


Ilusi adalah masalah biasa apabila menggunakan model bahasa besar (LLM). Walaupun LLM boleh menghasilkan teks yang lancar dan koheren, maklumat yang dijananya selalunya tidak tepat atau tidak konsisten. Untuk mengelakkan LLM daripada halusinasi, sumber pengetahuan luaran, seperti pangkalan data atau graf pengetahuan, boleh digunakan untuk memberikan maklumat fakta. Dengan cara ini, LLM boleh bergantung pada sumber data yang boleh dipercayai ini, menghasilkan kandungan teks yang lebih tepat dan boleh dipercayai.
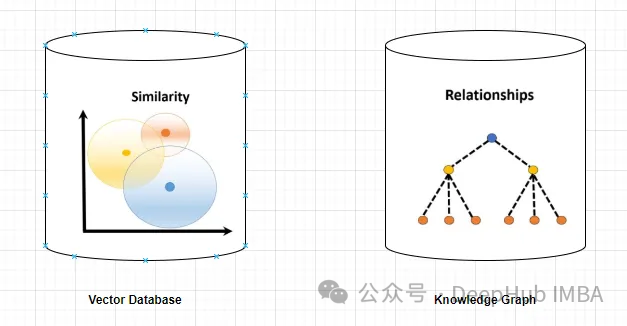
Pangkalan data vektor ialah set vektor berdimensi tinggi yang mewakili entiti atau konsep. Ia boleh digunakan untuk mengukur persamaan atau korelasi antara entiti atau konsep yang berbeza, dikira melalui perwakilan vektornya.
Pangkalan data vektor boleh memberitahu anda, berdasarkan jarak vektor, bahawa "Paris" dan "Perancis" lebih berkaitan daripada "Paris" dan "Jerman".
Menyoal pangkalan data vektor biasanya melibatkan pencarian vektor yang serupa atau perolehan semula vektor berdasarkan kriteria tertentu. Berikut ialah contoh mudah untuk menanyakan pangkalan data vektor.
Katakan terdapat pangkalan data vektor berdimensi tinggi yang menyimpan profil pelanggan. Anda ingin mencari pelanggan yang serupa dengan pelanggan rujukan yang diberikan.
Pertama, untuk mentakrifkan pelanggan sebagai perwakilan vektor, kami boleh mengekstrak ciri atau atribut yang berkaitan dan menukarnya kepada bentuk vektor.
Carian persamaan boleh dilakukan dalam pangkalan data vektor menggunakan algoritma yang sesuai seperti jiran k-hampir atau persamaan kosinus untuk mengenal pasti jiran yang paling serupa.
Dapatkan profil pelanggan yang sepadan dengan vektor jiran terdekat yang ditentukan yang mewakili pelanggan yang serupa dengan pelanggan rujukan, mengikut ukuran persamaan yang ditentukan.
Tunjukkan kepada pengguna profil pelanggan yang diambil atau maklumat berkaitan seperti nama, data demografi atau sejarah pembelian.
Graf pengetahuan ialah koleksi nod dan tepi yang mewakili entiti atau konsep dan perhubungannya (seperti fakta, atribut atau kategori). Berdasarkan atribut nod dan tepinya, ia boleh digunakan untuk bertanya atau membuat kesimpulan maklumat fakta tentang entiti atau konsep yang berbeza.
Sebagai contoh, graf pengetahuan boleh memberitahu anda bahawa "Paris" ialah ibu kota "Perancis" berdasarkan label tepi.
Menyoal pangkalan data graf melibatkan merentasi struktur graf dan mendapatkan semula nod, perhubungan atau corak berdasarkan kriteria tertentu.
Katakan anda mempunyai pangkalan data graf yang mewakili rangkaian sosial, di mana pengguna adalah nod dan perhubungan mereka diwakili sebagai tepi yang menyambungkan nod. Jika rakan rakan (sambungan biasa) ditemui untuk pengguna tertentu, maka kita harus melakukan perkara berikut:
1 Kenal pasti nod yang mewakili pengguna rujukan dalam pangkalan data graf. Ini boleh dicapai dengan membuat pertanyaan untuk pengecam pengguna tertentu atau kriteria lain yang berkaitan.
2. Gunakan bahasa pertanyaan graf, seperti Cypher (digunakan dalam Neo4j) atau Gremlin, untuk merentasi graf daripada nod pengguna rujukan. Tentukan corak atau perhubungan untuk diterokai.
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User) RETURN fofPertanyaan ini bermula dengan pengguna rujukan, mengikuti perhubungan FRIEND untuk mencari nod lain (FRIEND), dan kemudian mengikuti perhubungan FRIEND lain untuk mencari kawan kawan (fof).
3. Jalankan pertanyaan pada pangkalan data graf dan dapatkan semula nod hasil (rakan rakan) mengikut mod pertanyaan untuk mendapatkan atribut khusus atau maklumat lain tentang nod yang diambil.
Pangkalan data graf boleh menyediakan fungsi pertanyaan yang lebih maju, termasuk penapisan, pengagregatan dan padanan corak yang kompleks. Bahasa pertanyaan dan sintaks tertentu mungkin berbeza-beza, tetapi proses umum melibatkan merentasi struktur graf untuk mendapatkan semula nod dan perhubungan yang memenuhi kriteria yang diperlukan.
Graf pengetahuan memberikan maklumat yang lebih tepat dan khusus berbanding pangkalan data vektor. Pangkalan data vektor mewakili persamaan atau korelasi antara dua entiti atau konsep, manakala graf pengetahuan membolehkan pemahaman yang lebih baik tentang hubungan antara mereka. Sebagai contoh, graf pengetahuan boleh memberitahu anda bahawa "Menara Eiffel" ialah mercu tanda "Paris", manakala pangkalan data vektor hanya boleh menunjukkan persamaan kedua-dua konsep, tetapi ia tidak menjelaskan bagaimana ia berkaitan.
Graf pengetahuan menyokong pertanyaan yang lebih pelbagai dan kompleks daripada pangkalan data vektor. Pangkalan data vektor terutamanya boleh menjawab pertanyaan berdasarkan jarak vektor, persamaan atau jiran terdekat, yang terhad kepada ukuran persamaan langsung. Dan graf pengetahuan boleh mengendalikan pertanyaan berdasarkan operator logik, seperti "Apakah semua entiti dengan atribut Z atau "Apakah kategori biasa W dan V Ini boleh membantu LLM menjana teks yang lebih pelbagai dan menarik?"
Graf pengetahuan lebih baik untuk penaakulan dan inferens daripada pangkalan data vektor. Pangkalan data vektor hanya boleh menyediakan maklumat langsung yang disimpan dalam pangkalan data. Graf pengetahuan boleh memberikan maklumat tidak langsung yang diperoleh daripada perhubungan antara entiti atau konsep. Sebagai contoh, graf pengetahuan boleh membuat kesimpulan "Menara Eiffel terletak di Eropah" berdasarkan dua fakta "Paris ialah ibu negara Perancis" dan "Perancis terletak di Eropah". Ini boleh membantu LLM menjana teks yang lebih logik dan konsisten.
Jadi graf pengetahuan ialah penyelesaian yang lebih baik daripada pangkalan data vektor. Ini memberikan LLM maklumat yang lebih tepat, relevan, pelbagai, menarik, logik dan konsisten, menjadikannya lebih dipercayai dalam menghasilkan teks yang tepat dan sahih. Tetapi yang penting di sini ialah perlu ada hubungan yang jelas antara dokumen dokumen, jika tidak graf pengetahuan tidak akan dapat menangkapnya.
但是,知识图谱的使用并没有向量数据库那么直接简单,不仅在内容的梳理(数据),应用部署,查询生成等方面都没有向量数据库那么方便,这也影响了它在实际应用中的使用频率。所以下面我们使用一个简单的例子来介绍如何使用知识图谱构建RAG。
我们需要使用3个主要工具/组件:
1、LlamaIndex是一个编排框架,它简化了私有数据与公共数据的集成,它提供了数据摄取、索引和查询的工具,使其成为生成式人工智能需求的通用解决方案。
2、嵌入模型将文本转换为文本所提供的一条信息的数字表示形式。这种表示捕获了所嵌入内容的语义含义,使其对于许多行业应用程序都很健壮。这里使用“thenlper/gte-large”模型。
3、需要大型语言模型来根据所提供的问题和上下文生成响应。这里使用Zephyr 7B beta模型
下面我们开始进行代码编写,首先安装包
%%capture pip install llama_index pyvis Ipython langchain pypdf
启用日志Logging Level设置为“INFO”,我们可以输出有助于监视应用程序操作流的消息
import logging import sys # logging.basicConfig(stream=sys.stdout, level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
导入依赖项
from llama_index import (SimpleDirectoryReader,LLMPredictor,ServiceContext,KnowledgeGraphIndex) # from llama_index.graph_stores import SimpleGraphStore from llama_index.storage.storage_context import StorageContext from llama_index.llms import HuggingFaceInferenceAPI from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings from llama_index.embeddings import LangchainEmbedding from pyvis.network import Network
我们使用Huggingface推理api端点载入LLM
HF_TOKEN = "api key DEEPHUB 123456" llm = HuggingFaceInferenceAPI(model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN )
首先载入嵌入模型:
embed_model = LangchainEmbedding(HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name="thenlper/gte-large") )
加载数据集
documents = SimpleDirectoryReader("/content/Documents").load_data() print(len(documents)) ####Output### 44构建知识图谱索引
创建知识图谱通常涉及专业和复杂的任务。通过利用Llama Index (LLM)、KnowledgeGraphIndex和GraphStore,可以方便地任何数据源创建一个相对有效的知识图谱。
#setup the service context service_context = ServiceContext.from_defaults(chunk_size=256,llm=llm,embed_model=embed_model ) #setup the storage context graph_store = SimpleGraphStore() storage_context = StorageContext.from_defaults(graph_store=graph_store) #Construct the Knowlege Graph Undex index = KnowledgeGraphIndex.from_documents( documents=documents,max_triplets_per_chunk=3,service_context=service_context,storage_context=storage_context,include_embeddings=True)
Max_triplets_per_chunk:它控制每个数据块处理的关系三元组的数量
Include_embeddings:切换在索引中包含嵌入以进行高级分析。
通过构建查询引擎对知识图谱进行查询
query = "What is ESOP?" query_engine = index.as_query_engine(include_text=True,response_mode ="tree_summarize",embedding_mode="hybrid",similarity_top_k=5,) # message_template =f"""Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer. Question: {query} Helpful Answer: """ # response = query_engine.query(message_template) # print(response.response.split("")[-1].strip()) #####OUTPUT ##################### ESOP stands for Employee Stock Ownership Plan. It is a retirement plan that allows employees to receive company stock or stock options as part of their compensation. In simpler terms, it is a plan that allows employees to own a portion of the company they work for. This can be a motivating factor for employees as they have a direct stake in the company's success. ESOPs can also be a tax-efficient way for companies to provide retirement benefits to their employees.可以看到,输出的结果已经很好了,可以说与向量数据库的结果非常一致。
最后还可以可视化我们生成的图谱,使用Pyvis库进行可视化展示
from pyvis.network import Network from IPython.display import display g = index.get_networkx_graph() net = Network(notebook=True,cdn_resources="in_line",directed=True) net.from_nx(g) net.show("graph.html") net.save_graph("Knowledge_graph.html") # import IPython IPython.display.HTML(filename="/content/Knowledge_graph.html")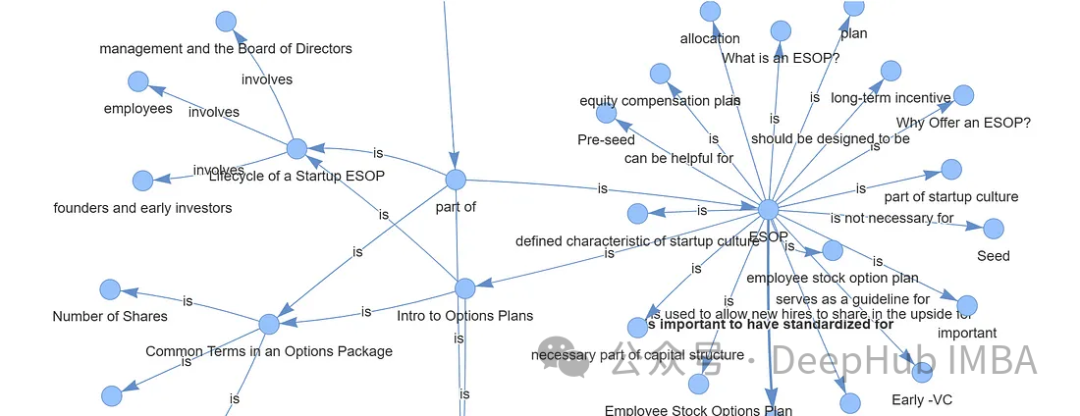

通过上面的代码我们可以直接通过LLM生成知识图谱,这样简化了我们非常多的人工操作。如果需要更精准更完整的知识图谱,还需要人工手动检查,这里就不细说了。
数据存储,通过持久化数据,可以将结果保存到硬盘中,供以后使用。
storage_context.persist()
存储的结果如下:

向量数据库和知识图谱的区别在于它们存储和表示数据的方法。向量数据库擅长基于相似性的操作,依靠数值向量来测量实体之间的距离。知识图谱通过节点和边缘捕获复杂的关系和依赖关系,促进语义分析和高级推理。
对于语言模型(LLM)幻觉,知识图被证明优于向量数据库。知识图谱提供了更准确、多样、有趣、有逻辑性和一致性的信息,减少了LLM产生幻觉的可能性。这种优势源于它们能够提供实体之间关系的精确细节,而不仅仅是表明相似性,从而支持更复杂的查询和逻辑推理。
在以前知识图谱的应用难点在于图谱的构建,但是现在LLM的出现简化了这个过程,使得我们可以轻松的构建出可用的知识图谱,这使得他在应用方面又向前迈出了一大步。对于RAG,知识图谱是一个非常好的应用方向。
Atas ialah kandungan terperinci Menggunakan graf pengetahuan untuk meningkatkan keupayaan model RAG dan mengurangkan tanggapan palsu model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menangani aksara Cina yang kacau dalam Linux
Bagaimana untuk menangani aksara Cina yang kacau dalam Linux
 Pesanan yang disyorkan untuk mempelajari bahasa c++ dan c
Pesanan yang disyorkan untuk mempelajari bahasa c++ dan c
 Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
Bagaimana untuk menyelesaikan aksara bercelaru dalam PHP
 Kaedah pembaikan keraguan pangkalan data
Kaedah pembaikan keraguan pangkalan data
 Penyelesaian tamat masa permintaan pelayan
Penyelesaian tamat masa permintaan pelayan
 IIS penyelesaian ralat tidak dijangka 0x8ffe2740
IIS penyelesaian ralat tidak dijangka 0x8ffe2740
 navigator.useragent
navigator.useragent
 Bagaimana untuk mendapatkan token
Bagaimana untuk mendapatkan token








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



