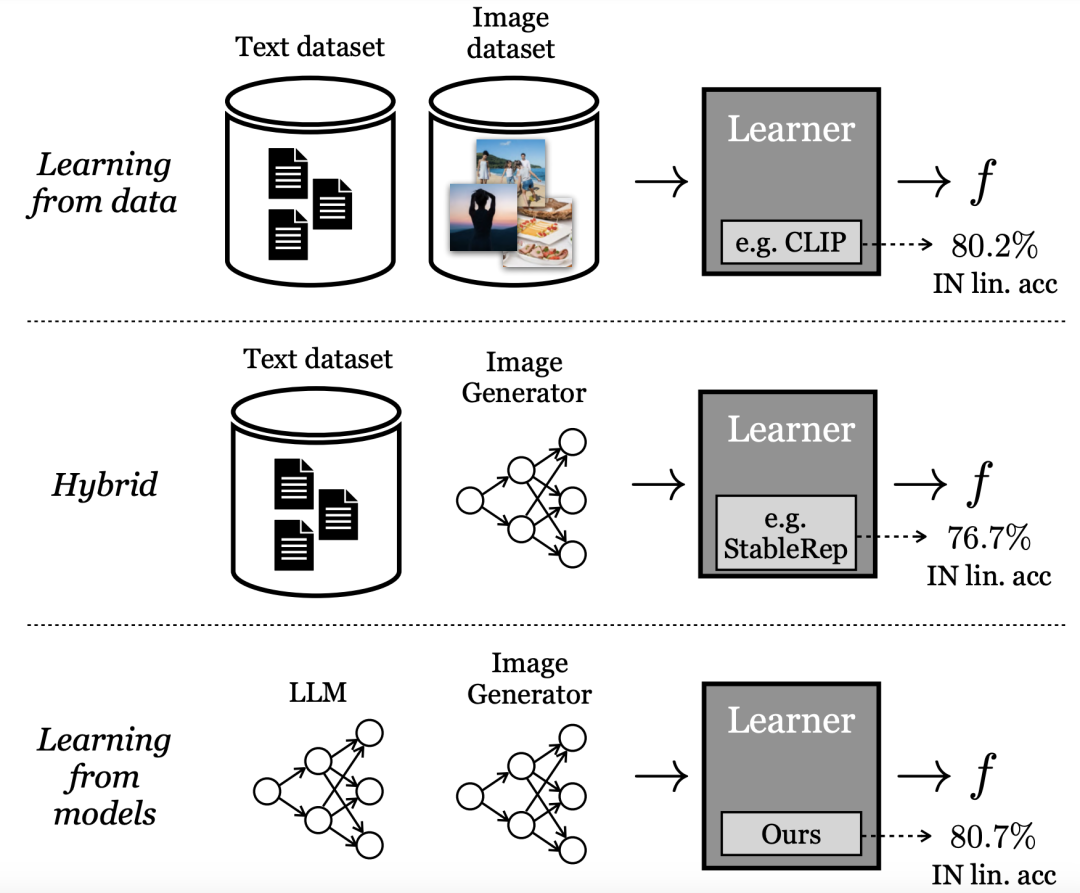
Berbeza dengan belajar terus daripada data, penyelidik Google memanggil mod ini "belajar daripada model". Sebagai sumber data untuk membina set latihan berskala besar, model mempunyai beberapa kelebihan:
- Menyediakan kaedah kawalan baharu untuk pengurusan data melalui pembolehubah terpendam, pembolehubah bersyarat dan hiperparameternya.
 - Model juga lebih mudah untuk dikongsi dan disimpan (kerana model lebih mudah untuk dimampatkan daripada data), dan boleh menghasilkan sampel data yang tidak terhad.
- Model juga lebih mudah untuk dikongsi dan disimpan (kerana model lebih mudah untuk dimampatkan daripada data), dan boleh menghasilkan sampel data yang tidak terhad.
Sebuah badan kesusasteraan yang semakin berkembang menyiasat sifat-sifat ini dan kelebihan serta keburukan lain model generatif sebagai sumber data untuk melatih model hiliran.
Sesetengah kaedah ini menggunakan model hibrid, iaitu mencampurkan set data sebenar dan sintetik, atau memerlukan satu set data sebenar untuk menjana set data sintetik yang lain.
Kaedah lain cuba mempelajari perwakilan daripada "data sintetik" semata-mata tetapi jauh ketinggalan di belakang model berprestasi terbaik.
Dalam kertas kerja, kaedah terkini yang dicadangkan oleh penyelidik menggunakan model generatif untuk mentakrifkan semula butiran kelas visualisasi.
Seperti yang ditunjukkan dalam Rajah 2, empat imej telah dijana menggunakan 2 petua "A golden retriever memakai cermin mata hitam dan topi pantai menunggang basikal" dan "A comel golden retriever duduk di atas rumah yang diperbuat daripada sushi" di dalam".
Kaedah penyeliaan sendiri tradisional (seperti Sim-CLR) akan menganggap imej ini sebagai kelas yang berbeza, dan pembenaman imej yang berbeza akan diasingkan, tanpa mempertimbangkan secara jelas semantik yang dikongsi antara imej.
Selain itu, kaedah pembelajaran yang diselia (iaitu SupCE) menganggap semua imej ini sebagai satu kelas (seperti "golden retriever"). Ini mengabaikan nuansa semantik dalam imej, seperti anjing menunggang basikal dalam sepasang imej dan anjing duduk di rumah sushi di tempat lain.
Sebaliknya, pendekatan SyncCLR menganggap perihalan sebagai kelas, iaitu satu kelas visualisasi bagi setiap perihalan.
Dengan cara ini, kita boleh mengumpulkan gambar mengikut dua konsep "menunggang basikal" dan "duduk di restoran sushi".
Perincian jenis ini sukar diperoleh dalam data sebenar kerana mengumpul berbilang imej mengikut perihalan yang diberikan bukanlah perkara remeh, terutamanya apabila bilangan perihalan meningkat.
Walau bagaimanapun, model penyebaran teks ke imej pada asasnya mempunyai keupayaan ini.
Dengan hanya mengkondisikan penerangan yang sama dan menggunakan input hingar yang berbeza, model resapan teks ke imej boleh menjana imej berbeza yang sepadan dengan penerangan yang sama.
Secara khusus, penulis mengkaji masalah pembelajaran pengekod visual tanpa data imej atau teks sebenar.
Pendekatan terkini bergantung pada penggunaan 3 sumber utama: model penjanaan bahasa (g1), model penjanaan teks ke imej (g2) dan senarai susun atur konsep visual (c).
Pra-pemprosesan merangkumi tiga langkah:
(1) Gunakan (g1) untuk mensintesis set penerangan imej T yang komprehensif, yang merangkumi pelbagai konsep visual dalam C
Untuk setiap satu tajuk dalam T, berbilang imej dijana menggunakan (g2), akhirnya menghasilkan set data imej sintetik yang luas X
(3) dilatih pada X untuk mendapatkan pengekod perwakilan visual f.
Kemudian, gunakan llama-27b dan Stable Diffusion 1.5 masing-masing sebagai (g1) dan (g2) kerana kelajuan inferensnya yang pantas. . untuk memasukkan pelbagai konsep visual.
Sebagai tindak balas, pengarang membangunkan kaedah berskala untuk mencipta set penerangan yang begitu besar, memanfaatkan keupayaan pembelajaran kontekstual model besar.
Berikut menunjukkan tiga contoh templat sintetik.
Yang berikut menggunakan Llama-2 untuk menjana penerangan konteks secara rawak tiga contoh konteks dalam setiap inferens dijalankan.

Untuk setiap penerangan teks, penyelidik memulakan proses resapan belakang dengan hingar rawak yang berbeza, menghasilkan pelbagai imej. 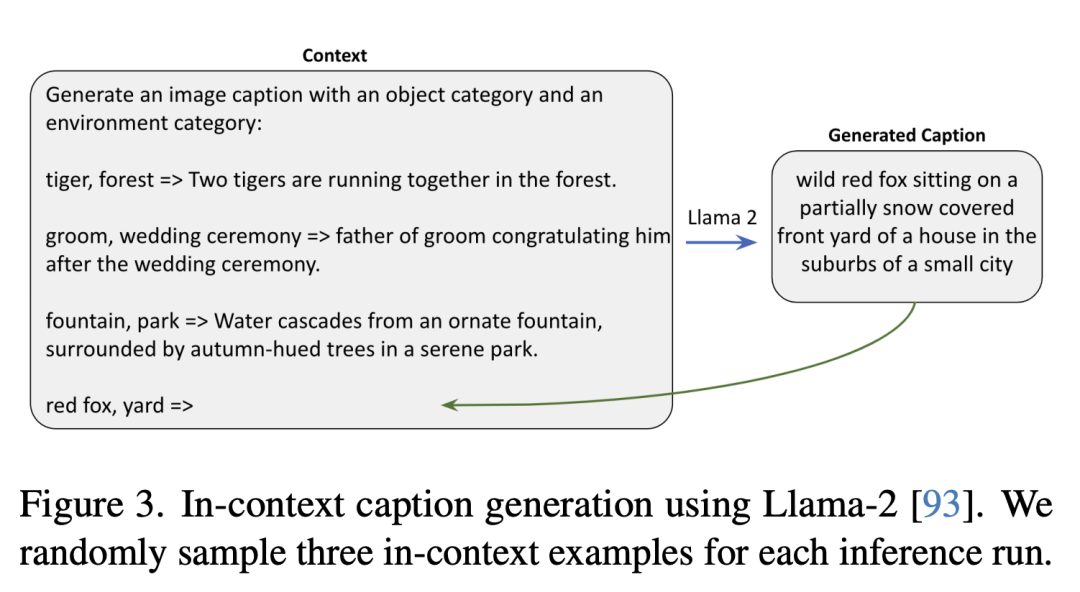
Dalam proses ini, nisbah bootstrapping (CFG) tanpa pengelas adalah faktor utama.
Semakin tinggi skala CFG, lebih baik kualiti sampel dan ketekalan antara teks dan imej, manakala semakin rendah skala, lebih besar kepelbagaian sampel dan lebih baik ketekalan antara imej berdasarkan teks yang diberikan bersyarat asal pengedaran.
Pembelajaran Perwakilan
Dalam kertas kerja, kaedah pembelajaran perwakilan adalah berdasarkan StableRep. 
Komponen utama kaedah yang dicadangkan oleh pengarang ialah kehilangan pembelajaran kontras berbilang positif, yang berfungsi dengan menjajarkan (dalam ruang membenamkan) imej yang dihasilkan daripada penerangan yang sama.
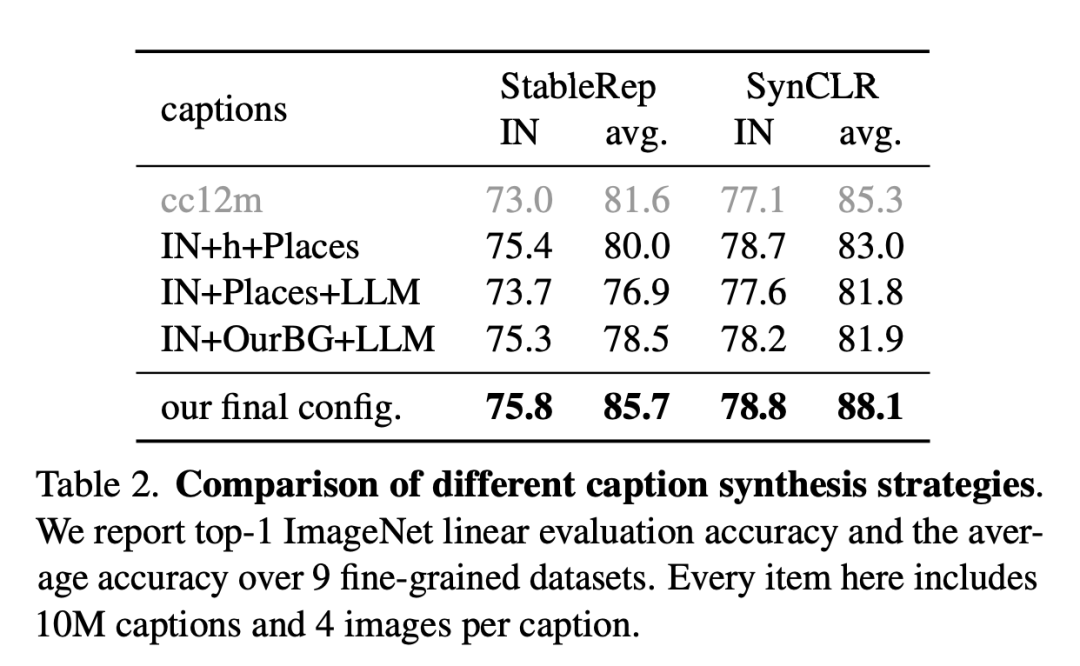
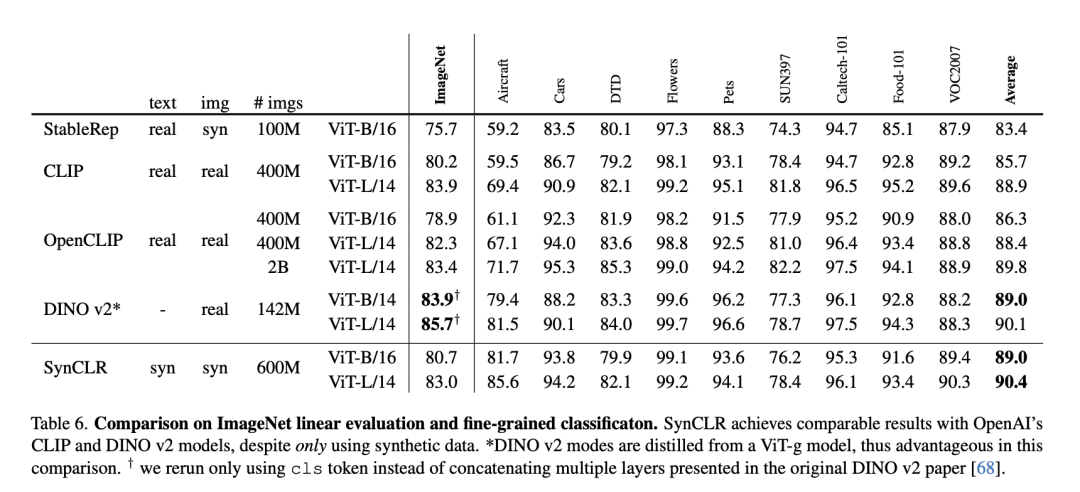
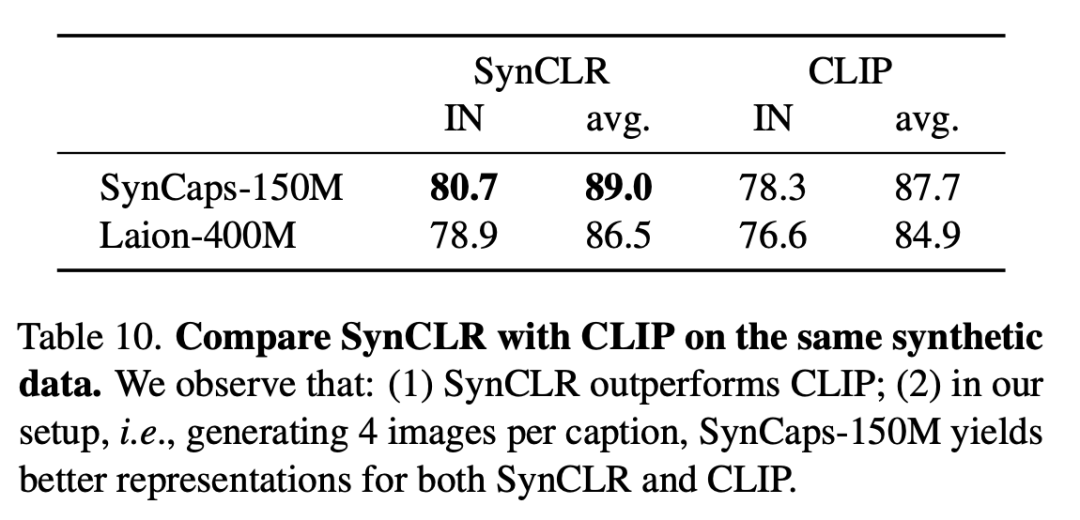
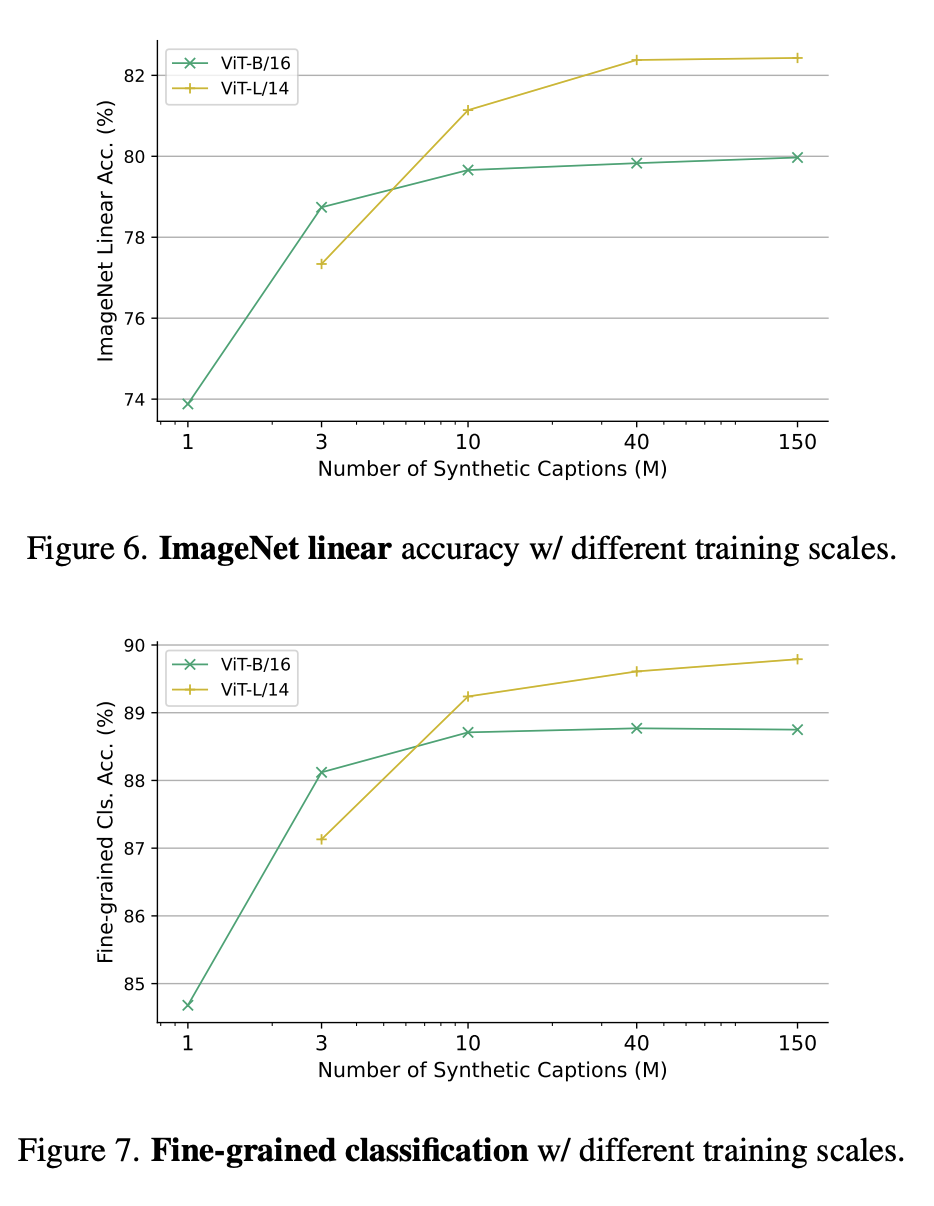
Selain itu, pelbagai teknik daripada kaedah pembelajaran penyeliaan kendiri yang lain turut digabungkan dalam kajian.Dalam penilaian eksperimen, penyelidik mula-mula menjalankan kajian ablasi untuk menilai keberkesanan pelbagai reka bentuk dan modul dalam perancangan, dan kemudian terus mengembangkan jumlah data sintetik. Gambar di bawah adalah perbandingan strategi sintesis penerangan yang berbeza. Penyelidik melaporkan ketepatan penilaian linear ImageNet dan ketepatan purata pada 9 set data terperinci. Setiap item di sini termasuk 10 juta huraian dan 4 gambar setiap huraian. Jadual berikut ialah perbandingan penilaian linear ImageNet dan pengelasan terperinci. Walaupun hanya menggunakan data sintetik, SynCLR mencapai hasil yang setanding dengan model OpenAI CLIP dan DINO v2. Jadual berikut membandingkan SyncCLR dan CLIP pada data sintetik yang sama Dapat dilihat bahawa SyncCLR jauh lebih baik daripada CLIP. Ditetapkan khusus untuk menjana 4 imej setiap tajuk, SynCaps-150M menyediakan perwakilan yang lebih baik untuk SyncCLR dan CLIP. Visualisasi PCA adalah seperti berikut. Mengikuti DINO v2, para penyelidik mengira PCA antara patch set imej yang sama dan mewarnakannya berdasarkan 3 komponen pertama mereka. Berbanding dengan DINO v2, SynCLR lebih tepat untuk lukisan kereta dan kapal terbang, tetapi lebih teruk sedikit untuk lukisan yang boleh dilukis. Rajah 6 dan Rajah 7 masing-masing menunjukkan ketepatan linear ImageNet di bawah skala latihan yang berbeza dan pengelasan halus di bawah skala parameter latihan yang berbeza. Mengapa belajar daripada model generatif? Satu sebab yang menarik ialah model generatif boleh beroperasi pada ratusan set data serentak, menyediakan cara yang mudah dan cekap untuk menyusun data latihan. Ringkasnya, kertas kerja terkini menyiasat paradigma baharu pembelajaran perwakilan visual - belajar daripada model generatif. Representasi visual yang dipelajari oleh SyncCLR adalah setanding dengan yang dipelajari oleh pelajar representasi visual tujuan am yang canggih tanpa menggunakan sebarang data sebenar. Setanding dengan CLIP OpenAI

Atas ialah kandungan terperinci Penyelidikan terkini daripada Google MIT menunjukkan bahawa mendapatkan data berkualiti tinggi tidak sukar, dan model besar adalah penyelesaiannya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Apakah perbezaan antara lulus dengan nilai dan lulus dengan rujukan dalam java
Apakah perbezaan antara lulus dengan nilai dan lulus dengan rujukan dalam java
 Perkara yang perlu dilakukan jika postskrip tidak dapat dihuraikan
Perkara yang perlu dilakukan jika postskrip tidak dapat dihuraikan
 Apa yang perlu dilakukan jika terdapat konflik IP
Apa yang perlu dilakukan jika terdapat konflik IP
 Peranan pemacu kad grafik
Peranan pemacu kad grafik
 Bagaimana untuk memadam fail dalam linux
Bagaimana untuk memadam fail dalam linux
 Bagaimana untuk mengoptimumkan prestasi Tomcat
Bagaimana untuk mengoptimumkan prestasi Tomcat
 Cara menggunakan php sleep
Cara menggunakan php sleep








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



